
Whether you’re coming from healthcare, aerospace, manufacturing, government or any other industries the term big data is no foreign concept; however how that data gets integrated into your current existing MATLAB or Simulink model at scale could be a challenge you’re facing today. This is why Databricks and Mathwork’s partnership was built in 2020, and continues to support customers to derive faster meaningful insights from their data at scale. This allows the engineers to continue to develop their algorithms/models in Mathworks without having to learn new code while taking advantage of Databricks Data Intelligence Platform to run those models at scale to perform data analysis and iteratively train and test those models.
For example, in the manufacturing sector, predictive maintenance is a crucial application. Engineers leverage sophisticated MATLAB algorithms to analyze machine data, enabling them to forecast potential equipment failures with remarkable accuracy. These advanced systems can predict impending battery failures up to two weeks in advance, allowing for proactive maintenance and minimizing costly downtime in vehicle and machinery operations.
In this blog, we will be covering a pre-flight checklist, a few popular integration options, “Getting started” instructions, and a reference architecture with Databricks best practices to implement your use case.
Pre-Flight Checklist
Here are a set of questions to answer in order to get started with the integration process. Provide the answers to your technical support contacts at Mathworks and Databricks so that they can tailor the integration process to meet your needs.
- Are you using Unity Catalog?
- Are you using a MATLAB Compiler SDK? Do you have a MATLAB Compiler SDK license?
- Are you on MacOS or Windows?
- What kinds of models or algorithms are you using? Are the models built using MATLAB or Simulink or both?
- Which MATLAB/Simulink toolboxes are these models using?
- For Simulink models, are there any state variables/parameters stored as *.mat files which need to be loaded? Are models writing intermediary states/results into *.mat files?
- What MATLAB runtime version are you on?
- What Databricks Runtime versions do you have access to? The minimum required is X
Deploying MATLAB models at Databricks
There are many different ways to integrate MATLAB models at Databricks; however in this blog we will discuss a few popular integration architectures that customers have implemented. To get started you need to install the MATLAB interface for Databricks to explore the integration methods, such as the SQL Interface, RestAPI, and Databricks Connect for testing and development, and the Compiler option for production use cases.
Integration Methods Overview
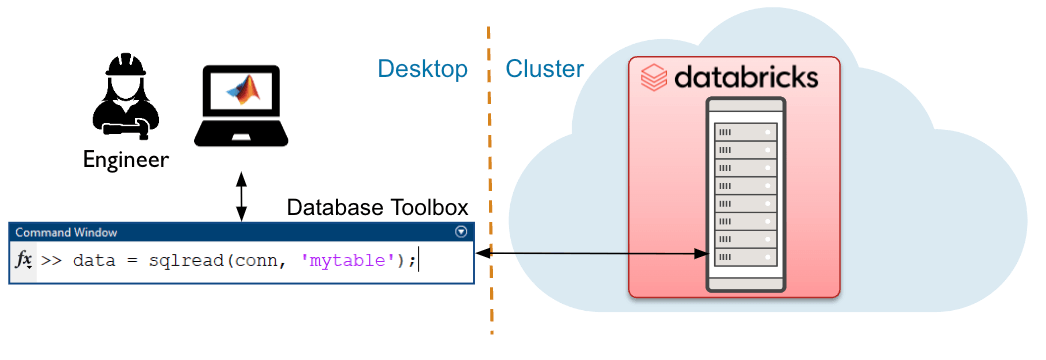
SQL Interface to Databricks
The SQL interface is best suited for modest data volumes and provides quick and easy access with database semantics. Users can access data in the Databricks platform directly from MATLAB using the Database Toolbox.
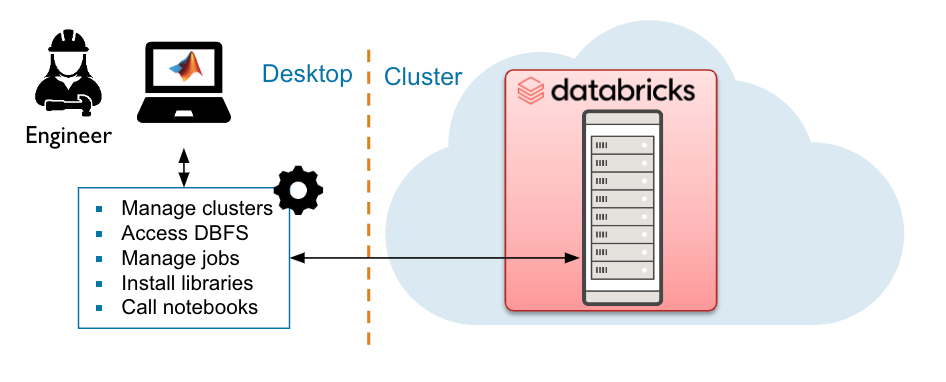
RestAPI to Databricks
The REST API enables the user to control jobs and clusters within the Databricks environment, such as control of Databricks resources, automation, and data engineering workflows.
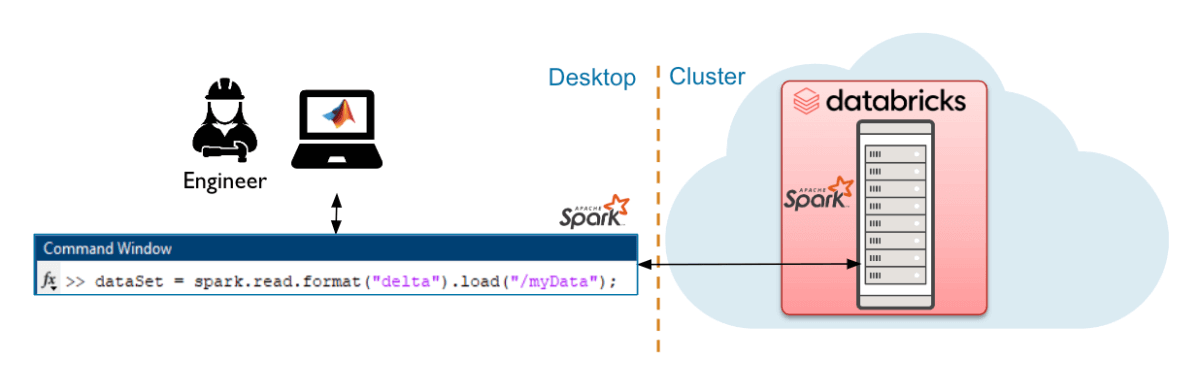
Databricks Connect Interface to Databricks
The Databricks Connect (DB Connect) interface is best suited for modest to large data volumes and uses a local Spark session to run queries on the Databricks cluster.
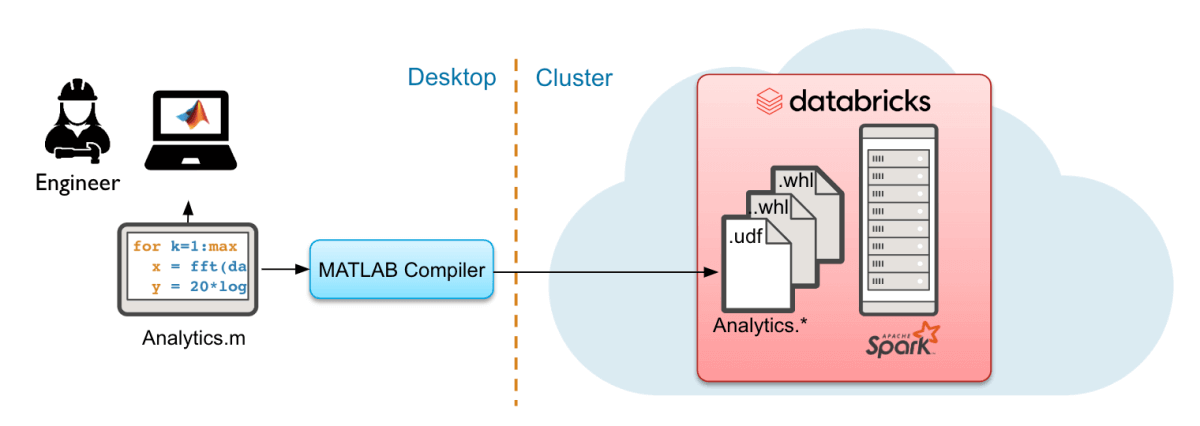
Deploy MATLAB to run at scale in Databricks using MATLAB Compiler SDK
MATLAB Compiler SDK brings MATLAB compute to the data, scales via spark to use large data volumes for production. Deployed algorithms can run on-demand, scheduled, or integrated into data processing pipelines.
For more detailed instructions on how to get started with each of these deployment methods please reach out to the MATLAB and Databricks team.
Getting Started
Installation and setup
- Navigate to MATLAB interface for Databricks and scroll down to the bottom and click the “Download the MATLAB Interface for Databricks” button to download the interface. It will be downloaded as a zip file.
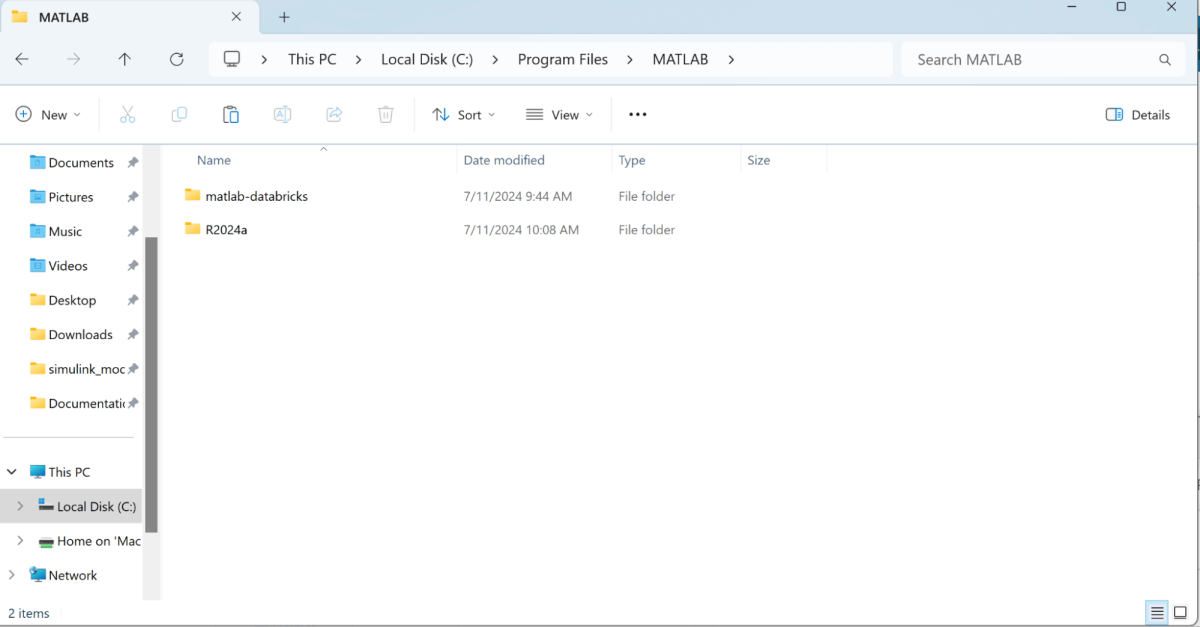
- Extract the compressed zipped folder “matlab-databricks-v4-0-7-build-…” inside Program Files MATLAB. Once extracted you will see the “matlab-databricks” folder. Make sure the folders are in this folder and this hierarchy:
- Launch the MATLAB application from local Desktop application through the Search bar and make sure to run as an administrator

- Go to the command line interface in MATLAB and type “ver” to verify that you have all the dependencies necessary:

- Next you are ready to install the runtime on Databricks cluster:
- Navigate to this path: C:Program FilesMATLABmatlab-databricksSoftwareMATLAB: cd <C:[Your path]Program FilesMATLABmatlab-databricksSoftwareMATLAB>
- You should see in the top bar next to the folders icon the current directory path. Make sure that path looks like the path written above, and you can see
install.mavailable in the current folder.

- Call
install()from the MATLAB terminal - You will be prompted with several questions for configuring the cluster spin up.
- Authentication method, Databricks username, cloud vendor hosting Databricks, Databricks org id, etc
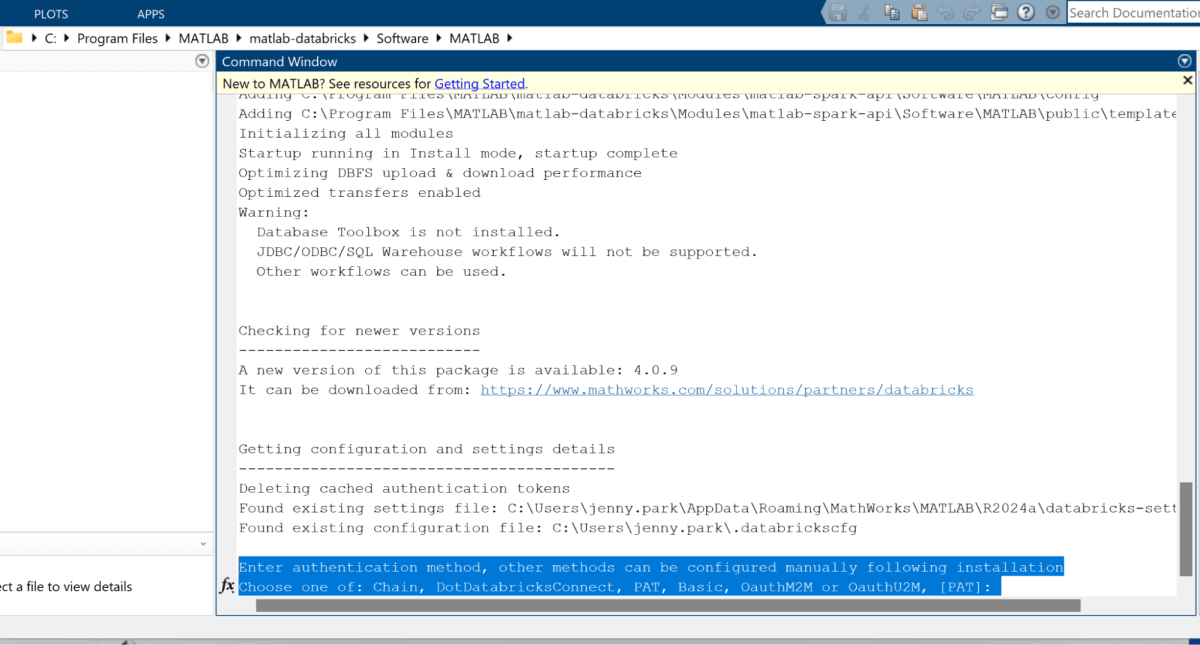
- Authentication method, Databricks username, cloud vendor hosting Databricks, Databricks org id, etc
- When prompted with “Enter the local path to the downloaded zip file for this package (Point to the one on your local machine)”
- You should provide the path to your MATLAB compressed zip file. E.g: C:UserssomeuserDownloadsmatlab-databricks-v1.2.3_Build_A1234567.zip
- A job will be created in Databricks automatically as shown below (Make sure the job timeout is set to 30 minutes or greater to avoid timeout error)
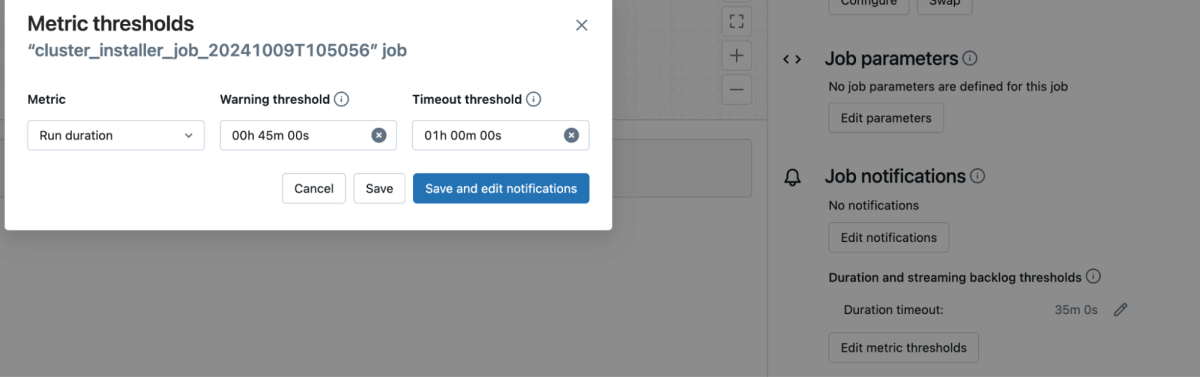
a.
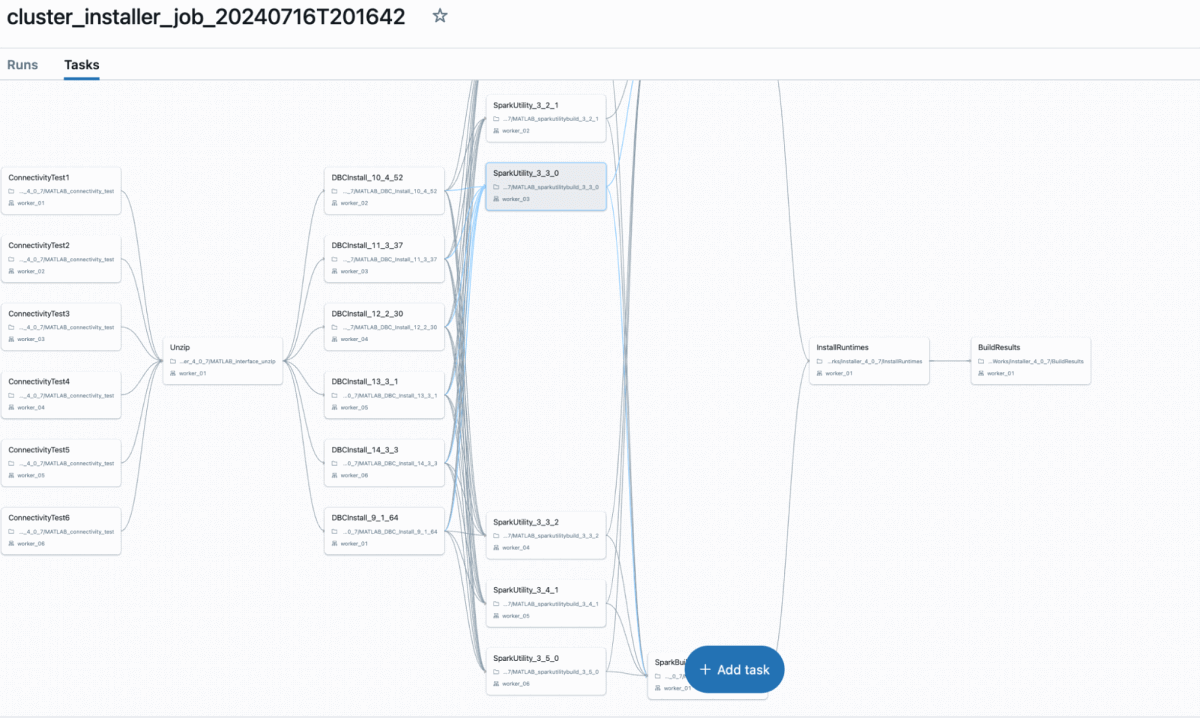
b.
- Once this step is completed successfully, your package should be ready to go. You will need to restart MATLAB and run
startup()which should validate your settings and configurations.
Validating installation and packaging your MATLAB code for Databricks
- You can test one integration option, Databricks-Connect, quite simply with the following steps:
spark = getDatabricksSessionds = spark.range(10)Ds.show- If any of these don’t work, the most likely issue is not being connected to a supported compute (DBR14.3LTS was used for testing) and needing to modify the configuration files listed under the authorization header of the `startup()` output.
- Upload your .whl file to Databricks Volumes
- Create a notebook and attach the “MATLAB install cluster” to the notebook and import your functions from your .whl wrapper file
Reference Architecture of a Batch/Real time Use Case in Databricks Using MATLAB models
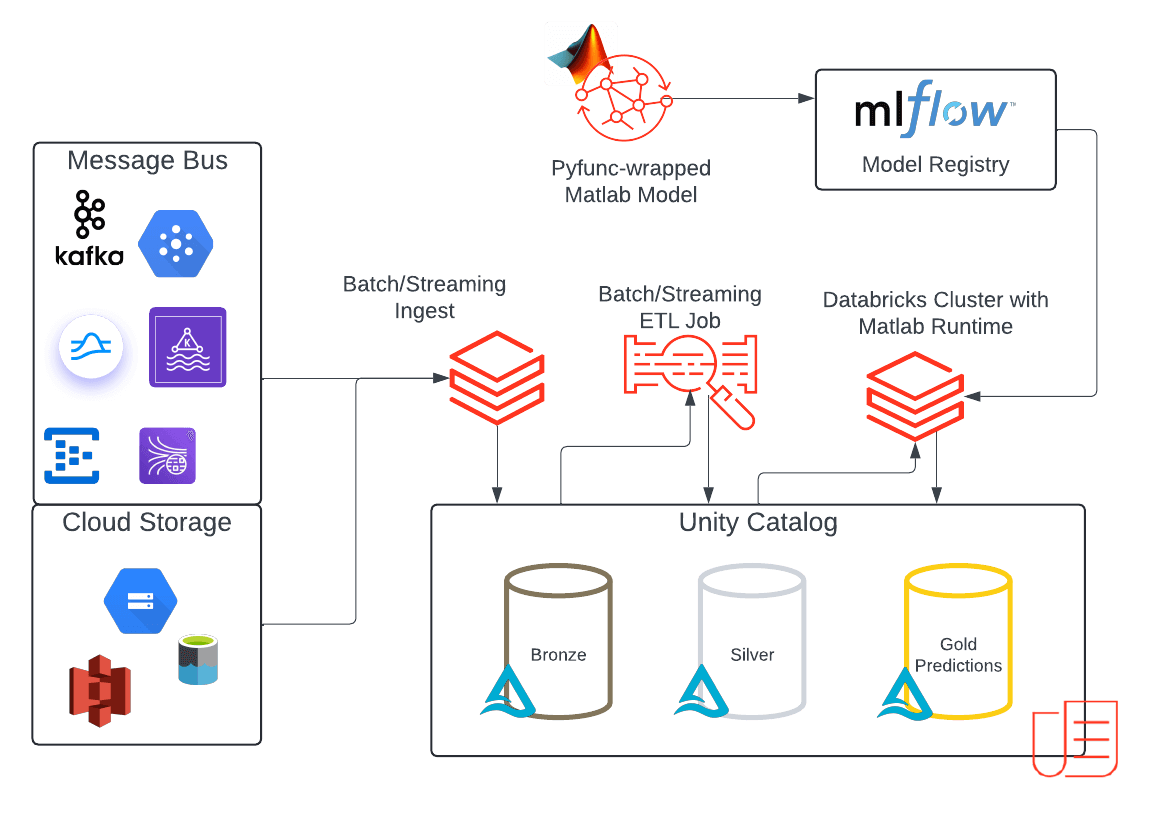
The architecture showcases a reference implementation for an end-to-end ML batch or streaming use cases in Databricks that incorporate MATLAB models. This solution leverages the Databricks Data Intelligence Platform to its full potential:
- The platform enables streaming or batch data ingestion into Unity Catalog (UC).
- The incoming data is stored in a Bronze table, representing raw, unprocessed data.
- After initial processing and validation, the data is promoted to a Silver table, representing cleaned and standardized data.
- MATLAB models are packaged as .whl files so they are ready to use as custom packages in workflows and interactive clusters. These wheel files are uploaded to UC volumes, as described previously, and access can now be governed by UC.
- With the MATLAB model available in UC you can load it onto your cluster as a cluster-scoped library from your Volumes path.
- Then import the MATLAB library into your cluster and create a custom pyfunc MLflow model object to predict. Logging the model in MLflow experiments allows you to save and track different model versions and the corresponding python wheel versions in a simple and reproducible way.
- Save the model in a UC schema alongside your input data, now you can manage model permissions on your MATLAB model like any other custom model in UC. These can be separate permissions apart from the ones you set on the compiled MATLAB model that was loaded into UC Volumes.
- Once registered, the models are deployed to make predictions.
- For batch and streaming – load the model into a notebook and call the predict function.
- For real time – serve the model using the serverless Model Serving endpoints and query it using the REST API.
- Orchestrate your job using a workflow to schedule a batch ingestion or continuously ingest the incoming data and run inference using your MATLAB model.
- Store your predictions in the Gold table in Unity Catalog to be consumed by downstream users.
- Leverage Lakehouse Monitoring to monitor your output predictions.
Conclusion
If you want to integrate MATLAB into your Databricks platform, we have addressed the different integration options that exist today and have presented an architecture pattern for end to end implementation and discussed options for interactive development experiences. By integrating MATLAB into your platform you can leverage the benefits of distributed compute on spark, enhanced data access and engineering capabilities with delta, and securely manage access to your MATLAB models with Unity Catalog.
Check out these additional resources:
Everything you wanted to know about Big Data processing (but were too afraid to ask) » Developer Zone – MATLAB & Simulink
Actionable Insight for Engineers and Scientists at Big Data Scale with Databricks and MathWorks
Transforming Electrical Fault Detection: The Power of Databricks and MATLAB
Source link
lol