
Training semantic segmentation models are often time-consuming and compute-intensive. However, with the powerful self-supervised DINOv2 backbones, we can drastically reduce the training compute and time. Using DINOv2, we can just add a semantic segmentation head on top of the pretrained backbone and train a few thousand parameters for good performance. This is exactly what we are going to cover in this article. We will modify the DINOv2 backbone, add a simple pixel classifier on top of it, and train DINOv2 for semantic segmentation.
What are we going to cover while training DINOV2 for semantic segmentation?
We will primarily answer the following questions.
- Why do we need this article?
- How do we modify the DINOv2 backbone for semantic segmentation?
- What is the process for training the model?
- What results can we expect after training DINOv2 for semantic segmentation?
- What are the limitations of our approach?
Note: This is not the cleanest possible code for converting a DINOv2 backbone into a semantic segmentation model. It is an early phase codebase for a larger project that we will work on at DebuggerCafe very soon. The code is not the cleanest, a lot of “patching” has gone into the modeling part, with some yet-to-be-answered parts.
Why Do We Need This Article?
The official DINOv2 repository provides two notebooks for modified DINOv2 models, one for semantic segmentation and another for depth estimation. We will keep our focus entirely on semantic segmentation here.
The repository only provides inference code for semantic segmentation with MMSegmentation integration. As it stands, it is quite difficult to set up the repository with MMSegmentation requirements because of several dependency issues. Furthermore, it is not clear how to train the model for semantic segmentation and what hyperparameters to choose. Additionally, the repository provides segmentation heads trained on Pascal VOC, and ADE20k, along with a completetly re-trained DINOv2 model based on Mask2Former segmentation head.
To mitigate some of the above issues, this article aims to completely discard the MMSegmentation dependency. We rely on pure PyTorch backbone code from the DINOv2 repository while adding the code needed to build the semantic segmentation version of it.
Because the project is in the early stages, the code is not yet completely clean as we mentioned above. Some of the hyperparameters and approaches are yet to be finalized. However, with this article, the community also gets their hands on something tangible that they can play around with, suggest, and improve.
The Human Segmentation Dataset
We will experiment with a very simple dataset, human segmentation to be precise, in this article. Our attempts at uncovering DINOv2 for different tasks (starting with segmentation in this article) may not produce very accurate results in the first pass, but we will get there eventually.
We will train the model on the Penn-Fudan Pedestrian Segmentation dataset. It is a small dataset with only 146 training samples and 24 validation samples. This is just perfect for experimenting with such a large code change so that we can iterate quickly.
The masks contain a different label mask for each person as it has been adapted from an instance segmentation dataset. During training, we will convert each person’s mask to a value of 255 and the background to 0.
You should see the following structure after downloading and extracting the data from the above link.
PennFudanPed/ ├── train_images ├── train_masks ├── valid_images └── valid_masks
The following are some ground truth images and masks (pedestrian mask labels have been converted to a value of 255).

Project Directory Structure
Let’s take a look at the project directory structure before moving to the coding part.
├── input │ ├── inference_data │ └── PennFudanPed ├── outputs │ ├── valid_preds │ ├── best_model_iou.pth │ └── best_model_loss.pth ├── config.py ├── datasets.py ├── engine.py ├── infer_image.py ├── infer_video.py ├── metrics.py ├── model.py ├── requirements.txt ├── temp.py ├── train.py └── utils.py
- The
inputdirectory contains the Penn-Fudan pedestrian segmentation dataset that we downloaded above. - The
outputsdirectory will contain the training results, the trained model weights, as well as the inference results. - In the root project directory, we have all the Python files that we will deal with.
All the code files, inference dataset, and trained weights will be available via the “Download Code” section.
Download Code
Installing Dependencies
We can install all the necessary dependencies using the requirements.txt file.
pip install -r requirements.txt
If you face OpenCV related errors (because of Albumentations), please execute the following command after installing the above requirements.
pip uninstall opencv-python opencv-python-headless pip install opencv-python
Semantic Segmentation using DINOv2
Starting from this section, we will cover the important coding parts involving the project. As we have discussed earlier, a lot of code components are strictly “patched in” right now and there are better code practices for them. We will be pointing these out while covering the model code.
How to Modify the DINOv2 Backbone for Semantic Segmentation?
The code for creating the DINOv2 based segmentation model resides in the model.py file. Let’s start with the import statements.
import torch import urllib import warnings import torch.nn.functional as F import torch.nn as nn from functools import partial from collections import OrderedDict from torchinfo import summary
Defining the DINOv2 Backbone
The first step for creating the model is defining the model architecture and downloading the pretrained backbone.
BACKBONE_SIZE = "small" # in ("small", "base", "large" or "giant")
backbone_archs = {
"small": "vits14",
"base": "vitb14",
"large": "vitl14",
"giant": "vitg14",
}
backbone_arch = backbone_archs[BACKBONE_SIZE]
backbone_name = f"dinov2_{backbone_arch}"
HEAD_SCALE_COUNT = 3 # more scales: slower but better results, in (1,2,3,4,5)
HEAD_DATASET = "voc2012" # in ("ade20k", "voc2012")
HEAD_TYPE = "ms" # in ("ms, "linear")
DINOV2_BASE_URL = "https://dl.fbaipublicfiles.com/dinov2"
head_config_url = f"{DINOV2_BASE_URL}/{backbone_name}/{backbone_name}_{HEAD_DATASET}_{HEAD_TYPE}_config.py"
head_checkpoint_url = f"{DINOV2_BASE_URL}/{backbone_name}/{backbone_name}_{HEAD_DATASET}_{HEAD_TYPE}_head.pth"
backbone_model = torch.hub.load(repo_or_dir="facebookresearch/dinov2", model=backbone_name)
backbone_model.cuda()
We are choosing the small backbone from DINOv2. Each backbone name is coupled with a different ViT model as we can see in backbone_archs. For DINOv2-Small model, it is vits14 which is a small Vision Transformer model with 14×14 resolution patches.
From this, we define the backbone_arch, and backbone_name, which in turn defines the head configuration and head checkpoint URLs.
We also have HEAD_SCALE_COUNT, HEAD_DATASET, and HEAD_TYPE. The HEAD_DATASET defines the dataset on which the segmentation head has been trained on. In this case, it is the Pascal VOC dataset. The HEAD_TYPE is multi-scale which tells the model later to aggregate features from different layers before passing it to the pixel classification layer.
At the moment, although we have defined HEAD_SCALE_COUNT, we are not using it. This is part of the MMCV configuration file and using MMSegmentation for training/inference uses this automatically. I have not yet figured out how to use it without MMSegmentation configuration file for training or inference. One speculation is that we should have different image scales for each batch to train the model at different resolutions. However, a closer look at the internal codebase is needed for proper implementation.
Downloading Backbone Configuration
Now coming to the messy part of the code. We need to download the configuration file to define the model backbone properly. The authors originally used this configuration for MMSegmentation training which is the expected methodology for the library.
# TODO: This part needs cleaning #
def load_config_from_url(url: str) -> str:
with urllib.request.urlopen(url) as f:
return f.read().decode()
cfg_str = load_config_from_url(head_config_url)
with open('temp.py', 'w') as f:
f.write(cfg_str)
from temp import model as model_dict
##################################
backbone_model.forward = partial(
backbone_model.get_intermediate_layers,
n=model_dict['backbone']['out_indices'],
reshape=True,
)
for name, param in backbone_model.named_parameters():
param.requires_grad = False
We download the model configuration using the head_config_url and save it as temp.py. This file contains several dictionaries defining important training, inference, and test configurations along with model configs.
We load the model configuration dictionary as model_dict which is further used to define a partial method along with the number of layers (n) to get the features from. For segmentation, we will concatenate features from 4 different layers defined as out_indices in the configuration (temp.py) file.
The following shows the model configuration from temp.py.
model = dict(
type="EncoderDecoder",
pretrained=None,
backbone=dict(type="DinoVisionTransformer", out_indices=[8, 9, 10, 11]),
decode_head=dict(
type="BNHead",
in_channels=[384, 384, 384, 384],
in_index=[0, 1, 2, 3],
input_transform='resize_concat',
channels=1536,
dropout_ratio=0,
num_classes=21,
norm_cfg=dict(type="SyncBN", requires_grad=True),
align_corners=False,
loss_decode=dict(
type="CrossEntropyLoss", use_sigmoid=False, loss_weight=1.0)),
test_cfg=dict(mode="slide", crop_size=(640, 640), stride=(320, 320)))
As we can see, the configuration instructs the partial method to extract features from layers 8, 9, 10, and 11. It is important to remember that this configuration is only valid for the ViT-Small model and will differ for each backbone.
Custom Resize Function
Next, we have a custom resize function used in the model’s segmentation head.
def resize(input_data,
size=None,
scale_factor=None,
mode="nearest",
align_corners=None,
warning=True):
if warning:
if size is not None and align_corners:
input_h, input_w = tuple(int(x) for x in input.shape[2:])
output_h, output_w = tuple(int(x) for x in size)
if output_h > input_h or output_w > input_w:
if ((output_h > 1 and output_w > 1 and input_h > 1
and input_w > 1) and (output_h - 1) % (input_h - 1)
and (output_w - 1) % (input_w - 1)):
warnings.warn(
f'When align_corners={align_corners}, '
'the output would more aligned if '
f'input size {(input_h, input_w)} is `x+1` and '
f'out size {(output_h, output_w)} is `nx+1`')
return F.interpolate(input_data, size, scale_factor, mode, align_corners)
The BNHead for Pixel Classification
We use the BNHead class from the DINOv2 repository to concatenate the extracted features, define the pixel classification head for segmentation, and carry out the forward pass.
class BNHead(nn.Module):
"""Just a batchnorm."""
def __init__(self, resize_factors=None, **kwargs):
super().__init__(**kwargs)
# HARDCODED IN_CHANNELS FOR NOW.
self.in_channels = 1536
self.bn = nn.SyncBatchNorm(self.in_channels)
self.resize_factors = resize_factors
self.in_index = [0, 1, 2, 3]
self.input_transform = 'resize_concat'
self.align_corners = False
self.conv_seg = nn.Conv2d(self.in_channels, 21, kernel_size=1)
def _forward_feature(self, inputs):
"""Forward function for feature maps before classifying each pixel with
``self.cls_seg`` fc.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
feats (Tensor): A tensor of shape (batch_size, self.channels,
H, W) which is feature map for last layer of decoder head.
"""
x = self._transform_inputs(inputs)
feats = self.bn(x)
return feats
def _transform_inputs(self, inputs):
"""Transform inputs for decoder.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
Tensor: The transformed inputs
"""
if self.input_transform == "resize_concat":
# accept lists (for cls token)
input_list = []
for x in inputs:
if isinstance(x, list):
input_list.extend(x)
else:
input_list.append(x)
inputs = input_list
# an image descriptor can be a local descriptor with resolution 1x1
for i, x in enumerate(inputs):
if len(x.shape) == 2:
inputs[i] = x[:, :, None, None]
# select indices
inputs = [inputs[i] for i in self.in_index]
# Resizing shenanigans
# print("before", *(x.shape for x in inputs))
if self.resize_factors is not None:
assert len(self.resize_factors) == len(inputs), (len(self.resize_factors), len(inputs))
inputs = [
resize(input=x, scale_factor=f, mode="bilinear" if f >= 1 else "area")
for x, f in zip(inputs, self.resize_factors)
]
# print("after", *(x.shape for x in inputs))
upsampled_inputs = [
resize(input_data=x, size=inputs[0].shape[2:], mode="bilinear", align_corners=self.align_corners)
for x in inputs
]
inputs = torch.cat(upsampled_inputs, dim=1)
elif self.input_transform == "multiple_select":
inputs = [inputs[i] for i in self.in_index]
else:
inputs = inputs[self.in_index]
return inputs
def cls_seg(self, feat):
"""Classify each pixel."""
output = self.conv_seg(feat)
return output
def forward(self, inputs):
"""Forward function."""
output = self._forward_feature(inputs)
output = self.cls_seg(output)
return output
The pixel classification layer is just a Conv2D layer with 21 classes (for VOC). We will change the output channels as per the number of classes later. The forward method transforms the inputs as per the multi-scale output, resizes them, and passes them through the classifier head.
One factor to note here is the in_channels for the segmentation head which we hardcode as 1536. This is the final number of output features after concatenating the 384 dimensional features 4 times (as we concatenate features from 4 layers). Later, it will be much better to make this calculation dynamic.
Define the Final DINOv2 Segmentation Model
Finally, we define the DINOv2 Segmentation model as a Sequential Ordered and Named Dictionary with a backbone and decode_head.
class DINOv2Segmentation(nn.Module):
def __init__(self):
super(DINOv2Segmentation, self).__init__()
self.backbone_model = backbone_model
self.decode_head = BNHead()
self.model = nn.Sequential(OrderedDict([
('backbone', self.backbone_model),
('decode_head', self.decode_head)
]))
def forward(self, x):
outputs = self.model(x)
return outputs
if __name__ == '__main__':
model = DINOv2Segmentation()
summary(
model,
(1, 3, 644, 644),
col_names=('input_size', 'output_size', 'num_params'),
row_settings=['var_names']
)
Executing this file with the command python model.py will give the following output.
============================================================================================================================= Layer (type (var_name)) Input Shape Output Shape Param # ============================================================================================================================= DINOv2Segmentation (DINOv2Segmentation) [1, 3, 644, 644] [1, 21, 46, 46] -- ├─Sequential (model) [1, 3, 644, 644] [1, 21, 46, 46] -- │ └─DinoVisionTransformer (backbone) [1, 3, 644, 644] [1, 384, 46, 46] 526,848 │ │ └─PatchEmbed (patch_embed) [1, 3, 644, 644] [1, 2116, 384] (226,176) │ │ └─ModuleList (blocks) -- -- (21,302,784) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (768) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ └─BNHead (decode_head) [1, 384, 46, 46] [1, 21, 46, 46] -- │ │ └─SyncBatchNorm (bn) [1, 1536, 46, 46] [1, 1536, 46, 46] 3,072 │ │ └─Conv2d (conv_seg) [1, 1536, 46, 46] [1, 21, 46, 46] 32,277 ============================================================================================================================= Total params: 22,091,925 Trainable params: 35,349 Non-trainable params: 22,056,576 Total mult-adds (Units.MEGABYTES): 568.19 ============================================================================================================================= Input size (MB): 4.98 Forward/backward pass size (MB): 1073.41 Params size (MB): 86.26 Estimated Total Size (MB): 1164.64 =============================================================================================================================
As we are freezing the backbone, only the decode head is trainable with 35,349 parameters for 21 classes. This is going to reduce even further as we will train just one class, that is person.
One final point to note is the image size of 644×644 that we used in the above dummy forward pass. Because of the structure of the backbone (kernel size and padding), the input features get cropped and a resolution of 640×640 throws an error as the patches to be created are not divisible by 14. However, during training, we will handle this in the dataloader image transforms so that we can pass 640×640 resolution in the command line arguments to avoid confusion.
Important Factors About Dataset Preparation
In this section, we will explore some important code snippets from the datasets.py file which prepares the dataset.
The first one is the normalization values. We do not have the normalization values for the LVD-142M dataset. So, we use the ImageNet normalization values.
MEAN = [0.485, 0.456, 0.406] STD = [0.229, 0.224, 0.225]
The second one is the training and validation transforms.
# TODO: Batchwise rescaling with different image ratios.
def train_transforms(img_size):
"""
Transforms/augmentations for training images and masks.
:param img_size: Integer, for image resize.
"""
train_image_transform = A.Compose([
A.Resize(img_size[1], img_size[0], always_apply=True),
A.PadIfNeeded(
min_height=img_size[1]+4,
min_width=img_size[0]+4,
position='center',
value=0,
mask_value=0
),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Rotate(limit=25),
A.Normalize(mean=MEAN, std=STD, max_pixel_value=255.)
], is_check_shapes=False)
return train_image_transform
# TODO: Batchwise rescaling with different image ratios.
def valid_transforms(img_size):
"""
Transforms/augmentations for validation images and masks.
:param img_size: Integer, for image resize.
"""
valid_image_transform = A.Compose([
A.Resize(img_size[1], img_size[0], always_apply=True),
A.PadIfNeeded(
min_height=img_size[1]+4,
min_width=img_size[0]+4,
position='center',
value=0,
mask_value=0
),
A.Normalize(mean=MEAN, std=STD, max_pixel_value=255.)
], is_check_shapes=False)
return valid_image_transform
The following are the common transforms for training and validation:
- First, we resize the images to the resize values passed through the command line during the training script execution. For this project, it is going to be 640×640.
- Then we center pad each image and mask with 4 black pixels. This brings the final resolution to 644×644. The original implementation from the authors does this on the fly and is part of the model pipeline. Furthermore, the authors implement dynamic padding so that the model never throws the patch division error. In our case, the 4 pixel center padding will work for 640×640 images. It is hardcoded for now. Generally, it needs to be
image_size + (image_size/160). So, for 1280×1280 image size, we should have a center padding of 8 pixels.
We apply horizontal flipping, random brightness contrast, and rotation augmentations to the training set to avoid overfitting.
Furthermore, the file also contains SegmentationDataset class to prepare custom datasets. As all instances of persons have different values, we will make each pixel with a value greater than 0 as 255. This code snippet in the __getitem__ method of the dataset class does the job.
# Make all pixel > 0 as 255. im = mask > 0 mask[im] = 255 mask[np.logical_not(im)] = 0
The Logits to Upsampled Pixel Map Logic
The model originally returns 46×46 shaped logits as raw pixel maps. These are 14 times downsampled compared to the 644×644 input that we pass. To calculate the loss and also for inference visualization, we need the upsampled logits which will be converted to segmentation maps.
To achieve this, in the train and validate method of engine.py, we have the following logic.
upsampled_logits = nn.functional.interpolate(
outputs, size=target.shape[-2:],
mode="bilinear",
align_corners=False
)
We apply a bilinear interpolation to resize the logits to the original input image shape. The same logic is used during inference.
This completes all the important code snippets that we needed to cover.
Training the DINOv2 Model for Semantic Segmentation
In the train.py script, we need to modify the number of classes for the final segmentation head after initializing the model.
model = DINOv2Segmentation() model.decode_head.conv_seg = nn.Conv2d(1536, len(ALL_CLASSES), kernel_size=(1, 1), stride=(1, 1))
We are all set to start the training process. Execute the following command in the terminal within the parent project directory.
python train.py --lr 0.001 --batch 20 --imgsz 640 640 --epochs 65 --scheduler --scheduler-epochs 50
We use a higher learning rate than usual as we train just the new segmentation head and the backbone weights are frozen. Furthermore, this follows the same pipeline as the original configuration file. We train with 640×640 resolution images for 65 epochs and apply a learning rate scheduler to reduce the learning rate by a factor of 10 after 50 epochs.
The following are the truncated results.
============================================================================================================================= Layer (type (var_name)) Input Shape Output Shape Param # ============================================================================================================================= DINOv2Segmentation (DINOv2Segmentation) [1, 3, 644, 644] [1, 2, 46, 46] -- ├─Sequential (model) [1, 3, 644, 644] [1, 2, 46, 46] -- │ └─DinoVisionTransformer (backbone) [1, 3, 644, 644] [1, 384, 46, 46] 526,848 │ │ └─PatchEmbed (patch_embed) [1, 3, 644, 644] [1, 2116, 384] (226,176) │ │ └─ModuleList (blocks) -- -- (21,302,784) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (768) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ │ └─LayerNorm (norm) [1, 2117, 384] [1, 2117, 384] (recursive) │ └─BNHead (decode_head) [1, 384, 46, 46] [1, 2, 46, 46] -- │ │ └─SyncBatchNorm (bn) [1, 1536, 46, 46] [1, 1536, 46, 46] 3,072 │ │ └─Conv2d (conv_seg) [1, 1536, 46, 46] [1, 2, 46, 46] 3,074 ============================================================================================================================= Total params: 22,062,722 Trainable params: 6,146 Non-trainable params: 22,056,576 Total mult-adds (Units.MEGABYTES): 506.39 ============================================================================================================================= Input size (MB): 4.98 Forward/backward pass size (MB): 1073.08 Params size (MB): 86.14 Estimated Total Size (MB): 1164.20 ============================================================================================================================= EPOCH: 1 Training 100%|████████████████████| 8/8 [00:10<00:00, 1.34s/it] Validating 100%|████████████████████| 2/2 [00:02<00:00, 1.15s/it] Best validation loss: 0.3740081340074539 Saving best model for epoch: 1 Best validation IoU: 0.4842417537368489 Saving best model for epoch: 1 Train Epoch Loss: 0.5106, Train Epoch PixAcc: 0.6750, Train Epoch mIOU: 0.504861 Valid Epoch Loss: 0.3740, Valid Epoch PixAcc: 0.5870 Valid Epoch mIOU: 0.484242 LR for next epoch: [0.001] -------------------------------------------------- EPOCH: 2 Training 100%|████████████████████| 8/8 [00:10<00:00, 1.29s/it] Validating 100%|████████████████████| 2/2 [00:02<00:00, 1.13s/it] Best validation loss: 0.2752937972545624 Saving best model for epoch: 2 Best validation IoU: 0.54755631614711 Saving best model for epoch: 2 Train Epoch Loss: 0.3536, Train Epoch PixAcc: 0.7934, Train Epoch mIOU: 0.652029 Valid Epoch Loss: 0.2753, Valid Epoch PixAcc: 0.6221 Valid Epoch mIOU: 0.547556 LR for next epoch: [0.001] -------------------------------------------------- . . . -------------------------------------------------- EPOCH: 49 Training 100%|████████████████████| 8/8 [00:11<00:00, 1.40s/it] Validating 100%|████████████████████| 2/2 [00:02<00:00, 1.26s/it] Best validation loss: 0.07244893908500671 Saving best model for epoch: 49 Best validation IoU: 0.6051037135003753 Saving best model for epoch: 49 Train Epoch Loss: 0.1237, Train Epoch PixAcc: 0.8418, Train Epoch mIOU: 0.733629 Valid Epoch Loss: 0.0724, Valid Epoch PixAcc: 0.6472 Valid Epoch mIOU: 0.605104 LR for next epoch: [0.001] -------------------------------------------------- . . . EPOCH: 65 Training 100%|████████████████████| 8/8 [00:10<00:00, 1.37s/it] Validating 100%|████████████████████| 2/2 [00:02<00:00, 1.23s/it] Train Epoch Loss: 0.1205, Train Epoch PixAcc: 0.8438, Train Epoch mIOU: 0.741549 Valid Epoch Loss: 0.0727, Valid Epoch PixAcc: 0.6472 Valid Epoch mIOU: 0.604787 LR for next epoch: [0.0001] -------------------------------------------------- TRAINING COMPLETE
We obtain the best validation IoU of 60.5% on the 49th epoch.
Let’s take a look at the pixel accuracy, mean IoU, and loss graphs.
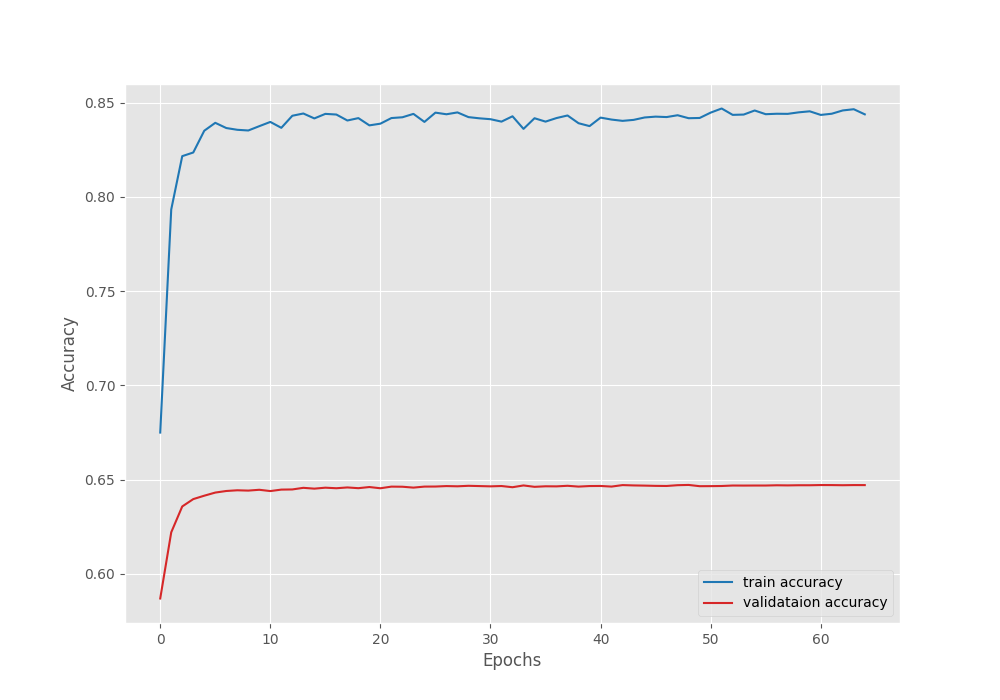
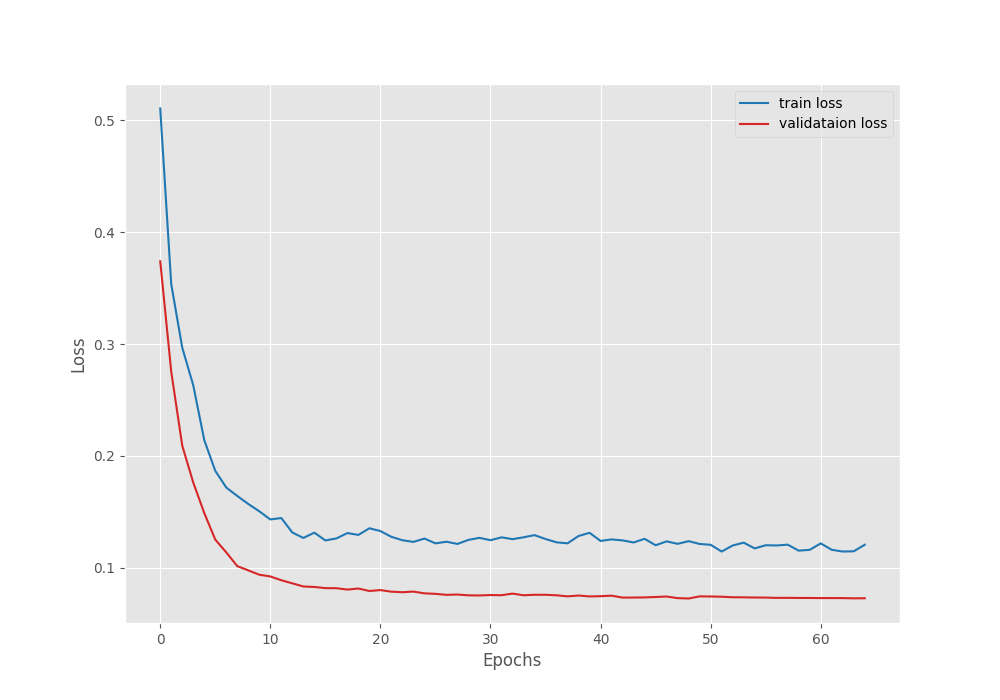
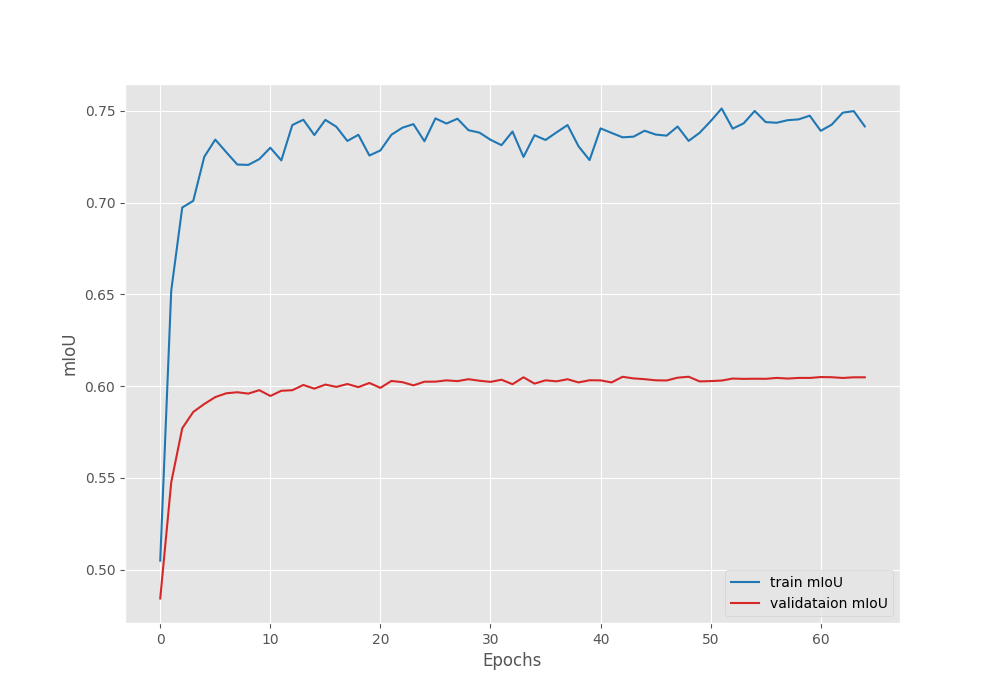
The validation plots plateaued after applying the learning rate scheduler. Although it is subject to experiment, we could train the model for a few more epochs without the scheduler to obtain a slightly higher mean IoU.
Inference on Images
It is quite straightforward to run image inference. All the code for running inference on images is present in infer_image.py file. The script accepts a path to a directory containing images along with other arguments.
python infer_image.py --imgsz 640 640 --model outputs/best_model_iou.pth
The image size is 640×640 which is the same as training and we use the model weights based on the highest IoU.
Following are the results that we get.

The results are not exceptional, just good enough for a first pass of the experiment. In fact, for crowded scenes and persons who appear smaller, the segmentation maps are not good at all.
Inference on Videos
The infer_video.py script contains code to run inference on videos with similar arguments.
python infer_video.py --imgsz 640 640 --model outputs/best_model_iou.pth --input input/inference_data/videos/video_1.mp4
The only difference is that we need to provide the path to the specific video.
Running on an RTX 3070 Ti laptop GPU, we are getting an average of 97 FPS. We can see that the segmentation maps often overlap when the two persons are close.
Here are some other results.
As we can see, the model is struggling primarily with thin structures like hands and legs of the persons.
Let’s take a look at a final difficult scenario.
Just like in images, for crowded and difficult scenarios, the results are not good.
Further Improvements and Analysis
From the above results, we can infer that the current approach “just works OK”. Further, resizing the logits to the original image/frame size makes the segmentation maps too much expanded out of the objects.
We can improve the results with the following changes:
- The simplest one is training the model on more images. This will lead to slightly higher mean IoU and somewhat better segmentation maps. However, it is not enough to obtain results as shown in the demo notebooks in the official repository.
- Applying varying image scale resizing during training will surely lead to better segmentation maps and will solve the issues with finer structures that the model is facing currently. In fact, the authors use this approach in the original training regime.
Summary and Conclusion
In this article, we attempted to train the DINOv2 model on semantic segmentation task. We started with the modification of the DINOv2 backbone and added a pixel classification head on top of it. Furthermore, we explored some of the important dataset preparation code snippets, along with the mask preparation and image resizing logic, training, inference, and analysis of results. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol