
When working with big data, having a good CSV importer is essential. Yes, CSV is imperfect, but it is simple. Modern systems are driven by other formats – Parquet, Avro, Arrow, Orc, and others – but the CSV remains ubiquitous. To quickly grab data or do a proof-of-concept, CSV is often your friend.
“Quickly” is the operative word. It’s not complicated: When you want to quickly work with data, slow ingestion of a source CSV is annoying.
Too often this was the complaint of our users. Deephaven empowers people to work with both streaming and static data, and it has slick scripting and GUI methods for ingesting CSVs. Unfortunately, the CSV reader under the covers was slow for large sources – 5 minutes to read a 16G file. We felt our users’ pain.
We went hunting for an upgrade to the system’s CSV reader. We had 3 requirements:
- Written in Java.
- High performance–for speed and memory use.
- Good with type-inference: automatically pick the most appropriate data type by column.
The paragraphs below detail our journey to find, then develop a better CSV reader. For those less interested in the sausage-making, however, here are the Cliffs Notes….
We benchmarked Apache Commons CSV, FastCSV, Jackson CSV, OpenCSV, SimpleFlatMapper, and SuperCSV.
Though all were Java utilities – requirement #1 – none checked both of the other two boxes. Type inference was largely ignored, but we knew it was vital for ease of use.
Having found no turnkey alternative, for the reasons outlined later in the piece, we decided to write a new CSV Reader from scratch. It is now available at deephaven-csv on GitHub.
Here is what we think you’ll like about the deehaven-csv library:
-
It is fast.
For a good-faith 16GB file, containing 100 million rows and 8 columns of randomly-generated timestamps, booleans, strings, longs, and doubles, we found it to be 35% faster than the fastest Java CSV libraries, 3X faster than Apache Commons, and 6X faster than Python Pandas, despite the fact that we do automatic type inference and other libraries do not. -
Data inference just happens.
Though faster than the others, the Deephaven CSV Reader is the only one that also infers data types automatically on ingest. This makes working with the ingested tables easy. You can’t really be sure of the best-fitting data type for your column until you’ve looked at every last value: our library handles this automatically for you, without sacrificing performance. -
Fast double and DateTime parsing.
We enlist a third-party library for fast double parsing, and we wrote our own fast ISO DateTime parser. These implementations are radically faster than the ones provided by the standard library.
The exposition below and the benchmarking suite found at deephaven-csv on GitHub tell the full story and the lessons we learned along the way. We look forward to your engagement in the project.
Many driving use cases for Deephaven users revolve around its “Streaming Tables”, which are designed to handle real-time and dynamic data sources. However, many users use static, batch data as well: for stand-alone analytics or applications, or as context within the real-time workloads.
As with other engines, in the Deephaven system, every table column has a specific data type. In order to make file uploading as user-friendly as possible, we want our CSV library to be able to look over the whole input text and choose the most appropriate type automatically, on a per-column basis, without the user needing to specify it beforehand. None of the popular CSV readers provided this feature. This was one of our motivations for writing our own library.
In Deephaven’s core data engine we made several radical wagers: big technical bets that have major impact on the design of the system –bets we believe will uniquely empower users. We applied that same philosophy to our CSV reader problem.
We hypothesized that we could get better performance than existing solutions by eliminating short-term memory allocations, avoiding the String type, parsing columns concurrently, and various other optimizations. We did this work “clean room” style so that we wouldn’t find ourselves boxed in by the design choices of other libraries, especially because we were doing type inferencing in a two-pass style and we needed that to be as efficient as possible.
Starting from scratch gave us the freedom to refine areas of the implementation that we wanted to be as fast as possible. For example, because our typical datasets have a lot of timestamp and double values, we needed a very fast ISO DateTime parser and a very fast double parser. For timestamps, this meant doing away with the usual regex-based library implementation and hand-writing an ISO date/time parser ourselves. For double parsing, we ended up using Werner Randelshofer’s FastDoubleParser, which is a Java port of Daniel Lemire’s amazing fast_double_parser library.
We also sought to avoid memory and garbage collection pressure as much as possible: typical datasets will contain hundreds of millions of cells, and we would like to avoid creating hundreds of millions of temporary objects. We also sought to use concurrency wherever possible: in particular, we dedicate a thread to parsing the CSV format (field separators, quoting, etc.) and then we parse each column’s data in separate threads.
Measuring the deephaven-csv reader performance ex post facto, we are able to assess the relative effect of various optimizations. In the future, we may incorporate other libraries and retire some of our code if we can do so without affecting performance.
As you will see below, these optimizations, taken together, provide us with excellent performance. Our library is able to outperform a variety of well-known CSV libraries as well as Pandas, in all cases except columns of Strings. In this particular case, we perform respectably, but we underperform the two fastest Java libraries. Improving this will be a topic of future work. We expect this to be a back-and-forth process: we can adopt the clever techniques used by other libraries and they may be able to adopt some of ours as well.
I present below the various design choices and optimizations we made. Following that are graphs and a discussion of some JMH benchmarks.
Type inferencing intends to map a column of CSV data to the most appropriate type seamlessly on ingestion. For example, assume a column contained the following input text:
In this case the library would want to choose int as its data type (or perhaps even byte or short if a memory-constrained user opted for that). On the other hand, consider a column containing this input text:
Here the library would want to choose double as its data type (or perhaps float if a memory-constrained user opted for that). As a final example, consider a column like this:
Here, there is no numeric or boolean type that is suitable for the whole column, so the library would want to choose String for this column’s type. There are even some gotchas. Consider a column like this:
Here the library should choose char as the data type (assuming the user opted to enable char parsing); however, if the first line were 10 or even 01, the library would need to choose String instead.
Two-phase parsing
In general, the library doesn’t know column types ahead of time, so it may need to make two passes through the input data in order to properly parse it. This is not always necessary: when the library infers the correct type from the beginning and all the data in the column is consistent with the inferred type, there is no need for a second pass. In other cases, however, the library needs to rescan the input data a second time.
Note that the library never makes more than two passes through the input. In the first pass, it keeps a running guess of the best type for the column, and parses and stores the data in that column according to its current best guess. The library may refine its guess multiple times as it goes along. By the time it gets to the end of the input, it will have determined the best-fitting type for the whole column, and it will have parsed some suffix of the input data with this best-fitting type.
If the library is lucky, and its first guess was correct all along, then the “suffix” is actually the whole column and it is done. Otherwise, the library needs to take a second pass over the input, up to the start of the suffix, reparsing that data using the best-fitting type. Put another way, the library will make somewhere between 1 and 2 passes over the input, where the size of the second pass depends on the location of the ultimate data cell that happened to determine the type of the whole column.
As an example, consider the following input text:
Here, the library would start by inferring a column type of boolean, and would optimistically parse valid (case-insensitive) boolean literals until the fourth cell. However, flense isn’t a boolean literal, so at this point the library would decide that this column, in fact, needs to be String. The library would continue parsing input, parsing the last two entries (flense and false) as String. Now it has a validly-parsed suffix of the column in the finally-determined type, but it needs to redo the first three entries. So, in a second pass, it would reparse the first three entries (case-sensitive “True”, “FALSE”, and “true”) as String. Then the parse is complete.
Fast inference path for numbers of different types
When the type inference algorithm switches between different types that all happen to be numeric, it is able to do a faster second pass that does not re-parse the input text. Instead, it just reads back the previously-parsed data values and casts them to the correct type. Consider the following input text:
1
2
3000000000
4000000000
5.5
6.6
Here the parser would read and store 1 and 2 as ints, then (because 3000000000 is too large to fit in a Java int), it would read and store 3000000000 and 4000000000 as longs, and finally it would read and store 5.5 and 6.6 as doubles. At this point, we could have handled the reparse the same way we handle other second-phase parsing (namely, go back to the input text and reparse the first four cells as doubles). However, we saw a tantalizing optimization opportunity here that seemed too good to pass up. In the second phase, when the values are all numeric, the library goes back to the already-stored data values, reads them back in, and simply casts them to the best-fitting type rather than reparsing the input text. In this case, it casts ints 1 and 2 to double, then longs 3000000000 and 4000000000 to double. The casting operation is obviously significantly faster than parsing so there is a material performance gain here that was worth the extra programming effort.
The library owes its performance to a variety of optimizations working together. We discuss some of these below.
Avoiding allocations / reusing objects
The Java garbage collector is a marvel of engineering, and in most cases, the programmer needn’t worry about the overhead of garbage collection. Nevertheless, there are still some use cases where it pays to be frugal with allocations. We expect this library to be used with files that have hundreds of millions of elements. If we were not careful, this would translate to many hundreds of millions of heap-allocated objects, a burden for the garbage collector and a damper on performance. So inside our innermost loops we try to avoid allocations, and our design takes pains to reuse temporaries. When we work with pieces of the input data, we use a reusable ByteSlice type that refers to underlying byte[] storage rather than making temporary Strings. After all, the easiest kind of garbage to clean up is garbage that never existed in the first place.
Avoiding the String type
The Java String type has a fair amount of overhead. At the very least, it needs to store the Java object header, the text itself, the length, and perhaps some housekeeping fields like the cached hashcode. There may be further overhead if the underlying implementation stores text data in a separate array. The JVM has many opportunities to be clever, so calculating the exact amount of overhead involved is a task best left to experts. However, as a ballpark, it’s fair to assume that small Strings of the kind frequently encountered in this use case (having, say, 10-20 characters per cell) probably have 200% overhead or more. In our design, where we need to store the whole text column because we might need to reparse it, it is very inefficient to store each cell as a separate String. Instead, we pack all incoming text (encoded as UTF-8) into large byte[] chunks, and we maintain a linked list of those chunks. Separately, we maintain a data structure that knows the length of each cell. Because we need only sequential access rather than random access, this is sufficient to store the input data and iterate over it again if necessary. The reason we use a linked list of chunks is so that the garbage collector has the opportunity to release chunks earlier once our algorithm has iterated past them for the last time.
Multithreading
The library uses one thread to parse the CSV format (field separators, escaping, newlines, and the like) into multiple blobs of text, one for each column. Then the type inference and data parsing for each column can take place concurrently, using one thread for each column. This concurrency provides an extra performance boost when there are extra cores available.
FastDoubleParser
As previously noted, for parsing doubles we use Werner Randelshofer’s FastDoubleParser, which is a Java port of Daniel Lemire’s amazing fast_double_parser library. Not only does this provide increased raw parsing performance, but it also enables us to avoid untold millions of String allocations, because the only available overload for Java’s built-in Double.parseDouble takes a String.
Handwritten ISO DateTime Parser
One of the most pleasant surprises of our implementation was the performance gain we got from our hand-written ISO DateTime parsing code rather than using library code or regular expressions. Even though writing this code by hand was tedious, the performance gain (on the order of 20x and up to 100x faster in some cases) was well worth it. We have since become aware of other Java projects that do fast date-time parsing, and it’s possible we can either cut over or contribute to those projects instead of maintaining our own.
We benchmarked our code with JMH against some popular and high-quality CSV libraries:
The benchmarking code is all available in the Deephaven CSV project.
In our first benchmark, we created a large file, about 16GB in size, containing 100 million rows and 8 columns of randomly-generated data. The columns comprised a diversity of types: ISO timestamp, boolean, String, two longs, and three doubles. We stored the file on a RAMdisk in order to factor out disk I/O cost from the benchmarks. The test machine was an n1-standard-32 machine (32 VCPUs, 120 GB memory) on Google Cloud Platform.
Large file benchmark
This benchmark measures total runtime, so smaller numbers are better. Here, Deephaven did significantly better (at 98 seconds) than its nearest competitors, FastCSV and SimpleFlatMapper, both at about 134 seconds. It is unclear which of our optimizations contributed most to our performance, but we suspect that our concurrent design is giving us a big advantage here.
Performance vs. Pandas
Pandas performs poorly on our input file, taking about 620 seconds (over ten minutes) to read it; or 6.3X longer than Deephaven’s. The command line we used was:
/usr/bin/time python3 -c "import pandas as pd; df = pd.read_csv('/mnt/ramdisk/largefile.csv', parse_dates=['Timestamp'], infer_datetime_format=True, dtype={'String':'string','Bool':'bool'});"
We suspect the reason for this poor performance is that Pandas is optimized to deal with numeric data, not strings, and especially not timestamp parsing. When we compared Deephaven to Pandas on a numeric-only file (100 million rows and 8 columns, half of them longs and half of them doubles), Deephaven parsed the file in 93 seconds, whereas Pandas took a respectable 129. Again, we believe our performance improvement is due to our multithreaded parsing as well as our use of the FastDoubleParser library.
Type-specific benchmarks
In the benchmarks below, we drill into specific types to compare performance. These benchmarks measure operations per second, so larger numbers are better. In these benchmarks, we see that, except for the String case, Deephaven is able to significantly outperform these other libraries. The closest competitors are FastCSV and SimpleFlatMapper, which have similar performance.
Integer benchmark
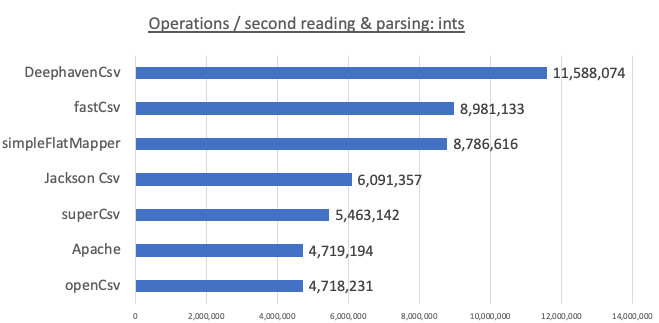
Our performance handily exceeds our nearest competitors (11.6 million ops/second for Deephaven vs. about 9.0 million for FastCsv, and 8.8 million for SimpleFlatMapper). This performance improvement likely comes from our concurrent parsing per column and our direct parsing of integers from the byte stream, rather than creating temporary Strings and calling Integer.parse() on those Strings.
Double benchmark
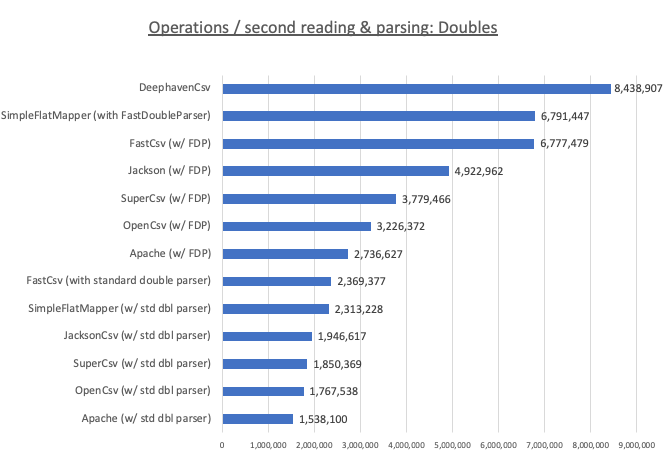
In order to understand how much performance gain is simply due to the use of the FastDoubleParser library, we compared Deephaven to other libraries using FastDoubleParser as well as the built-in Double.parse. As expected, the FastDoubleParser versions were always faster than the Double.parse versions. However, even with FastDoubleParse, Deephaven (~8.4 million ops/sec) was able to beat simpleFlatMapper and FastCSV (about 6.8 million ops/sec).
DateTime benchmark
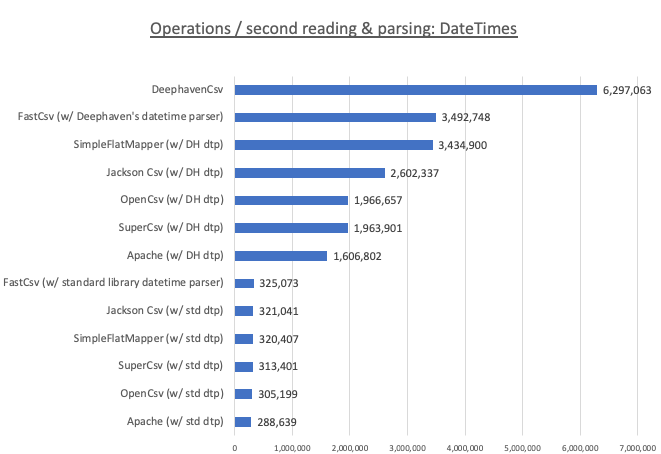
As we did with the Double benchmark, we tested the other libraries two ways: (i) with our own Fast DateTime parser, and (ii) with the standard LocalDateTime.parse(). Our Fast DateTime parser had significant advantage. Then we leveled the field and coupled all of the libraries with our Fast DateTime parser, Deephaven remained the clear winner — delivering 6.3 million ops/second, compared to 3.4-3.5 million for FastCsv and SimpleFlatMapper. Again, the concurrent parsing and the avoidance of String temporaries creation likely deserve the credit.
String benchmark
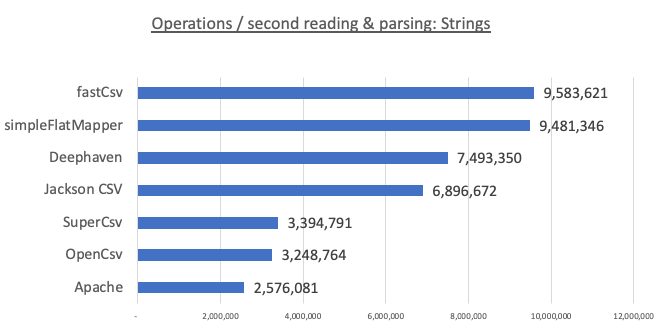
Here, we were squarely beaten by our usual competitors, FastCSV and SimpleFlatMapper. Our performance (7.5 million ops/second) was quite a bit less than theirs (~9.6 million ops/second). We suspect that since there is no parsing to be done, and because the cells need to end up as Strings anyway, our other overheads (such as reading the whole file into memory) get in the way and prevent us from doing as well as these other libraries in the String case.
For users that are well served by a performant Java CSV reader, and particularly for those that will benefit from the hands-free benefits of automatic type inference, the Deephaven CSV Reader is at your service. Implementation instructions can be found in the README. We welcome your feedback.
If a powerful data system might be helpful — one that is slick with huge CSVs while also being best-in-class with streams and other dynamic data, we encourage you to download Deephaven Community Core, or engage with us on Slack to support you.
Source link
lol