
User feedback has always played a critical role in software applications for two key reasons: evaluating the application’s performance and informing its development. For AI applications, user feedback takes on an even more significant role. It can be used to personalize models and to train future model iterations.
Foundation models enable many new application interfaces, but one that has especially grown in popularity is the conversational interface, such as with chatbots and assistants. The conversational interface makes it easier for users to give feedback but harder for developers to extract signals. This post will discuss what conversational AI feedback looks like and how to design a system to collect the right feedback without hurting user experience.
Individually, each of the points discussed might seem obvious to people working in the field. However, a holistic framework for user feedback isn’t often discussed, and I hope this post will start the conversation.
User feedback is proprietary data, and data is a competitive advantage. A well-designed feedback system is necessary to create a data flywheel. A product that launches quickly and attracts users early can gather data to continually improve its models, making it difficult for competitors to catch up. One key advantage proprietary applications have over open source is that it’s a lot harder to collect user feedback for the latter. Users can deploy your open source application independently and you have no idea how the application is used.
It’s necessary to emphasize that user feedback is user data. Leveraging feedback requires the same cautions needed when leveraging any user data. User privacy should be respected. Users have the right to know how their data is being used.
This post is adapted from the User Feedback section of AI Engineering (2025) with minor edits to make it a standalone post.
Traditionally, feedback can be explicit or* implicit*. Explicit feedback is information users provide in response to explicit requests for feedback, such as thumbs up/thumbs down, upvote/downvote, star rating, or a yes/no answer to the question “Did we solve your problem?”. Explicit feedback is fairly standard across applications—there are only so many ways you can ask a person if they like something. Therefore, explicit feedback is better understood.
Implicit feedback is information inferred from user activities. For example, if someone buys a product recommended to them, it implies that it is a good recommendation. Implicit feedback depends on the actions a user can do within an application and is, therefore, highly application-dependent. Foundation models enable a new world of applications and, with them, many genres of implicit feedback.
The conversational interface that many AI applications use makes it easier for users to give feedback. Users can encourage good behaviors, complain about bad behaviors, and correct errors as part of the dialogues. The instruction that a user gives AI can convey feedback about both the application’s performance and the user’s preference.
Imagine you’re using an AI assistant to help you plan your trip to Australia. You ask the AI to find you a hotel for three nights in Sydney. It responds with three recommendations as follows:
Here are three hotel suggestions in Sydney for a 3-night stay:
1. Historic Rocks Boutique Hotel (The Rocks)
* Price: ~$400/night
* Neighborhood: Charming streets and close to iconic sights.
2. Stylish Surry Hills House Hotel (Surry Hills)
* Price: ~$200/night
* Neighborhood: Trendy, with vibrant cafes and art galleries.
3. Chill Bondi Beachside Hotel (Bondi Beach)
* Price: ~$300/night
* Neighborhood: Beachside, ideal for relaxation and city exploration.
How you respond to these three recommendations reveals your preference. For example, if you respond with "Yes book me the one close to galleries", you show an interest in art. On the other hand, the response "Is there nothing under $200?" reveals a price-conscious preference and suggests that the assistant doesn’t quite get you yet.
User feedback, extracted from conversations, can be used for evaluation, development, and personalization:
- Evaluation: derive metrics to monitor the application
- Development: train the future models or guide their development
- Personalization: personalize the application to each user
Implicit conversational feedback can be inferred from both the content of user messages (natural language feedback) and their communication patterns. Because feedback is blended into dialogues, it’s also challenging to extract. While intuition about conversational cues can help devise an initial set of signals to look for, rigorous data analysis and user studies are necessary. This post will discuss how to extract signals from both natural language feedback and other conversational signals.
Before we continue, it’s worth noting that while conversational feedback has enjoyed greater attention thanks to the popularity of conversational bots, it had been an active research area for years before ChatGPT came out. Many learnings from these studies are applicable to generative AI applications.
- The reinforcement learning community has been trying to get RL algorithms to learn from natural language feedback since the late 2010s, many with promising results (Fu et al., 2019; Goyal, Niekum, and Mooney, 2019; Zhou and Small, 2020; Sumers et al., 2020).
- Natural language feedback is also of great interest for early conversational AI applications such as Amazon Alexa (Ponnusamy et al., 2019; Park et al., 2020), Spotify’s voice control feature (Xiao et al., 2021), and Yahoo! Voice (Hashimoto and Sassano, 2018).
Natural language feedback
Feedback extracted from the content of messages is called natural language feedback. Here are examples of natural language feedback signals that tell you how a conversation is going. It’s useful to track these signals in production to monitor your application’s performance.
Understanding how the application fails is crucial in making it better. For example, if you know that users frequently complain that the outputs are verbose, you can change the application’s prompt to make it more concise. If the user is unhappy because the answer lacks details, you can prompt the bot to be more specific.
Table 1 shows eight groups of natural language feedback resulting from automatically clustering the FITS (Feedback for Interactive Talk & Search) dataset by Yuan, Cho, and Weston (2023).
| Group | Feedback type | Num. | % |
| 1 | Clarify their demand again. | 3702 | 26.54% |
| 2 | Complain that the bot (1) does not answer the question or (2) gives irrelevant information or (3) asks the user to find out the answer on their own. | 2260 | 16.20% |
| 3 | Point out specific search results that can answer the question. | 2255 | 16.17% |
| 4 | Suggest that the bot should use the search results. | 2130 | 15.27% |
| 5 | States that the answer is (1) factually incorrect, or (2) not grounded on the search results. | 1572 | 11.27% |
| 6 | Point out that the bot’s answer is not specific/accurate/complete/detailed. | 1309 | 9.39% |
| 7 | Point out that the bot is not confident in its answers and always begins its responses with “I am not sure” or “I don’t know”. | 582 | 4.17% |
| 8 | Complain about repetition/rudeness in bot responses. | 137 | 0.99% |
Clarification and error correction
If a user starts their follow-up with "No, …" or "I meant, …", the model’s response is likely off the mark.
To correct errors, users might try to rephrase their requests. Figure 1 shows an example of a user’s attempt to correct the model’s misunderstanding. Rephrase attempts can be detected using heuristics or ML models.
Figure 1. Because the user both terminates the generation early and rephrases the question, it can be inferred that the model misunderstood the intention of the original request.
Users can also clarify their requisitions or point out specific things the model should’ve done differently. For example, if the user gives the feedback: "No, summarize the attached PDF, not my message" the model should be able to take this feedback and revise its summary.
This kind of action-correcting feedback is especially common for agentic use cases where users might nudge the agent towards more optional actions. For example, if a user assigns the agent the task of doing market analysis about company XYZ, this user might give feedback such as “You should also check the companys GitHub page” or “Check the CEO’s social media.”
Sometimes, users might want the model to correct itself by asking for explicit confirmation, such as “Are you sure?”, “Check again”, or “Where did you get this from?” This doesn’t necessarily mean that the model gives wrong answers. However, it might mean that your model’s answers lack the details the user is looking for. It can also indicate general distrust in your model.
If your model changes its answer after being questioned, the model might be hallucinating.
In my analysis, clarification and error correction are the most common type of feedback, which is consistent with the findings of Yuan, Cho, and Weston (2023). I’ll be share my analysis when I have a chance, but here are examples of error-correcting feedback from conversations shared on SharedGPT.
"You gave me general advice, though. I need specific advise in evaluating the wording of all of my topic sentences. Please do this.""No, I want to do this programmatically""I mean the code you written""something more short""I think the public_path() there is not correct, I think the function should be base_path()"
Some applications let users edit the model’s responses directly. For example, if a user asks the model to generate code, and the user edits the generated code, it’s a strong signal that the generated code isn’t quite right.
User edits also serve as a valuable source of preference data, which can be used to align a model to human preference. For those not familiar, preference data shows which response, out of two responses, is preferred. It’s typically in the format of (query, winning response, losing response) and often called comparison data. Each user edit makes up a preference example, with the original response being the losing response and the edited response being the winning response.
If the user asks the model to correct itself, then the original response is still the losing response, but the generation after correction is the winning response.
Complaints
Users can complain about the outputs without trying to correct them. For example, they might complain that an answer is wrong, irrelevant, toxic, lengthy, lacking details, or just bad.
Complaints can also be general expressions of negative sentiments (frustration, disappointment, ridicule, etc.) without explaining the reason why, such as "Ugh" or "What?".
In my analysis of ShareGPT conversations in early 2023, I found many angry user messages, which I won’t share because most of them contain variations of f, b, s words. However, angry messages are much less frequent than clarification or error correction messages. It’s likely because back then if someone became frustrated with ChatGPT, they’d simply leave the chat.
However, negative sentiments are much more common with voice assistants. This might sound dystopian, but analysis of a user’s sentiments throughout conversations with a bot might give you insights into how the bot is doing. Some call centers track users’ voices throughout the calls. If a user gets increasingly loud, something is wrong. Conversely, if someone starts a conversation angry but ends happily, the conversation might have resolved their issue.
Natural language feedback can also be inferred from the model’s responses. One important signal is the model’s refusal rate. If a model says things like "Sorry, I don't know that one" or "As a language model, I can't …", the user is probably unhappy.
Communication pattern feedback
There are other types of conversational feedback that can be derived from user actions instead of messages.
Early termination
If a user terminates a response early, e.g., stopping the generation halfway, exiting the app, telling the model to stop (for voice assistants), or simply leaving the agent hanging (e.g., not responding to the agent), it’s likely that the conversation isn’t going well.
Regeneration
Many applications let users generate another response, sometimes with a different model. If a user chooses regeneration, they might find the first response unsatisfying. However, it might be possible that the first response is adequate, but the user wants options to compare. This is especially common with creative requests like image or story generation.
The strength of signals from regeneration depends on whether regeneration costs money. For applications with subscription-based billing, because regeneration doesn’t cost extra, users are more likely to regenerate out of idle curiosity, which doesn’t say much about the first response’s quality.
Personally, I often choose regeneration for complex requests to ensure the model’s responses are consistent. If two responses give contradicting answers, I won’t be able to trust either.
After regeneration, some applications might explicitly ask to compare the new response with the previous one, as shown in Figure 2. This comparison data, again, can be used for preference finetuning.

Figure 2. ChatGPT asks for comparative feedback when a user regenerates another response
Conversation organization and sharing
The actions a user takes to organize their conversations—such as delete, rename, share, and bookmark—can also be signals. Deleting a conversation is a pretty strong signal that the conversation is bad unless it’s an embarrassing conversation and the user wants to remove its trace. Renaming a conversation suggests that the conversation is good, but the auto-generated title is bad.
Side note: As of this writing, because ChatGPT doesn’t yet allow me to star my favorite conversations (Claude does), I manually add [Good] to the beginning of each conversation I like so that I can find it later. Other people might have use the same app differently. That’s why it’s so important to understand your users.
Sharing a conversation can either be a negative or a positive signal. For example, a friend of mine mostly shares conversations when the model has made some glaring mistakes, and another friend mostly shares useful conversations with their coworkers. Again, it’s important to study your users to understand why they do each action.
Adding more signals can help clarify the intent. For example, if the user rephrases their question after sharing a link, it might indicate that the conversation didn’t meet their expectations. Extracting, interpreting, and leveraging implicit responses from conversations is a small but growing area of research.
Conversation length
Another signal that is commonly tracked is the number of turns per conversation. Whether this is a positive or negative signal depends on the application. For AI companions, a long conversation might indicate that the user enjoys the conversation. However, for chatbots geared towards productivity like customer support, a long conversation might indicate that the bot is inefficient in helping users resolve their issues.
Dialogue diversity
Conversation length can also be interpreted together with dialogue diversity, which can be measured by the distinct token or topic count. For example, if the conversation is long but the bot keeps repeating a few lines, the user might be stuck in a loop.
Feedback Design
We discussed what feedback to collect in the last section. This section discusses when and how to collect this valuable feedback.
When to collect feedback
Feedback can and should be collected throughout the user journey. Users should have the option to give feedback, especially to report errors, whenever this need arises. The feedback collection option, however, should be nonintrusive. It shouldn’t interfere with the user workflow. Here are a few places where user feedback might be particularly valuable.
In the beginning
When a user has just signed up, user feedback can help calibrate the application for the user. For example, a face ID app must scan your face first to work. A voice assistant might ask you to read a sentence out loud to recognize your voice for wake words (words that activate a voice assistant, like “Hey Google”). A language learning app might ask you a few questions to gauge your skill level.
For some applications, such as face ID, calibration is necessary. For other applications, however, initial feedback should be optional, as it creates friction for users to try out your product. If a user doesn’t specify their preference, you can fall back to a neutral option and calibrate over time.
When something bad happens
When the model makes a mistake—e.g. hallucinating a response, blocking a legitimate request, or generating a compromising image—users should be able to notify you of these failures.
To address a mistake, you can give users the option to:
- Downvote the response
- Edit the response
- Regenerate with the same model
- Change to another model
- Start the conversation from scratch
Users might just give conversational feedback like "Wrong" or "Too cliche".
Ideally, when your product makes mistakes, users should still be able to accomplish their tasks. For example, if the model wrongly categorizes a product, users can edit the category. Let users collaborate with the AI. If that doesn’t work, let them collaborate with humans. Many customer support bots offer to transfer users to human agents if the conversation drags on or if users seem frustrated.
An example of human–AI collaboration is the inpainting functionality for image generation. If a generated image isn’t exactly what the user needs, they can select a region of the image and describe with a prompt how to make it better. Figure 3 shows an example of inpainting with DALL-E (OpenAI, 2021). This feature allows users to get better results while giving developers high-quality feedback.

Figure 3. An example of how inpainting works in DALL-E
Side note: I wish there were inpainting for text-to-speech. I find text-to-speech works well 95% of the time, but the other 5% can be frustrating. AI might mispronounce a name or fail to pause during dialogues. I wish there were apps that let me edit just the mistakes instead of having to regenerate the whole audio.
When the model has low confidence
When a model is uncertain about an action, you can ask the user for feedback to increase its confidence. For example, given a request to summarize a paper, if the model is uncertain whether the user would prefer a short, high-level summary or a detailed section-by-section summary, the model can output both summaries side by side (assuming that generating two summaries doesn’t increase the latency for the user). The user can choose which one they prefer. An example of comparative evaluation in production is shown in Figure 4.
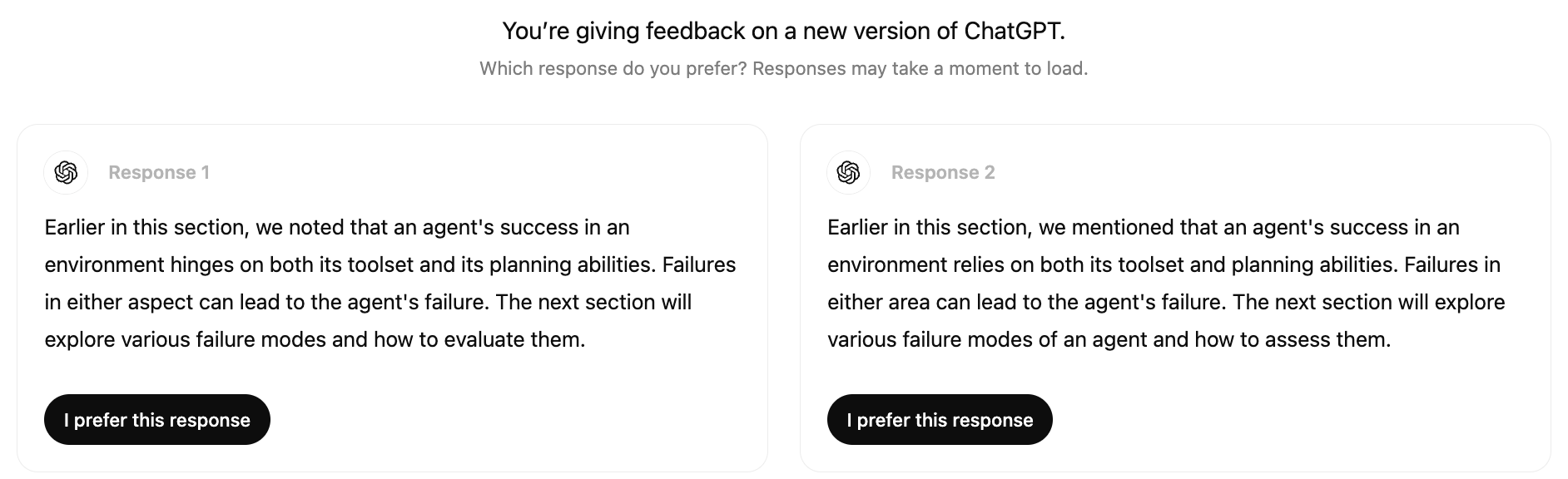
Figure 4. Side-by-side comparison of two ChatGPT responses
Showing two full responses for the user to choose means asking that user for explicit feedback. Users might not have time to read two full responses or care enough to give thoughtful feedback. This can result in noisy votes. Some applications, like Google Gemini, show only the beginning of each response, as shown in Figure 5. Users can click to expand the response they want to read.
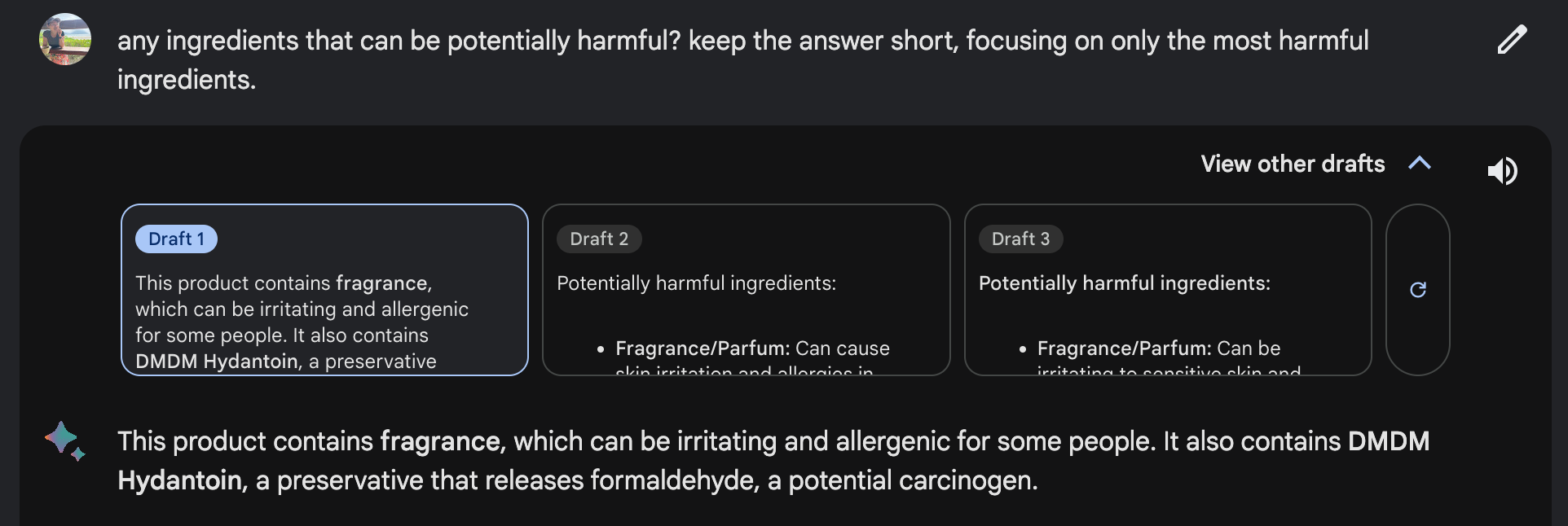
Figure 5. Google Gemini shows partial responses side by side for comparative feedback. Users have to click on the response they want to read more about.
It’s unclear, however, whether showing full or partial responses side by side gives more reliable feedback. When I ask this question at events I speak at, the responses are conflicted. Some people think showing full responses gives more reliable feedback because it gives users more information to make a decision. At the same time, some people think that once users have read full responses, there’s no incentive for them to click on the better one.
Another example is a photo organization application that automatically tags your photos, so that it can respond to queries like “Show me all the photos of X”. When unsure if two people are the same, it can ask you for feedback, as Google Photos does in Figure 6.
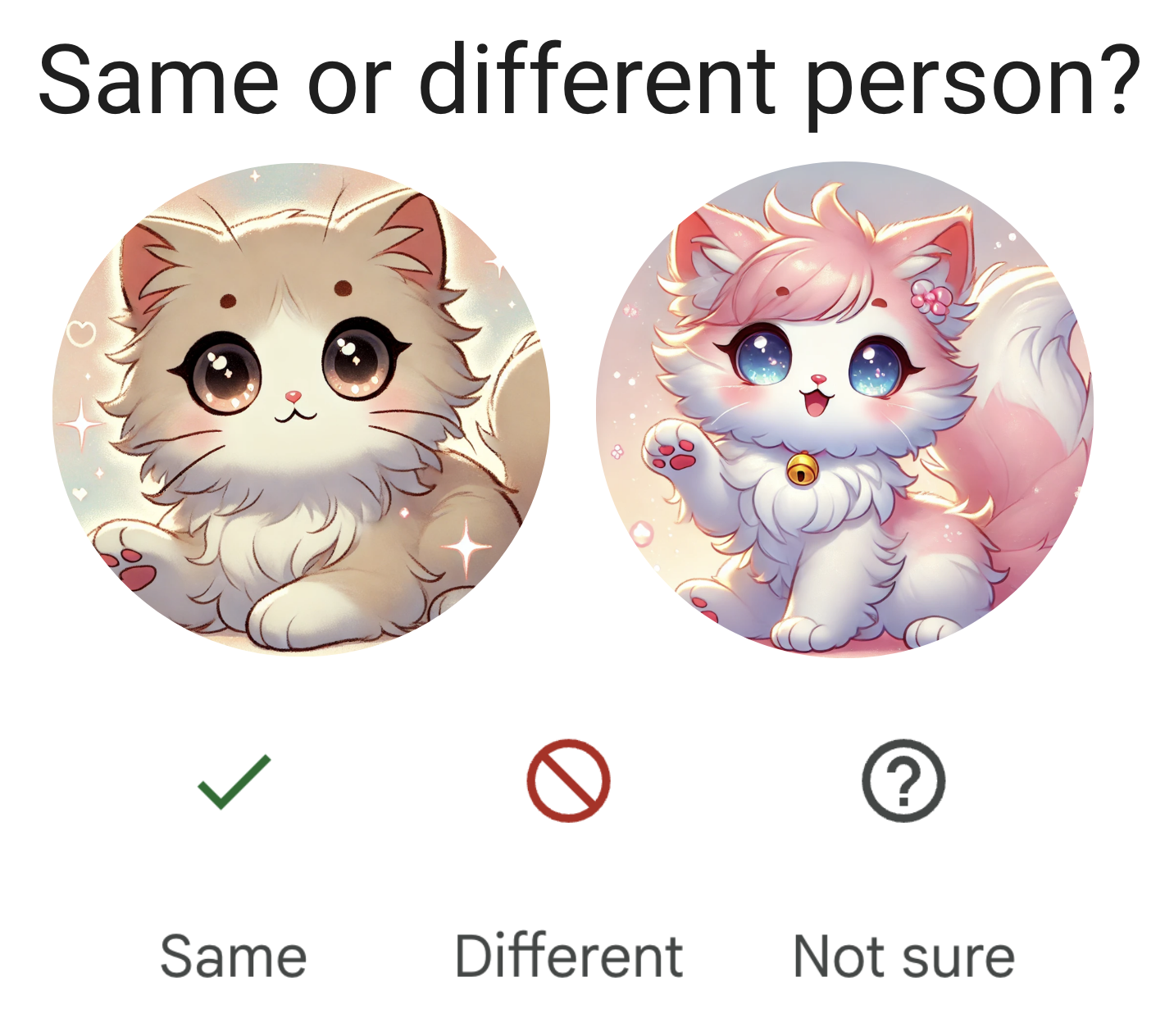
Figure 6. Google Photos asks for user feedback when unsure.
You might wonder: how about feedback when something good happens? Actions that users can take to express their satisfaction include thumbs up, favoriting, or sharing. However, Apple’s human interface guideline warns against asking for both positive and negative feedback. Your application should produce good results by default. Asking for feedback on good results might give users the impression that good results are exceptions. Ultimately, if users are happy, they continue using your application.
However, many people I’ve talked to believe users should have the option to give feedback when they encounter something amazing. A product manager for a popular AI-powered product mentioned that their team needs positive feedback because it reveals the features users love enough to give enthusiastic feedback about. This allows the team to concentrate on refining a small set of high-impact features rather than spreading resources across many with minimal added values.
Some avoid asking for positive feedback out of concern it may clutter the interface or annoy users. However, this risk can be managed by limiting the frequency of feedback requests. For example, if you have a large user base, showing the request to only 1% of users at a time could help gather sufficient feedback without disrupting the experience for most users. Keep in mind that the smaller the percentage of users asked, the greater the risk of feedback biases. Still, with a large enough pool, the feedback can provide meaningful product insights.
How to collect feedback
Feedback should seamlessly integrate into the user’s workflow. It should be easy for users to provide feedback without extra work. Feedback collection shouldn’t disrupt user experience and be easy to ignore. There should be incentives for users to give good feedback.
One example often cited as good feedback design is from the image generator app Midjourney. For each prompt, Midjourney generates a set of (four) images and gives the user the following options, as shown in Figure 7.
- Generate an unscaled version of any of these images.
- Generate variations for any of these images.
- Regenerate.

Figure 7. Midjourney’s workflow allows the app to collect implicit feedback
All these options give Midjourney different signals.
- Options 1 and 2 tell Midjourney which of the four photos is considered by the user to be the most promising. Option 1 gives the strongest positive signal about the chosen photo. Option 2 gives a weaker positive signal.
- Option 3 signals that none of the photos is good enough. However, users might choose to regenerate even if the existing photos are good just to see what else is possible.
Code assistants like GitHub Copilot might show their drafts in lighter colors than the final texts, as shown in Figure 8. Users can use the Tab key to accept a suggestion or simply continue typing to ignore the suggestion, both providing feedback.
Figure 8: GitHub Copilot makes it easy to both suggest and reject a suggestion
One of the biggest challenges of standalone AI applications like ChatGPT and Claude is that they aren’t integrated into the user’s daily workflow, making it hard to collect high-quality feedback the way integrated products like GitHub Copilot can. For example, if Gmail suggests an email draft, Gmail can track how this draft is used or edited. However, if you use ChatGPT to write an email, ChatGPT doesn’t know whether the generated email is actually sent.
The feedback alone might be helpful for product analytics. For example, thumbs up/down information is sufficient for calculating how often people are happy or unhappy with your product. For deeper analysis, you would need context around the feedback, such as the previous 5 to 10 dialogue turns. This context can help you figure out what went wrong. However, getting this context might not be possible without explicit user consent, especially if the context might contain personally identifiable information.
For this reason, some products include terms in their service agreements that allow them to access user data for analytics and product improvement. For applications without such terms, user feedback might be tied to a user data donation flow, where users are asked to donate (e.g., share) their recent interaction data along with their feedback. For example, when submitting feedback, you might be asked to check a box to share your recent data as context for this feedback.
Explaining to users how their feedback is used can motivate them to give more and better feedback. Do you use a user’s feedback to personalize the product to this user, to collect statistics about general usage, or to train a new model? If users are concerned about privacy, reassure them that their data won’t be used to train models or won’t leave their device (only if these are true).
Don’t ask users to do the impossible. For example, if you collect comparative signals from users, don’t ask them to choose between two options they don’t understand. For example, I was once stumped when ChatGPT asked me to choose between two possible answers to a statistical question, as shown in Figure 9. I wish there were an option for me to say, “I don’t know.”
Figure 9. An example of ChatGPT asking a user to select the response the user prefers. However, for mathematical questions like this, the right answer shouldn’t be a matter of preference.
Add icons and tooltips to an option if they help people understand it. Avoid a design that can confuse users. Ambiguous instructions can lead to noisy feedback. I once hosted a GPU optimization workshop, using Luma to collect feedback. When I was reading the negative feedback, I was confused. Even though the responses were positive, the star ratings were 1/5. When I dug deeper, I realized that Luma used emojis to represent numbers in their feedback collection form, but the angry emoji, corresponding to a one-star rating, was put where the five-star rating should be, as shown in Figure 10.
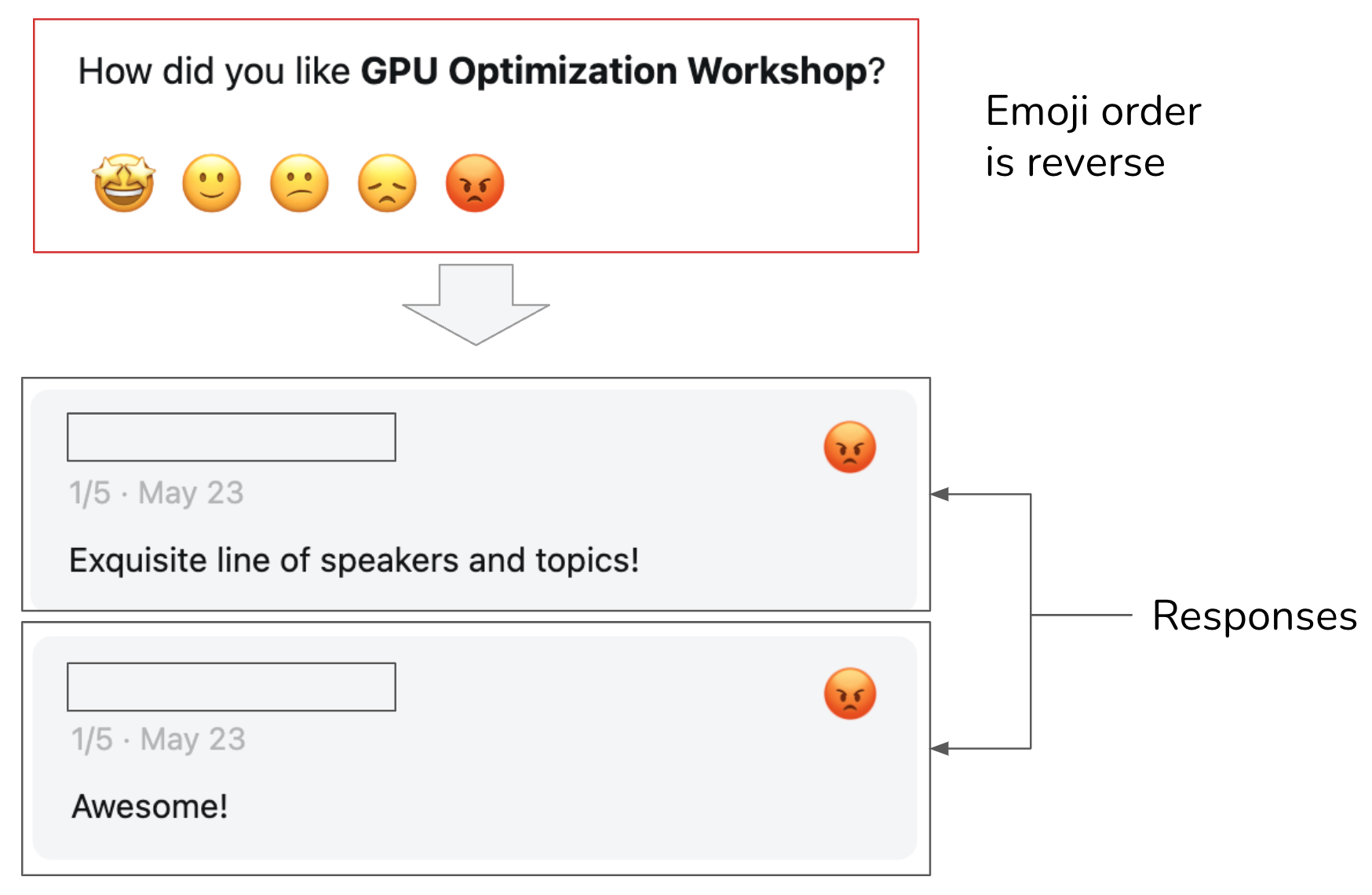
Figure 10. Because Luma put the angry emoji, corresponding to a 1-star rating, where a 5-star rating should’ve been, some users mistakenly picked it for positive reviews.
Be mindful of whether you want users’ feedback to be private or public. For example, if a user likes something, do you want this information shown to other users? In its early days, Midjourney’s feedback—someone choosing to upscale an image, generate variations, or regenerate another batch of images—was public.
The visibility of a signal can profoundly impact user behavior, user experience, and the quality of the feedback. Users tend to be more candid in private—there’s a lower chance of their activities being judged—which can result in higher-quality signals (See “Ted Cruz Blames Staffer for ‘Liking’ Porn Tweet” and “Kentucky Senator Whose Twitter Account ‘Liked’ Obscene Tweets Says He Was Hacked”). In 2024, X made “likes” private. Elon Musk claimed a significant uptick in the number of likes after this change.
However, private signals can reduce discoverability and explainability. For example, hiding likes prevents users from finding tweets their connections have liked. If X recommends tweets based on the likes of the people you follow, hiding likes could result in users’ confusion about why certain tweets appear in their feeds.
Feedback Limitations
There’s no doubt of the value of user feedback to an application developer. However, feedback isn’t a free lunch. It comes with its own limitations.
Biases
Like any other data, user feedback has biases. It’s important to understand these biases and design your feedback system around them. Each application has its own biases. Here are a few examples of feedback biases to give you an idea of what to look out for:
Leniency bias
Leniency bias is the tendency for people to rate items more positively than warranted, often to avoid conflict because they feel compelled to be nice or because it’s the easiest option. Imagine you’re in a hurry, and an app asks you to rate a transaction. You aren’t happy with the transaction, but you know that if you rate it negatively, you’ll be asked to provide reasons, so you just choose positive to be done with it. This is also why you shouldn’t make people do extra work for your feedback.
On a 5-star rating scale, 4 and 5 stars are typically meant to indicate a good experience. However, in many cases, users may feel pressured to give 5-star ratings, reserving 4 stars for when something goes wrong. According to Uber, in 2015, the average driver’s rating was 4.8, with scores below 4.6 putting drivers at risk of being deactivated.
This bias isn’t necessarily a dealbreaker. Uber’s goal is to differentiate good drivers from bad drivers. Even with this bias, their rating system seems to help them achieve this goal. It’s essential to look at the distribution of your user ratings to detect this bias.
If you want more granular feedback, removing the strong negative connotation associated with low ratings can help people break out of this bias. For example, instead of showing users numbers 5 to 1, show users options such as the following.
- “Great ride. Great driver.”
- “Nothing to complain about but nothing stellar either.”
- “Could’ve been better.”
- “Don’t match me with this driver again.”
- “I’d rather walk next time.”
The options suggested here are only to show how options can be rewritten. They haven’t been validated. Personally, I think a 3-option scale might be sufficient.
Randomness
Users often provide random feedback, not out of malice, but because they lack motivation to give more thoughtful input. For example, when two long responses are shown side by side for comparative evaluation, users might not read them and just click on one at random. In the case of Midjourney, users might also randomly choose one image to generate variations.
Position bias
The position in which an option is presented to users influences how this option is perceived. Users are generally more likely to click on the first suggestion than the second. This means that if a user clicks on the first suggestion, this doesn’t necessarily mean that it’s a good suggestion.
When designing your feedback system, this bias can be mitigated by randomly varying the positions of your suggestions or by building a model to compute a suggestion’s true success rate based on its position.
Preference bias
There are many other biases that can affect a person’s feedback, some of which have been discussed in this book. For example, people might prefer the longer response in a side-by-side comparison, even if the longer response is less accurate—length is easier to notice than inaccuracies. Another bias is recency bias, where people tend to favor the answer they see last when comparing two answers.
It’s important to inspect your user feedback to uncover its biases. Understanding these biases will help you interpret the feedback correctly, avoiding misleading product decisions.
Degenerate feedback loop
When using user feedback, keep in mind that user feedback is incomplete. You only get feedback on what you show users.
In a system where user feedback is used to modify a model’s behavior, degenerate feedback loops can arise. A degenerate feedback loop can happen when the predictions themselves influence the feedback, which, in turn, influences the next iteration of the model, amplifying initial biases.
Imagine you’re building a system to recommend videos. The videos that rank higher show up first, so they get more clicks, reinforcing the system’s belief that they’re the best picks. Initially, the difference between the two videos, A and B, might be minor, but because A was ranked slightly higher, it got more clicks, and the system kept boosting it. Over time, A’s ranking soared, leaving B behind. This feedback loop is why popular videos stay popular, making it tough for new ones to break through. This issue is known as “exposure bias,” “popularity bias,” or “filter bubbles,” and it’s a well-studied problem.
A degenerate feedback loop can alter your product’s focus and use base. Imagine that initially, a small number of users give feedback that they like cat photos. The system picks up on this and starts generating more photos with cats. This attracts cat lovers, who give more feedback that cat photos are good, encouraging the system to generate even more cats. Before long, your application becomes a cat haven. Here, I use cat photos as an example, but the same mechanism can amplify other biases, such as racism, sexism, and preference for explicit content.
Acting on user feedback can also turn a conversational agent into, for lack of a better word, a liar. Multiple studies have shown that training a model on user feedback can teach it to give users what it thinks users want, even if that isn’t what’s most accurate or beneficial (Stray, 2023). Sharma et al. (2023) show that AI models trained on human feedback tend towards sycophancy. They are more likely to present user responses matching this user’s view.
User feedback is crucial for improving user experience, but if used indiscriminately, it can perpetuate biases and destroy your product. Before incorporating feedback into your product, make sure that you understand the limitations of this feedback and its potential impact.
Conclusion
The post is long but not long enough for me to go into the depth I’d like with feedback design for AI applications. I also haven’t covered how to use the extracted signals to train models or generate product analytics. However, I hope that this post covers what conversational feedback is, why it’s important, and an overview of how to design a feedback system. I’ll try to follow up with more specific examples of actual feedback in applications and how to use feedback.
User feedback has always been invaluable for guiding product development, but for AI applications, user feedback has an even more crucial role as a data source for improving models. At the same time, the conversational interface enables new types of user feedback, which you can leverage for analytics, product improvement, and the data flywheel.
Traditionally, user feedback design has been seen as a product responsibility rather than an engineering one, and as a result, it is often overlooked by engineers. However, since user feedback is a crucial source of data for continuously improving AI models, more AI engineers are now becoming involved in the process to ensure they receive the data they need. This reinforces the idea that, compared to traditional ML engineering, AI engineering is moving closer to product. This is because of both the increasing importance of data flywheel and product experience as competitive advantages.
Source link
lol