
Traditional approaches might suggest randomly selecting images for annotation, but this can be inefficient and wasteful. Active Learning takes a more strategic approach: it identifies and prioritizes the most valuable samples that could contribute most significantly to improving model performance. Such a selection process considerably reduces the amount of labeled data needed to train a model while maintaining and improving the model accuracy.
In the following sections, we’ll explore:
- The fundamental principles behind Active Learning strategies
- Common query methods for sample selection
- Real-world implementation considerations
- Best practices for integrating Active Learning into existing CV workflows
- Case studies demonstrating successful Active Learning deployments
- Future trends and emerging techniques in the field
Understanding Active Learning
Active Learning enables us to select important and impactful data points or samples to train a machine learning model. But why is this an important and valuable approach?
We must understand that not all the data samples contribute to providing valuable information. Some samples can just add noise to the training dataset which might lead to the following issues:
- Model is underfitting even with ample amounts of training data. Reason, presence of redundant samples.
- Model doesn’t perform well during inference i.e. the model overfits. This can happen because the training dataset is biased or unbalanced leading to not recognising outliers.
In other cases, a lack of labeled data to train a good and robust classifier can call for a method such as active learning. It allows you to achieve high model performance with minimal labeling cost and effort.
Active learning samples data that contain a good representation of the entire dataset. It uses a selection process such as a query strategy that iteratively chooses unlabeled samples or data points that are important and impactful. The selected samples are then sent to a human for annotation or labeling. They are called “oracles”.
Also, keep in mind that the active learning models can also label, annotate, or create segmentation masks for unlabeled samples automatically reducing the burden of the oracles and saving time. Only the difficult cases or samples with high potential are sent to oracles.
One key feature is that active learning creates a feedback loop between the model and human annotators rather than labeling all available data upfront, which can be expensive and time-consuming. Once the data is labeled it is added to the labeled dataset pool for training the model.
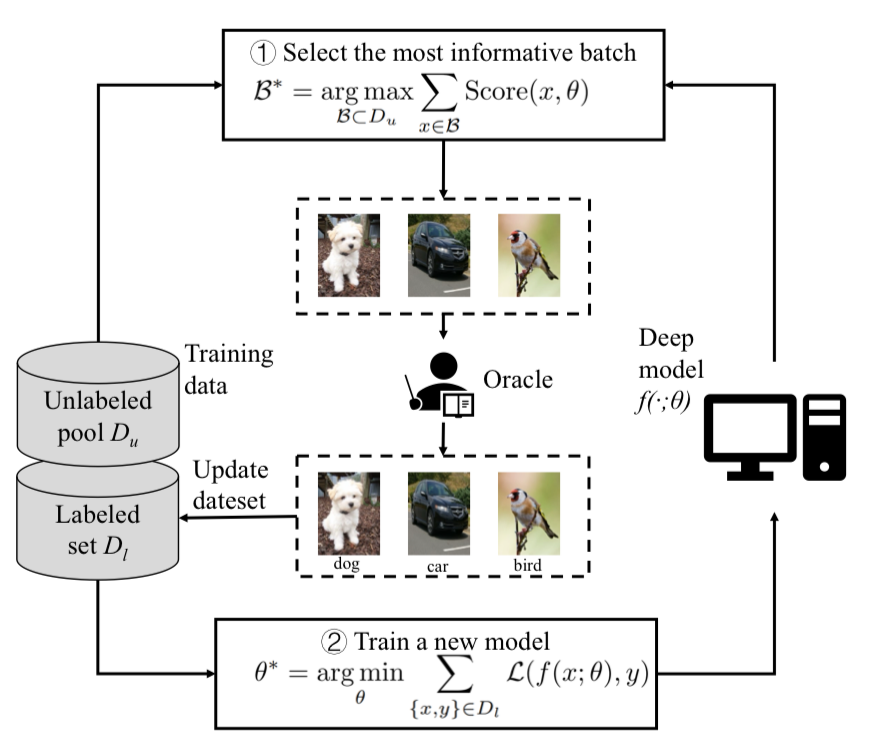
Here’s how the iterative process works:
- Initial Training:
- Start with a small set of labeled data
- Train an initial model on this seed dataset
- Selection Strategy:
- The model looks at a pool of unlabeled data
- Using various sampling strategies, it identifies the most “informative” examples
- These might be:
- Uncertain predictions (where the model has low confidence)
- Boundary cases (samples near decision boundaries)
- Diverse examples (representing different parts of the data distribution)
- Automatic labeling:
- The model automatically labels samples with high confidence and reduces burden on the oracles.
- The samples with the high uncertainty are sent to human annotators.
- Human Annotation:
- Selected samples are sent to human annotators
- Experts provide labels for these specific examples
- This targeted approach focuses human effort on the most valuable but uncertain data points
- Model Update:
- The newly labeled data is added to the training set
- The model is retrained with the expanded dataset
- This process repeats from step 2
Now, let’s understand how active learning is effective and cost-efficient compared to the traditional bulk labeling process:
- Efficiency:
- Traditional: Labels all data regardless of importance
- Active Learning: Prioritizes the most informative examples
- Cost:
- Traditional: Fixed cost proportional to dataset size
- Active Learning: Reduced cost by labeling fewer, more valuable samples
- Model Performance:
- Traditional: Linear improvement with more data
- Active Learning: Often performs better with less labeled data
- Adaptivity:
- Traditional: Static, one-time process
- Active Learning: Dynamic, responds to model needs
This approach is vital in scenarios where:
- Labeling is expensive or time-consuming
- You have access to large amounts of unlabeled data
- The data distribution is imbalanced or complex
Benefits of Active Learning
Let’s discuss some of the benefits of active learning. We will look into the four main aspects – cost reduction benefits, performance enhancement benefits, efficiency benefits, and quality improvement benefits.
Cost Reduction Benefits
We can view cost reduction benefits from two perspectives: Targeted Resource Allocation and Optimizing Expert Time.
A. Targeted Resource Allocation
Traditional machine-learning approaches often require extensive data labeling, which can be costly and time-consuming. Active Learning significantly reduces these costs through strategic selection of data points.
Example: Medical Imaging Project
- Traditional Approach: Requires radiologists to label 10,000 X-rays
- Active Learning Approach: Identifies only 2,000 critical cases focusing on:
- Edge cases with unusual presentations
- Difficult diagnostic boundaries
- Rare conditions
Result: Significant reduction in expert labeling time while maintaining similar model performance.
B. Optimized Expert Time
Active Learning ensures expert time is spent on cases where their expertise adds the most value.
Example: Legal Document Review via Optical Character Recognition
- Traditional: Lawyers examine every contract
- Active Learning: System prioritizes:
- Complex clauses with unusual language leveraging natural language processing and computer vision
- Documents with novel terms
- Cases where the model shows high uncertainty
- Impact: More efficient use of expensive legal expertise
Performance Enhancement Benefits
Active learning performance can be evaluated based on two criteria: Faster Learning Curve and Handling of Edge Cases.
A. Faster Learning Curve
Active Learning achieves better model performance with fewer labeled examples by focusing on the most informative cases.
Example: Autonomous Vehicle Object Detection
- Traditional Approach:
- Requires 200,000 labeled video frames
- 6 months of annotation time
- Full coverage of all driving scenarios
- Active Learning Approach:
- Achieves equivalent performance with 60,000 strategic frames
- Prioritizes:
- Complex traffic scenarios
- Rare object appearances
- Challenging weather conditions
- Unusual road configurations
- Result: Matches baseline performance with 70% fewer annotations
- Deployment time reduced to 2 months
B. Better Handling of Edge Cases
Active Learning can help identify challenging cases, such as edge cases, through strategic sample selection. We must keep in mind that it does not automatically prioritize edge cases unless specifically designed to do so. Edge cases represent rare or unusual scenarios that may be critical for model robustness. For instance, given a certain sample if the active learning algorithm is uncertain about the correct response it can send the sample to the human annotator. The annotator can then properly evaluate the image, label it correctly, and add it to the labeled data pool.
Example: Manufacturing Quality Control
- Traditional: Labels all defect images equally
- Active Learning: Prioritizes uncertain samples which are:
- Subtle defects that are hard to detect
- New types of defects not well-represented in training
- Borderline cases between acceptable and defective
- Result: More robust model performance on challenging cases
Additionally, active learning has demonstrated quantifiable performance benefits in specific computer vision tasks:
- Semantic segmentation tasks achieve equivalent performance while reducing labeling costs by up to 80%
- Video recognition sees improved results through strategic keyframe selection based on temporal uncertainty
- Complex projects maintain high performance under real-world constraints by focusing annotation effort on the most informative samples
Efficiency Benefits
Efficiency in active learning can be viewed in terms of time and adaptation to changing conditions.
A. Reduced Time to Production
Active Learning enables faster deployment and iteration cycles.
- Can deploy earlier with an initial model trained on core cases
- Continuous improvement through targeted labeling
- Faster iteration cycles based on model performance
B. Dynamic Adaptation
Enables rapid response to changing conditions and requirements. Consider a Traffic Monitoring System, its adaptive capabilities allow it:
- Recognize new vehicle models as they enter the market
- Adjusts to road construction and temporary signage
- Handles seasonal changes in lighting and weather
- Adapts to changes in traffic patterns
Quality Improvement Benefits
In active learning quality largely depends on two factors, label quality and balanced dataset creation.
A. Better Label Quality
Label Quality determines how well the model learn the truth during training.
- Reduces annotator fatigue through focused attention
- Improves label quality by reducing cognitive load
- Enables better quality control of the labeling process
B. Balanced Dataset Creation
Balanced Dataset Creation refers to active learning’s ability to select samples that ensure proper representation across different classes and scenarios, especially in cases of imbalanced data distribution.
Example: Wildlife Species Classification
- Traditional: Over-represents common animals/common behaviors
- Active Learning: Prioritizes:
- Rare species with limited samples
- Nocturnal animal behaviors
- Animals in different seasonal conditions
- Various habitats and environmental contexts
- Result: A more balanced dataset capturing the full diversity of species and behaviors
Keeping the above points in mind, what can be the long-term benefits of active learning for computer vision applications?
Long term benefits
When it comes to long term benefits of active learning two factors must be kept in mind – Scalability and Improvement.
Scalability means:
- Easier to expand to new use cases. Once you establish an effective workflow for selecting and labeling data, it becomes easier to expand to new applications. For instance, if you’ve developed a successful active learning process for detecting cars in self-driving applications, you can apply the same structured approach when expanding to detect pedestrians or traffic signs, since the workflow and data selection strategy are already defined and tested. This allows organizations to grow their AI capabilities more efficiently without needing to rebuild their entire data collection and labeling process for each new use case.
- More efficient use of labeling budget
- Faster model updates and improvements
Continuous Improvement means:
- Regular identification of valuable new cases
- System actively identifies and prioritizes areas where model shows poor performance or high uncertainty, then collects more training examples of those specific scenarios
- Better adaptation to changing data distributions
The strategic value of Active Learning is particularly evident in domains where:
- Labeling costs are high
- Expert time is limited
- Data distributions change frequently
- Edge cases are particularly important
Organizations implementing Active Learning can expect to see benefits across multiple dimensions, from immediate cost savings to long-term improvements in model quality and maintainability.
Types of Active Learning
In this section, we will discuss the types of active learning. Specifically, we will focus on pool-based active learning, stream-based active learning, and query synthesis active learning. For each type, we will have an overview, key characteristics, applications, and advantages so that we will have a structured form of understanding.
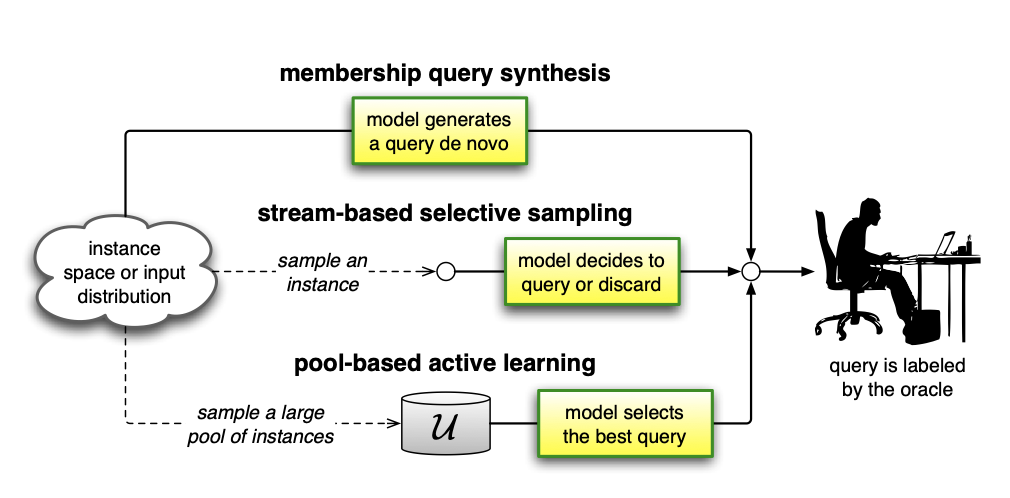
Pool-Based Active Learning
Overview
Pool-based active learning is the most commonly used approach in practical applications. It operates on a large static pool of unlabeled data and selectively chooses the most informative samples for labeling.
Key Characteristics
- Static Dataset: Works with a predefined set of unlabeled examples
- Batch Selection: Can select multiple samples simultaneously for labeling because of which it is widely used by deep learning models.
- Selection Strategies:
- Uncertainty sampling: Selects samples where the model is least confident in its predictions, helping identify hard-to-learn cases that could improve model performance when labeled.
- Diversity-based selection: Chooses samples that are different from what’s already in the training set, ensuring broad coverage of the data distribution and reducing redundant labeling
- Expected model change: Identifies samples that would cause the largest updates to the model’s parameters if labeled, prioritizing data points with the most potential impact on model behavior.
- Query by committee: Uses multiple models to vote on predictions for unlabeled samples – those with the most disagreement among models are selected for labeling since they represent challenging or ambiguous cases.
Suitable Applications
Here are some of the suitable applications for pool-based active learning. These applications uses large pool of unlabeled dataset.
- Image classification
- Text categorization
- Document sorting
- Sentiment analysis
- Medical image diagnosis
Advantages
- Pool-based active learning can leverage relationships between data points through techniques like density-based sampling and cluster analysis. For example, if several images contain similar visual features, the algorithm can select the most representative sample from that group for labeling, avoiding redundant annotation of highly similar examples while ensuring coverage of the feature space.
- Suitable for offline learning scenarios because in pool-based active a large pool of unlabeled data is provided. This allows it to evaluate and find relationships between the data points which is essential for clustering.
- Supports batch processing for quick processing for the images.
Stream-Based Active Learning
Overview
Stream-based active learning, also known as sequential active learning, processes data points one at a time and makes immediate decisions about whether to request labels.
Key Characteristics
- Sequential Processing: Evaluates examples one at a time
- Immediate Decision Making: Decides whether to query each instance
- Query Threshold: Uses thresholds to determine label necessity. Essentially, a query is a confidence cutoff value that determines whether to request human labeling for an incoming data point – if the model’s confidence is below the threshold, human annotation is requested, while predictions above the threshold are automatically accepted.
- Memory Efficient: Unlike pool-based active learning this doesn’t need to store all unlabeled data which can lead to memory limitations. Because stream-based active learning works well with a single sample at a time it tackles the issue of memory limitation.
Suitable Applications
Here are some of the suitable applications for stream-based active learning. These applications use a single sample at a given point of time.
- Social media monitoring
- Sensor networks
- Online anomaly detection
- Real-time classification tasks
Advantages
- Suitable for real-time applications: Stream-based active learning makes real-time decisions about whether incoming samples need labeling, but the actual human labeling typically happens asynchronously in a separate workflow. The selected samples are queued for human annotation while the model continues processing the incoming stream using its current knowledge, making it suitable for applications like content moderation where immediate classifications are needed but can be refined later. This approach allows the system to balance the need for real-time processing with the practical constraints of human labeling speed, while still benefiting from expert input to improve the model over time.
- Handles concept drift: Stream-based active learning can detect and adapt to concept drift (changes in data distribution over time) by continuously evaluating new samples and identifying when predictions become less reliable, triggering more frequent requests for human labels in those cases. This allows the model to naturally adapt its decision boundaries as the underlying patterns in the data evolve, making it particularly useful for real-world applications where data distributions aren’t static.
- Adaptable to resource constraints: It processes one sample at a time and uses simple decision criteria (like thresholds) to determine label necessity. This makes it suitable for resource-constrained environments like edge devices or mobile applications where storing and processing large batches of data isn’t feasible.
Query Synthesis
Overview
Query synthesis is a unique approach that generates synthetic examples for labeling rather than selecting from existing data points.
Key Characteristics
- Synthetic Data Generation: Query synthesis algorithms actively generate new training examples rather than selecting from an existing pool. These synthetic examples are created through techniques like Generative Adversarial Networks (GANs), interpolation between existing samples, or parametric models. The generation process is guided by the model’s current understanding and areas of uncertainty.
- Exploration Focus: The algorithm specifically targets regions of the feature space where the model shows high uncertainty or where training data is sparse. This targeted exploration allows the model to investigate decision boundaries more efficiently than methods that rely on existing samples. The approach is particularly valuable when the natural data distribution doesn’t adequately cover important edge cases or rare scenarios.
- Domain Knowledge: Success in query synthesis heavily depends on domain expertise to ensure generated examples are realistic and meaningful. Domain experts must validate that synthetic samples maintain physical constraints, follow domain-specific rules, and represent plausible scenarios that could occur in the real world. This expertise helps avoid wasting computational resources on impossible or irrelevant synthetic examples.
- Active Exploration: Query synthesis actively generates new examples in uncertain regions of the model’s decision space rather than waiting to find them in existing data. For example, if a model struggles to classify cats at unusual angles, the system can generate synthetic images of cats at those specific angles to improve learning. This targeted generation helps the model quickly address its weaknesses through precisely created training examples.
Suited Applications
Here are some of the suitable applications for query synthesis active learning. These applications generate synthetic samples for labeling.
- Handwriting recognition
- Robotics learning
- Drug discovery
- Material science
- Generative modeling tasks
Advantages
- Can explore unseen regions of feature space: The system can generate examples in areas of the feature space where no real data exists, helping discover edge cases and corner cases that might be rare or impossible to find naturally.
- Not limited by available unlabeled data: Unlike traditional active learning that depends on an existing pool of unlabeled data, query synthesis can generate new examples on demand to meet specific learning needs.
- Potentially more efficient learning: By generating precisely targeted examples that address model weaknesses or uncertainties, query synthesis can achieve better performance with fewer training samples compared to methods that only use existing data.
- Custom-tailored queries: The system can generate examples with specific combinations of features or attributes needed to test hypotheses about the model’s decision boundaries or improve performance on particular cases.
Comparison and Selection Criteria
So far we have seen the different types of active learning but the question remains as to “when to use each approach?”
To understand which approach is better let’s discuss each approach with a scenario and learn why it would be the best approach for that scenario.
Pool-Based Active Learning
Scenario: Classifying images of artwork styles for a digital archive.
Why: With a large static pool of unlabeled images, the system can use techniques like uncertainty sampling to focus on ambiguous styles, leveraging deep learning models to improve classification accuracy while minimizing redundancy.
Stream-Based Active Learning
Scenario: Monitoring online product reviews for emerging trends or sentiment changes.
Why: Stream-based active learning can process reviews sequentially in real time, identifying low-confidence predictions for human labeling while adapting to shifting consumer sentiment trends efficiently.
Query Synthesis
Scenario: Training a model to classify rare astronomical events using synthetic telescope data.
Why: By generating hypothetical images of events in underrepresented regions of the feature space, the system can refine its decision boundaries and improve performance on rare but critical classifications.
The Core Challenges and Solutions in Computer Vision Active Learning
The Computer Vision dataset is rich in visual representation that is often expressed with high-dimensional structures like 3D. The high dimensions of the datasets make it complex to annotate, label, and segmentate. This section will discuss some of the challenges that computer vision data brings and how they can be solved using active learning.
High Dimension Data Complexity
Challenge: CV data contains rich spatial, temporal and semantic information that is difficult to efficiently annotate and learn from.
Solutions:
- Employ dimension reduction techniques before sample selection
- Use hierarchical sampling strategies that first select at coarse levels
- Leverage self-supervised pretraining to learn better feature representations
- Focus annotation effort on most informative dimensions/aspects
Annotation Effort and Cost
Challenge: Manual labeling requires significant time and expertise, especially for dense tasks like segmentation.
Solutions:
- Combine active and semi-supervised learning to leverage unlabeled data
- Use weak supervision and partial annotations where appropriate
- Implement interactive annotation tools with smart suggestions
- Break complex annotations into simpler subtasks
Label Noise and Ambiguity
Challenge: Visual data often has unclear boundaries, occlusions, and subjective interpretations leading to inconsistent labels.
Solutions:
- Design robust selection strategies that account for label uncertainty
- Implement consensus mechanisms across multiple annotators
- Use probabilistic labels rather than hard assignments
- Focus on high-confidence examples during early training
Long-Tail Distributions
Challenge: Real-world data has imbalanced class distributions and rare cases that are critical but hard to find.
Solutions:
- Employ class-aware sampling strategies
- Combine uncertainty and diversity metrics in selection
- Use data synthesis for minority classes
- Design evaluation metrics sensitive to rare class performance
Active Learning Techniques for Computer Vision
Active learning in computer vision can be classified under both traditional and modern deep learning approaches. Both of these approaches use different methods to label the dataset for various computer vision tasks.
Traditional Active Learning has the following characteristics. They are:
- Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decision trees, or k-nearest neighbors (kNN).
- Relies on explicit decision boundaries or feature representations for sample selection.
- Works well with small datasets and models with fewer parameters.
Deep Learning AL, on the other hand, has the following characteristics, they:
- Leverage deep learning models like convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers.
- Employ feature representations extracted from high-dimensional data.
- Require large-scale datasets and computational resources due to the data-hungry nature of deep learning models.
In this section, we will look into the four major areas in computer vision where active learning is used and how traditional and deep learning methods are used in each task.
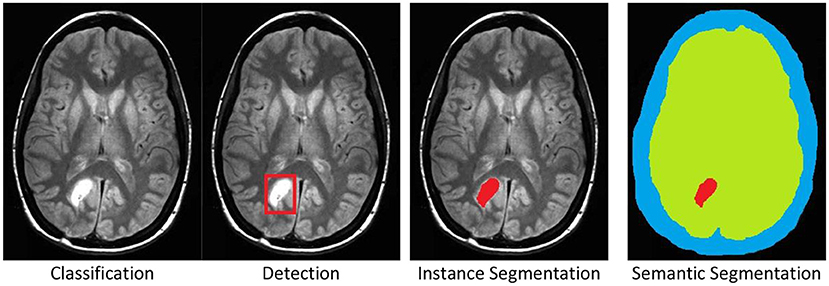
Image Classification & Recognition
In computer vision image classification and recognition are the fundamental tasks that lays the foundation for other tasks. These tasks involve classifying samples in the dataset with the appropriate labels. The goal is to build models that generalize well, even with limited labeled data.
Traditional Active Learning Approaches
In traditional active learning, scores are calculated for unlabeled samples to prioritize which ones should be sent for labeling. Samples with the highest scores, often those that the model finds most uncertain or impactful, are selected. The following notations are used:
- x: An unlabeled sample
- y: Predicted class
- P(y|x): Model’s predicted probability for class y given input x
- ŷ: Most likely predicted class
- ŷ₁, ŷ₂: Top two predicted classes
- |Y|: Total number of classes
- c: Each possible class in the classification task.
- Uncertainty-Based Sampling: These methods identify samples the model is least confident about. Note: While these sampling methods were originally developed for traditional machine learning, they are framework-agnostic and can be effectively applied to both traditional models and deep neural networks. The key difference lies in how the probabilities P(y|x) are obtained – through classical probabilistic models or deep network outputs.
- Margin Sampling focuses on samples with a small difference between the top two predicted probabilities:
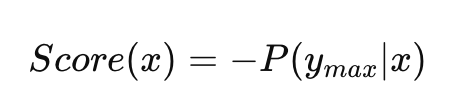
- Least Confidence selects samples with the lowest predicted probability for the most likely class:
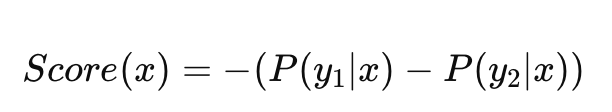
- Entropy-Based Sampling measures uncertainty using entropy:
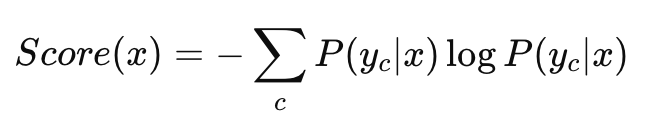
- Diversity-Based Sampling: It selects samples that are significantly different from those already in the training set, ensuring comprehensive data representation and reducing redundancy. For instance, clustering algorithms like k-means can identify distinct groups within data, or distance-based methods can prioritize outliers. You can explore more on this topic in this article by Lilian Weng or this one.
- Query-by-Committee (QBC): Builds a committee of models trained on the same labeled dataset with variations (e.g., different architectures or initializations). Samples that yield the greatest disagreement among committee members are selected for labeling. This article provides a hands-on implementation of QBC in scikit-learn.
Disagreement can be measured using Vote Entropy:
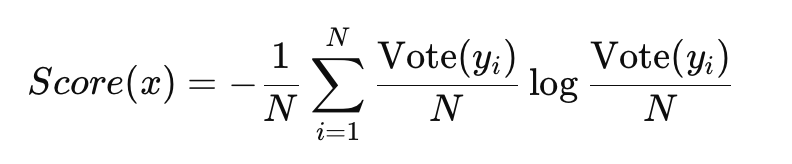
Deep Learning Approaches
In deep learning-based active learning, uncertainty estimation is key to determining which samples are most informative for labeling. The process involves sampling from the predictive distribution to capture model uncertainty, enabling the selection of high-impact cases.
- Monte Carlo Dropout: This method perform multiple forward passes through the neural network with different dropout masks to obtain a distribution of predictions. The variance in these predictions provides a principled measure of model uncertainty for sample selection.

- T: Number of Monte Carlo forward passes through the model.
- Mt: Model instance in the t-th forward pass.
- P(y∣x,Mt): Predicted probability of y for x under model Mt.
- Bayesian Convolutional Neural Networks (Bayesian CNNs): It incorporates uncertainty estimation into deep learning by treating model weights as probabilistic distributions rather than fixed values. This approach provides a principled way to quantify the uncertainty of predictions. . To estimate uncertainty, multiple samples are drawn from the posterior distribution over weights, producing a distribution of predictions for each input. The active learning algorithm then selects cases with high predictive variance or entropy across these sampled predictions, effectively targeting inputs where the model’s uncertainty is highest.In Bayesian CNNs, the posterior distribution over model parameters P(θ∣D) is inferred given the training data D. Predictions are then made by marginalizing over this posterior:
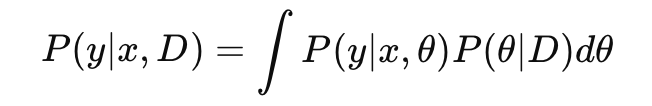
- y: Predicted class label.
- x: Input sample.
- θ: Model parameters.
- P(θ∣D): Posterior distribution over parameters given training data D.
- P(y∣x,θ): Likelihood of y given x and parameters θ.
- BatchBALD: BatchBALD extends BALD (Bayesian Active Learning by Disagreement) to handle batch selection more effectively. While standard BALD evaluates mutual information for individual samples independently, BatchBALD computes joint mutual information between a batch of samples and model parameters. This approach accounts for redundancy between samples – if two samples provide similar information about model parameters, selecting both would be inefficient. BatchBALD favors diverse batches that jointly maximize information gain about the model’s parameters.
- Expected Model Change: Measures the expected impact of labeling a sample on model parameters by evaluating gradient norms. Samples with high gradient norms are selected, indicating their potential to alter model behavior significantly.
- Loss Prediction Module: Attaches a small neural network to the main model to predict the loss for unlabeled samples. Samples with the highest predicted loss are prioritized for annotation.
Object Detection
Object detection goes beyond classification to locate objects in an image, typically represented by bounding boxes. This task demands instance-level annotations, which are costly and time-consuming.
Traditional Active Learning Approaches
- Uncertainty Sampling: Similar to classification, but focuses on instance-level uncertainties, such as the confidence of bounding box predictions.
- Decision Boundary-Based Methods: This method combines two key components: sliding windows and (SVMs) classification. The sliding window is a rectangular box that moves across the image in a grid pattern, taking fixed-size steps. At each position, the window creates an image patch. For each patch, features are extracted (like edges, textures, etc) and fed into a trained SVM classifier. The SVM returns a confidence score indicating how sure it is about an object being present. In active learning, we specifically look for patches where the SVM score is close to zero – these are points near the decision boundary where the classifier is most uncertain about whether an object is present or not. These uncertain patches are prioritized for human annotation. This approach was popular before deep learning but was computationally expensive since each image required evaluating thousands of window positions.
Deep Learning Approaches
- Region Proposal Networks (RPNs): Focus on high-uncertainty proposals, ensuring that challenging regions are prioritized for annotation. In active learning, RPN’s regional proposals can be evaluated for uncertainty. RPN proposes regions in images that might contain objects. It selects images where RPN’s proposed regions have uncertain predictions – meaning the model isn’t confident about what objects those regions contain. Such images are sent to the annotator for annotation.
- Generative Models: GANs can be trained to synthesize challenging examples by incorporating detection-specific metrics like bounding box uncertainty and object localization confidence into the GAN’s loss function. This helps generate images with hard-to-detect objects, complex occlusions, or unusual viewing angles. The synthetic data is particularly valuable when the original dataset lacks examples of certain object poses, scales, or interactions, allowing the detector to learn from generated scenarios that would be rare or expensive to collect naturally.
- Gradient-Based Selection (BADGE): Chooses samples expected to cause the most significant updates to model parameters, optimizing training.
- Bayesian Active Learning by Disagreement (BALD): Uses the mutual information between model predictions and parameters to identify samples where the model is most uncertain.
Image Segmentation
Image segmentation classifies each pixel in an image into predefined categories. This pixel-level annotation significantly increases the labeling cost. This is because:
- Granularity: Each individual pixel must be classified, compared to:
- Image classification: One label per entire image
- Object detection: Simple bounding boxes around objects
- Instance segmentation: Rough object outlines
- Precision Required: Annotators must carefully delineate exact boundaries between different regions/objects, often requiring zoom and pixel-precise work
- Complexity: Many images contain multiple overlapping objects and complex boundaries, requiring careful attention to properly segment
For example, labeling a medical image would require:
- Classification: Simply label “tumor” or “no tumor”
- Detection: Draw a box around tumor location
- Segmentation: Precisely outline every pixel belonging to the tumor, which takes significantly more time and expertise
This precision and granularity typically results in segmentation annotation taking 5-10x longer than simpler labeling tasks.
Traditional Active Learning Approaches
- Superpixel-Based Sampling: It doesn’t reduce the final annotation scope, rather it groups pixels into superpixels and selects uncertain regions for annotation. Essentially, it helps prioritize which regions to annotate first by grouping similar neighboring pixels into superpixels and identifying which of these groups are most uncertain/informative. But ultimately the entire image still needs to be segmented.
- Clustering-Based Methods: It ensures diverse regions in the image are sampled for labeling, reducing redundancy. Clustering-based methods for image segmentation don’t actually reduce the annotation requirements instead, they identify diverse, representative regions to prioritize for annotation first. This ensures the model learns from a variety of image patterns and textures early in the training process.
Deep Learning Approaches
- Pseudo-Labeling: Pseudo-labeling automatically assigns labels to regions with high-confidence (like sky or road surfaces) without human verification. The regions where the model is uncertain require manual or human annotation. This hybrid approach significantly reduces human labeling effort while maintaining quality, though confidence thresholds must be carefully set to avoid propagating model errors.
- Entropy-Based Sampling: Calculates entropy over the pixel probabilities in a region. Entropy in this context measures the uncertainty or “disorder” in the model’s predictions for each pixel in an image region. Higher entropy means the model is more unsure about the correct labels. Active learning strategies prioritize regions with high entropy for human annotation since these represent areas where the model is most confused and could benefit most from expert labeling.
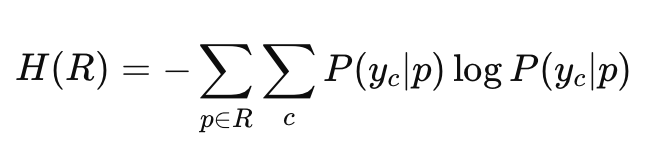
- R: A region in the image.
- p: Pixel within region RR.
- P(y_c∣p): Predicted probability of class y_c for pixel p.
- c: Each possible class in the segmentation task.
- GANs for Segmentation: GAN-based models can enhance this process by generating synthetic data allowing the model to learn distinctions without extensive manual labeling. These images are generated with corresponding synthetic segmentation masks that can supplement the training data, particularly for underrepresented categories. It is then validated by human annotators for quality control.
Video Recognition
Video recognition extends classification tasks to the temporal domain, requiring models to recognize patterns across frames.
Traditional Active Learning Approaches
- Keyframe-Based Sampling: Selects individual frames with high uncertainty. It is a method used in video recognition where the system analyzes individual video frames and selects the most uncertain ones for human labeling. These uncertain frames are typically those where the model has low confidence in its predictions, such as scenes with rapid motion, lighting changes, or complex object interactions.
- Temporal Clustering: Ensures that selected frames represent diverse segments of the video.
Deep Learning Approaches
- RNN-Based Approaches: The authors of this paper used RNN-based approaches to identify frame sequences where predictions show significant temporal variation or uncertainty. The paper describes using features extracted from high-dimensional video data through CNNs and then feeding them into an RNN architecture (like GRU) to analyze temporal patterns and identify which frames or sequences would be most informative for labeling.
- Temporal Consistency-Based Methods: Measures augmentation consistency to identify informative frames.
- Expected Model Change: Evaluates the potential parameter updates from labeling specific video frames, prioritizing impactful samples.
- Query-by-Committee: Uses multiple temporal models to identify frames or sequences with high disagreement. These models are time-based models or models that take the time factor into account. They are designed to extract patterns from sequential data where the current values depends on prior values like video frames, weather dataset, stock market, etc.
Summary Table of Enhanced Strategies
Practical Applications of Active Learning in Computer Vision
Case studies demonstrating the effectiveness of Active Learning
Image Classification: Active Learning has shown impressive results in medical image classification, particularly for disease diagnosis. For example, in diabetic retinopathy classification, researchers applied Bayesian-based CNN Active Learning strategy to screen retinal images. By selectively choosing the most uncertain cases for expert review, they achieved 92% accuracy while requiring doctors to label only about 20% of the total images compared to traditional approaches. This is particularly valuable since getting ophthalmologists’ time for labeling is both expensive and limited.
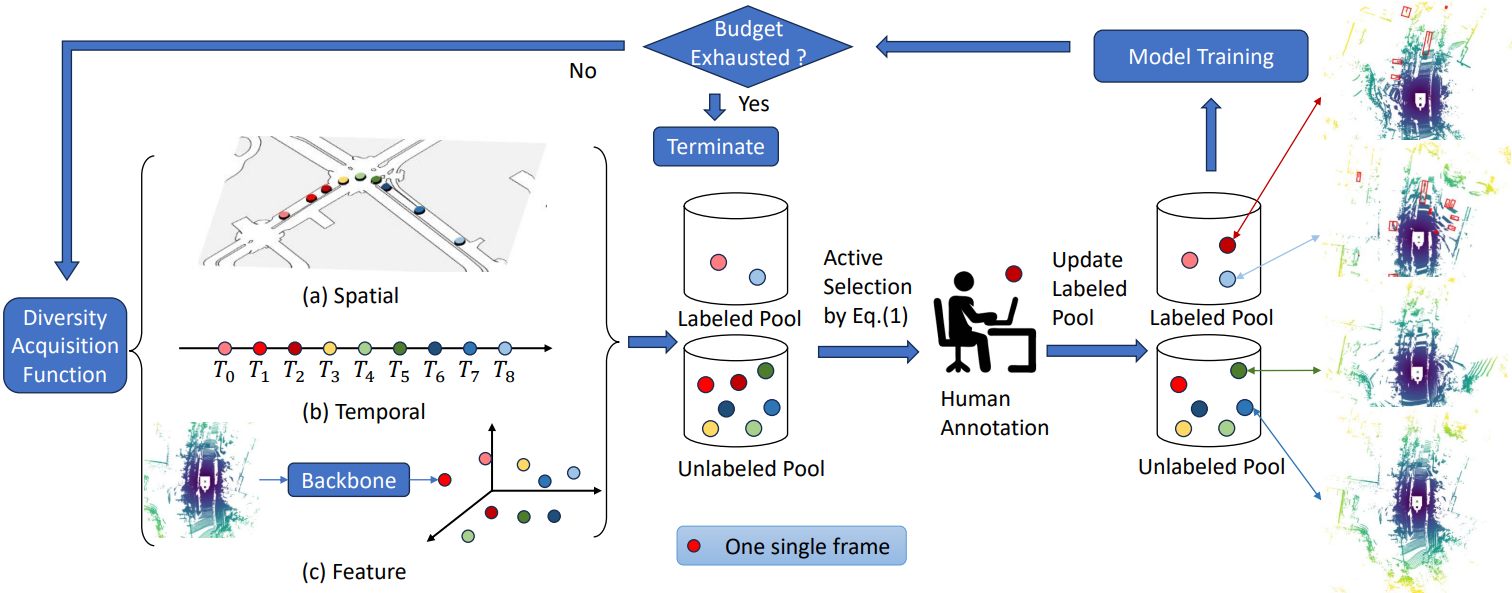
Object Detection: In autonomous driving, labeling all frames from vehicle cameras is prohibitively expensive. Active Learning has been effectively used to identify the most informative frames for annotation. One particularly interesting case study comes from Lin et al.’s work on 3D object detection, where they developed a diversity-based selection strategy that considers spatial and temporal information from LiDAR point clouds. Their approach achieved superior performance compared to traditional methods. This makes a huge difference in the real world where labeling 3D bounding boxes is extremely expensive.
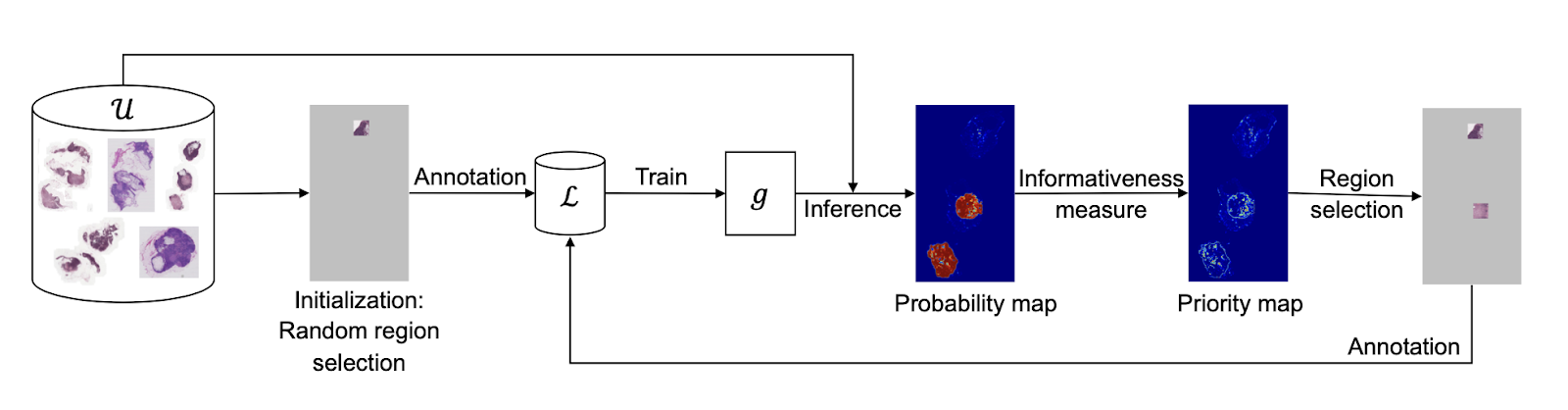
Semantic Segmentation: In medical image segmentation, where pixel-level annotation is incredibly labor-intensive, Active Learning has been a game-changer. For example, in breast cancer segmentation tasks, researchers have used region-based Active Learning approaches that divide images into superpixels and only request annotations for the most informative regions. This significantly reduces the annotation burden on radiologists while maintaining high segmentation accuracy. Some studies have reported achieving 90%+ of full supervision performance with just 20-30% of the labeling effort.
Implementing frameworks and tools
Let’s look at some active learning frameworks and tools. We will divide this section into two categories: Python library and web based tools.
Python Libraries
- DagsHub: DAGsHub provides a robust active learning solution for modern machine learning workflows, particularly for collaborative labeling efforts. It streamlines the process of data labeling and model improvement by combining version control, reproducibility, and active learning strategies.
- Facilitates iterative labeling by prioritizing data samples that maximize the model’s learning potential. It supports strategies like uncertainty sampling, entropy-based selection, and query-by-committee to identify valuable data points for labeling
- Provides various selection mechanisms, such as uncertainty estimation and loss prediction, to target data that would improve model performance.
- Enables users to manage and visualize data pipelines, keeping track of what’s labeled and what’s prioritized for future iterations.
- Libact: It is a Python package for active learning. It provides implementations of various active learning algorithms like uncertainty sampling, query-by-committee, and density-weighted methods.
- Easy to integrate with scikit-learn models and datasets.
- Libact is suitable for quick prototyping and testing different active learning strategies
- modAL: A modular active learning framework that offers a flexible interface to create custom query strategies and extend to different estimators. You can implement several query strategies like uncertainty sampling, expected error reduction, and density-weighted methods.
- Integrates well with scikit-learn and can be used with any supervised learning model.
- Provides a simple, yet powerful API for building active learning workflows
- Baal: Bayesian active learning library: A library to enable deep Bayesian active learning. It focuses on active learning with deep neural networks.
- Supports multiple uncertainty estimation techniques like MC-Dropout, ensemble, and switchable training
- Implements several active learning algorithms and acquisition functions
- Integrates seamlessly with PyTorch and supports popular datasets like MNIST, CIFAR, and ImageNet
- Suitable for active learning in deep learning scenarios
Web-based Tools
- Prodigy: A web-based annotation tool with active learning capabilities, developed by Explosion AI.
- Provides a Python API for customization and integration with existing ML pipelines.
- It can be run locally or through a cloud service.
- It offers a streamlined interface for annotators and supports collaborative workflows
- Amazon SageMaker Ground Truth: It is a fully managed data labeling service with built-in active learning capabilities.
- Provides pre-built workflows for common computer vision tasks like image classification, object detection, and semantic segmentation
- It automatically selects the most informative images for annotation based on model predictions
- Supports custom labeling workflows and integrates seamlessly with the SageMaker training pipeline
- Handles the scaling and distribution of annotation tasks, making it suitable for large-scale labeling projects
- Labelbox: It is collaborative web-based platform for image annotation with active learning support. Labelbox allows users to create labeling projects, import datasets, and manage annotation tasks.
- Provides a Python SDK for integrating active learning and model training into the workflow
- Can connect to various cloud storage buckets for importing and exporting data
- Offers a user-friendly interface for annotators and supports quality control measures
- DataTurks: A web-based data annotation platform with active learning capabilities. Supports tasks like image classification, bounding box annotation, and polygon annotation
- Provides an API for creating active learning projects, importing datasets, and exporting annotated data
- Offers a simple interface for annotators to label suggested images
- Handles annotator management, quality control, and data export
- Suitable for small to medium-scale annotation projects
How to select the right tool for your project?
When selecting a tool or framework for active learning in computer vision, consider the following factors:
- Scale of the annotation project
- Specific tasks and data types involved
- Required level of customization and integration with existing ML pipelines
- Ease of use and setup complexity
- Support for collaboration and quality control measures
- Pricing and hosting options (for web-based tools)
Python libraries like libact and modAL are suitable for quick prototyping, testing different active learning strategies, and integrating with existing Python-based ML workflows. These libraries offer flexibility and customization options but require more setup and management overhead.
Web-based tools like Prodigy, Amazon SageMaker Ground Truth, Labelbox, and DataTurks provide end-to-end solutions for data annotation with active learning capabilities. These tools offer user-friendly interfaces, collaborative workflows, and managed infrastructure, making them suitable for larger-scale annotation projects. However, they may have limitations in terms of customization and integration compared to Python libraries.
Evaluating the Impact of Active Learning on Model Performance
Understanding the impact of active learning on model performance is crucial for optimizing efficiency in machine learning workflows. In the following section we will discuss some of the best practices to evaluate your model’s performance. This section explores how active learning boosts model accuracy, improves label efficiency, reduces annotation burden, and accelerates learning curves, demonstrating its effectiveness in achieving superior results with significantly less effort and cost.
- Boost Model Accuracy:
- Utilize Active Learning to strategically select the most informative examples for labeling.
- Compare the accuracy of models trained on actively selected data vs. randomly selected data.
- Achieve comparable accuracy using only a fraction of the training data, demonstrating the effectiveness of Active Learning.
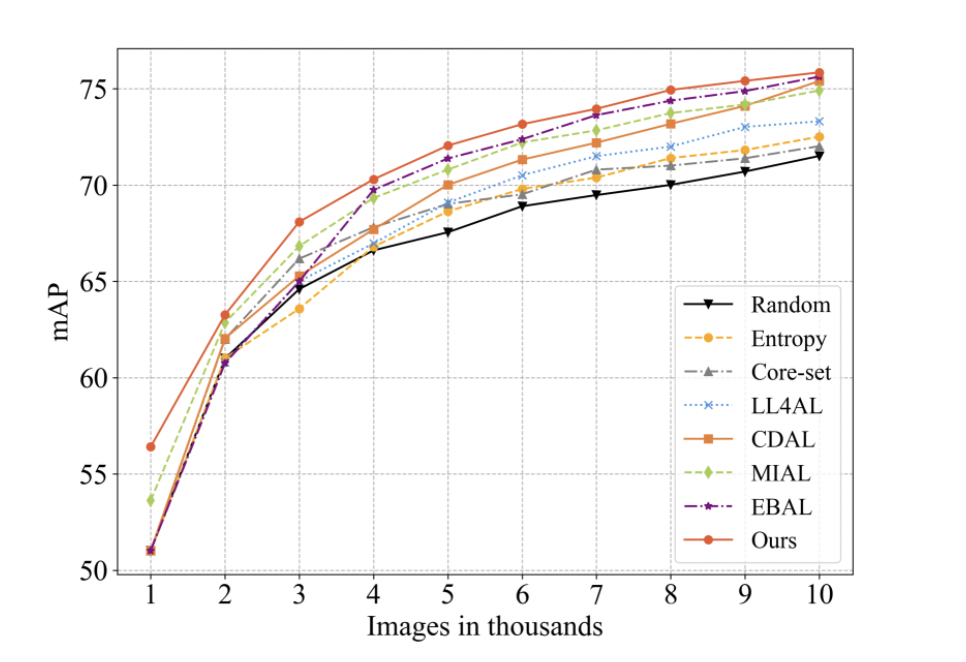
- Example: An object detection model achieving 0.9 mean Average Precision (mAP) with 5,000 actively selected examples vs. 20,000 randomly selected examples.
- Improve Label Efficiency:
- Measure the number of labeled examples an actively trained model needs to match the accuracy of a randomly trained model.
- Reduce labeling costs significantly without sacrificing performance.
- Track label efficiency over time to quantify Active Learning’s impact as you scale up.
- Example: Reaching 95% accuracy on a classification task with just 30% of the total training data using Active Learning, effectively reducing labeling costs by 70%.
- Reduce Annotation Burden:
- Estimate the time and cost required for annotators to label enough data to reach your target accuracy with and without Active Learning.
- Cut annotation time drastically by using Active Learning to select the most informative examples.
- Multiply time savings by hourly annotation costs to estimate total cost savings.
- Example: Achieving 0.75 mIoU (mean of Intersection over union) for a semantic segmentation model with masks that take 50 hours to annotate using Active Learning, compared to 200 hours with random selection, reducing annotation time by 75%.
- Accelerate Learning Curves:
- Plot accuracy vs. number of training examples for models trained on actively and randomly selected data examples.
- Observe faster model improvement in the early stages of training with Active Learning, indicating the selection of more informative examples.
- Achieve higher accuracy with the same number of examples, especially early on, making your pipeline more efficient.
- Faster improvement with less data demonstrates the effectiveness of Active Learning in accelerating the learning process.
Challenges and Considerations in Implementing Active Learning
Active learning can provide significant cost savings and efficiency gains for computer vision projects by carefully selecting the most informative samples to label. However, it’s important to be aware of potential drawbacks and to thoughtfully manage the trade-offs when implementing active learning. Here are some key considerations:
- Computational Overhead: Active learning introduces additional computational steps compared to standard supervised learning. Evaluating sample informativeness, updating models iteratively, and managing the interaction between the model and annotators all add processing time and complexity. This overhead can be especially significant for deep learning models on large datasets. To mitigate this:
- Use batch-mode active learning to amortize overhead across multiple samples per iteration
- Leverage parallelization and high-performance compute resources where possible
- Consider lighter-weight proxy models for informativeness scoring versus training
- Integrate active learning with existing ML pipelines to avoid duplicating work
- Cost-Benefit Analysis: While active learning reduces total labeling costs, it introduces development and infrastructure costs. Carefully assess whether the labeling savings will outweigh the upfront investment and maintenance burden, factoring in the scale of your dataset, cost per label, model complexity, and engineering resources.Active learning makes the most sense when you have a very large pool of unlabeled data, expensive labels (requiring expertise or significant time), and a complex model that needs many labels to perform well. It may not pay off for simpler problems. Start with a small pilot to validate the return on investment before committing fully.
- Class Imbalance and Distribution Shift: Many active learning approaches preferentially sample rare and difficult examples. While this can lead to faster learning, it also risks inducing a distribution mismatch between training and testing. Similarly, active learning can exacerbate existing class imbalances in the unlabeled data.Strategies to handle this:
- Mix in some random sampling to cover the input space
- Set selection budgets for under-represented classes
- Use distribution matching techniques when scoring informativeness
- Upsample rare classes and downsample common ones during training
- Employ importance weighting to align training and test distributions
- Developer Guidance and Monitoring: Active learning is not a fully automated process. It requires developer oversight to select strategies, set parameters, monitor data balance and quality, and decide when to stop. Plan for this ongoing “human-in-the-loop” effort in your project.Best practices:
- Understand your data and design your selection strategy around its characteristics
- Visualize and analyze the samples selected in each iteration
- Engage domain experts to vet subsets of the selected data
- Track model performance on a held-out set to validate learning progress
- Set clear stopping criteria aligned with project goals to avoid excess iterations
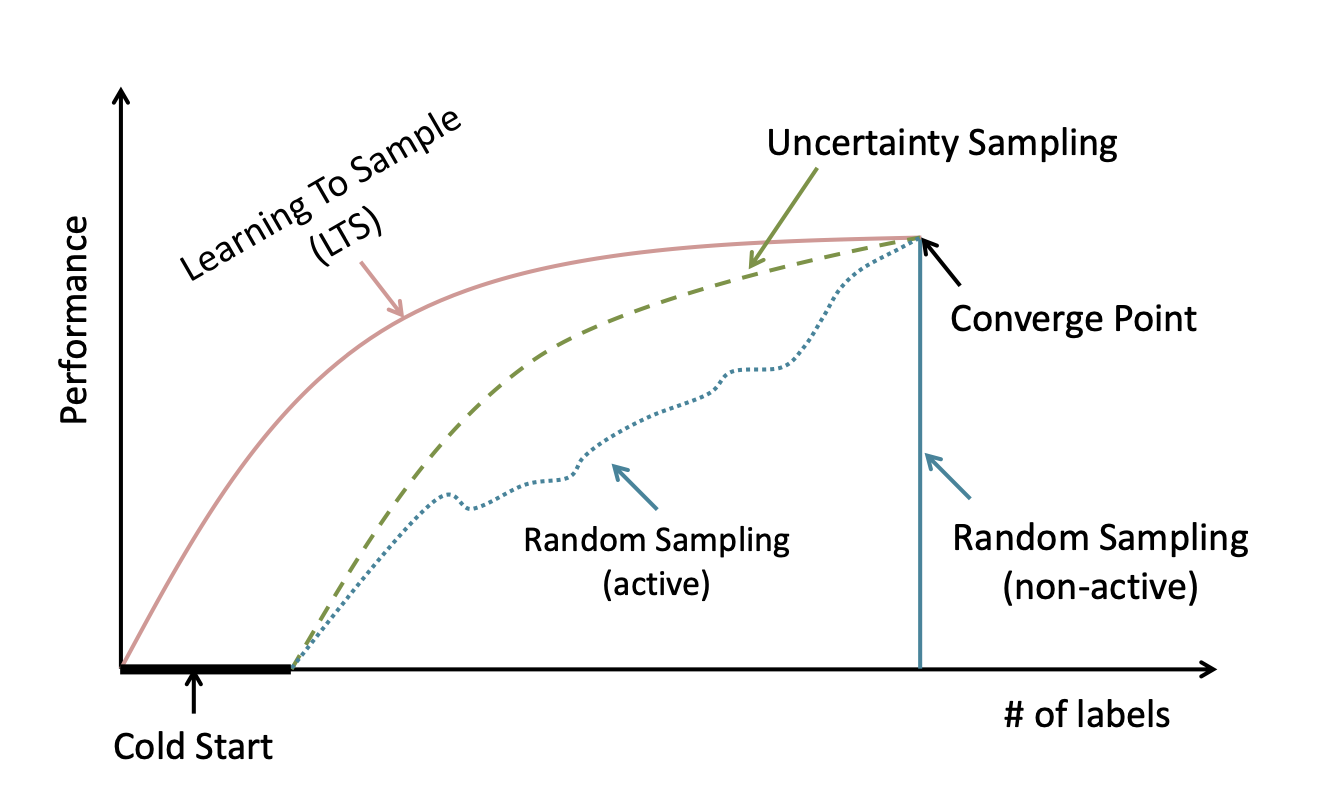
- Cold Start Problem: Active learners can struggle in the early phases of training when the model is too weak to reliably estimate informativeness. This can actually lead to slower convergence than simple random sampling at first.To overcome the cold start:
- Seed the initial labeled pool with a diverse set of representative samples
- Use a hybrid strategy that blends active selection and random sampling at first
- Employ transfer learning to initialize the model with quality feature representations
- Explore meta-learning, unsupervised pre-training, e.g. with contrastive learning, to improve early robustness
With thoughtful design and management, active learning can drive major efficiency gains for computer vision projects. The keys are to align the approach with your specific data and goals, adopt best practices to navigate the key trade-offs, and closely monitor the process to ensure it delivers on its promise. By following this advice, you can unlock the potential of active learning while sidestepping the pitfalls.
Future Directions in Active Learning for Computer Vision
In this section, we will discuss the future direction of active learning in computer vision tasks and applications.
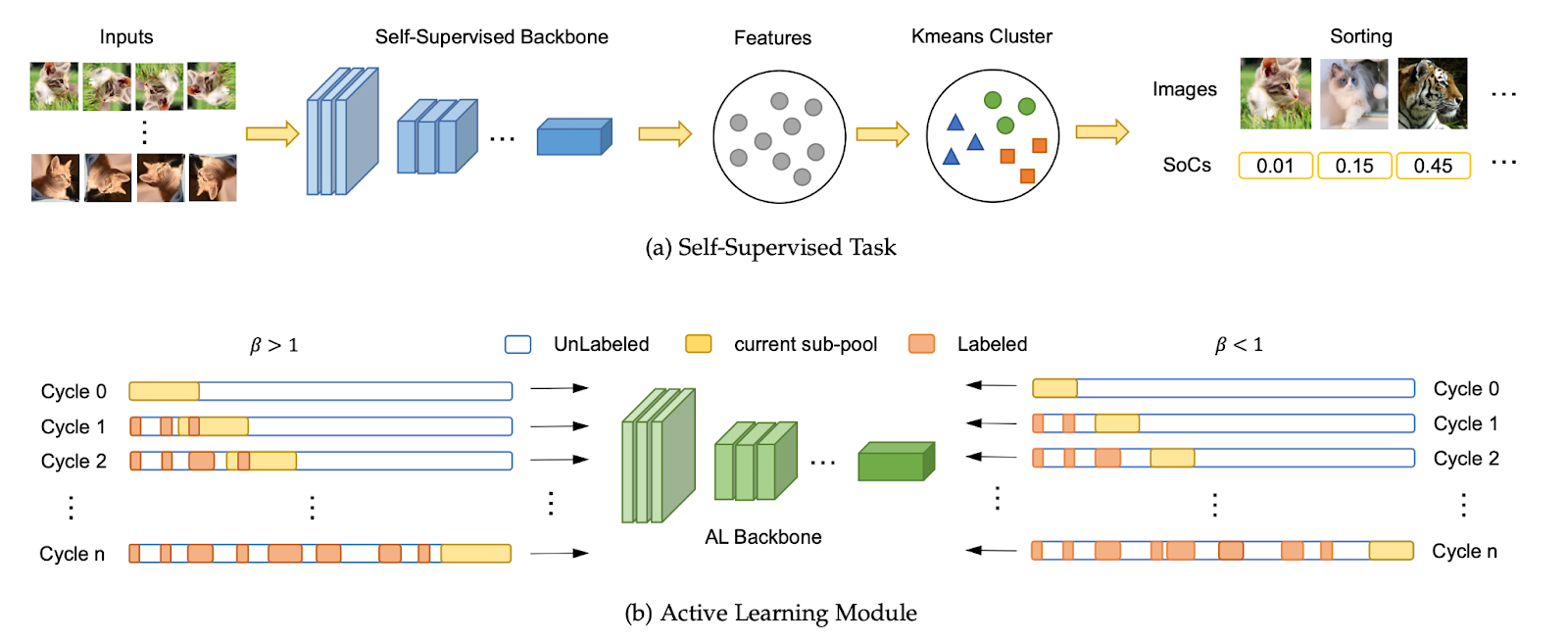
Integration with Self-Supervised Learning
Current Convergence
Self-supervised learning (SSL) and AL are increasingly converging in computer vision applications, creating powerful synergies that address the limitations of traditional supervised approaches.
- Pretrained Representations
- SSL provides robust feature representations through pretraining on unlabeled data
- These representations improve AL sample selection by offering better uncertainty estimates
- Reduces the “cold start” problem mentioned in the article’s challenges section
- Complementary Strengths
- SSL: Learns general visual features from vast unlabeled datasets
- AL: Identifies critical samples requiring human annotation
- Combined approach: More efficient use of both labeled and unlabeled data
Emerging Hybrid Approaches
- Contrastive Active Learning
- Uses contrastive learning to create better feature spaces for sample selection
- Improves diversity sampling by better understanding image similarities
- Reduces required labeled data by up to 60% compared to traditional AL methods
- Self-Paced Active Learning
- Automatically adjusts the difficulty of selected samples during training
- Integrates curriculum learning principles with AL. It involves adjusting the difficulty of selected samples dynamically during training, starting with simpler examples and progressing to more complex ones. This ensures smoother model training by aligning the sample complexity with the model’s learning stage, improving robustness and stability.
- Improves model robustness and training stability
Automated and Adaptive Systems
Next-Generation Selection Strategies
- Meta-Learning for Sample Selection
- Learning to learn which samples to select
- Adapts selection strategy based on dataset characteristics
- Automatically chooses between uncertainty, diversity, or hybrid sampling
- Dynamic Batch Selection
- Adaptive batch sizes based on model confidence
- Automatic adjustment of selection frequency
- Optimizes human-in-the-loop workflow
Advanced Uncertainty Estimation
- Ensemble-Free Uncertainty
- Novel architectures providing uncertainty estimates without ensembles
- Reduced computational overhead compared to traditional methods
- More reliable uncertainty estimates for deep networks
- Bayesian Neural Networks
- Improved variational inference methods
- Better calibrated uncertainty estimates
- More efficient sampling strategies
Integration with Modern Architectures
Vision Transformers and Active Learning
- Attention-Based Sample Selection
- Leveraging attention maps for informativeness estimation
- Better handling of long-range dependencies
- Improved selection for complex scenes
- Multi-Modal Active Learning
- Joint learning from image and text data
- Cross-modal uncertainty estimation
- More robust feature representations
Efficient Architectures
- Lightweight Models for Quick Assessment
- Proxy models for rapid informativeness scoring
- Reduced computational overhead
- Faster iteration cycles
- Neural Architecture Search
- Automatic optimization of model architecture during active learning
- Adapts to changing data distribution
- Improves efficiency-accuracy trade-off
Future Predictions
Most of the predictions in this section aligns with the growth and the acceleration of AI in general. We will at some point reach a point where labeling data in a short amount of time is not possible and leveraging active learning to automatically and collaboratively label data will be a feasible way.
In a short-term timeframe let’s say 1-2 years, AL can:
- Automate Workflows by:
- Increasing automation of the active learning pipeline
- Providing better integration with annotation tools
- Offering more sophisticated quality control mechanisms
- Improve Efficiency by:
- 50% reduction in required labeled data
- Faster convergence through better initialization
- More reliable stopping criteria
When talking about medium-term timeframe of 3-5 years, AL can offer:
- Autonomous Systems
- Enhanced Scalability
- Distributed active learning systems
- Better handling of extremely large datasets
- More efficient use of computational resources
Lastly, a long-term timeframe of 5+ years can allow us to witness:
- General Purpose Systems
- Domain-agnostic active learning
- Zero-shot transfer to new tasks
- Automatic adaptation to new domains
- Human-AI Collaboration
- More natural interaction between human annotators and AL systems
- Better understanding of human expertise
- Optimal division of labor between human and machine
Conclusion
To conclude this article let’s consider some of the major key points:
- Active Learning is a powerful methodology that strategically selects the most valuable samples for annotation, enabling models to achieve high performance with significantly less labeled data compared to traditional approaches.
- It is an iterative process that creates a feedback loop between the model and human annotators.
- Active Learning provides several key benefits:
- Improved efficiency by prioritizing the most useful data
- Reduced labeling costs by up to 80% while maintaining performance
- Faster model improvement, especially in the early stages of training
- Better handling of edge cases and imbalanced data distributions
- Successful case studies demonstrate the effectiveness of Active Learning across image classification, object detection, semantic segmentation and video recognition tasks. The applications range from medical imaging to autonomous driving.
- Implementing Active Learning requires careful design and monitoring to manage trade-offs around computational overhead, distribution shift, and the cold start problem. Best practices and automated tools can help navigate these challenges.
There is an exciting future that lies ahead for AL in many image processing domains. Apart from that, we will also see the integration of AL with self-supervised learning, meta-learning for adaptive sample selection, and the development of more automated and scalable AL systems. The future is gonna be interesting with many researched-based and growth-oriented startups paving the way for AL in data annotation and model development.
Source link
lol