
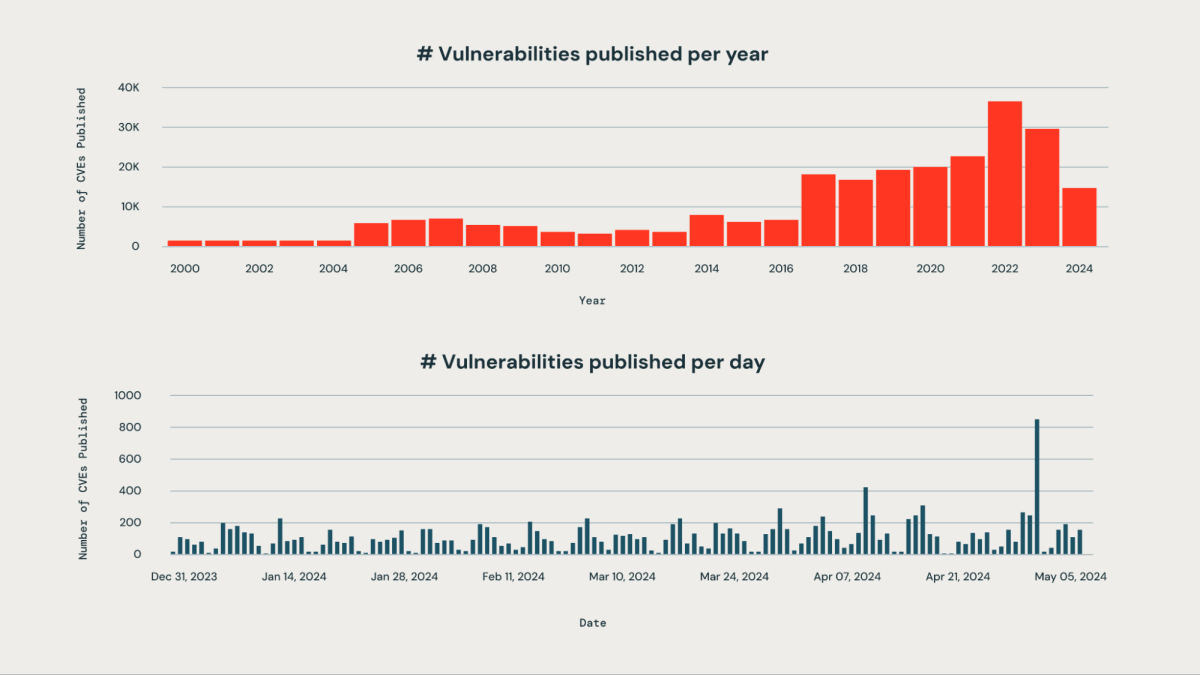
Every organization is challenged with correctly prioritizing new vulnerabilities that affect a large set of third-party libraries used within their organization. The sheer volume of vulnerabilities published daily makes manual monitoring impractical and resource-intensive.
At Databricks, one of our company objectives is to secure our Data Intelligence Platform. Our engineering team has designed an AI-based system that can proactively detect, classify, and prioritize vulnerabilities as soon as they are disclosed, based on their severity, potential impact, and relevance to Databricks infrastructure. This approach enables us to effectively mitigate the risk of critical vulnerabilities remaining unnoticed. Our system achieves an accuracy rate of approximately 85% in identifying business-critical vulnerabilities. By leveraging our prioritization algorithm, the security team has significantly reduced their manual workload by over 95%. They are now able to focus their attention on the 5% of vulnerabilities that require immediate action, rather than sifting through hundreds of issues.
{kind=link}
In the next few steps, we are going to explore how our AI-driven approach helps identify, categorize and rank vulnerabilities.
How Our System Continuously Flags Vulnerabilities
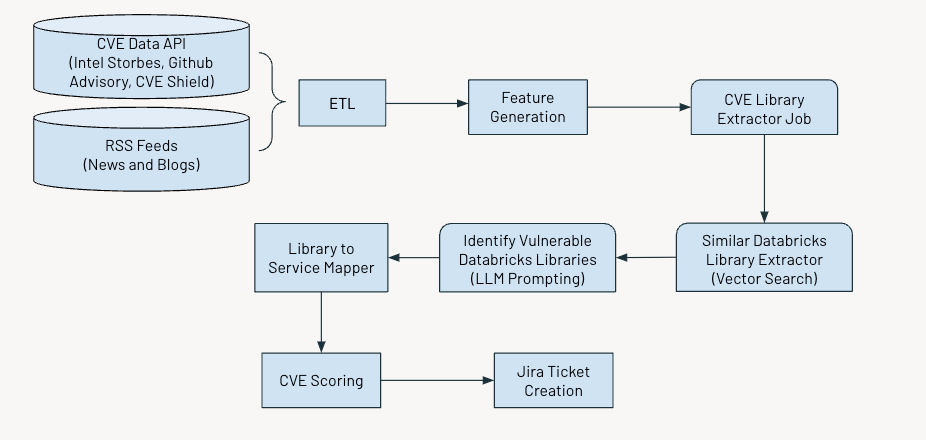
The system operates on a regular schedule to identify and flag critical vulnerabilities. The process involves several key steps:
- Gathering and processing data
- Generating relevant features
- Utilizing AI to extract information about Common Vulnerabilities and Exposures (CVEs)
- Assessing and scoring vulnerabilities based on their severity
- Generating Jira tickets for further action.
The figure below shows the overall workflow.
Data Ingestion
We ingest Common Vulnerabilities and Exposures (CVE) data, which identifies publicly disclosed cybersecurity vulnerabilities from multiple sources such as:
- Intel Strobes API: This provides information and details on the software packages and versions.
- GitHub Advisory Database: In most cases, when vulnerabilities are not recorded as CVE, they appear as Github advisories.
- CVE Shield: This provides the trending vulnerability data from the recent social media feeds
Additionally, we gather RSS feeds from sources like securityaffairs and hackernews and other news articles and blogs that mention cybersecurity vulnerabilities.
Feature Generation
Next, we will extract the following features for each CVE:
- Description
- Age of CVE
- CVSS score (Common Vulnerability Scoring System)
- EPSS score (Exploit Prediction Scoring System)
- Impact score
- Availability of exploit
- Availability of patch
- Trending status on X
- Number of advisories
While the CVSS and EPSS scores provide valuable insights into the severity and exploitability of vulnerabilities, they may not fully apply for prioritization in certain contexts.
The CVSS score does not fully capture an organization’s specific context or environment, meaning that a vulnerability with a high CVSS score might not be as critical if the affected component is not in use or is adequately mitigated by other security measures.
Similarly, the EPSS score estimates the probability of exploitation but doesn’t account for an organization’s specific infrastructure or security posture. Therefore, a high EPSS score might indicate a vulnerability that is likely to be exploited in general. However, it might still be irrelevant if the affected systems are not part of the organization’s attack surface on the internet.
Relying solely on CVSS and EPSS scores can lead to a deluge of high-priority alerts, making managing and prioritizing them challenging.
Scoring Vulnerabilities
We developed an ensemble of scores based on the above features – severity score, component score and topic score – to prioritize CVEs, the details of which are given below.
Severity Score
This score helps to quantify the importance of CVE to the broader community. We calculate the score as a weighted average of the CVSS, EPSS, and Impact scores. The data input from CVE Shield and other news feeds enables us to gauge how the security community and our peer companies perceive the impact of any given CVE. This score’s high value corresponds to CVEs deemed critical to the community and our organization.
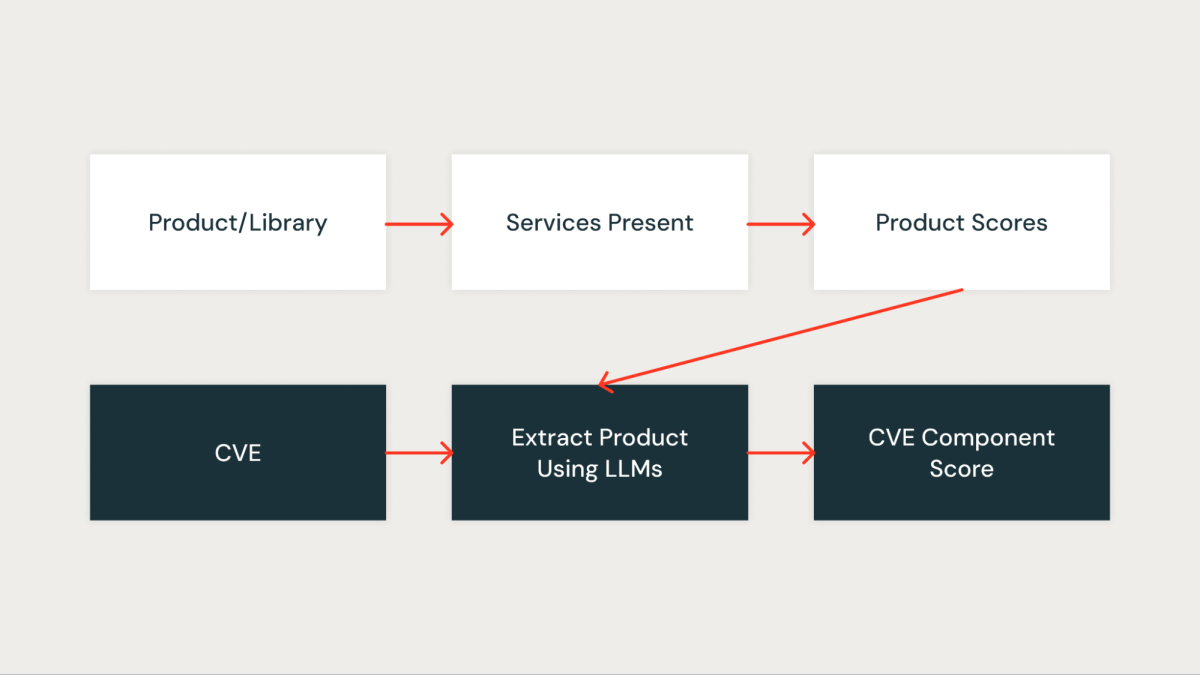
Component Score
This score quantitatively measures how important the CVE is to our organization. Every library in the organization is first assigned a score based on the services impacted by the library. A library that is present in critical services gets a higher score, while a library that is present in non-critical services gets a lower score.
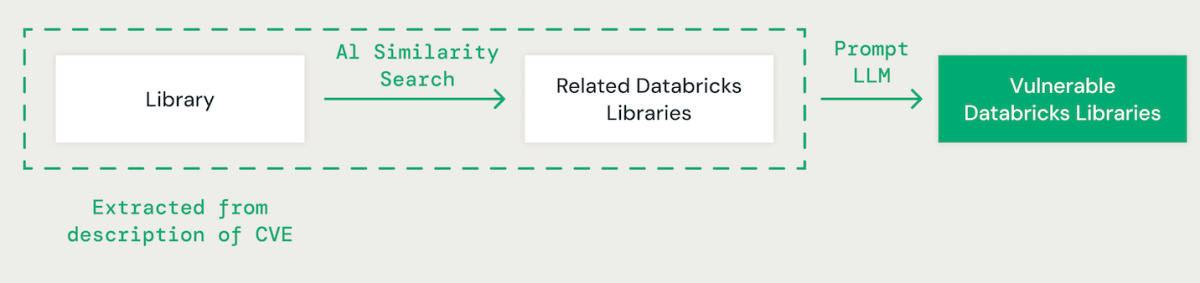
AI-Powered Library Matching
Utilizing few-shot prompting with a large language model (LLM), we extract the relevant library for each CVE from its description. Subsequently, we employ an AI-based vector similarity approach to match the identified library with existing Databricks libraries. This involves converting each word in the library name into an embedding for comparison.
When matching CVE libraries with Databricks libraries, it’s essential to understand the dependencies between different libraries. For example, while a vulnerability in IPython may not directly affect CPython, an issue in CPython could impact IPython. Additionally, variations in library naming conventions, such as “scikit-learn”, “scikitlearn”, “sklearn” or “pysklearn” must be considered when identifying and matching libraries. Furthermore, version-specific vulnerabilities should be accounted for. For instance, OpenSSL versions 1.0.1 to 1.0.1f might be vulnerable, whereas patches in later versions, like 1.0.1g to 1.1.1, may address these security risks.
LLMs enhance the library matching process by leveraging advanced reasoning and industry expertise. We fine-tuned various models using a ground truth dataset to improve accuracy in identifying vulnerable dependent packages.
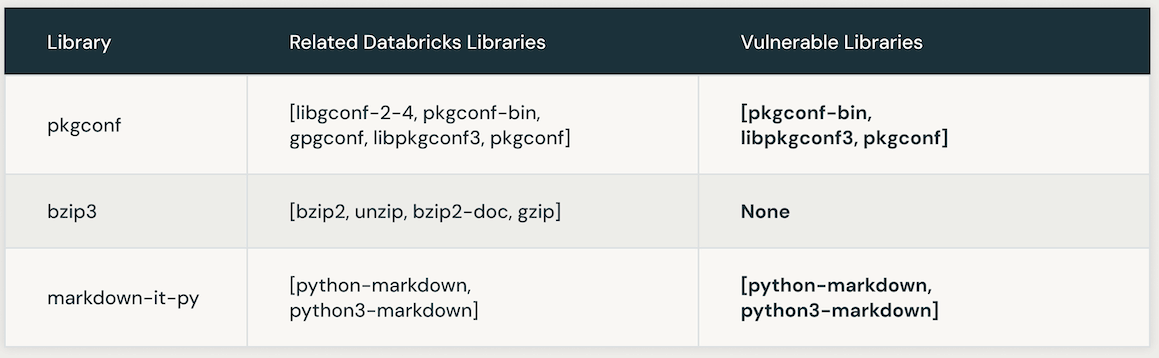
The following table presents instances of vulnerable Databricks libraries linked to a specific CVE. Initially, AI similarity search is leveraged to pinpoint libraries closely associated with the CVE library. Subsequently, an LLM is employed to ascertain the vulnerability of those similar libraries within Databricks.
Automating LLM Instruction Optimization for Accuracy and Efficiency
Manually optimizing instructions in an LLM prompt can be laborious and error-prone. A more efficient approach involves using an iterative method to automatically produce multiple sets of instructions and optimize them for superior performance on a ground-truth dataset. This method minimizes human error and ensures a more effective and precise enhancement of the instructions over time.
We applied this automated instruction optimization technique to improve our own LLM-based solution. Initially, we provided an instruction and the desired output format to the LLM for dataset labeling. The results were then compared against a ground truth dataset, which contained human-labeled data provided by our product security team.
Subsequently, we utilized a second LLM known as an “Instruction Tuner”. We fed it the initial prompt and the identified errors from the ground truth evaluation. This LLM iteratively generated a series of improved prompts. Following a review of the options, we selected the best-performing prompt to optimize accuracy.
After applying the LLM instruction optimization technique, we developed the following refined prompt:
Choosing the right LLM
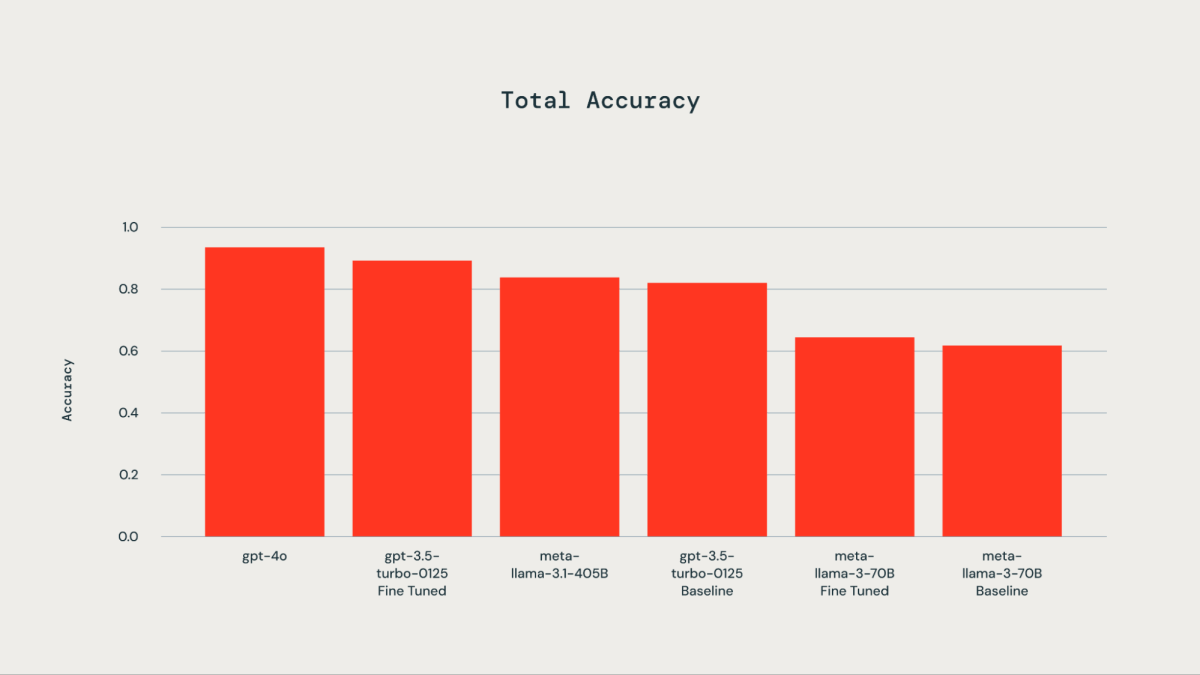
A ground truth dataset comprising 300 manually labeled examples was utilized for fine-tuning purposes. The tested LLMs included gpt-4o, gpt-3.5-Turbo, llama3-70B, and llama-3.1-405b-instruct. As illustrated by the accompanying plot, fine-tuning the ground truth dataset resulted in improved accuracy for gpt-3.5-turbo-0125 compared to the base model. Fine-tuning llama3-70B using the Databricks fine-tuning API led to only marginal improvement over the base model. The accuracy of the gpt-3.5-turbo-0125 fine-tuned model was comparable to or slightly lower than that of gpt-4o. Similarly, the accuracy of the llama-3.1-405b-instruct was also comparable to and slightly lower than that of the gpt-3.5-turbo-0125 fine-tuned model.
Once the Databricks libraries in a CVE are identified, the corresponding score of the library (library_score as described above) is assigned as the component score of the CVE.
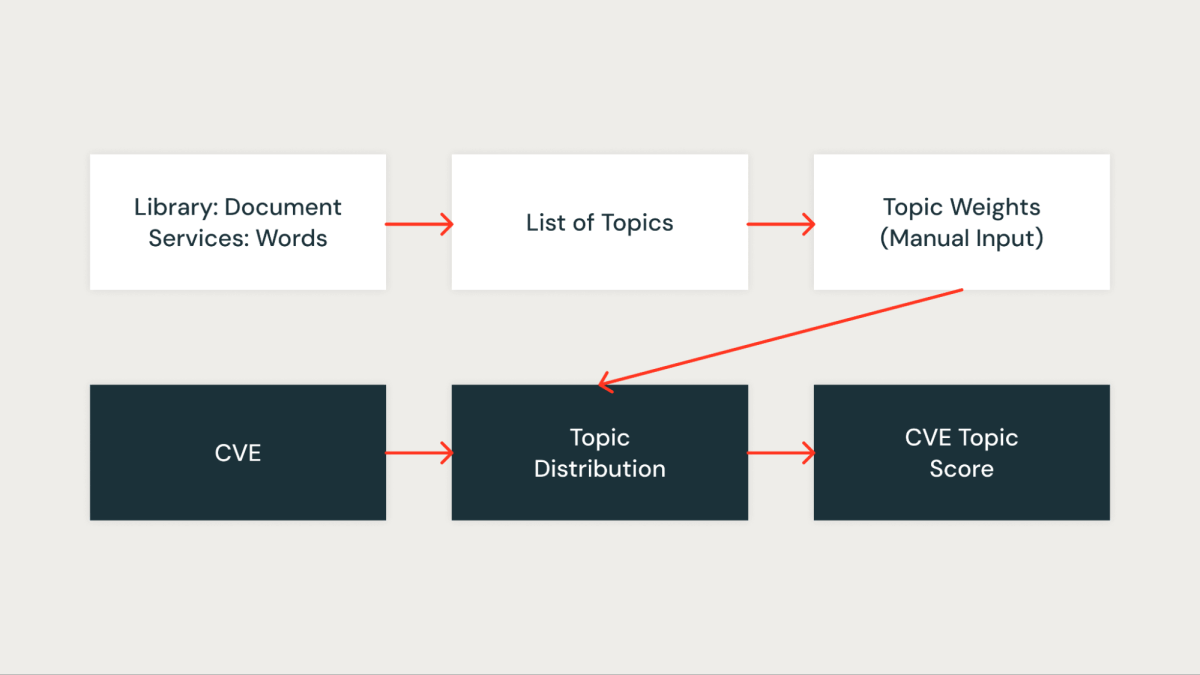
Topic Score
In our approach, we utilized topic modeling, specifically Latent Dirichlet Allocation (LDA), to cluster libraries according to the services they are associated with. Each library is treated as a document, with the services it appears in acting as the words within that document. This method allows us to group libraries into topics that represent shared service contexts effectively.
The figure below shows a specific topic where all the Databricks Runtime (DBR) services are clustered together and visualized using pyLDAvis.
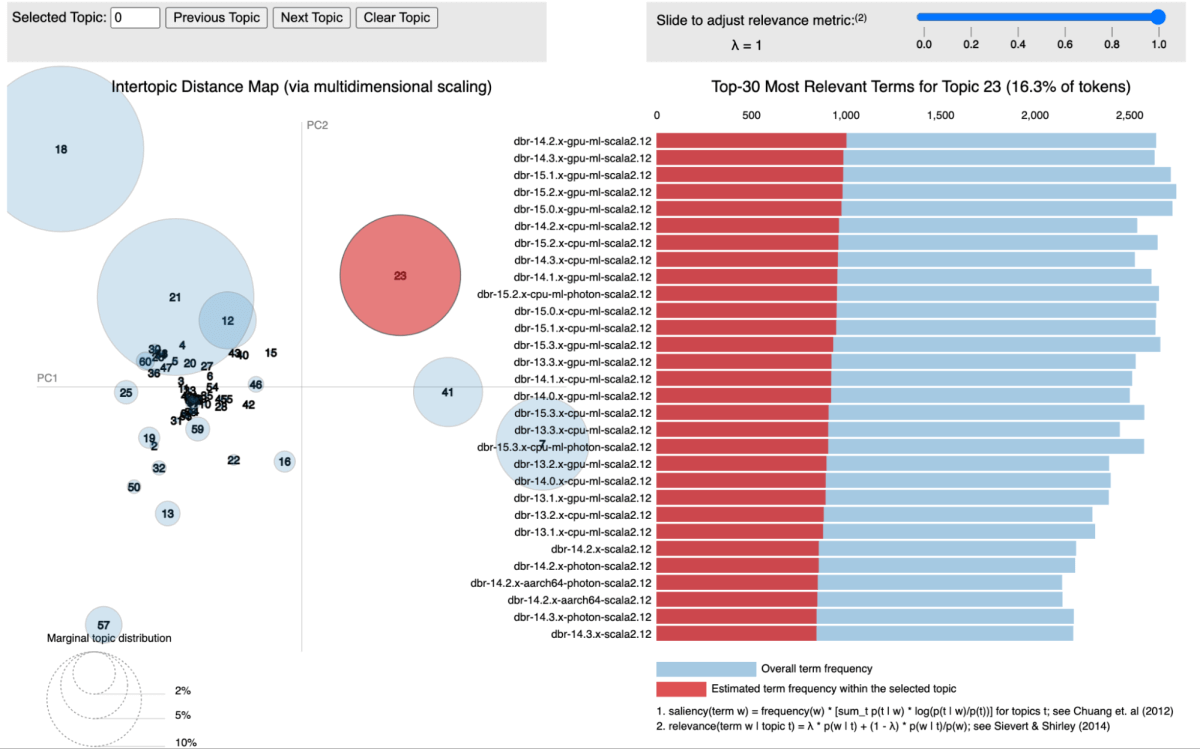
For each identified topic, we assign a score that reflects its significance within our infrastructure. This scoring allows us to prioritize vulnerabilities more accurately by associating each CVE with the topic score of the relevant libraries. For example, suppose a library is present in multiple critical services. In that case, the topic score for that library will be higher, and thus, the CVE affecting it will receive a higher priority.
Impact and Results
We have utilized a range of aggregation techniques to consolidate the scores mentioned above. Our model underwent testing using three months’ worth of CVE data, during which it achieved an impressive true positive rate of approximately 85% in identifying CVEs relevant to our business. The model has successfully pinpointed critical vulnerabilities on the day they are published (day 0) and has also highlighted vulnerabilities warranting security investigation.
To gauge the false negatives produced by the model, we compared the vulnerabilities flagged by external sources or manually identified by our security team that the model failed to detect. This allowed us to calculate the percentage of missed critical vulnerabilities. Notably, there were no false negatives in the back-tested data. However, we recognize the need for ongoing monitoring and evaluation in this area.
Our system has effectively streamlined our workflow, transforming the vulnerability management process into a more efficient and focused security triage step. It has significantly mitigated the risk of overlooking a CVE with direct customer impact and has reduced the manual workload by over 95%. This efficiency gain has enabled our security team to concentrate on a select few vulnerabilities, rather than sifting through the hundreds published daily.
Acknowledgments
This work is a collaboration between the Data Science team and Product Security team. Thank you to Mrityunjay Gautam Aaron Kobayashi Anurag Srivastava and Ricardo Ungureanu from the Product Security team, Anirudh Kondaveeti Benjamin Ebanks Jeremy Stober and Chenda Zhang from the Security Data Science team.
Source link
lol