
With the rapid expansion of the internet, social media, and mobile devices, video data generation has skyrocketed. These videos contain tremendous amounts of information, but effectively analyzing them at scale is challenging. Therefore, it is essential to identify objects of interest in the video for efficient analysis using segmentation and tracking. This article looks deeper into the nuances of video segmentation and discusses different segmentation methods, challenges, and the potential future of the field.
Video segmentation is the process of separating videos into multiple regions or key points of interest based on specific properties or semantics in a video scene. These semantics can often include object boundaries, motion, color, texture, or other visual contexts. The goal is to separate different objects and temporal events in a video thereby providing a more detailed and structured representation of the visual content. The problem of video segmentation is fundamental and challenging in the field of computer vision with various potential applications including autonomous driving, automated surveillance, augmented reality, and robotics to name a few.
Segmentation divides the pixels in an image into multiple regions based on similarities such as color or shape and generates the foreground mask from the background. Tracking is used to determine the exact location of the target in the video image and generate the object bounding box. Tracking is crucial for intelligent monitoring and scalable video search and retrieval, as it helps in identifying and localizing objects across frames. Although segmentation and tracking might seem like two independent problems, in reality, they are often quite inseparable. The solution for one problem usually involves solving the other problem implicitly or explicitly.
The mask generated through object segmentation provides reliable object observations helping tackle problems such as occlusion, deformation, and scaling fundamentally avoiding tracking failures. On the other hand, object tracking estimates the trajectory of moving objects in the sequence of images. This aids the segmentation algorithm in determining the object position and helps reduce the impact of fast-moving objects, complex backgrounds, and similar objects. Thereby, solving the problem of Video Object Segmentation (VOS) and Segmentation-based Object Tracking (SOT) together often leads to better performance whilst overcoming each other’s difficulties. The combined approach is often referred to in literature as Video Object Segmentation and Tracking (VOST). The image below demonstrates video segmentation in action. The frame-by-frame analysis highlights the separation of objects and the continuous tracking of said objects in a sequence of images.
Frame-by-Frame Video Segmentation (source)
Video segmentation can be done at several levels of granularity, ranging from individual items within a shot to complete shots or scenes. It can also be done at different points in the video processing pipeline, from raw video data to extracted features or annotations. Several approaches and techniques utilized for video segmentation are summarized in the diagram shown below.
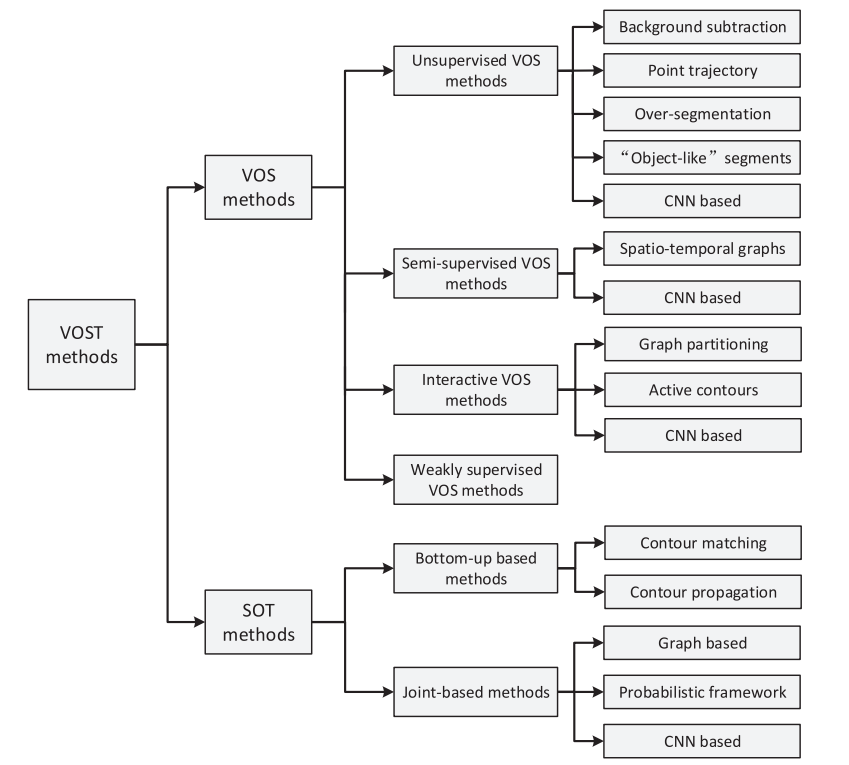
Taxonomy of video segmentation techniques (source)
SOT methods are designed to follow a single target object across frames, maintaining a bounding box around it as it moves. While SOT methods are also widely used, this article as the title suggests is focused more on video segmenting rather than object tracking, Thereby the next section will briefly explore the VOS techniques currently used in the industry.
Unsupervised VOS methods (UVOS)
As the name suggests unsupervised VOS methods rely on segmenting objects in a video in absence of any labeled data. The model should ideally learn the appearance and motion of objects in a video assuming that the objects in question have different motions or appear frequently and automatically segment them out.
Earlier UVOS methods were geometric in nature, primarily they followed classic background subtraction methods where the background appearance of each pixel is simulated and rapidly changing pixels are treated as the foreground. Any significant change among these layers represented a moving object. The pixels that make up the changed region are marked for further processing. Background subtraction methods can be further categorized according to the dimension of the utilized motion.
- Stationary backgrounds
- Backgrounds undergoing 2D parametric motion
- Backgrounds undergoing 3D motions
Although this approach saw some success, it relies heavily on the assumption that the camera is stable, slowly moving, and rigid.
Latter approaches in UVOS saw success in point trajectory techniques where motion information is analyzed over longer time periods in order to solve the problem of VOS. Motion can be a strong perceptual cue for segmenting a video into different objects. One such technique is the optical flow method, where a dense motion field which is the movement of each pixel from one frame to the next is estimated. The optical flow method assumes that the brightness is constant, that is when the same object moves across frames the brightness does not change. It also assumes that the object position doesn’t drastically change across consecutive frames. The diagram below shows the optical flow method in action. The motion field is estimated in each frame in order to figure out the moving object in the foreground and segment it.

Video segmentation based on optical flow/ point trajectory technique (source)
Unsupervised techniques are generally suitable for video analysis over video editing, especially in cases where arbitrary objects need to be segmented with flexibility. A widely used application of UVOS is the virtual backgrounds we find in video conferencing.
Semi-supervised VOS methods (SVOS)
Semi-supervised VOS techniques are fed with an initial object mask in the first frame or keyframes and then the model is allowed to automatically learn to segment the object in the remaining frames. Semi-supervised techniques provide the best of both worlds as they leverage the strengths of both supervised and unsupervised techniques to achieve higher accuracy and efficiency.
Broadly speaking SVOS techniques can be categorized into two main categories spatio-temporal graphs, and CNN-based methods.
- Spatio-Temporal Graph Methods – These methods create spatio-temporal graphs to propagate the initial object mask across video frames. Early approaches rely on hand-crafted features like appearance and motion cues to represent objects and form spatio-temporal connections. Techniques often involve pixel, superpixel, or patch-based representations, each with unique strengths in balancing computational cost and segmentation detail. Graph structures such as Conditional Random Fields (CRF) or Markov Random Fields (MRF) optimize label propagation across frames, aiming for label consistency and temporal coherence while addressing complex video dynamics like occlusion and fast motion.
- CNN-Based Methods – CNN-based SVOS approaches leverage deep learning for more advanced segmentation, divided into motion-based and detection-based types. Motion-based methods incorporate optical flow to propagate masks by tracking object motion, often using recurrent networks to model temporal dependencies. Detection-based methods, meanwhile, build appearance models from initial frames, fine-tuning to adapt as frames progress. Despite their robustness to temporal inconsistencies, CNN-based methods can struggle with rapid appearance shifts, demanding further innovation in adaptive appearance modeling for stable performance across varied video scenes.
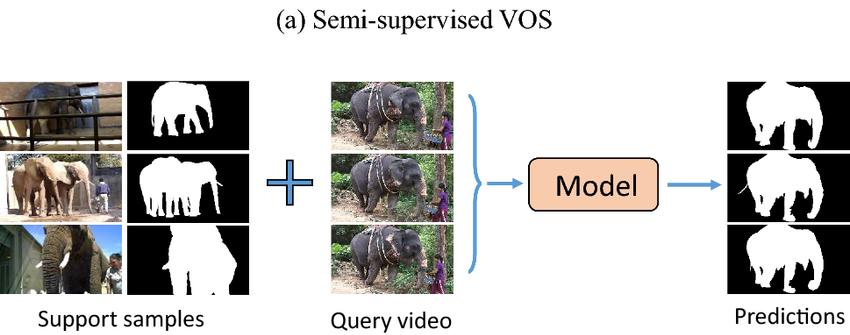
Semi-supervised VOS sample (source)
SVOS techniques require less labeled data and thereby are particularly useful in cases where obtaining labeled data is difficult or expensive. Compared to UVOS techniques SVOS is more flexible in defining target objects due to the human input. Furthermore, the unsupervised techniques used in combination can help improve the robustness and generalization of the segmentation results as they can consider additional context and information that may have been missed in the labeled data. SVOS is highly applicable for user-friendly settings such as video content creation on mobile phones. For example, with SVOS, a mobile video editing app can allow users to isolate or highlight a specific person or object in a scene, such as a pet in a family video, without the need for extensive manual editing. The app can provide accurate object segmentation with minimal user input, enabling quick and easy customization of videos.
Interactive VOS methods (IVOS)
SVOS models are designed to operate automatically once the target has been identified, while systems for IVOS incorporate user guidance throughout the analysis process.
IVOS combines techniques from graph partitioning, active contours, and CNNs to enhance accuracy and user control. Graph-based methods, such as graph cuts and random walker algorithms, define objects by segmenting frames based on user-defined markers, while active contour models use initial points to evolve curves that capture object boundaries as frames progress.
Meanwhile, CNN-based methods leverage deep learning to improve segmentation accuracy by integrating user feedback directly into model predictions. Rather than requiring input for every frame, the model uses user-provided input on keyframes, such as initial scribbles or additional markings to guide the segmentation process. In the image below, the user provides an initial scribble on the target object in the first frame, which the model uses to generate segmentation masks across the video. An agent then evaluates the quality of these masks using a quality vector and recommends frames where additional input may be beneficial. The user can add more scribbles on these recommended frames to refine the segmentation. This approach allows the model to adapt frame-by-frame based on user input, improving precision without requiring feedback on every frame. The model interpolates between frames, adjusting to changes in the object’s appearance or position to maintain accurate segmentation across the video.
Although touchscreen devices can sometimes make precise input challenging, IVOS techniques, especially those using CNNs, offer increasingly effective tools for achieving high-quality, multi-object segmentation in video content.

IVOS process example (source)
IVOS can obtain high-quality segments and is suitable for computer-generated imagery (CGI) and video post-production, where meticulous human intervention is possible.
There are varied applications of video segmentation and it is utilized in several industries.
- Real-time monitoring and Surveillance – Specific objects or people can be automatically identified in a live security camera feed using video segmentation which will be greatly beneficial in identifying potential threats or detecting suspicious behavior.
- Transportation – Video segmentation can also be used to analyze traffic camera footage to help identify and prevent accidents while monitoring driver behavior.
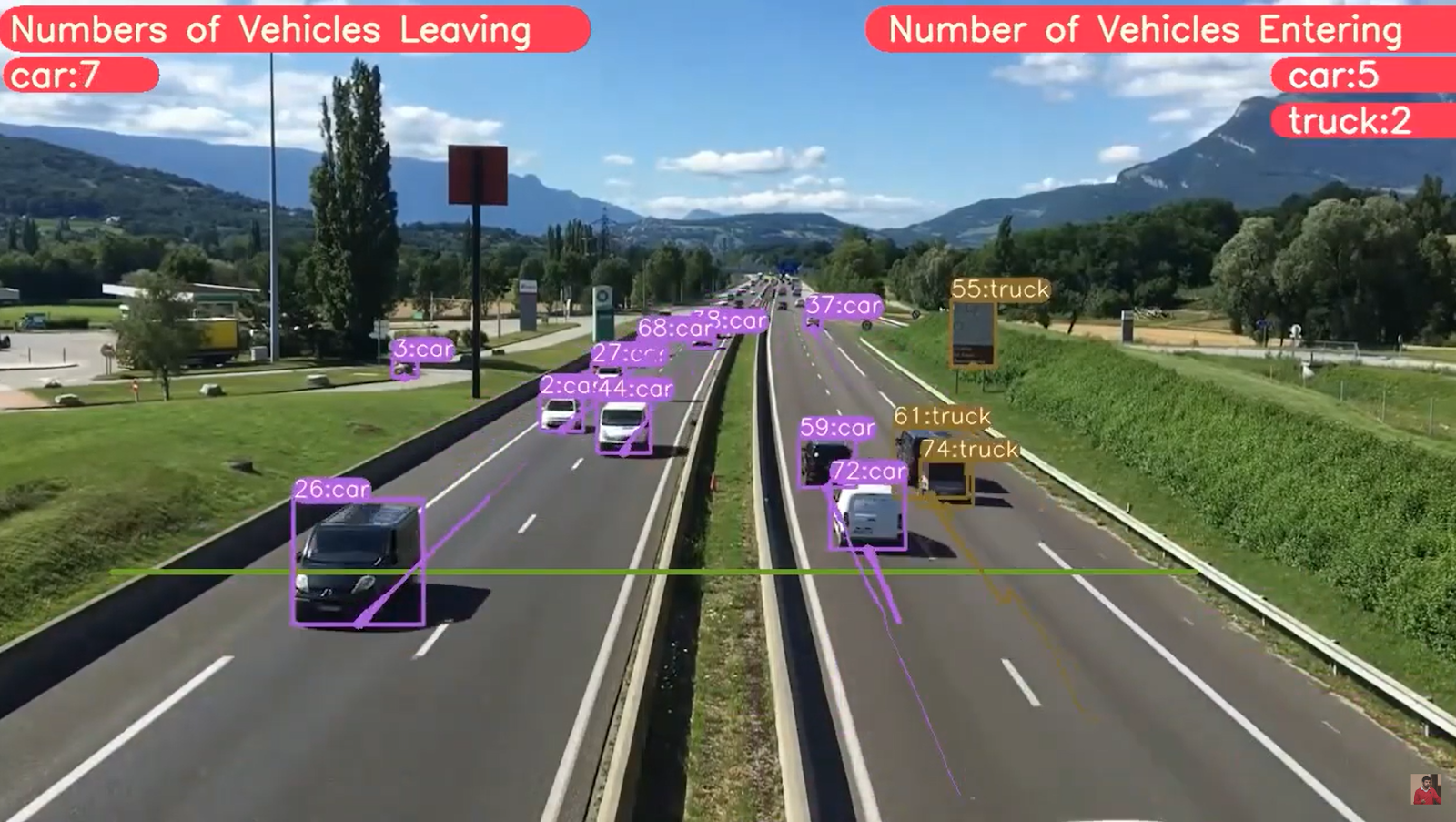
Example of video segmentation + AI to monitor real-time highway traffic footage (source)
- Video editing – In the modern social-media-driven world a crucial usage of video segmentation is in video editing tools. AI models can effortlessly identify and extract specific objects, scenes, or actions from videos. This saves video editors and content creators a considerable amount of time allowing them to quickly and easily edit their videos and produce high-quality content in large volumes.
- Sports analysis – Video segmentation is also beneficial in the field of sports. Analyzing player actions and tracking player movements can be analyzed to aid coaches in improving player performance and carry out strategic decisions.
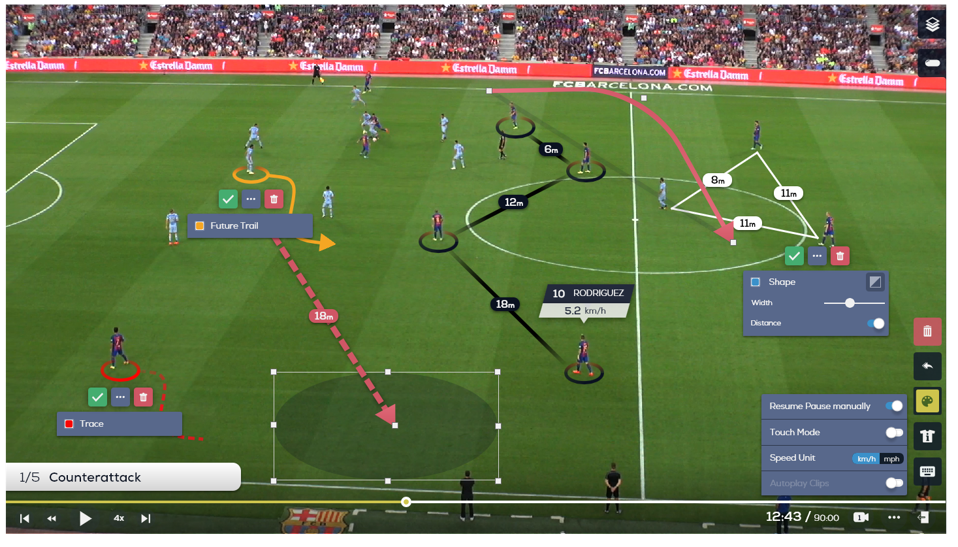
Real-time video segmentation and tracking of football players (source)
- AR/VR & Entertainment – Video segmentation is the key technology behind Augmented Reality (AR) and Virtual Reality (VR) as it allows for digital elements to be superimposed on real images. Integration of virtual objects into the real environment and tracking user/object movements in a virtual environment is possible due to video segmentation techniques.
- Healthcare – Video segmentation is greatly beneficial in the healthcare field as it can be used to monitor vital signs and detect anomalies in medical videos, such as endoscopies. It can also be used for continuous monitoring of patient movements and actions which will be beneficial in physical rehabilitation.

Video Segmentation techniques + AR for placing and trying out furniture in your home. (source)
Despite the numerous benefits and applications of video segmentation, there are also several ongoing challenges and limitations that need to be kept in mind when working with this technology. Some of them include,
- Video quality – Several factors that affect the quality of a video can also hinder the performance of video segmentation. This includes variations in lighting, resolution, frame rate, deformation, motion blur, scale variation, and more. Several efforts have been made over the years to deal with variations in object appearance, deep-learning methods, and multi-scale features to name a few. Color histograms and texture features also help in dealing with varied lighting conditions. Nevertheless, it’s still not perfect and there are many ongoing efforts to improve the performance.
- Occlusions and Complexity – When one object blocks the view of another object occlusions occur making it quite difficult to track. Efforts have been taken to deal with occlusions by utilizing multiple cameras or depth sensors. If the scene is complex in nature and there are multiple objects, events, reflections, and occlusions this can also make it quite challenging to identify and segment the content of the video.
- Temporal Consistency – If the contents of a video suddenly and significantly changes from frame to frame it makes it quite difficult to maintain consistency in segmentation across frames. Utilization of optical flow, motion features, and Recurrent Neural Networks (RNNs) can help alleviate this issue to a certain extent.
- Computational Complexity – Video segmentation can be quite computationally expensive especially when dealing with massive high-resolution video datasets. Efforts need to be taken to keep the segmentation process scalable so there’s minimal latency when performing real-time video segmentation.
Video segmentation techniques and their performance will evolve in the future and listed below are some upcoming trends in the field,
- Simultaneous VOS and VOT Prediction: Recent end-to-end approaches focus on predicting highly accurate pixel-wise object masks while simultaneously identifying the object’s bounding box location in VOS and VOT processes. Such an approach enhances both the speed and the precision, two critical factors in applications requiring immediate feedback without compromising on the segmentation deliverables.
- Fine-Grained VOS and VOT: The evolution of high-definition videos creates a need for the refinement and enhancement of the tracking and segmentation processes targeting small, fine-grained objects against diverse backgrounds. These features often have important semantic meaning which is vital for accurate object recognition thereby warranting the need for specialized techniques that will strive to ensure these features are accurately recognized and tracked.
- Generalization Performance of VOST: VOST algorithms face difficulties generalizing across varying scenes and object categories, especially in unconstrained environments. While deep learning and extensive datasets offer partial solutions, enhancing VOST methods to handle diverse appearances and complex motion remains a key research focus.
- Multi-Camera VOST: Working with numerous cameras can facilitate segmentation and tracking in a given set of shared environments. Different camera angles must be considered and techniques that allow for synchronized analysis in a multi−camera context enhance object tracking capabilities in a multi−camera configuration.
- 3D VOST: VOST in 3D spaces will be beneficial in applications such as autonomous navigation and 3D modeling. These techniques help in binding object edges in 3D space, which facilitates the performance of activities like obstacle avoidance and virtual reconstruction and simplifies complicated applications in robotics and infrastructure modeling.
In the video content creation age, the tasks of video segmentation and tracking have gained special relevance supported by the emergence of intelligent applications. More practices have demonstrated that these methods are widely used in a variety of fields such as in real-time observation, autonomous vehicles, video production, or healthcare where precision in tracking and identifying objects is crucial. With the rise of end-to-end deep learning methods, the VOST technologies have developed quite significantly showing various potentials such as multi-camera implementations, fine-grained object localization, and 3D rendering.
Nevertheless, the problem of obtaining high levels of generalization and computational efficiency across different, complex operational environments continues to be an open problem. Further development of VOST technologies will be directed at solving the trade-off between speed and precision, introducing better object recognition in cross-domain environments, and more optimized real-time processing providing opportunities for more comprehensive and flexible video analytics tools.
Source link
lol