Large language models (LLMs) have advanced beyond simple autocompletion, predicting the next word or phrase. Recent developments allow LLMs to understand and follow human instructions, perform complex tasks, and even engage in conversations. These advancements are driven by fine-tuning LLMs with specialized datasets and reinforcement learning with human feedback (RLHF). RLHF is redefining how machines learn and interact with human inputs.
What is RLHF?
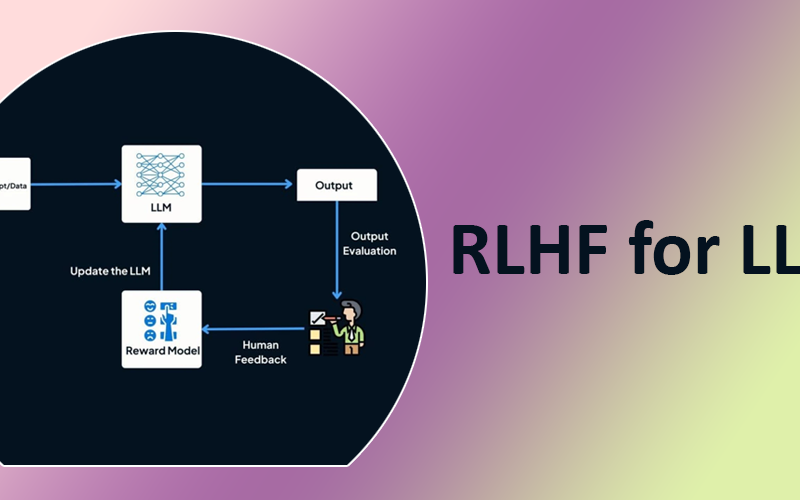
RLHF is a technique that trains a large language model to align its outputs with human preferences and expectations using human feedback. Humans evaluate the model’s responses and provide ratings, which the model uses to improve its performance. This iterative process helps LLMs to refine their understanding of human instructions and generate more accurate and relevant output. RLHF has played a critical role in improving the performance of InstructGPT, Sparrow, Claude, and more, enabling them to outperform traditional LLMs, such as GPT-3.
Let’s understand how RLHF works.
RLHF vs Non-RLHF
Large language models were originally designed to predict the next word or token to complete a sentence based on the input known as ‘prompt’. For example, to complete a statement, you prompt GPT-3 with the following input:
Prompt: Complete the sentence “Human input enables AI systems to navigate complex and nuanced scenarios that AI might struggle with. For example, in taxation, human consultants can …….”
The model then successfully completes the statement as follows:
“Human input enables AI systems to navigate complex and nuanced scenarios that AI might struggle with. For example, in taxation, human consultants can interpret intricate tax laws, tailor advice to specific client situations, and apply critical thinking to ambiguous regulations.”
Asking LLM to continue a prompt
However, large language models are expected to do more than complete a prompt. LLMs are required to write stories, emails, poems, code, and more.
RLHF vs Non-RLHF Examples
Here are a few examples showing the difference between non-RLHF LLM (Next token predictor) and RLHF LLM (trained on human feedback) output.
Non-RLHF Output – Story
When you tell GPT-3 to ‘write a fictional story about Princess Anastasia falling in love with a soldier’, a non-RLHF model generates output like:
Prompt: Write a fictional story about Princess Anastasia falling in love with a soldier.
However, large language models are expected to do more than complete a prompt. LLMs are required to write stories, emails, poems, code, and more.
RLHF vs Non-RLHF Examples
Here are a few examples showing the difference between non-RLHF LLM (Next token predictor) and RLHF LLM (trained on human feedback) output.
Non-RLHF Output – Story
When you tell GPT-3 to ‘write a fictional story about Princess Anastasia falling in love with a soldier,’ a non-RLHF model generates output like:
Prompt: Write a fictional story about Princess Anastasia falling in love with a soldier.

The model knows how to write stories, but it can’t understand the request because LLMs are trained on internet scrapes which are less familiar with commands like ‘write a story/ email’, followed by a story or email itself. Predicting the next word is fundamentally different from intelligently following instructions.
RLHF Output – Story
Here is what you get when the same prompt is provided to an RLHF model trained on human feedback.
Prompt: Write a fictional story about Princess Anastasia falling in love with a soldier.

Now, the LLM generated the desired answer.
Non-RLHF Output – Mathematics
Prompt: What is 4-2 and 3-1?

The non-RLHF model doesn’t answer the question and takes it as part of a story dialogue.
RLHF Output – Mathematics
Prompt: What is 4-2 and 3-1?

The RLHF model understands the prompt and generates the answer correctly.
How does RLHF Work?
Let’s understand how a large language model is trained on human feedback to respond appropriately.
Step 1: Starting with Pre-trained Models
The process of RLHF starts with a pre-trained language mode or a next-token predictor.
Step 2: Supervised Model Fine-tuning
Multiple input prompts about the tasks you want the model to complete and a human-written ideal response to each prompt are created. In other words, a training dataset consisting of <prompt, corresponding ideal output> pairs is created to fine-tune the pre-trained model to generate similar high-quality responses.
Step 3: Creating a Human Feedback Reward Model
This step involves creating a reward model to evaluate how well the LLM output meets quality expectations. Like an LLM, a reward model is trained on a dataset of human-rated responses, which serve as the ‘ground truth’ for assessing response quality. With certain layers removed to optimize it for scoring rather than generating, it becomes a smaller version of the LLM. The reward model takes the input and LLM-generated response as input and then assigns a numerical score (a scalar reward) to the response.
So, human annotators evaluate the LLM-generated output by ranking their quality based on relevance, accuracy, and clarity.
Step 4: Optimizing with a Reward-driven Reinforcement Learning Policy
The final step in the RLHF process is to train an RL policy (essentially an algorithm that decides which word or token to generate next in the text sequence) that learns to generate text the reward model predicts humans would prefer.
In other words, the RL policy learns to think like a human by maximizing feedback from the reward model.
This is how a sophisticated large language model like ChatGPT is created and fine-tuned.
Final Words
Large language models have made considerable progress over the past few years and continue to do so. Techniques like RLHF have led to innovative models such as ChaGPT and Gemini, revolutionizing AI responses across different tasks. Notably, by incorporating human feedback in the fine-tuning process, LLMs are not only better at following instructions but are also more aligned with human values and preferences, which help them better understand the boundaries and purposes for which they are designed.
RLHF is transforming large language models (LLMs) by enhancing their output accuracy and ability to follow human instructions. Unlike traditional LLMs, which were originally designed to predict the next word or token, RLHF-trained models use human feedback to fine-tune responses, aligning responses with user preferences.
Summary: RLHF is transforming large language models (LLMs) by enhancing their output accuracy and ability to follow human instructions. Unlike traditional LLMs, which were originally designed to predict the next word or token, RLHF-trained models use human feedback to fine-tune responses, aligning responses with user preferences.
The post How RLHF is Transforming LLM Response Accuracy and Effectiveness appeared first on Datafloq.
Source link
lol