
Kaggle is one of the best resources for data. If you’re at a loss about what to do with your next project, jump into the rabbit hole of Kaggle for never-ending inspiration.
Ok – now you have ideas, but how do you actually get your hands on data and start to process it ASAP?
When I first started using Kaggle, I had no idea how easy it is getting the data into Python. My workflow was pretty manual:
- find an interesting data set
- explore data set limitations like size and variable type
- download the data
- copy or scp the data set to the place I could work on it
This process was tedious until I pieced together a nearly automated system. Now all I need to do is step 1!
This guide shows you how, with Python, to get a Kaggle CSV file NOW.
Sorry, this is the longest step. You need to get a Kaggle API key.
When you see your JSON, don’t close it! Copy those values into your environment variables.
Inside your Python console, enter the username and key:
import os
os.environ['KAGGLE_USERNAME'] = "USER_NAME_FROM_JSON"
os.environ['KAGGLE_KEY'] = "KEY_FROM_JSON"
The hardest step is to decide what you want. Kaggle has all the data I’ve ever wanted. Want to read all the Harry Potter books again? Download the text corpus from Kaggle. Interested in the SEC Annual Financial Filings… yes, Kaggle has that. Or perhaps I’m writing an AI for music recognition – I could start at this music classification set on Kaggle.
Once you do pick a data set, the Kaggle API is fantastic. My favorite and easiest method to use is dataset_download_file.
Set the data_set and data_file variables to match the data you want. In this example, I want to use the google-doodle CSV file called list.csv. (Note this automated method is only for CSVs with small modifications for other data types. Slack us if you need ideas on how to make those changes.)
I can either copy the API command or the url. Take only the username/notebook and assign it to the data_set.
Next, I want to specify which data set. This one has two; I pick list.csv and assign that to data_file.
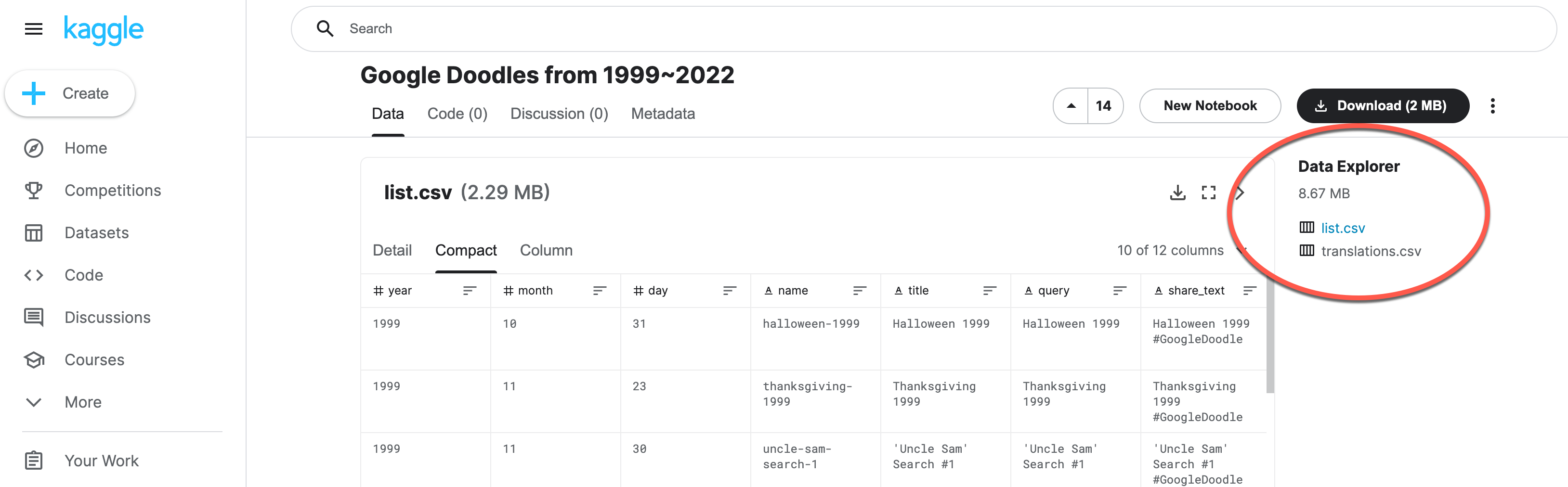
data_set = 'joonasyoon/google-doodles'
data_file ='list.csv'
Slack us if you found a cool data set to use!
The nitty-gritty details step. If you’re using a CSV file, you won’t need to change any of this code – it just works. The comments in the code echo the detailed explanation below the block.
os.system("pip install kaggle")
import kaggle
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
api.dataset_download_file(data_set, data_file)
from zipfile import ZipFile
zf = ZipFile(data_file+'.zip')
zf.extractall()
zf.close()
from deephaven import read_csv
data=read_csv(data_file)
- A) I like to import Kaggle with a local pip install. If you plan on using this frequently, you might want to read our guide on other ways to install Python packages.
- B) Next, import the library and authenticate your credentials.
- C) This uses the variables set for the notebook and file to download that file. Remember, this is inside a Docker container and not downloaded to your local machine.
- D) Most of the time the data set needs to be unzipped. This code unzips our file.
- E) Careful with this step. It seems like 90%+ of the data on Kaggle are
CSVbut there might be other formats. Deephaven works with those, too, like Parquet.
Deephaven is built for large data sets, like many of those on Kaggle. Try some of our features such as aggregations, formulas, or many of plotting options.
Source link
lol