
(FlorentinCatargiu/Shutterstock)
Organizations investing in data lakehouses in 2025 may want to check out a new offering unveiled by Onehouse this week. The company founded by the creator of the Apache Hudi table format launched Onehouse Compute Runtime (OCR), which it says enables customers to manage and optimize data lakehouse workloads across multiple cloud platforms, query engines, and open table formats.
We’re in the midst of a building boom for data lakehouses at the moment, largely due to the industry coalescing around the Apache Iceberg table format in mid-2024, which reduced the odds that customer could choose the “wrong” format, thereby stranding their data. The rise of Iceberg would seem to put competing table formats, including Apache Hudi and Databricks Delta Lake, on the backburner. But the folks at Hudi-backer Onehouse see abundant opportunity, and aren’t taking the changes lying down.
While the Hudi-Iceberg comparison is not exactly apples-to-apples (read this story to learn how Hudi was originally designed to solve the fast data issue on Uber’s Hadoop cluster), Onehouse is nevertheless adapting to the reality that Iceberg is positioned to be the dominant table format moving forward. One way it’s doing that is by launching OCR.
OCR gives customers the capability to manage their lakehouse environments across multiple cloud platforms (Databricks, Snowflake, AWS, Google Cloud) that use a variety of query engines (Spark, Redshift, BigQuery, Snowflake) on data stored in multiple table formats (Iceberg, Delta Lake, and Hudi). OCR doesn’t concern itself with the execution of the SQL (or other compute) workloads. Rather, it’s focused on automating some of the less glamorous but necessary maintenance work that lakehouses require.
Onehouse employees Kyle Weller and Rajesh Mahindra explain the emerging situation in a blog post this week:
“Basic read/write support is a commendable start to establishing independence, but new friction points have emerged that challenge storage being interoperable and universal once again: data catalogs, table maintenance, and workload optimizations. Almost every vendor that supports an OTF [open table format] now also offers their own catalog and maintenance, which often restricts which tools can read/write to the tables. To ensure that the control of data remains firmly in the users’ hands, the industry needs not only decentralized storage but also a carefully crafted decentralized compute platform that can perform table maintenance and optimize typical workloads universally across these different cloud data warehouses and vendors.”
Onehouse’s OCR aims to be that decentralized compute platofrm. The offering, which Onehouse launched Tuesday January 14, automatically spins up the required compute resources on various cloud platforms using serverless computing techniques in customers own virtual private cloud (VPC) environments.
OCR’s Spark-based serverless compute manager enables elastic scaling of the lakehouse maintenace workloads, such as data ingestion, table optimization, and ETL operations. This results in a 2x to 30x performance gain at a cost savings of 20% to 80%, the company says. OCR supports multiple formats by utilizing Apache XTable (incubating), the open-source offering that delivers read-write interoperability among Hudi, Delta, and Iceberg table formats. Onehouse donated XTable to Apache.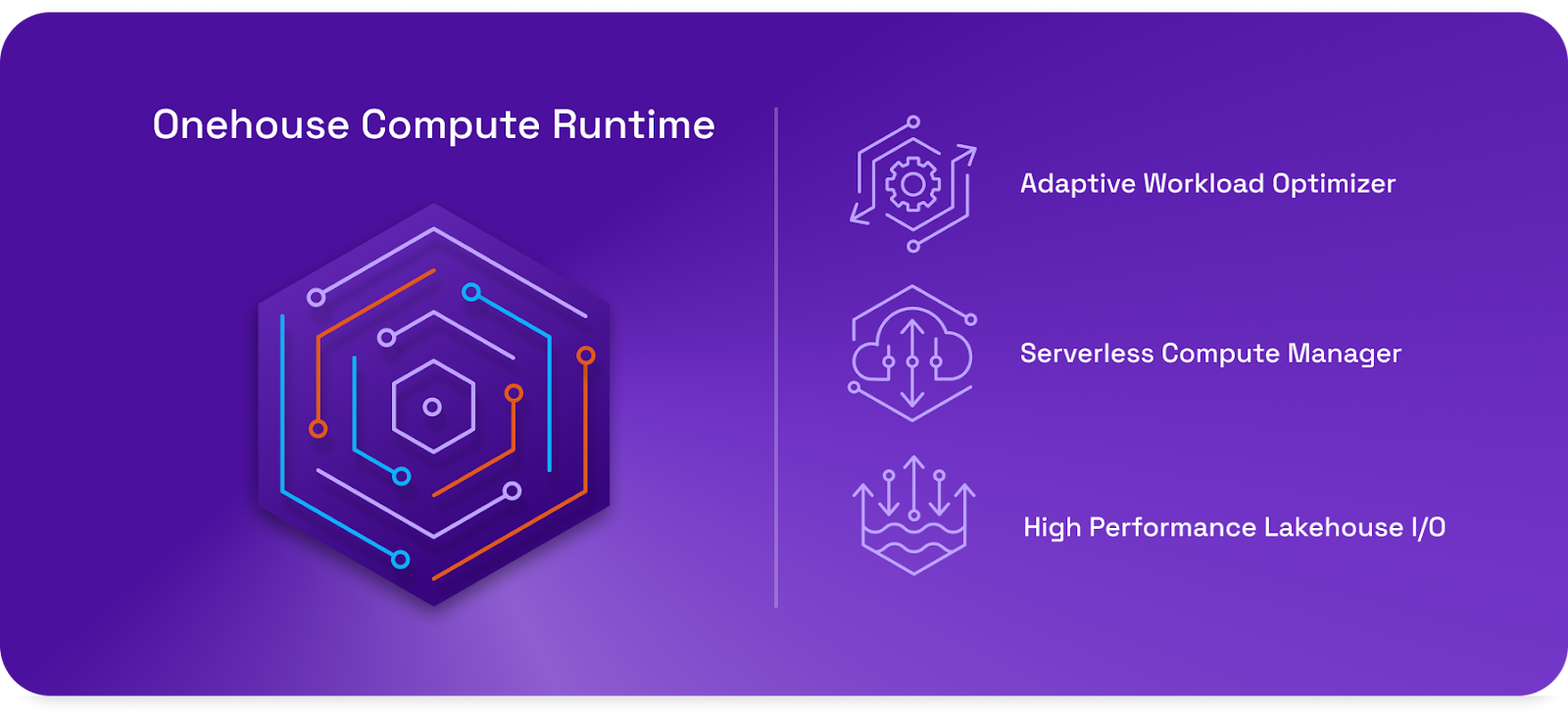
OCR utilizes vectorized columnar merging for fast writes, parallel pipelined execution to maximize CPU efficiency, and optimized storage access to reduce network requests compared to standard open source Parquet readers, the company says.
The goal with OCR is to give customers all the tools they need to take advantage of the growth in lakehouses and openness of table formats, according to Vinoth Chandar, the creator of Hudi and founder and CEO at Onehouse.
“While open table formats have emerged as means to open up data across multiple engines, there is great need for a high-performance compute platform that can transform and optimize data across such engines,” says Chandar, a BigDATAwire 2024 Person to Watch, in a press release. “With OCR, we are delivering all the compute infrastructure and software required to run data lakehouse workloads efficiently. OCR features draw from years of experience powering the largest data lakes in the world using Apache Hudi, widely regarded for its high performance industry-wide. The runtime optimizes all the typical data lakehouse operations centrally once across engines, cutting down redundant compute costs and lock-in points.”
One early adopter of OCR is the digital marketing company Conductor. “Our Onehouse data lakehouse has enabled us to meet the demands of rapid growth while dramatically simplifying our data architecture,” said Emil Emilov, principal software engineer at Conductor. “With automated scaling and resources that adapt to our workloads, Onehouse helps us dedicate our teams to building out our core platform differentiators rather than keeping the data stack continuously optimized.”
Onehouse is hosting a webinar on Thursday, January 23 at 10 a.m. PT to provide more details on OCR. You can register for the webinar here. You can also read Onehouse’s blog on OCR here.
Related Items:
Why Data Lakehouses Are Poised for Major Growth in 2025
How Apache Iceberg Won the Open Table Wars
Apache Hudi Is Not What You Think It Is
Source link
lol