
Every day, businesses manage an extensive volume of documents—contracts, invoices, reports, and correspondence. Critical data, often in unstructured formats that can be challenging to extract, is embedded within these documents. While humans can perform this task, it becomes costly and error-prone as the volume of documents grows.
So, how can we effectively extract information from documents?
This is where document semantic segmentation becomes essential. Semantic segmentation involves identifying and classifying key regions within an image. When applied to documents, it targets the most relevant sections, enabling streamlined information extraction and enhancing data accessibility.
In this article, we’ll cover:
- How semantic segmentation can be applied to document processing
- The best approaches for document segmentation
- A look at different model architectures for document segmentation
- Key evaluation metrics in document segmentation
- Real-world applications for document segmentation
Understanding Document Segmentation
The general idea of semantic segmentation is as follows: I have an image and want to classify its pixels into specific categories. The goal remains the same when applied to documents: I have a document image and want to classify its sections.
A document typically consists of multiple sections, each containing distinct information. Document semantic segmentation aims to detect these sections within a document and assign a class label to each or extract relevant information.
For instance, a receipt would have sections such as:
- Name and address of the seller
- Description of goods
- Quantity and price of each item
- The date and time of the transaction
- Total amount paid
Segmentation is handled by a deep learning model that inputs the document’s image and outputs the corresponding segmented regions.
Key Tasks in Document Segmentation
To extract useful information from a document, the segmentation model must be able to perform the following tasks:
- Text recognition and classification
- Layout analysis
- Image understanding
- Data extraction
Text Recognition and Classification
Since documents primarily comprise text, text recognition is a crucial step in document segmentation. Given a document, the segmentation model must recognize and extract all text within the image.
This includes printed text and handwritten elements, especially in physical documents, requiring the model to detect and extract these variations accurately.
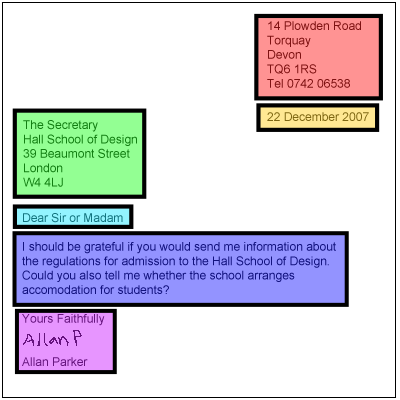
Beyond recognition, proper classification of the extracted text is essential. Each text in a document serves a specific purpose, so classification should emphasize this context. For example, key text elements are segmented and assigned class labels through color coding in the letter image above.
While convolutional segmentation models can identify and segment regions such as the sender’s address, date, and recipient’s address, interpreting and classifying the actual text content requires an intermediate Optical Character Recognition (OCR) step.
Layout Analysis
There is no universally agreed-upon layout standard for documents; each organization may structure its document differently, and layouts can even vary across pages of the same document.

For a document segmentation model to perform effectively, it must be capable of accurately understanding and interpreting the document’s layout. The model should be able to identify regions of interest that hold value for the user, regardless of layout variations.
Image Understanding
Most documents are multimodal, containing both text and images. A document segmentation model should identify and extract images and understand their content. This enables effective categorization of different images within the document.

Document images vary widely, from organizational logos and ID photos to presentation photographs, diagrams, and charts. A segmentation model that can accurately segment and classify these different types of images can be of significant value.
A document segmentation model should be capable of extracting more than just text and images; it should also identify and extract various types of structured data that add valuable context to the document’s content.
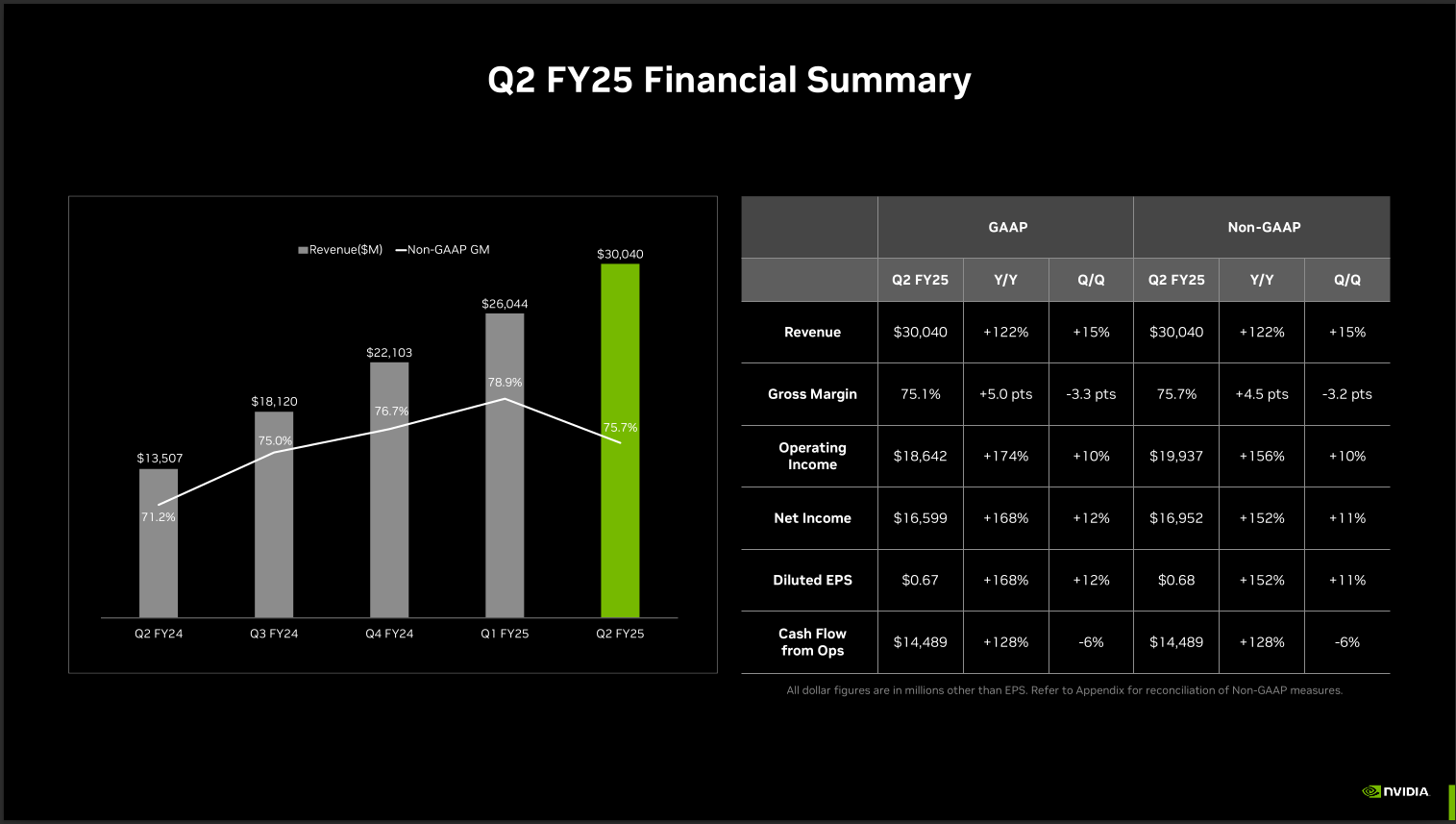
For example, tables in reports and financial documents often contain critical data that must be accurately captured for analysis. Additionally, elements like forms, checkboxes, footnotes, headers, and page numbers provide essential contextual information.
The model improves the organization and usability of the extracted information by including these elements.
Laying the Groundwork for Effective Document Segmentation
Now that we understand document semantic segmentation, let’s look at how to implement it for a business. There are three primary approaches:
- Train a model from scratch.
- Use a pretrained model.
- Fine-tune a pretrained model.
Training a model from scratch involves selecting an existing model architecture, such as those designed for object detection or segmentation, and collecting datasets to train the model. This approach is the most resource-intensive of the three since you will build from scratch rather than starting from a pretrained checkpoint.
Using a pretrained model is the most straightforward approach to document segmentation. These models are already trained to perform document segmentation tasks and are ready to use with minimal effort. However, they come with certain limitations.
Most pretrained models are designed for general-purpose applications, making them versatile but not highly specialized. Consequently, their performance might not always be optimal for specific use cases or highly specialized tasks.
For instance, models like LayoutLM and StructureLM are pretrained specifically to understand the structure of documents but might struggle with tasks such as invoice parsing or contract analysis on a specific organization’s documents.
To address this, fine-tuning is often used. Fine-tuning involves taking a pretrained model and performing additional training on it to optimize its performance for a specific task. For instance, you can take the LayoutLM model along with an internal dataset for contract analysis and train LayoutLM on this dataset.
Similarly, non-document segmentation models, such as YOLO, can be fine-tuned to perform document segmentation tasks.
This approach, like training a model from scratch, requires you to collect or create a dataset. However, it is less compute-intensive because it builds upon an already existing model. The training process focuses on refining the model to perform well on the specific task at hand.
Let’s break down the steps involved in training a model from scratch or fine-tuning a pretrained model:
- Data Foundation: The process begins with acquiring an existing dataset or creating a high-quality dataset tailored to a specific task.
- Data Preprocessing: After collecting the dataset, the next step is to clean, augment, and transform the data into a suitable format for the model.
- Model Selection: With the data prepared, the next task is selecting a suitable model that can be trained or fine-tuned for your needs.
- Model training: With the model selected you can then begin your training on the dataset.
- Performance Evaluation: Once the model is trained, it’s essential to evaluate its performance using metrics and test datasets to ensure it meets the desired accuracy and reliability.
In the following sections, we will explore these steps in detail, focusing on their role in creating an effective document segmentation model. From building a solid data foundation to fine-tuning and evaluating the model, each step will be discussed to ensure a deep understanding of the process.
Preparing a Dataset for Document Segmentation
Let’s dive into the process of preparing a dataset for document segmentation. The quality and quantity of the dataset directly influence the success of the entire process. A poor dataset can significantly impact model performance, whether in size, variety, or annotation accuracy. Therefore, it’s essential to approach dataset preparation with great care and attention to detail.
In this section, we will walk through the complete data preparation process, covering everything from gathering the dataset to annotation techniques and the tools that can assist with this task.
Data Collection Strategies
Once you build your dataset, you must choose an appropriate data-gathering strategy. One option is to use an existing dataset. Several publicly available document datasets, such as FUNSD, DocVQA, and SmartDoc QA, can be collected and combined to suit your needs.
Alternatively, you can gather documents from internal sources, such as a company’s internal reports, receipts, and invoices. You can create a custom dataset more specific to your use case by annotating these documents. While this approach tends to yield better results, it requires more effort and resources. We will discuss annotation strategies that can support this approach in more detail.
Another option is to generate synthetic data. This involves using automated systems to create and annotate documents. While this strategy can provide a high volume of data, it may come with trade-offs, such as lower quality or reduced diversity in the dataset.
Each of these strategies has its strengths and weaknesses. A combined approach, utilizing a mix of public, internal, and synthetic data, can often offer the best balance of quality, quantity, and diversity.
Annotation guidelines
A document segmentation dataset comprises image files of documents and their corresponding annotations. Building such a dataset begins with collecting the documents and then annotating them. For document segmentation tasks, annotations are typically performed using two main approaches: Masks and Bounding Boxes.
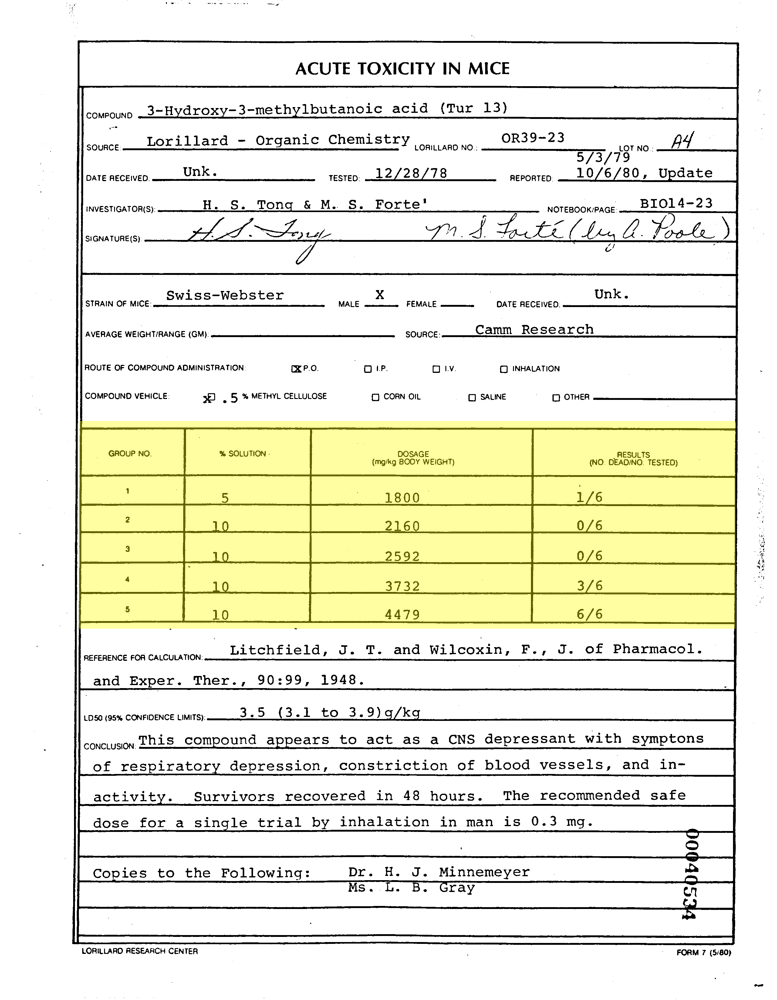
Masking involves identifying all the pixels of interest within an image. For instance, in the image above, the table is the area of focus, so it has been masked accordingly. This mask can be visualized by assigning it a specific color to highlight the region of interest.
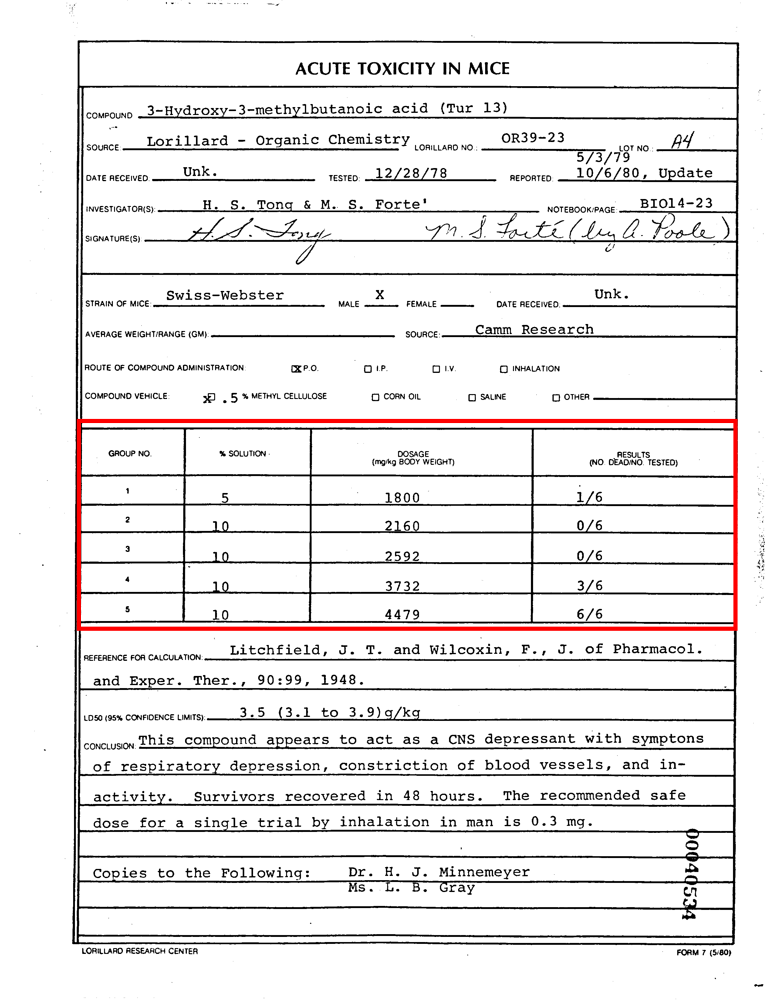
Bounding box annotation involves drawing a rectangle around the region of interest in a document. This method is simpler because it uses a smaller set of values. The annotations for a bounding box typically require four key values: the object’s center coordinates and the bounding box’s height and width.
Annotations are typically stored in JSON format due to its flexibility and readability. Below is an example of a JSON annotation for a document containing two regions of interest: one representing a table and the other an image.
{
"document_id": "doc_001",
"file_name": "sample_document.png",
"annotations": [
{
"id": "1",
"type": "table",
"bounding_box": {
"center_x": 225,
"center_y": 200,
"width": 350,
"height": 200
}
},
{
"id": "2",
"type": "image",
"bounding_box": {
"center_x": 650,
"center_y": 300,
"width": 300,
"height": 300
}
}
]
}Annotation files can be expanded to include details, making them more descriptive and informative. For instance, in the case of a table, the annotation could specify attributes like the number of rows and columns and the values contained within the table.
Providing such detailed annotations enhances the dataset, enabling the model to learn more effectively and perform better when trained on the annotation-image pairs.
Tools and Platforms for Dataset Creation
Now that we have discussed data collection and annotation strategies let’s look at a couple of tools that can assist with creating and annotating documents.
- DagsHub is an all-in-one tool for managing the entire machine learning pipeline. It streamlines the process by enabling the curation and annotation of high-quality datasets, tracking experiments, and evaluating model performance on the dataset.
- Labeling Tools: Tools like LabelImg, prodi.gy, and Doccano are user-friendly for annotating text, images, and other document elements. These tools help with tasks like drawing bounding boxes and labeling text regions.
- Automated Tools: Pretrained document segmentation models can automate the initial annotation process, speeding up dataset creation. You can then refine these annotations, saving time while ensuring accuracy.
Data Preprocessing Techniques for Optimal Results
Additional data preprocessing techniques can be applied to enhance the document segmentation process. One important approach is ensuring that the image resolution and quality meet the required standards, making the image suitable for processing.
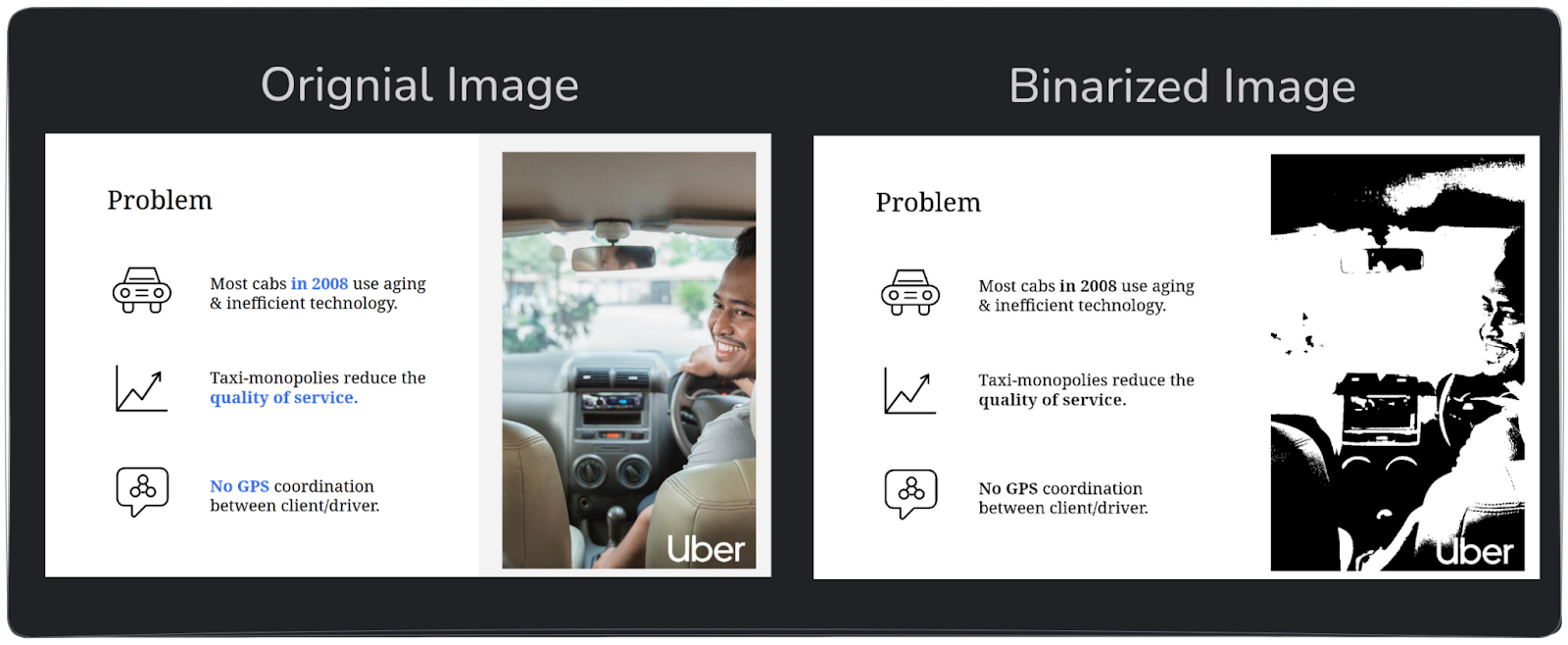
Some techniques help remove irrelevant information for document segmentation. One such technique is binarization, which simplifies images by converting them to black and white.
This process removes unnecessary color details without affecting the information extraction process, as most document segmentation tasks rely on structure rather than color.

Another valuable preprocessing technique is data augmentation. This involves creating multiple document variations to introduce diversity into the dataset.
For example, consider a document from the FUNSD dataset. We can augment this document by rotating it and generating a new variation.

Even if some parts of the document are lost in the rotation, we aim to make the model more adaptable, ensuring it performs well even with real-world variations.

Another augmentation strategy is to introduce defects to the document. This can include adding noise, distortions, or other imperfections, further diversifying the dataset.
These defects help prepare the model for real-world scenarios, where documents may not always be perfectly formatted.
Choosing the Right Model Architecture for Document Segmentation
Various model architectures can be employed for document segmentation, each offering unique advantages. In this section, we’ll explore these architectures and examine how they can enhance segmentation performance for document processing.
UNet
UNet is a widely recognized architecture for image segmentation tasks. It was initially introduced to address challenges in medical image segmentation. Its architecture comprises an encoder and a decoder, built using convolutional neural networks (CNNs).
The encoder downsamples the input image, capturing essential features and compressing the spatial information into a more compact representation. The decoder then upsamples this downsampled representation, making pixel-level predictions to generate segmentation masks.
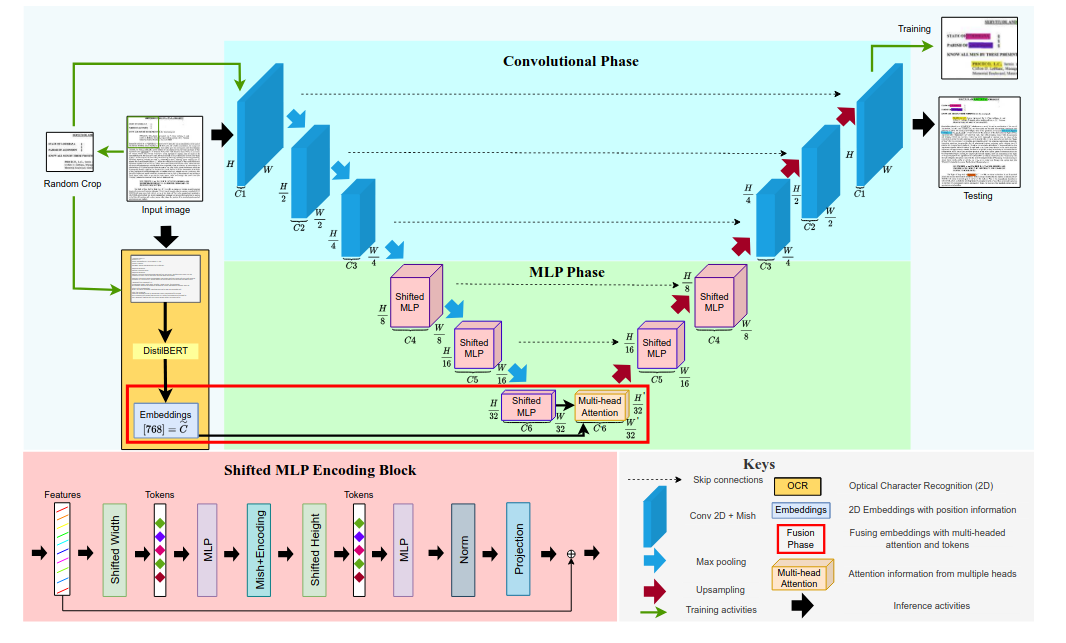
In the context of documents, the UNet encoder processes the document image, extracting and compressing its features. The decoder then reconstructs these features into segmentation masks, highlighting regions of interest, such as text, tables, or images, with precise pixel-level accuracy. This makes UNet particularly effective for tasks requiring detailed segmentation.
Several U-Net variants have been pretrained on specific document segmentation tasks. One example is DocParseNet, introduced in the paper DocParseNet: Advanced Semantic Segmentation and OCR Embeddings for Efficient Scanned Document Annotation. The model’s code is available on the paper’s corresponding code page.
Another example is the U-Net model introduced in the paper End-to-End Information Extraction by Character-Level Embedding and Multi-Stage Attentional U-Net. The code for this model can also be found on the paper’s code page.
Object Detection Models
While UNet and similar models focus on predicting masks for regions of interest, object detection models are designed to predict bounding boxes.
These bounding boxes represent the coordinates of objects within an image, such as the layout of a document, addresses in a letter, form fields, or even a person’s signature.
Popular object detection models like YOLO and SSD have been pre-trained on well-known datasets like COCO and can be fine-tuned for document segmentation tasks. These models offer a more straightforward approach, as they only need to predict rectangular bounding boxes rather than more complex masks in the form of polygons.
A popular source for object detection models is Ultralytics, known for offering several pretrained YOLO models. The codebase referenced here fine-tunes YOLOv5 by Ultralytics for document segmentation.
Transformer-Based Models
Transformer architecture has emerged as the dominant model in deep learning, revolutionizing various tasks across various domains.
Its application to document segmentation has been made possible by innovative models like LayoutLM and its subsequent variants.
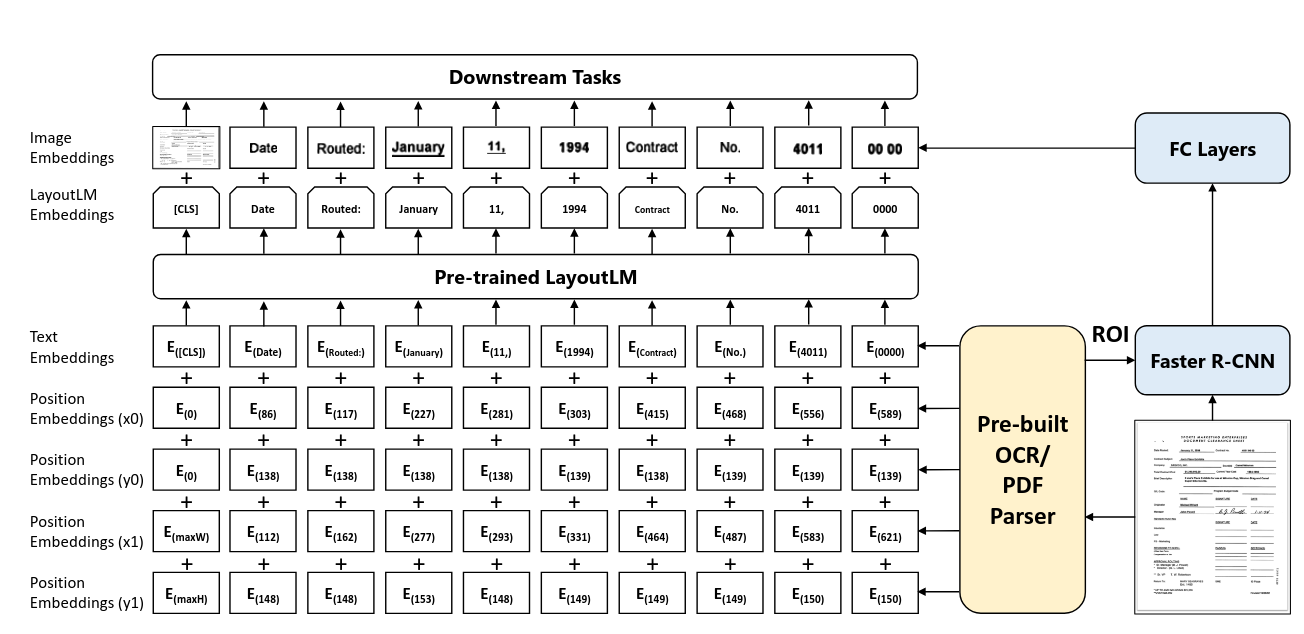
LayoutLM introduced the concept of document pretraining, a step forward from the traditional text-based pretraining approaches. Inspired by BERT, LayoutLM builds on BERT’s architecture with significant additions to handle not only text but also the visual and layout information of documents.
While BERT focuses primarily on text representation, LayoutLM enhances this by incorporating text embeddings alongside 2D positional embeddings, which capture the spatial location of text elements within the document.
Additionally, LayoutLM uses Faster R-CNN to generate image embeddings, combining these with the text and positional embeddings to create a richer, more comprehensive input representation for the model.
While BERT was pretrained on tasks like Masked Language Modeling (MLM) and Next Sentence Prediction (NSP), LayoutLM’s pretraining tasks include Masked Visual-Language Modeling (MVLM) and Multi-label Document Classification, enabling it to better understand document structures and content.
After pretraining, LayoutLM can be fine-tuned for various document segmentation tasks, including Form Understanding, Receipt Parsing, and Document Image Classification. LayoutLM and its updated versions LayoutLMv2 and LayoutLMv3 can be easily accessed on Hugging Face, where you can find pretrained models ready for fine-tuning on your specific use cases.
Evaluating Model Performance in Document Segmentation
Assessing the performance of a document segmentation model is vital to ensuring it meets the project’s requirements. A well-defined evaluation process highlights the model’s strengths and weaknesses, guiding further improvements. Here, we explore key metrics commonly used to evaluate document segmentation models.
Intersection over Union (IoU)
Intersection over Union, often called IoU, measures the overlap between the predicted segmentation and the ground truth. It evaluates how closely the predicted segments align with the actual regions. An IoU score closer to 1 indicates better overlap and, consequently, more accurate predictions.
Precision and Recall
Precision and recall are metrics that evaluate the accuracy and completeness of a model’s predictions:
- Precision focuses on the proportion of correct predictions compared to all predictions made. A high precision score shows that the model produces fewer false positives.
- Recall measures the proportion of correct predictions out of all actual regions. A high recall score indicates that the model successfully identifies most true regions, minimizing false negatives.
F1 Score
The F1 score combines precision and recall into a single metric, providing a balanced evaluation of the model’s performance. It is instrumental when precision and recall are equally crucial for the task.
Pixel Accuracy
Pixel accuracy is a commonly used evaluation metric in segmentation tasks, including document segmentation. It measures the proportion of correctly classified pixels over the total number of pixels in the image.
Real-World Applications and Case Studies
Organizations want to extract useful information from their data to help their businesses grow. This section will show how organizations utilize document segmentation in the real world.
CheQ Leverages Google’s Document AI for Efficient Credit Management
Cheq, a leading credit management company in India, leverages Google’s Document AI and Google Cloud to automate extracting essential credit product information from customer communications such as emails, SMS, and other documents.
By utilizing Document AI’s advanced OCR capabilities and machine learning models, Cheq efficiently identifies and extracts key details like payment status, transaction history, and customer inquiries, which are critical for managing credit products and processing payments.
This automation has enabled Cheq to build a comprehensive credit management and payment solution that integrates seamlessly into their workflow.
The system has significantly reduced manual effort, allowing the company to rely on a small team of just a few developers and a single customer support staff member to manage operations that typically require a much larger workforce.
With Document AI’s capabilities, Cheq has enhanced its operational efficiency, providing faster and more accurate services while minimizing human errors, ultimately leading to better customer satisfaction and cost savings.
Super.AI Streamlines FNOL Processing for Global Auto Insurer
One of the world’s largest auto insurers processes a high volume of First Notices of Loss (FNOL) daily. These reports, submitted by customers following incidents like theft or damage, contain vital details such as the time, location, police reports, and witness accounts. Accurately extracting this information is essential for both efficient claims processing and meeting customer expectations.
However, the variability in FNOL reports, including different formats and handwritten descriptions, made manual processing slow, costly, and error-prone.
The insurer adopted Super.AI’s Intelligent Document Processing (IDP) platform to address these challenges. The platform achieved over 99% accuracy in extracting information from FNOL reports by combining advanced AI with crowdsourced data processing. It flagged unclear or suspicious data for human review, reducing the need for manual intervention.
Future Trends
Multimodality, particularly through Vision Language Models (VLMs), is a rapidly growing area of AI that transforms document analysis. VLMs are designed to process both text and images simultaneously, enabling users to interact with documents more intuitively.
This capability allows for efficient and precise segmentation, where users can specify exactly what they want to extract from a document.
Google’s open-source model, Paligemma, is an example of a multimodal model pretrained for various vision-language tasks. By fine-tuning Paligemma, users can create an interactive document analysis system that prompts the model to extract specific information from documents, improving efficiency and accuracy in the segmentation process.
Looking ahead, VLMs are poised to become even more versatile. Their growing efficiency and accessibility will enable businesses to process and analyze documents flexibly.
With the ability to understand text and images, VLMs are redefining how document workflows are managed, allowing for more intuitive interactions and enhanced data extraction. This will give businesses powerful tools to optimize document handling, making workflows smarter and more dynamic.
Conclusion
Semantic segmentation for documents is a transformative approach to extracting and organizing meaningful information from diverse document types. Businesses can develop models that deliver accurate and efficient results by combining robust data preparation techniques, deep learning architectures, and reliable evaluation metrics.
These tools and processes are crucial for managing documents effectively across various applications, from automating workflows to improving data accessibility.
As multimodal models advance, their ability to handle diverse tasks with minimal finetuning reshapes document segmentation. These models excel at understanding both text and visual elements, making them increasingly valuable for general-purpose applications.
With their growing adaptability and ease of use, they are set to redefine how documents are processed, offering even greater efficiency and versatility in the years ahead.
Source link
lol