
On Compound AI Systems, Txt2SQL & Data Agents. A year ago or so, a client enthusiastically presented us with a long list of “AI LLM projects.” Among them, there was one project listed as: “use text-to-sql to automate all data analysis tasks” … We thought: “Umm… this is going to be an interesting project”… Months later the client abandoned the project.
Pioneers in Text-to-SQL at enterprise scale. afaik, Pinterest was one of the first companies that deployed Tex2SQL at scale in enterprise production. Importantly, they were one of the first ones in sharing their experience. This is an excellent post in which the engineering team describes the whole journey from academic Txt2SQL to production. Blogpost: How we built Text-to-SQL at Pinterest.
Text-to-SQL augmented with RAG: Not easy yet. Sure! LLMs can write beautiful, syntactically correct SQL statements because there are tons of public SQL code on which LLMs have been trained on. But LLMs have quite a bit of challenges when dealing with real-world relational data problems. Top 4 Challenges using RAG with LLMs to Text-to-SQL and how to solve it.
Text-to-SQL or human-like AI analysts? This is an interesting post by the team at Pattern, a startup building a financial analysis agent. Their main idea: Text-to-SQL should be more like Text-to-Analysis that works at the business layer. And the LLM -beyond prompting- should behave like a human analyst by using multiple, specialist AI agents that contribute to the analysis process. Blogpost: Text to SQL and its uncanny valley.
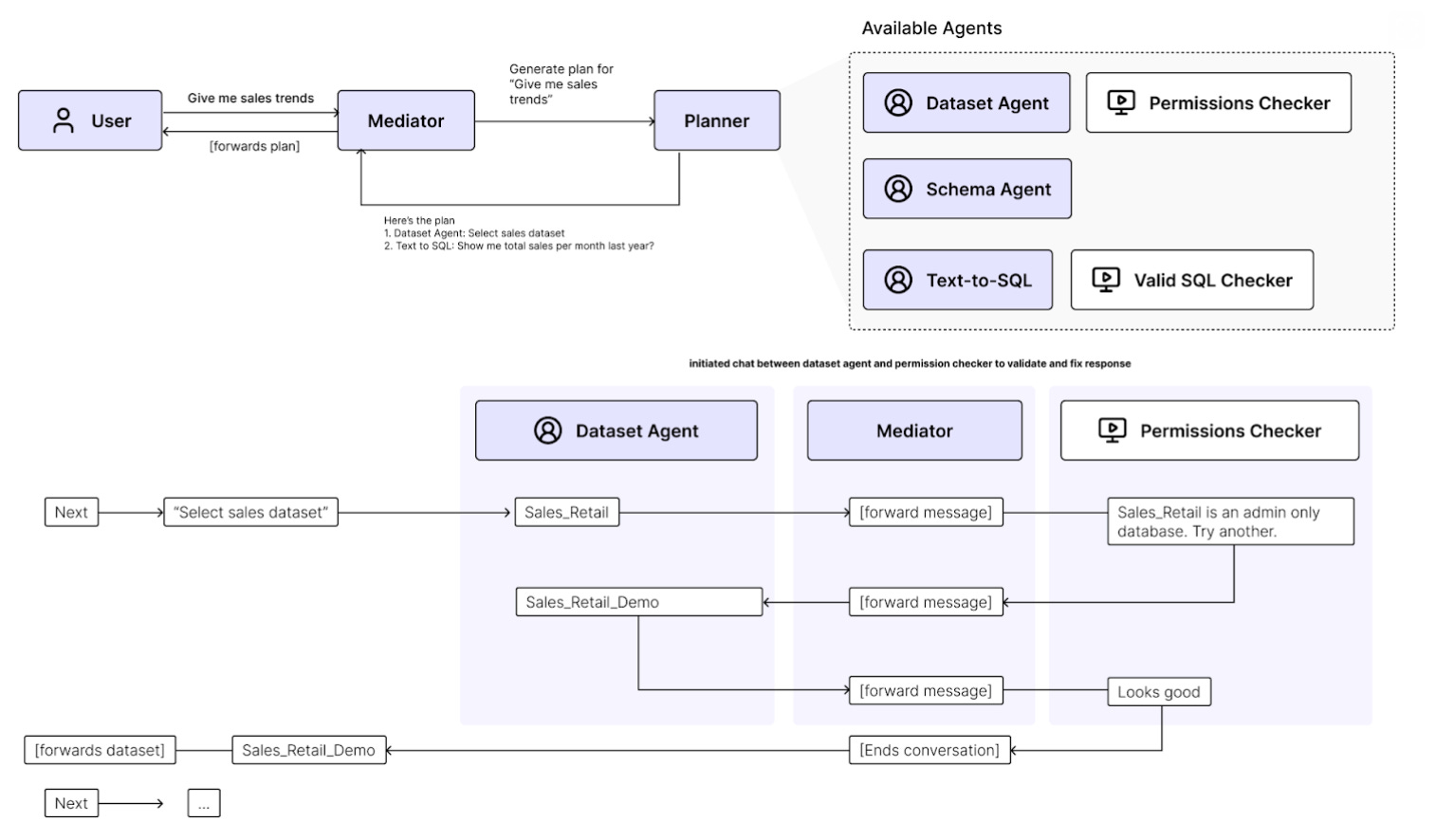
Agents for data workflows. In the real world, data workflows with several data pipelines with messy, dirty, changing data are an absolute nightmare! Enter Meadow: An open source, agentic framework for building multi-agent data workflows with LLMs with interactive user feedback. Meadow’s approach is to chain several specialised agents like Text-to-SQL, Planner, Executor, Schema Cleaner, Validator, Router agents to perform an end to end data workflow. Blogpost and repo here: Introducing Meadow: LLM Agents for Data Tasks.
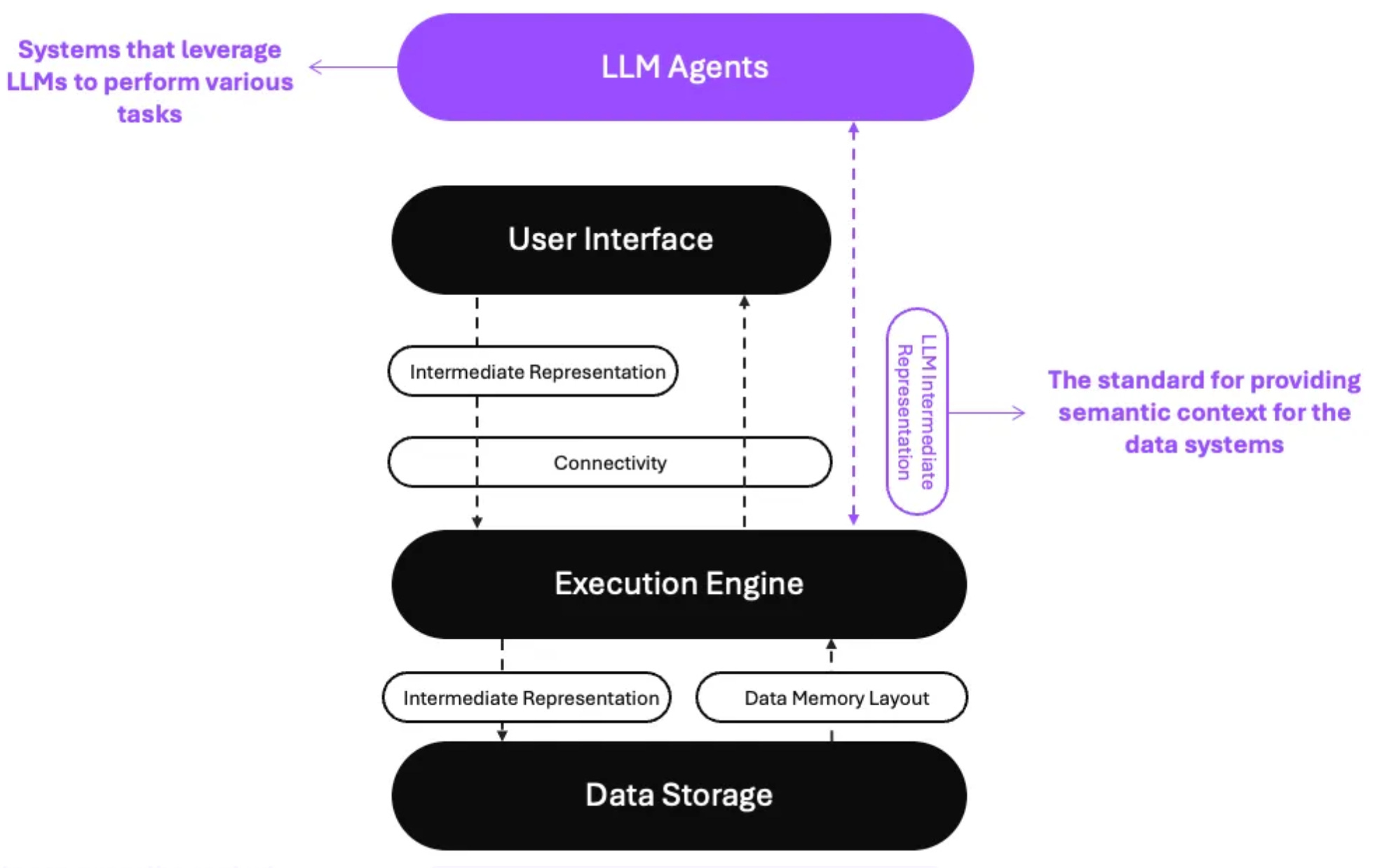
Compound AI Systems and LLM Data Agents. In February, researchers at Berkeley AIR published an article on the rapid Shift from Models to Compound AI Systems. In contrast to a “classic” rather static AI model, a Compound AI System interacts with multiple components… function calls, APIs, search, retrievers, agents… The researchers argue that you should design and implement an AI system from the perspective of a Compound AI System.
More recently, Howard at Wren.ai – a startup offering RAG-Txt2SQL solutions- wrote a great post on the new wave and the concept of Composable Data Systems and the Interface to LLM agents. And Mosaic AI (aka Databricks AI) just announced a series of new capabilities on building and deploying production-quality Compound AI Systems.
A fully open source NL engine for SQL DBs. Last month, the team at Dataherald open sourced natural language-to-SQL engine built for enterprise-level question answering over relational data. It allows you to set up an API from your database that can answer questions in plain English. You can do NL Q&A on Prod DBs, NL queries the DW directly without IT support, or create a ChatGPT plugin. Repo and docs here: Interact with your SQL database, Natural Language to SQL using LLMs.
Open Source AI Agents for Data Analysis. PandasAI just open sourced a Python library that makes it easy to ask questions to your data in natural language. Beyond querying, PandasAI offers functionalities to visualize data through graphs, cleanse datasets by addressing missing values, and enhance data quality through feature generation, making it a comprehensive tool for data scientists and analysts. Checkout the repo and docs here: Pandas AI – AI agents for Data Analysis.
Free course: Building Your Own Database Agent. In this course, you will develop an AI agent that interacts with databases using natural language, simplifying the process for querying and extracting insights. To know more and join this free course click here.
Have a nice week.
-
[gotcha] LLM Dataset Inference: Did you Train on My Dataset?
-
A Systematic Survey on [the latest] Prompting Techniques, 6/2024
-
The Challenges of Retrieving & Evaluating Relevant Context for RAG
-
NVIDIA Nemotron-4 340B: A SOTA Open Synthetic DataGen Pipeline
-
[new] Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations
-
[free, very comprehensive] Generative AI for Beginners v2, 18 Lessons
-
[great] Stanford CS25 v4: A Highly Opinionated View on Transformers
-
[official] Intro to Apple’s On-Device & Server Foundation Models
-
Can LLMs Invent Better Ways to Train LLMs? An Auto-Evolutionary Approach
-
Together.ai – Mixture of Agents (MoAs) Enhances LLMs Capabilities
-
MSR – Samba: Mamba SSM + MLP + Sliding Window for Unlimited Context
-
NVIDIA HelpSteer2: An Open Dataset for Training Top Reward Models
-
Character Codex: A Dataset of Characters in Comics, Movies, TV Shows for GenAI
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol