Generational features essays on the business of AI and spotlights outstanding AI companies and products. This essay began as a personal side project building knowledge graphs but evolved into an extensive exploration of knowledge copilots, retrieval augmented generation, and user experience. The main takeaway is that for knowledge intensive tasks, use multiquery RAG and thoughtful UX.
A knowledge copilot is a user’s thought partner, optimized for retrieving information from a knowledge base, reasoning through context, and synthesizing responses. It is much more than a wrapper around foundation models for generating copy or poems. For instance, a business analyst synthesizing the latest market news requires web access. A researcher may need to find relevant papers for citation. Features like image generation and empathic conversation, while valuable, are secondary to a knowledge copilot’s primary function: thinking and researching.
I write about this topic first because it fascinates me. Since 2016, I’ve been experimenting with crafting my own knowledge copilot using traditional NLP techniques. Second, it helps us become faster, better, and saner knowledge workers. Recent studies have shown that copilot-assisted research tasks are completed ~50% faster, without compromising quality. It eliminates the drudgery of sifting through documents and weblinks to find a specific information.
In the triad of retrieving, reasoning, and synthesizing information, retrieval is foundational. It lays the groundwork for the other two. Retrieval also addresses a key limitation of foundation models: their information is often outdated, and they don’t know everything. While their billions of parameters contain vast knowledge, this abundance can lead to ‘hallucinations’ or inaccuracies. Therefore, the capability to retrieve just the necessary contextual information is a crucial determinant of a knowledge copilot’s effectiveness.
So, let’s delve into Retrieval-Augmented Generation (RAG) and Knowledge Graphs (KG).
Retrieval-Augmented Generation combines retrieval-based and generative AI models. It first retrieves relevant information from a dataset, then uses this data to inform a generative model like GPT, thereby enhancing responses with more accurate and context-specific information. This improves the AI’s ability to provide informed answers based on external facts not contained in its initial training data.
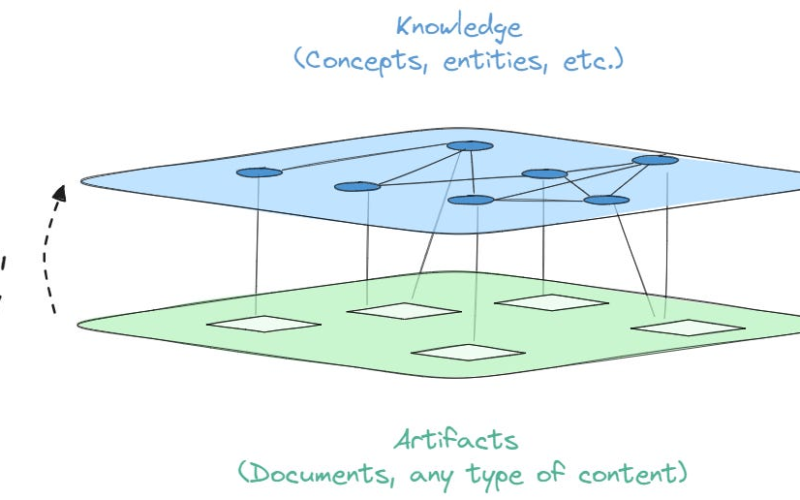
Recently, LLMs augmented with Knowledge Graphs have been gaining popularity. This grounds LLM responses in ground truth data, enabling more complex reasoning. In this essay, we focus on KGs derived from unstructured data like books and documents, as opposed to those constructed from structured data.
KGs represent human-and-computer readable synthesized representation of entities (persons, things, events), relationships (spouse, author, attendee), and properties (age, date) extracted from documents.

Instead of retrieving documents, why not directly retrieve information from a KG? To explore this, I built a KG-RAG, starting with constructing a KG. There is an established process to creating a KG.
-
Entity Extraction: Identify and extract entities from unstructured text data, such as persons, organizations, and concepts from text.
-
Relationship Extraction: Extract the relationships between entities.
-
Coreference Resolution: Coreference resolution determines when two or more expressions in a text refer to the same entity (i.e. he/she refers to the right entities)
-
KG Fusion/Construction: Fuse with an existing knowledge graph (lots of Match / Lookup queries). Otherwise, create a graph with entities and relationships as nodes and edges.
Traditionally, engineers would have to stitch a pipeline of custom models for each step. But instead I used GPT-4 Turbo as the single model to do everything. In a single prompt, I instructed the model to create a KG based on a lengthy essay by Paul Graham. Here’s a snapshot of the KG created.


The result was pretty comprehensive with ~100 entities and hundreds of relationships. KG-RAG could answer questions text chunk/document-based RAG could not. For example, it identified the books authored by Jessica Livingston’s partner (Paul Graham). But the document-RAG couldn’t and sometimes hallucinates by answering with the book Jessica wrote (a compilation of interviews with startup founders). With KG-RAG, I could also trace the logic of Jessica→dated→Paul→wrote→books→(Hackers & Painters, On Lisp). Let’s assume that the document-RAG is able to pull the right document chunks and answer correctly. Users would still have to read the retrieved text to validate and infer the same logical path.
Despite the advantages of KG-RAG, document-RAG is the right direction for knowledge copilots. The reasons being:
-
For a large corpus that exceeds the LLM context window, engineers have to build a KG pipeline with custom models. While there are generic off-the-shelf models, they still have to be finetuned to a specific domain.
-
Prompt engineering large context LLMs like GPT-4 Turbo or Anthropic Claude can streamline KG construction. But based on my tests, the results are highly sensitive to prompts. Tweaking a few words resulted in a materially different KG.
-
KG-RAG does not have the generalization that we expect from a copilot. It can only answer what’s captured in the KG, making it highly dependent on an already cumbersome and flaky process.
-
Conceptually and maybe even philosophically, knowledge is fluid. There are many perspectives on any single topic. Most people go through the exact same materials in school but end up with different takeaways. If you ask someone what is a cow, you’ll get different answers. For most people, it is an animal that produces milk and beef. For kids, it is black and white animal that produces milk. For butchers, it is a source of income with expensive cuts. We know what a cow is, but there are many ways to express it and they’re all correct.
Document-RAG works because vectorizing it retains enough generality for a copilot. KG-RAG is conceptually more attractive but document-RAG is the viable path for knowledge copilots. So which document-RAG strategy is the best? There are over a dozen strategies, ranging from simple RAG to sophisticated multi-agent set ups. To answer the question, I tested a few RAG strategies that represent different conceptual approaches.
To evaluate RAG strategies, I used text I knew well since I wanted to manually score the results instead of the industry practice of automating it with GPT-4. I used eight Generational articles I’ve written this year, which has ~13,000 words.
The scoring methodology was straightforward. Each RAG strategy started with a base score of 10 points. I crafted 10 questions requiring intricate reasoning or a deep understanding of the articles. The responses from each RAG strategy were assessed for “correctness”. For an incorrect answer or a failure to find the right information, I deducted 1 point. If the answer was partially correct, I subtracted 0.5 points. (To the engineers: yes, I am mixing retrieval and LLM generation evaluation together)
As a baseline, I also evaluated the performance of GPT-4 Turbo’s context window and the native RAG in OpenAI’s GPT, using the articles as the knowledge base. Details on the libraries and models used are available in the appendix. Now, let’s explore each RAG strategy and its underlying logic.
Simple/Naive RAG: This strategy takes an input and retrieves a set of documents with the most similar vectors.

Multiquery RAG: Generates multiple queries based on the user’s initial query. For each generated query, the most relevant documents are retrieved. The intuition is that by decomposing queries into distinct queries, we can capture the various perspectives better. The approach here is to transform the user query
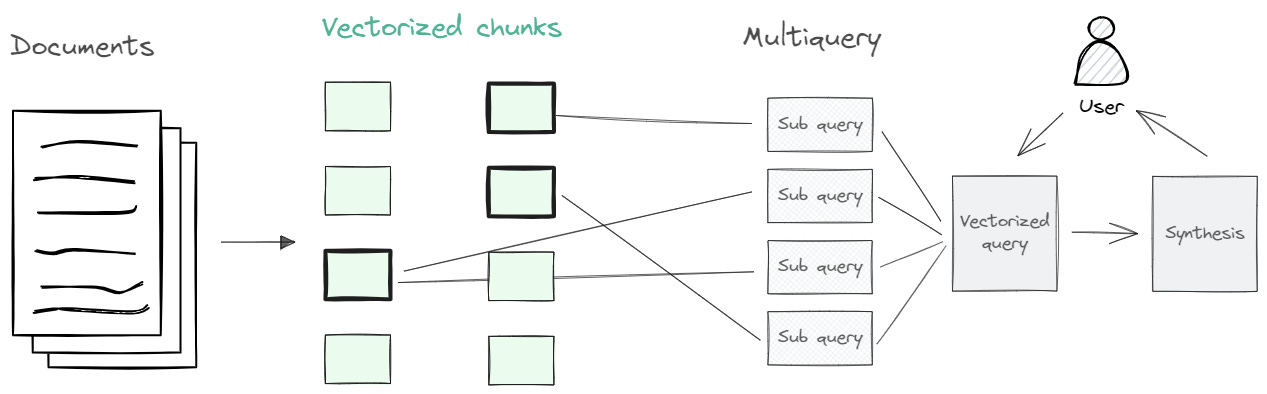
Hypothetical question RAG: This approach creates questions that can be answered from each text chunk. The user’s query is then matched with the most similar questions, and the associated ‘parent’ chunks are retrieved. The intent is to align the user’s queries with hypothetical questions, anticipating a closer match in their embeddings. The approach here is to further transform the documents

ReAct (short for reasoning and acting): An agent in this strategy iteratively retrieves chunks and reflects on whether there is sufficient information to respond or if more querying is needed. This mimics the process of traversing a knowledge graph, albeit through text chunks.

-
For simple use cases and smaller corpus, naive RAG works well enough. But if the corpus is large, more advanced RAG strategies might work better.
-
For best “accuracy”, agents work best. A ReAct agent iteratively acquire information and reflect on it, allowing for a traceable thought process akin to human knowledge work. For instance, when querying about Microsoft Copilot’s pricing versus Intercom Fin’s, ReAct would first retrieve a set of document chunks. If the information on Intercom’s pricing was missing, it would specifically seek out additional chunks related to Intercom.
-
If agents are impractical, use the multiquery approach. While both multiquery and hypothetical question RAGs had similar scores, I recommend using multiquery (or methods that modify the query instead of the corpus). It is more feasible to test and diagnose queries than going through the entire corpus. You’ll see products using this approach in the next section.
-
Context length is not everything. Extending the context length is an active area of development, with Anthropic’s Claude boasting a production model with 150,000 word context window (~500 pages). But stuffing the prompt with the entire corpus led to worse performance. Overloading with information, much like in humans, can be counterproductive.
-
Finally, OpenAI’s GPT models are frustratingly verbose. Prompt it to limit response length to a few hundred words. A cynical view of this is that OpenAI is financially incentivized to make their models verbose.
That said, agents are not the solution for knowledge copilots. ReAct-like agents does multiple retrievals behind the scenes. That can be slow and costly at scale. More crucial is that agents that iteratively reflect on intermediate results loses context. It could hallucinate or limit itself to an LLM’s stored knowledge. When I tested an advanced agent strategy called FLARE, the agent immediately assumes there is no pricing available for Microsoft Copilot because GPT-4’s knowledge cutoff was April 2023.
Humans should be steering the copilot during each turn. But it can be tedious to constantly type out more context and guidance. Imagine always having to type “please just search the top five Google results” or typing out acronyms like RAG. UX plays a crucial role in helping humans help copilots help humans. Below we go through examples of great UX from Perplexity and Bing’s new Deep Search.
-
Asking clarifying questions. This guides the retrieval to the right domain to search. For example, RAG has different meanings: a literal piece of rag, red/amber/green in project management, retrieval augmented generation, recombination-activating gene, and so on.


-
Showing the steps. It is helpful to see what the copilot did and how RAG worked. If the results seem off, this provides some level of auditability for users to adjust their queries. This transparency helps build trust with the copilot. Note that Perplexity might be using some form of multiquery RAG.

-
Citing sources. While most copilot products have this feature, simple UX features like showing logos and reference title improve the experience. Logos immediately signal the credibility and context of the information.

-
Constraining the search. Constraining the search surface area and setting the context can be effective. If I want to know the latest chatter, I should search Reddit. If I want to read up on the latest RAG papers, I should search Google Scholar.

Earlier, we noted that retrieval is the foundation for knowledge copilots. There is still reasoning and synthesis. But I’ll leave that to future essays.
Curated reads:
Commercial: An Introduction to Google Gemini
Technical: Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Corpus: ~13,000 words from eight Generational articles I’ve written over the past year
Libraries used:
Chunking scenarios
-
Smaller chunks (~500 words) to simulate the scenario of a large corpus with lots more chunks, making it harder to retrieve right information
-
Large chunks (~1,000 words) to increase the chances of retrieving the right the information
Models used
Source link
lol