Large language models are revolutionizing how we interact with technology by leveraging advanced natural language processing to perform complex tasks. In recent years, we have seen state-of-the-art LLM models enabling a wide range of innovative applications. Last year marked a shift toward RAG (Retrieval Augment generation), where users created interactive AI Chatbots by feeding LLMs with their organizational data (through vector embedding).
But we’re just scratching the surface. While powerful, “Retrieval Augment Generation” limits our application to static knowledge retrieval. Imagine a typical customer service agent who not only answers questions from internal data but also takes action with minimal human intervention. With LLMs, we can create fully autonomous decision-making applications that don’t just respond but also act on user queries. The possibilities are endless – from internal data analysis to web searches and beyond.
The semantic understanding and linguistic capability of Large Language Models enable us to create fully autonomous decision-making applications that can not only answer but also “act” based on users’ queries.
Databricks Mosaic AI Agent Framework:
Databricks launched Mosaic AI Agent framework that enables developers to build a production scale agent framework through any LLM. One of the core capabilities is to create tools on Databricks that are designed to help build, deploy, and evaluate production-quality AI agents like Retrieval Augmented Generation (RAG) applications and much more. Developers can create and log agents using any library and integrate them with MLFlow. They can parameterize agents to experiment and iterate on development quickly. Agent tracing lets developers log, analyze, and compare traces to debug and understand how the agent responds to requests.
In this first part of the blog, we will explore agents, and their core components and build an autonomous multi-turn customer service AI agent for an online retail company with one of the best-performing Databricks Foundational model (open source) on the Platform. In the next series of the blog, we will explore the multi-agent framework and build an advanced multi-step reasoning multi-agent for the same business application.
What is an LLM Agent?
LLM agents are next-generation advanced AI systems designed for executing complex tasks that need reasoning. They can think ahead, remember past conversations, and use various tools to adjust their responses based on the situation and style needed.
A natural progression of RAG, LLM Agents are an approach where state-of-the-art large language models are empowered with external systems/tools or functions to make autonomous decisions. In a compound AI system, an agent can be considered a decision engine that is empowered with memory, introspection capability, tool use, and many more. Think of them as super-smart decision engines that can learn, reason, and act independently – the ultimate goal of creating a truly autonomous AI application.
Core Components:
Key components of an agentic application include:
- LLM/Central Agent: This works as a central decision-making component for the workflow.
- Memory: Manages the past conversation and agent’s previous responses.
- Planning: A core component of the agent in planning future tasks to execute.
- Tools: Functions and programs to perform certain tasks and interact with the main LLM.
Central Agent:
The primary element of an agent framework is a pre-trained general-purpose large language model that can process and understand data. These are generally high-performing pre-trained models; Interacting with these models begin by crafting specific prompts that provide essential context, guiding it on how to respond, what tools to leverage, and the objectives to achieve during the interaction.
An agent framework also allows for customization, enabling you to assign the model a distinct identity. This means you can tailor its characteristics and expertise to better align with the demands of a particular task or interaction. Ultimately, an LLM agent seamlessly blends advanced data processing capabilities with customizable features, making it an invaluable tool for handling diverse tasks with precision and flexibility.
Memory:
Memory is an important component of an agentic architecture. It is temporary storage which the agent uses for storing conversations. This can either be a short-term working memory where the LLM agent is holding current information with immediate context and clears the memory out once the task is completed. This is temporary.
On the other hand, we have long-term memory (sometimes called episodic memory) which holds long-running conversations and it can help the agent to understand patterns, learn from previous tasks and recall the information to make better decisions in future interactions. This conversation generally is persisted in an external database. (e.g. – vector database).
The combination of these two memories allows an agent to provide tailored responses and work better based on user preference over time. Remember, do not confuse agent memory with our LLM’s conversational memory. Both serve different purposes.
Planner:
The next component of an LLM agent is the planning capability, which helps break down complex tasks into manageable tasks and executes each task. While formulating the plan, the planner component can utilize multiple reasoning techniques, such as chain-of-thought reasoning or hierarchical reasoning, like decision trees, to decide which path to proceed.
Once the plan is created, agents review and assess its effectiveness through various internal feedback mechanisms. Some common methods include ReAct and Reflexion. These methods help LLM solve complex tasks by cycling through a sequence of thoughts and observing the outcomes. The process repeats itself for iterative improvement.
In a typical multi-turn chatbot with a single LLM agent, the planning and orchestration are done by a single Language model, whereas in a multi-agent framework, separate agents might perform specific tasks like routing, planning, etc.We would discuss this more on the next part of the blog on multi-agent frame.
Tools:
Tools are the building blocks of agents, they perform different tasks as guided by the central core agent. Tools can be various task executors in any form (API calls, python or SQL functions, web search, coding , Databricks Genie space or anything else you want the tool to function. With the integration of tools, an LLM agent performs specific tasks via workflows, gathering observations and collecting information needed to complete subtasks.
When we are building these applications, one thing to consider is how lengthy the interaction is going. You can easily exhaust the context limit of LLMs when the interaction is long-running and potential to forget the older conversations. During a long conversation with a user, the control flow of decision can be single-threaded, multi-threaded in parallel or in a loop. The more complex the decision chain becomes, the more complex its implementation will be.
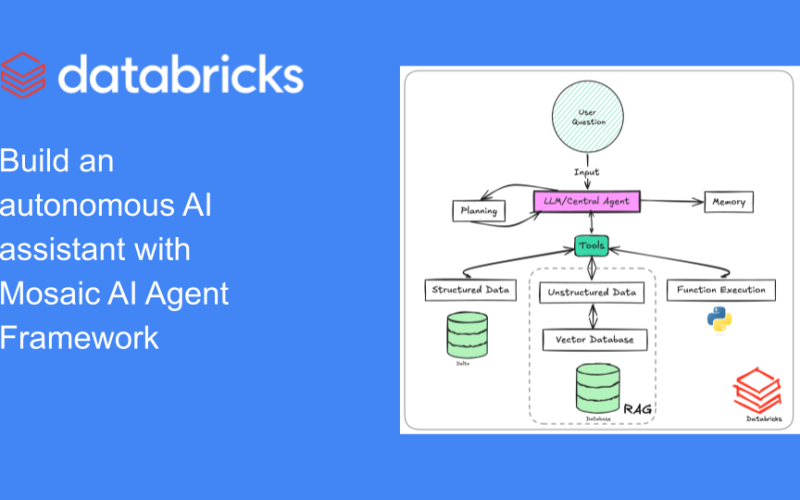
In Figure 1 below, a single high-performing LLM is the key to decision-making. Based on the user’s question, it understands which path it needs to take to route the decision flow. It can utilize multiple tools to perform certain actions, store interim results in memory, perform subsequent planning and finally return the result to the user.
Conversational Agent for Online Retail:
For the purpose of the blog, we are going to create an autonomous customer service AI assistant for an online electronic retailer via Mosaic AI Agent Framework. This assistant will interact with customers, answer their questions, and perform actions based on user instructions. We can introduce a human-in-loop to verify the application’s response. We would use Mosaic AI’s tools functionality to create and register our tools inside Unity Catalog. Below is the entity relationship (synthetic data) we built for the blog.

Below is the simple process flow diagram for our use case.

Code snippet: (SQL) Order Details
The below code returns order details based on a user-provided order ID. Note the description of the input field and comment field of the function. Do not skip function and parameter comments, which are critical for LLMs to call functions/tools properly.
Comments are utilized as metadata parameters by our central LLM to decide which function to execute given a user query. Incorrect or insufficient comments can potentially expose the LLM to execute incorrect functions/tools.
CREATE OR REPLACE FUNCTION
mosaic_agent.agent.return_order_details (
input_order_id STRING COMMENT 'The order details to be searched from the query'
)
returns table(OrderID STRING,
Order_Date Date,
Customer_ID STRING,
Complaint_ID STRING,
Shipment_ID STRING,
Product_ID STRING
)
comment "This function returns the Order details for a given Order ID. The return fields include date, product, customer details , complaints and shipment ID. Use this function when Order ID is given. The questions can come in different form"
return
(
select Order_ID,Order_Date,Customer_ID,Complaint_ID,Shipment_ID,Product_ID
from mosaic_agent.agent.blog_orders
where Order_ID = input_order_id
)Code snippet: (SQL) Shipment Details
This function returns shipment details from the shipment table given an ID. Similar to the above, the comments and details of the metadata are important for the agent to interact with the tool.
CREATE OR REPLACE FUNCTION
mosaic_agent.agent.return_shipment_details (
input_shipment_id STRING COMMENT 'The Shipment ID received from the query'
)
returns table(Shipment_ID STRING,
Shipment_Provider STRING,
Current_Shipment_Date DATE,
Shipment_Current_Status STRING,
Shipment_Status_Reason STRING
)
comment "This function returns the Shipment details for a given Shipment ID. The return fields include shipment details.Use this function when Shipment ID is given. The questions may come in different form"
return
(
select Shipment_ID,
Shipment_Provider ,
Current_Shipment_Date ,
Shipment_Current_Status,
Shipment_Status_Reason
from mosaic_agent.agent.blog_shipments_details
where Shipment_ID = input_shipment_id
)Code snippet: (Python)
Similarly, you can create any Python function and use it as a tool or function. It can be registered inside the Unity Catalog in a similar manner and provide you with all the benefits mentioned above. The below example is of the web search tool we have built and used as an endpoint for our agent to call.
CREATE OR REPLACE FUNCTION
mosaic_agent.agent.web_search_tool (
user_query STRING COMMENT 'User query to search the web'
)
RETURNS STRING
LANGUAGE PYTHON
DETERMINISTIC
COMMENT 'This function searches the web with the provided query. Use this function when a customer asks about competitive offers, discounts etc. Assess this would need the web to search and execute it.'
AS
$$
import requests
import json
import numpy as np
import pandas as pd
import json
url = 'https://<databricks workspace URL>/serving-endpoints/web_search_tool_API/invocations'
headers = {'Authorization': f'Bearer token, 'Content-Type': 'application/json'}
response = requests.request(method='POST', headers=headers,
url=url,
data=json.dumps({"dataframe_split": {"data": [[user_query]]}}))
return response.json()['predictions']For our use case, we have created multiple tools performing varied tasks like below:

|
return_order_details |
Return order details given an Order ID |
|
return_shipment_details |
Return shipment details provided a Shipment ID |
|
return_product_details |
Return product details given a product ID |
|
return_product_review_details |
Return review summary from unstructured data |
|
search_tool |
Searches web-based on keywords and returns results |
|
process_order |
Process a refund request based on a user query |
Unity Catalog UCFunctionToolkit :
We will use LangChain orchestrator to build our Chain framework in combination with Databricks UCFunctionToolkit and foundational API models. You can use any orchestrator framework to build your agents, but we need the UCFunctionToolkit to build our agent with our UC functions (tools).
from langchain_community.tools.databricks import UCFunctionToolkit
def display_tools(tools):
display(pd.DataFrame([{k: str(v) for k, v in vars(tool).items()} for tool in tools]))
tools = (
UCFunctionToolkit(
# SQL warehouse ID is required to execute UC functions
warehouse_id=wh.id
)
.include(
# Include functions as tools using their qualified names.
# You can use "{catalog_name}.{schema_name}.*" to get all functions in a schema.
"mosaic_agent.agent.*"
)
.get_tools()
)
Creating the Agent:
Now that our tools are ready, we will integrate them with a large language Foundational Model hosted on Databricks, note you can also use your own custom model or external models via AI Gateway. For the purpose of this blog, we will use databricks-meta-llama-3-1-70b-instruct hosted on Databricks.
This is an open-source model by meta and has been configured in Databricks to use tools effectively. Note that not all models are equivalent, and different models will have different tool usage capabilities.
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatDatabricks
# Utilize a Foundational Model API via ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-1-70b-instruct")
# Define the prompt for the model, note the description to use the tools
prompt = ChatPromptTemplate.from_messages(
[(
"system",
"You are a helpful assistant for a large online retail company.Make sure to use tool for information.Refer the tools description and make a decision of the tools to call for each user query.",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)Now that our LLM is ready, we would use LangChain Agent executor to stitch all these together and build an agent:
from langchain.agents import AgentExecutor, create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)Let’s see how this looks in action with a sample question:
As a customer, imagine I will start asking the agent the price of a particular product, “Breville Electrical Kettle,” in their company and in the market to see competitive offerings.
Based on the question, the agent understood to execute two functions/tools :
return_product_price_details– For internal priceweb_search_tool– For searching the web.
The below screenshot shows the sequential execution of the different tools based on a user question.
Finally, with the response from these two functions/tools, the agent synthesizes the answer and provides the response below. The agent autonomously understood the functions to execute and answered the user’s question on your behalf. Pretty neat!

You can also see the end-to-end trace of the agent execution via MLflow Trace. This helps your debugging process immensely and provides you with clarity on how each step executes.

Memory:
One of the key factors for building an agent is its state and memory. As mentioned above, each function returns an output, and ideally, you need to remember the previous conversation to have a multi-turn conversation. This can be achieved in multiple ways through any orchestrator framework. For this case, we would use LangChain Agent Memory to build a multi-turn conversational bot.
Let’s see how we can achieve this through LangChain and Databricks FM API. We would utilize the previous Agent executor and add an additional memory with LangChain ChatMessageHistory andRunnableWithMessageHistory.
Here we are using an in-memory chat for demonstration purposes. Once the memory is instantiated, we add it to our agent executor and create an agent with the chat history below. Let’s see what the responses look like with the new agent.
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.memory import ChatMessageHistory
memory = ChatMessageHistory(session_id="simple-conversational-agent")
agent = create_tool_calling_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)Now that we have defined the agent executor, let’s try asking some follow-up questions to the agent and see if it remembers the conversation. Pay close attention to session_id; this is the memory thread that holds the ongoing conversation.


Nice! It remembers all the user’s previous conversations and can execute follow-up questions pretty nicely! Now that we have understood how to create an agent and maintain its history, let’s see how the end-to-end conversation chat agent would look in action.
We would utilize Databricks AI Playground to see how it looks end-to-end. Databricks AI Playground is a chat-like environment where you can test, prompt, and compare multiple LLMs. Remember that you can also serve the agent you just built as a serving endpoint and use it in the Playground to test your agent’s performance.
Multi-turn Conversational Chatbot:
We implemented the AI agent using the Databricks Mosaic AI Agent Framework,Databricks Foundational Model API , and LangChain orchestrator.
The video below illustrates a conversation between the multi-turn agent we built using Meta-llama-3-1-70b-instruct and our UC functions/tools in Databricks.
It shows the conversation flow between a customer and our agent that dynamically selects appropriate tools and executes it based on a series of user queries to provide a seamless support to our customer.
Here is a conversation flow of a customer with our newly built Agent for our online retail store.

From a question initiation on order status with customer’s name to placing an order, all done autonomously without any human intervention.

Conclusion:
And that’s a wrap! With just a few lines of code, we have unlocked the power of autonomous multi-turn agents that can converse, reason, and take action on behalf of your customers. The result? A significant reduction in manual tasks and a major boost in automation. But we’re just getting started! The Mosaic AI Agent Framework has opened the doors to a world of possibilities in Databricks.
Stay tuned for the next installment, where we’ll take it to the next level with multi-agent AI—think multiple agents working in harmony to tackle even the most complex tasks. To top it off, we’ll show you how to deploy it all via MLflow and model-serving endpoints, making it easy to build production-scale agentic applications without compromising on data governance. The future of AI is here, and it’s just a click away.
Reference Papers & Materials:
Mosaic AI: Build and Deploy Production-quality AI Agent Systems
Announcing Mosaic AI Agent Framework and Agent Evaluation | Databricks Blog
Mosaic AI Agent Framework | Databricks
The Shift from Models to Compound AI Systems – The Berkeley Artificial Intelligence Research Blog
React: Synergizing reasoning and acting in language models
Reflexion: Language agents with verbal reinforcement learning
LLM agents: The ultimate guide | SuperAnnotate
Memory in LLM agents – DEV Community
A Survey on Large Language Model based Autonomous Agents arXiv:2308.11432v5 [cs.AI] 4 Apr 2024
Source link
lol