
The field of computer vision is experiencing an increase in foundation models, similar to those in natural language processing (NLP). These models aim to produce general-purpose visual features that we can apply across various image distributions and tasks without the need for fine-tuning. The recent success of unsupervised learning in NLP pushed the way for similar advancements in computer vision. This article covers DINOv2, an approach that leverages self-supervised learning to generate robust visual features.
The DINOv2 Framework
In this section we will cover, various components of the DINOv2 framework including the model architecture, datasets, and results.
The DINOv2 Architecture
The DINOv2 models come in 4 different sizes and architectures.
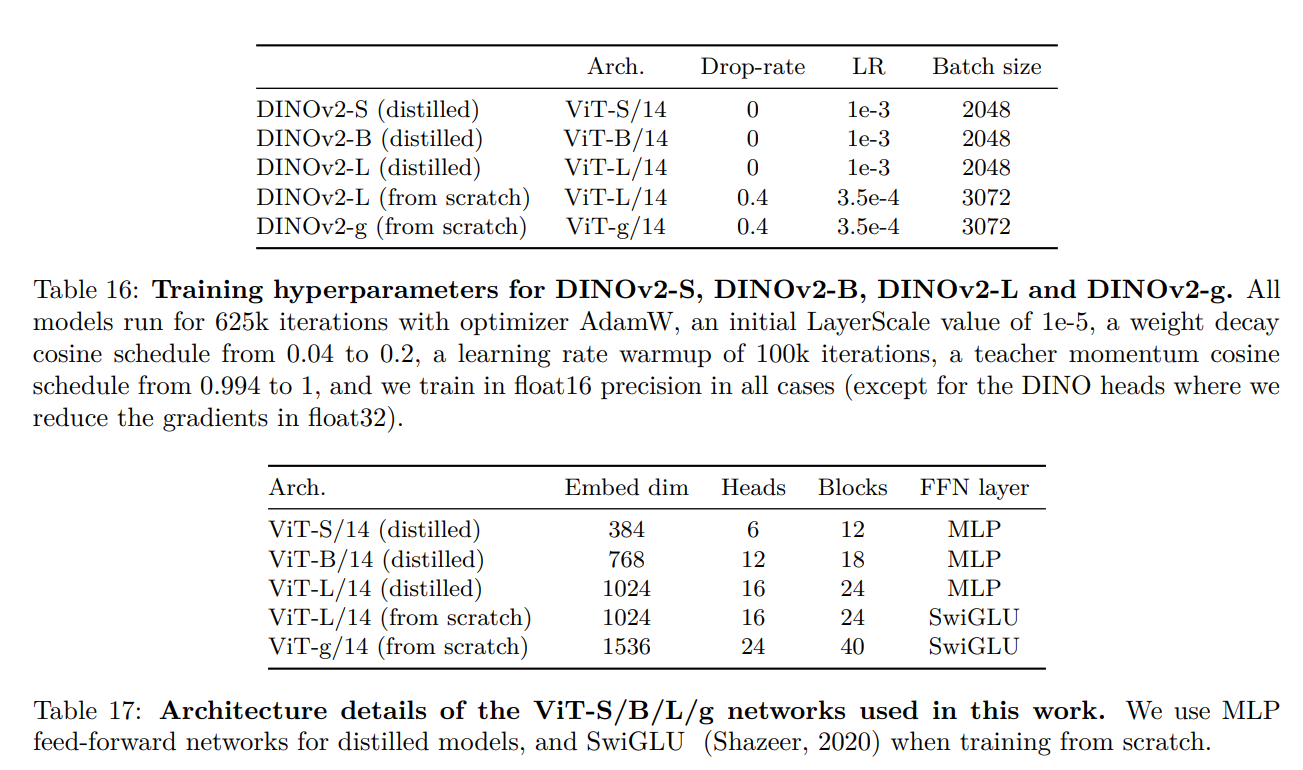
All the models are based on a slightly modified version of the original Vision Transformer (ViT) model.
- ViT-S/14 (Distilled): This model has 384 embedding dimensions, 6 heads, and 12 blocks. It is designed for lightweight applications and is distilled from larger models to maintain high performance with reduced complexity.
- ViT-B/14 (Distilled): With 768 embedding dimensions, 12 heads, and 18 blocks, this model offers a balance between performance and computational efficiency.
- ViT-L/14 (Distilled): This larger model has 1024 embedding dimensions, 16 heads, and 24 blocks. It provides enhanced performance at the cost of increased computational resources.
- ViT-L/14 (From Scratch): Similar to the distilled version but trained from scratch, this model uses SwiGLU feed-forward networks for improved feature extraction.
- ViT-g/14 (From Scratch): The largest model in the DINOv2 family, with 1536 embedding dimensions, 24 heads, and 40 blocks. It is optimized for high-performance applications and is the primary model used for knowledge distillation.
The DINOv2 Small and Base models are never trained from scratch by the authors. They are distilled from the DINOv2 Giant model.
Data Processing and Curation
One of the key innovations of DINOv2 is its sophisticated data processing pipeline. The authors have developed an automated system to filter and rebalance datasets from a vast collection of uncurated images. This pipeline, inspired by NLP data curation methods, uses data similarities instead of external metadata, eliminating the need for manual annotation. The resulting dataset, LVD-142M, comprises 142 million diverse images, carefully curated to ensure high-quality features.
Discriminative Self-Supervised Pre-Training
DINOv2 employs a discriminative self-supervised method that combines elements from DINO and iBOT losses, along with the centering technique from SwAV. This approach is designed to stabilize and accelerate training, especially when scaling to larger models and datasets. The training process includes several technical improvements, such as the KoLeo regularizer and a short high-resolution training phase, which enhance the model’s performance and robustness.
Efficient Implementation
The implementation of DINOv2 includes several optimizations to handle the computational demands of training large models. These include a custom version of FlashAttention, sequence packing, and an improved version of stochastic depth. Additionally, the use of Fully-Sharded Data Parallel (FSDP) significantly reduces memory footprint and communication costs, enabling efficient scaling across multiple GPUs.
I highly recommend going through Section 5 of the paper which covers the efficient implementation of the training and modeling pipeline in detail.
Ablation Studies and Empirical Validation
Training Recipe Improvements
The authors conducted extensive ablation studies to validate the effectiveness of each component in their training recipe. These studies showed that each modification, such as LayerScale, Stochastic Depth, and the KoLeo regularizer improved performance on various benchmarks. The results were consistent across different model sizes and datasets, demonstrating the robustness of the DINOv2 approach.
Pretraining Data Source
The quality of the pretraining data is crucial for the performance of visual features. The ablation study comparing LVD-142M with ImageNet-22k and uncurated data reveals that curated data significantly outperforms uncurated data. Training on LVD-142M led to superior performance across multiple benchmarks, highlighting the importance of data diversity and quality.
The authors created the uncurated data by randomly sampling 142 million images from the same source as LVD-142M.
Model Size and Data Scaling
The study on model size versus data scale showed that as models grow larger, training on LVD-142M becomes increasingly beneficial compared to ImageNet-22k. This points towards the benefits of scaling models and data when carrying out self-supervised training.
Loss Components
The ablation of specific loss terms, such as the KoLeo loss and the masked image modeling term, provided insights into their individual contributions. The KoLeo loss improved nearest-neighbor search tasks, while the masked image modeling term (from iBOT) enhanced dense prediction tasks like segmentation.

Knowledge Distillation
For smaller models, DINOv2 employs a knowledge distillation process, where smaller models are trained to mimic the output of larger models.
The results show that smaller distilled models outperform those trained from scratch on various benchmarks. The distillation process ensures that smaller models benefit from the performance of larger models.

Results and Benchmarks
ImageNet Classification
Compared to previous approaches, DINOv2 demonstrates improved performance on the ImageNet-1k classification dataset. The model achieves top-1 accuracy improvements of over 4% compared to iBOT.
Additionally, the features show better generalization on alternative test sets like ImageNet-Real and ImageNet-V2, indicating stronger robustness.
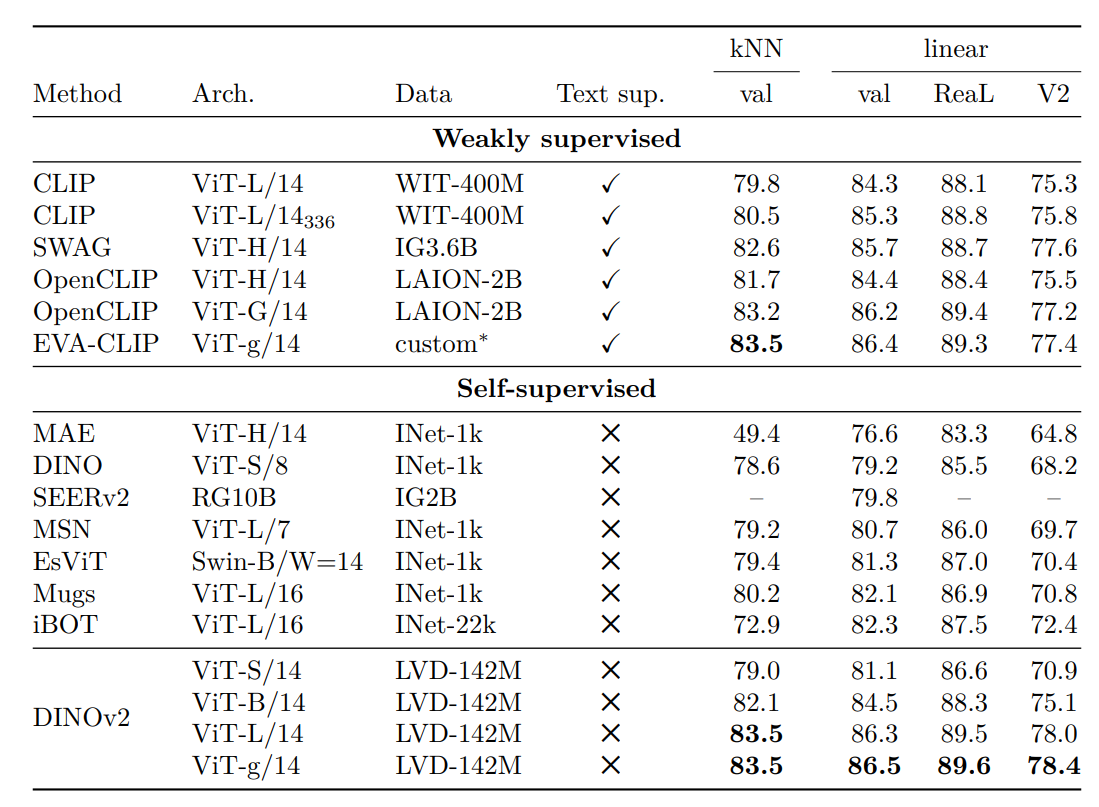
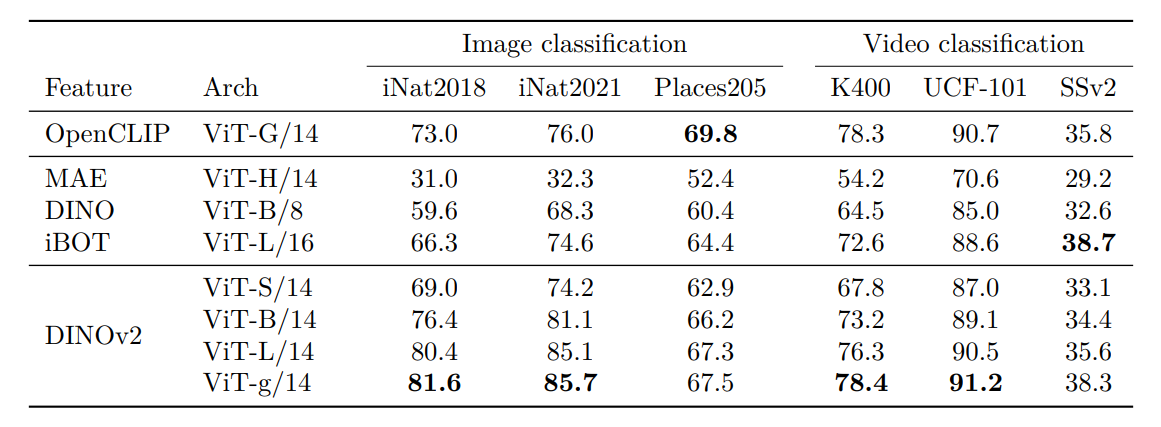
Image and Video Classification
The authors evaluate DINOv2 features on several image and video classification benchmarks, including iNaturalist, Places205, UCF-101, Kinetics-400, and Something-Something v2.
The models outperform existing self-supervised methods and were competitive with weakly-supervised models.
Instance Recognition
The instance-level recognition consists of tasks such as landmark recognition and artwork retrieval. DINOv2 models achieve significant improvements in mean average precision (mAP) across multiple benchmarks, demonstrating their effectiveness in both category-level and instance-level recognition tasks.
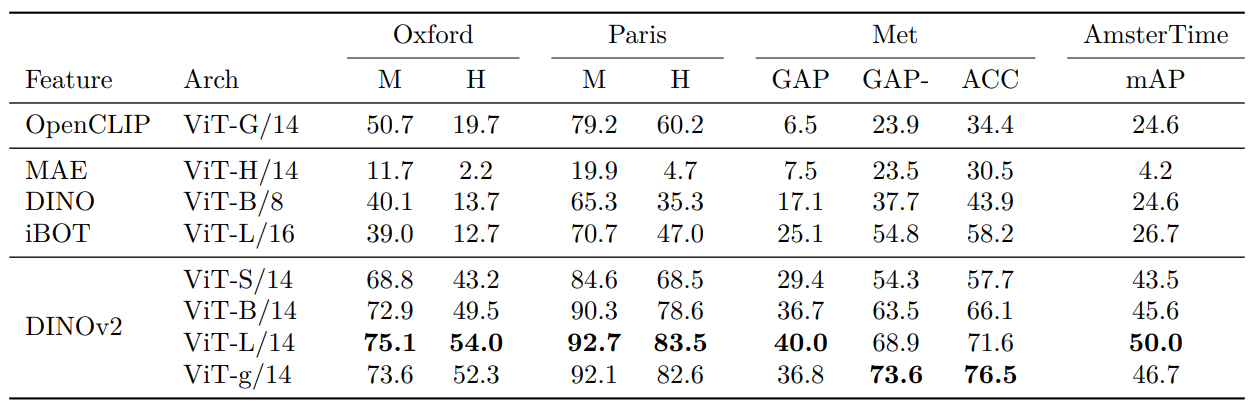
Given today’s real-world tasks, where RAG applications have become important, the features from DINOv2 can be used for image embedding search.
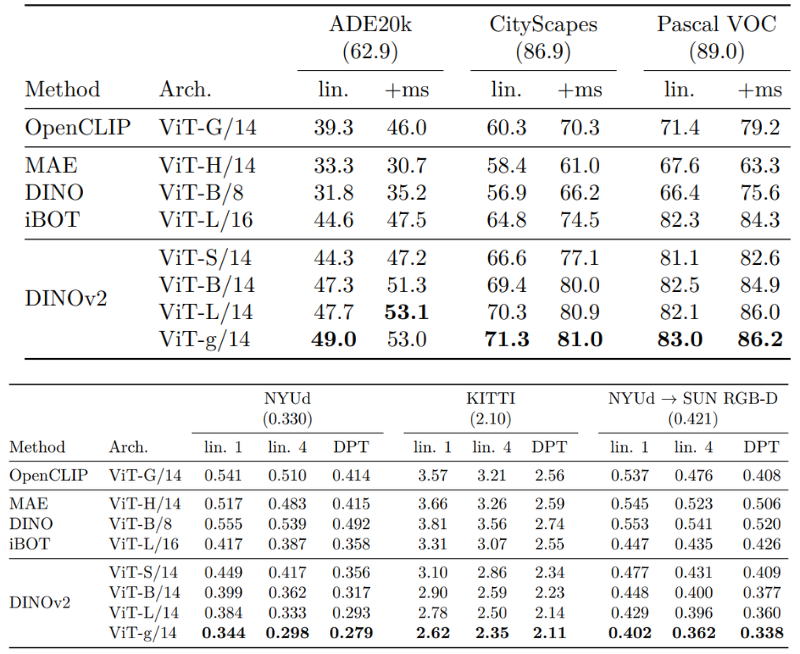
Semantic Segmentation and Depth Estimation
Because of the robust self-supervised pretraining, DINOv2 features also perform well on dense prediction tasks like semantic segmentation and depth estimation.
Compared to previous architectures and training regimes, DINOv2 models perform better on datasets like ADE20k, Cityscapes, and NYU Depth V2.
Qualitative Results
Semantic Segmentation and Depth Estimation
Qualitative results from semantic segmentation and depth estimation tasks illustrate the effectiveness of DINOv2 features. The segmentation masks produced by the linear classifier were more accurate compared to OpenCLIP. Similarly, the depth estimation results were smoother and more precise.

Furthermore, the segmentation and depth estimation results on out-of-distribution samples such as paintings and sketches support the evidence that the DINOv2’s robust features transfer between domains.
PCA of Patch Features
The principal component analysis (PCA) of patch features reveals that DINOv2 can effectively separate foreground objects from backgrounds and match parts of objects across different images.
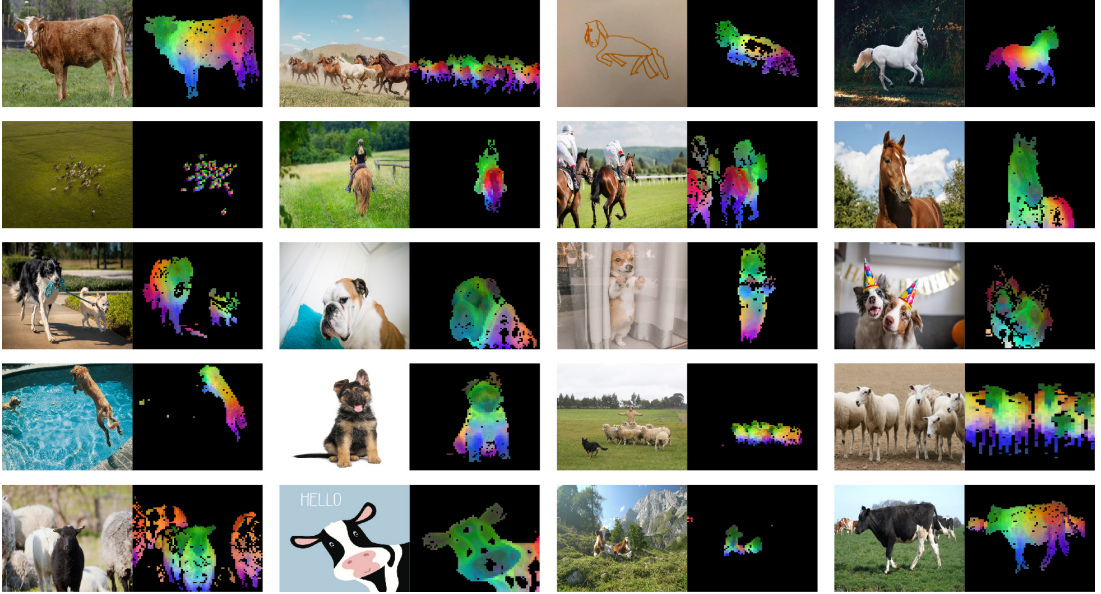
This can be considered an emergent property as DINOv2 was not explicitly trained to parse parts of objects.
Patch Matching
The patch matching experiments demonstrated the model’s ability to capture semantic regions and match them across different images.

Such properties can be used for image retrieval under complex and varied conditions.
Fairness and Bias
Bias has been a hot topic in the world of AI for years now. Under-represented communities, countries, and geographies often mislead models to give biased answers. DINOv2, although a step forward in the direction, is still not perfect.
Geographical Fairness
The evaluation of geographical fairness on the Dollar Street dataset showed that DINOv2 models are slightly fairer across regions and income levels compared to previous methods. However, significant performance differences were observed, particularly in Africa, indicating a bias toward Western countries.

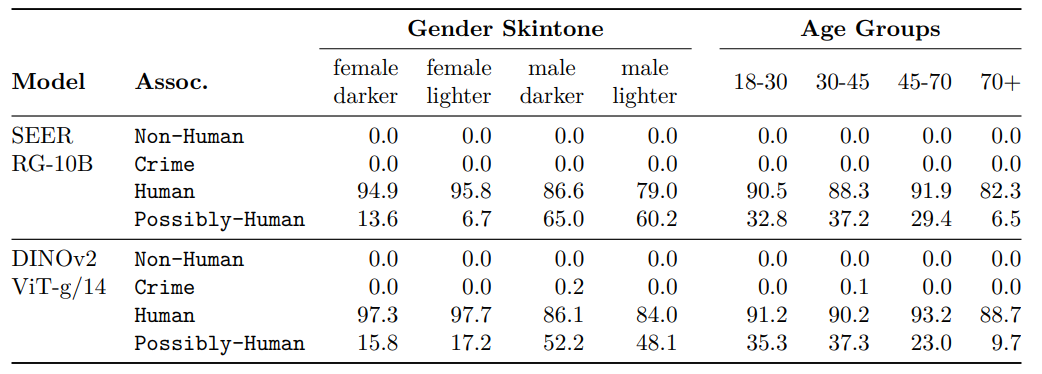
Gender, Skintones, and Age
The analysis of label associations across gender, skin tones, and age groups revealed that DINOv2 models often classify images as “Human” without significant deviations across groups. The models rarely predicted harmful labels, suggesting a lack of clear bias against specific groups.
Conclusion
DINOv2 has demonstrated the potential of self-supervised learning to produce general-purpose visual features that are competitive with weakly-supervised models. The model’s robust performance across various tasks, combined with its efficient implementation and low carbon footprint, makes it a valuable tool for the computer vision community. As research in this area progresses, we can expect to see even more sophisticated models that push the boundaries of what is possible with unsupervised visual feature learning.
References
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol