
After the Segment Anything Model (SAM) revolutionized class-agnostic image segmentation, we have seen numerous derivative works on top of it. One such was HQ-SAM which we explored in the last article. It was a direct modification of the SAM architecture. However, not all research work was a direct derivative built on the original SAM. For instance, Fast Segment Anything, which we will explore in this article, is a completely different architecture.
Rather than using SAM (Segment Anything [Model]) as a model, Fast Segment Anything uses SAM as a concept, that “we can segment anything with the right architecture”. With this concept, Fast Segment Anything is a completely different architecture, pipeline, and process. What’s more innovative with this approach, as we will see later, is that almost every component of the pipeline is decoupled and can be swapped if needed.
What are we going to cover while exploring Fast Segment Anything?
- What was the motivation behind its creation?
- What is the methodology and architecture of Fast Segment Anything (Fast SAM)?
- How does it hold up against the original SAM model in run-time efficiency and compute?
- What are some real-world applications of Fast SAM?
What was the Motivation Behind Creating Fast SAM?
The primary motivation behind the inception of Fast SAM was creating a pipeline that had the properties of the original Segment Anything Model but tens of times faster.
Introduced in the paper Fast Segment Anything by Zhao et al. Fast SAM takes a multi-stage non-Transformer based approach to class-agnostic image segmentation.
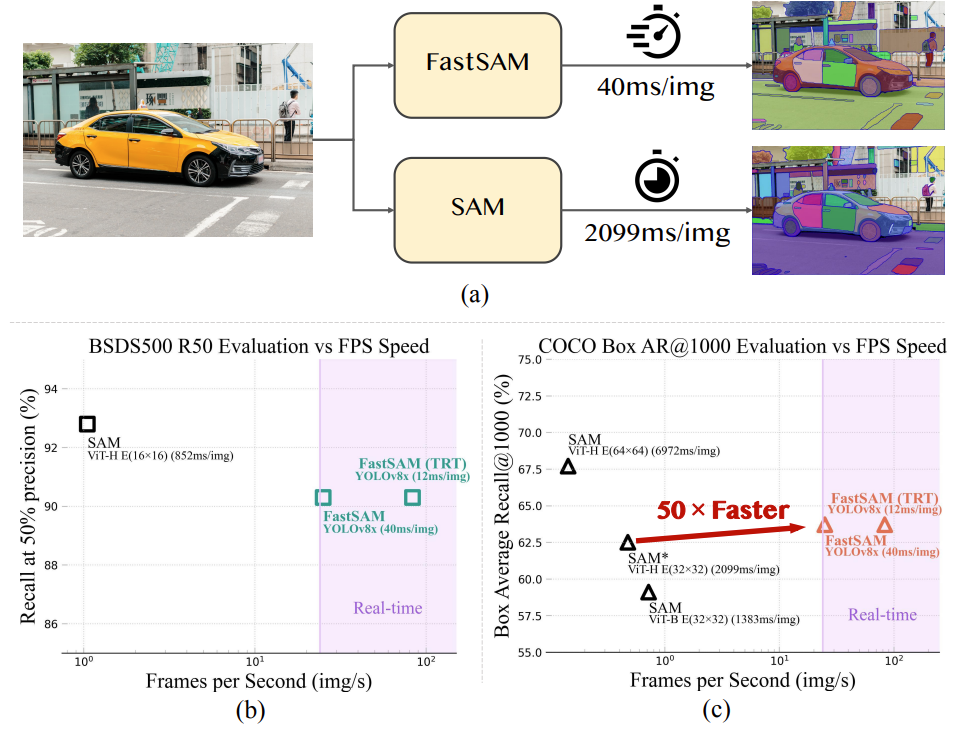
Although the authors recognize that SAM was a cornerstone in computer vision, they ponder over its industrial use case and address the following issues:
- SAM’s computational requirements are substantial. It employs a Vision Transformer backbone which is computationally heavy compared to its convolutional counterparts.
- Fast SAM decouples the segmentation, and prompt handling, making it a two-stage approach. This allows Fast SAM’s segmentation model to be trained independently without worrying about training the text prompt encoder.
What is the Approach and Architecture of Fast Segment Anything?
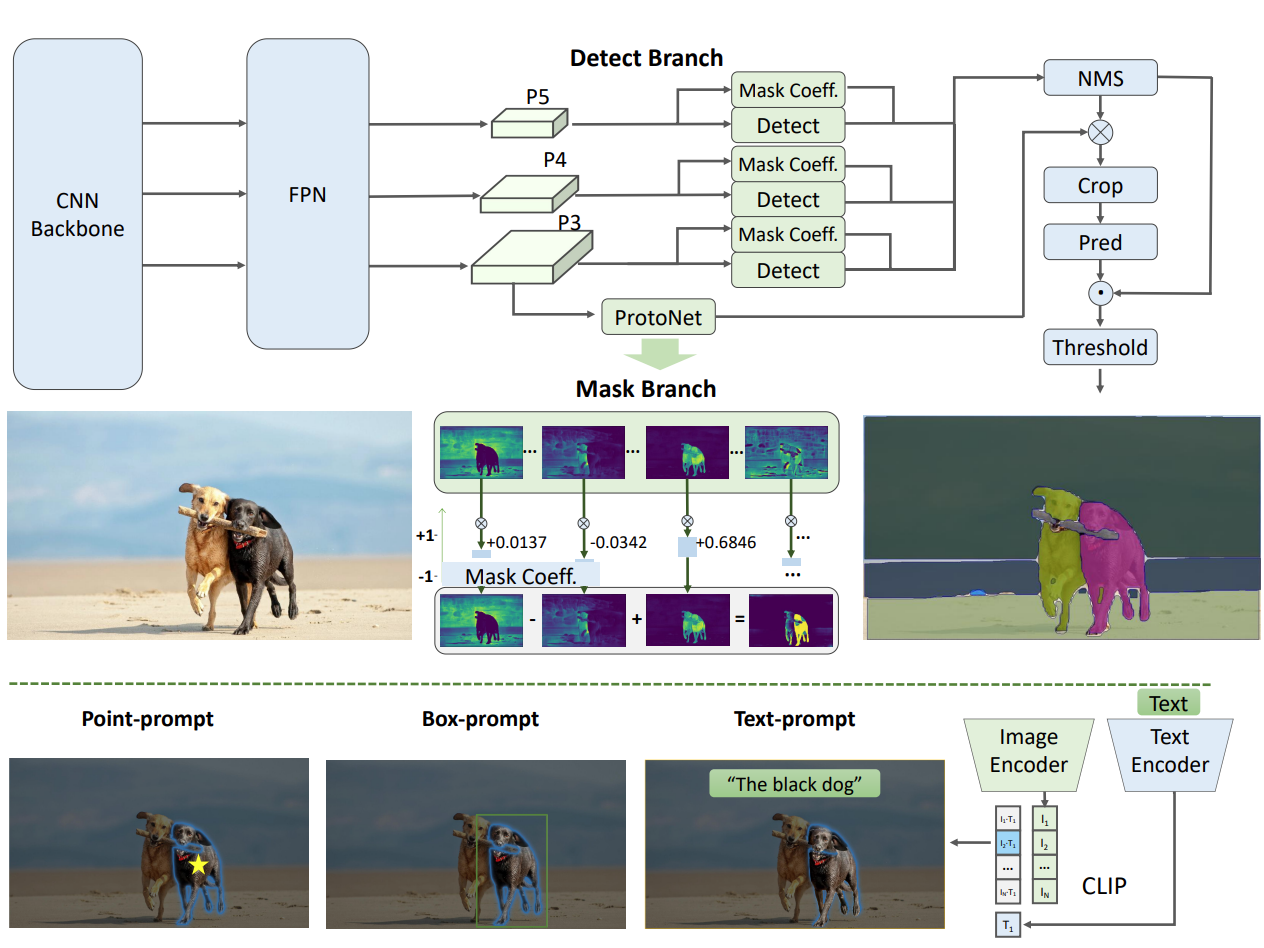
While SAM employs a single-stage architecture with a ViT backbone to segment anything, Fast SAM uses a two-stage approach.
Moving away from Transformer backbones, Fast SAM is built on top of YOLOv8-Seg, a CNN based instance segmentation model.
The following subsections explore the steps and stages of the model.
Training YOLOv8-Seg for Instance Segmentation
The authors start with training the YOLOv8-Seg model on 2% of the entire SA-1B dataset which is the primary dataset for training SAM. The training pipeline is built on top of Ultralytics.
It is difficult to find the exact details of how the model was trained on the dataset as SA-1B is a segmentation-only dataset. However, we can speculate a few things:
- SA-1B contains the RLE (Run Length Encoding) of masks for all objects in an image.
- The authors preprocessed the dataset to obtain the bounding boxes from the RLE and the x, y coordinates of all pixels for each object inside the bounding boxes.
- After converting into Ultralytics/YOLO format, they trained the model to obtain an instance segmentation model that can detect and segment all objects in an image.
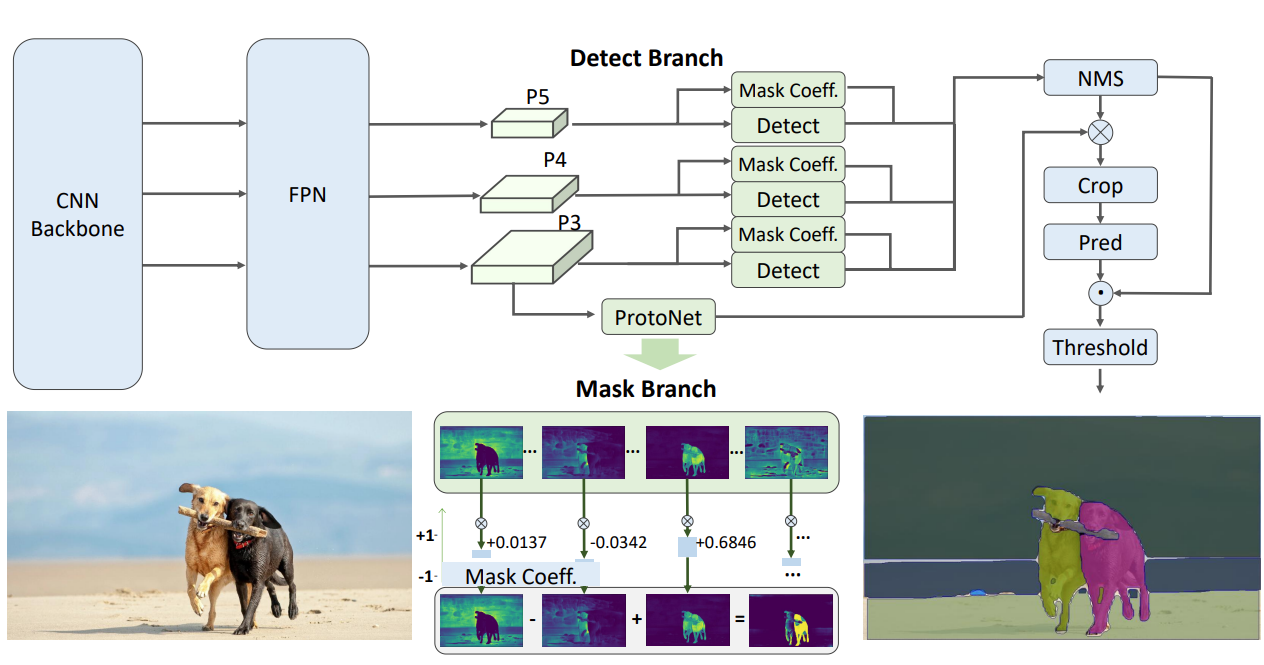
The authors call this stage All-Instance Segmentation. This stage gives the segmentation maps of all objects in an image.
Prompt Guided Selection
The second stage in the pipeline is dubbed “task-oriented post-processing”. This is a prompt-guided selection stage to obtain segmentation masks of specific objects using either of the following prompt strategies:
Point Prompt

The user provides a point (x, y coordinates) to obtain the mask for a specific object in the image. As the all-instance segmentation has already given us the masks of all objects in the image, this stage filters out the particular object mask based on the user point prompt.
This involves employing foreground/background points, multiple masks, and merging these masks to obtain the mask of interest.
Box Prompt

In this strategy, the user can provide bounding box coordinates as prompts for segmenting out particular objects. As a single bounding box can contain parts of several masks from the first stage, a processing step is necessary which determines the highest IoU mask with the bounding box region.
Text Prompt
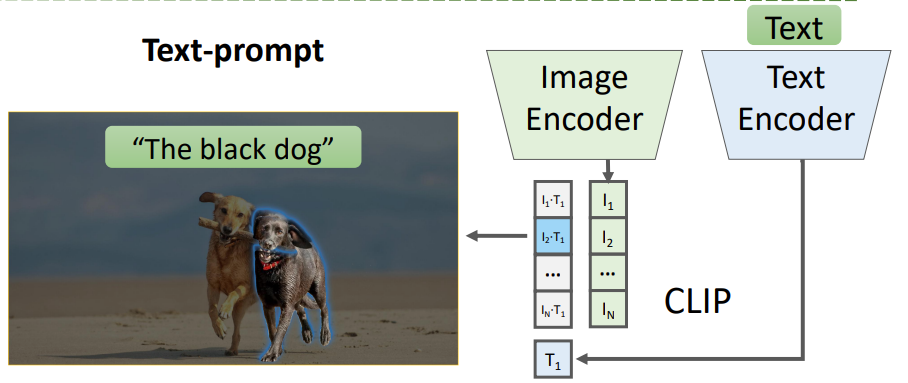
For text prompts, the Fast SAM pipeline uses CLIP. The CLIP model converts the user prompt into text embeddings. These embeddings are then compared with each of the segmented mask part embeddings of the image. The mask embedding which has the highest similarity score with the text embedding is retained in the output and other masks are discarded.
The only downside with this approach is that each mask embedding has to be compared with the text embeddings to get the highest score.
Training Details of Fast SAM
Here are the training details of Fast Segment Anything in brief:
- Primary model for All-Instance Segmentation: YOLOv8x-Seg model
- Input size: 1024
- Dataset size: 2% of the Segment Anything dataset
- Number of epochs: 100
All of this gives rise to Fast Segmentation Model that contains only 68 million parameters.
This concludes the model architecture and the strategy for training Fast SAM.
How Does Fast SAM Hold Up Against SAM?
For all experiments that we discuss further, the authors report the results and run-time on a single RTX 3090 GPU.
Let’s start with some standalone results of Fast SAM.

For a model with only 68M parameters, the results are surprisingly good. In all the images, the model is able to segment large as well small objects. These include the windows of buildings, the rearview mirrors of the car, dashed lines on the road, and even the backpack of the person far away.
Moving to a comparison of runtime between SAM and Fast Segment Anything.

Here, we have SAM Base and SAM Huge models against the Fast SAM model. We can see that in the everything mode, Fast SAM is more than 10 times faster than the SAM-B model.
Following are a few results for zero-shot edge detection.
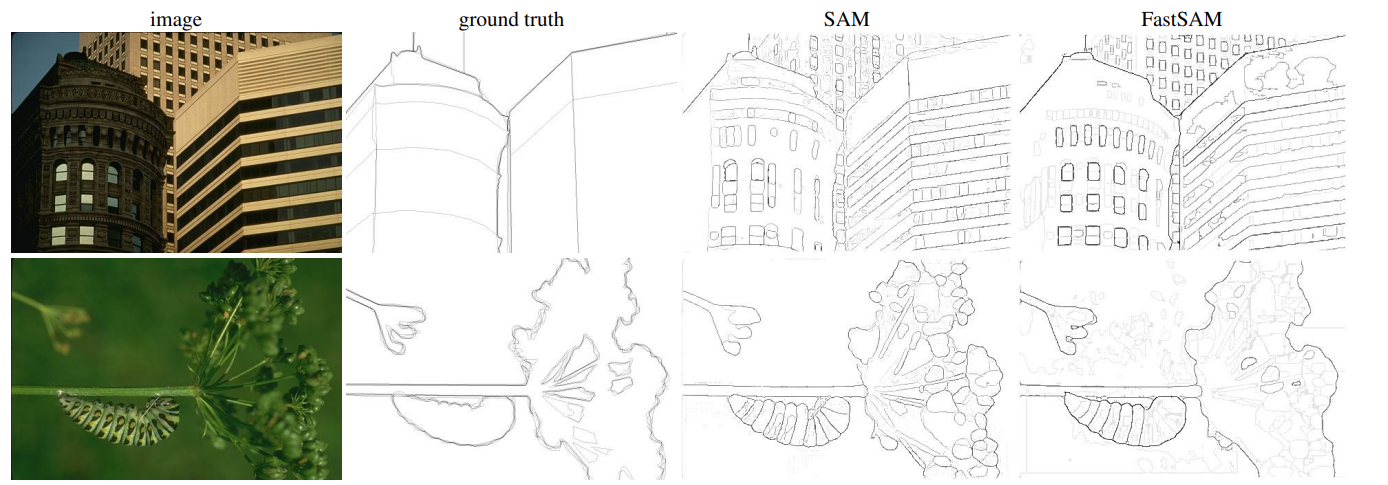
In this case, both SAM and Fast SAM predict more edges compared to the ground truth. The authors also point that out while further mentioning that some of the extra edge maps are logical as well.
Further, the authors use the ViTDet-H model to generate bounding boxes on images which are then passed on to both SAM and Fast Segment Anything as prompts for object segmentation.
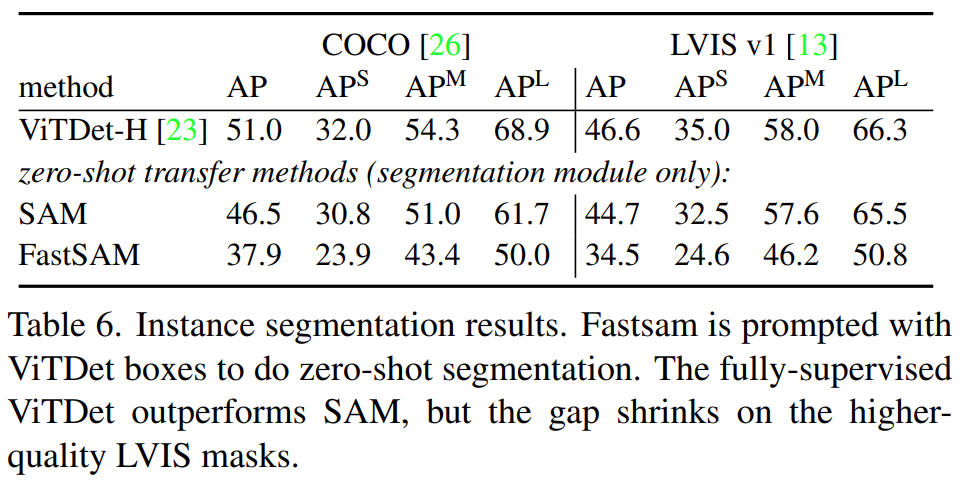
The above table shows the comparison between ViTDet-H (an instance segmentation model), SAM, and FastSAM. We can see that for zero-shot object segmentation based on bounding boxes, FastSAM falls behind. However, we can expect the gap to close soon if research continues.
Finally, we have object segmentation with text prompts.

Here, the user provides a free-form text prompt that passes through the CLIP encoder to generate text embeddings. These embeddings are compared with each of the mask embeddings that the Fast Segment Anything Model generates in the first stage. Finally, the most similar mask is retained.
However, the authors also point out that this is a sub-optimal process at the moment as the text embedding has to be compared with each of the mask embeddings.
Real-World Applications
The paper mentions several real-world applications of Fast SAM for near real-time object segmentation. We are not going into the theoretical details of each, however, the following subsections mention the application and the related images.
Anomaly Detection

Salient Object Segmentation

Building Extraction

It is highly recommended that the readers go through Section 5. Real-world Applications in the paper. I am sure that it will give beneficial insights into the applications of FastSAM.
Where to Try Out FastSAM?
Summary and Conclusion
In this article, we covered the Fast Segment Anything Model, a CNN based alternative approach to the original Transformer based SAM. Starting from the objective of the paper to the model architecture, approach, results, and real-world applications, we covered a lot of ground. I hope this article gave some new insights into this architecture.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol