
Over the last few decades, the sheer volume of data we have gathered has reached over 100 zettabytes (ZB). Yet nearly 80% of the data we captured globally remains unstructured, while only 20% is structured. Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning.
Many find themselves swamped by the volume and complexity of unstructured data. This is where artificial intelligence steps in as a powerful ally.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition.
Unstructured data, such as texts, images, videos, audio clips, and social media posts, doesn’t conform to a predefined format or conventional data models, making it harder to analyze. They don’t fit into tables with attributes where you see an organized structure.
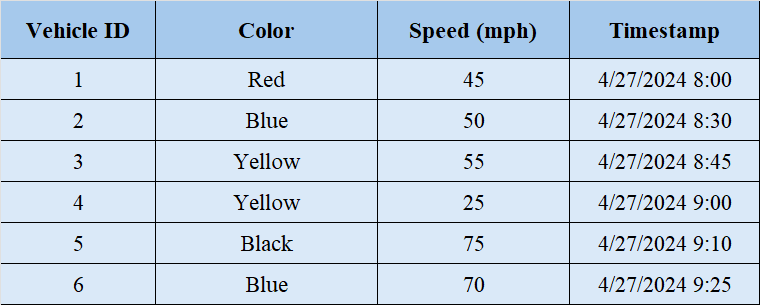
Think of a video of a busy traffic scene consisting of various vehicles moving through intersections. We need to identify the number of yellow taxis passing through the intersection in a given time, along with their speed and plates. We only have the video without any information.
The video consists of continuous streams of pixels, varying colors, and movement patterns, everything without a specific arrangement or a labeling system. Therefore, the video itself is unstructured, as the information lacks a predefined format, making it challenging to analyze using traditional methods.
How would structured data look like?
Converting video into structured data would involve capturing pixel values for each frame, generating vast tables of numerical data. Here, we see the output of solving a higher-level recognition task, where objects (vehicles) are detected and tracked, and relevant attributes (like colour, speed, and timestamps) are extracted to provide meaningful insights.
As unstructured data grows exponentially, organisations face the challenge of processing and extracting insights from these data sources. Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns.
Textual Data
Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
Handling textual data in large volumes in various languages, with different contextual understandings and quality differences, can be extremely difficult and require numerous preprocessing steps.
Images: Photographs, infographics, and medical scans contain rich visual data but require advanced computer vision techniques to analyze.
Audio: Music, podcasts, and voice recordings hold valuable patterns but are challenging to process in raw form. We need speech recognition technologies and sound analysis tools to extract sentiment, detect patterns, and even categorise audio content.
Video: Movies, live streams, and CCTV footage combine visual and audio data, making them highly complex. Video analytics enable object detection, motion tracking, and behavioural analysis for security, traffic monitoring, or customer engagement insights.
Sensor Data
Sensor data can often be semi-structured rather than fully unstructured. While sensor data is typically numerical and has a well-defined format, such as timestamps and data points, it only fits the standard tabular structure of databases. For example, IoT devices, wearables in health care, or car sensors produce time-series data, which can have variable intervals and reading types, such as temperature, speed, or heart rate.
This makes sensor data more structured than images or video, but it is still challenging to analyse using conventional databases due to its volume, variability, and real-time nature. Advanced processing techniques are often needed to handle the continuous data flow and extract actionable insights.
Almost every person these days has smartphone cameras around them and is active on social media. They easily create tons of images, videos, and text. In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today’s digital world.
Data Quality
Ensuring the quality of unstructured data is challenging due to its unstructured nature. While structured data may also contain some noise, unstructured information includes extra quality issues that are commonly more challenging to handle.
- Text data sources could include social media posts, emails, or multimedia files. These sources can contain irrelevant or incorrect information (noise) depending on usage. For instance, casual language or slang words in social media posts could be relevant to understanding users’ emotions in a sentiment analysis task. At the same time, the identical set of words could be considered noise in formal text analytics.
- Noise in images and videos can come from lighting conditions, camera settings, and background clutter. Inadequate lighting or too much light can hide essential details in images, making it hard to recognise objects. Also, different camera angles or problems with resolution can cause distortions that impact how well video analysis models work. For example, a system that detects images would struggle to locate an object in a dimmed scene.
- Background noise is one of the most significant issues for audio data. It ranges from background noises during recordings, to defective microphones and multiple voices simultaneously. In general, this noise seriously reduces the performance of speech recognition or music classification models. In realistic scenarios, such as call centre recordings or podcast transcripts, there is usually a need to clean the audio of additional sounds, like chatter in the background or mechanical noises.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Image and video data require computer vision techniques to address poor lighting and low resolution.
Additionally, context-aware algorithms enhance data quality by interpreting information based on its surrounding context, improving relevance for specific tasks. For example, context-aware models take the entire sentence or paragraph to infer meaning from obscure words when doing text analysis. Similarly, neighbourhood pixels can help better identify objects against messy scenes for image processing. Such algorithms are key to enhancing data.
Scale
The amount of data generated daily can overwhelm traditional systems when processing and storing it, while various formats like text, images, audio, and video require specialised processing and storage solutions.
We need a highly efficient and responsive infrastructure to manage and analyze vast amounts of data, which drives us to adopt new solutions.
Privacy and Security
Compliance for unstructured data is more time-consuming than that of structured data because there is no consistent structure to which it adheres; thus, checks are harder to automate. For example, the extraction of sensitive information about personally identifiable information (PII) from emails or documents requires deep NLP techniques, which may not be necessary for structured data that can easily be filtered through particular fields.
Interoperability
Due to the unstructured nature of the data, integrating multiple data formats and standards to achieve seamless data integration can be challenging. Formats such as JSON, XML, JPEG, and MP4 complicate standardization and require specialized interoperability solutions. This necessitates advanced tools and strategies to ensure efficient and accurate integration across different systems.
Managing unstructured data manually can be tiring, but AI techniques can help you handle its complexity effectively and efficiently. Let’s look at how we can convert unstructured data into better informative structures using new AI techniques and solutions.
Embedding Generation: Bridging Data Types
Embedding generation converts unstructured data into numerical vectors that ML models can understand.

Tools like LlamaCloud, VisualBERT and LlamaParse provide the frameworks for creating embeddings from unstructured text, images, and audio data. Word2Vec, GloVe, and BERT are good sources of embedding generation for textual data. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Images are processed using convolutional neural networks (CNNs), while transformer-based models and recurrent neural networks (RNNs) are used to process audio data focusing on temporal patterns.
Multimodal embedding is an extended part of ML in which various kinds of data, such as texts, images, audio, and video, can be combined into one space. It is instrumental in applications requiring understanding various types of information, such as matching images to their written description and linking audio with video. Creating multimodal embeddings means training models on datasets with multiple data types to understand how these types of information are related.
Multimodal embeddings help combine unstructured data from various sources in data warehouses and ETL pipelines. They finally reduce diverse data types into a single format where one can derive insights across diverse data sets. For instance, a company might use multimodal embeddings to connect product images, customer reviews, and audio feedback into one analysis system that gives a complete view of customer preference.
This development has further enabled the usage of advanced AI tools, including content recommendation systems, multitype-data-capable search engines, and automatic video analysis. It dramatically extends what ML models can do with complicated real-world data.
After generating embeddings from unstructured data, we can extract relevant features that isolate key attributes and improve the performance of models, especially in areas like natural language processing (NLP). Tools like Unstructured.io streamline this process by leveraging ML algorithms to clean and extract features from various data sources, including text and multimedia, significantly reducing the time required for preprocessing.
In the case of images and videos, feature extraction is crucial for tasks such as object detection, recognition, and classification. Techniques like Optical Character Recognition (OCR) convert printed or handwritten text from human-readable documents into machine-readable formats, which is essential for digitizing text-heavy content. For visual data, Convolutional Neural Networks (CNNs) play a central role in extracting intricate features like edges, textures, and patterns, enabling models to identify objects with high accuracy.
Regarding audio data, Mel-frequency cepstral Coefficients (MFCCs) represent the short-term power spectrum of sound, capturing its essential characteristics. By using MFCCs, we can improve the performance of speech recognition and music classification models.
AI tools like IBM Watson Assistant and Dialogflow by Google can extract features and analyse chat logs from customer interactions, streamlining the support process for finding common issues and resolutions.
The features extracted in the ETL process would then be inputted into the ML models. This will ensure the data is in an ideal structure for further analysis. This increases the performance of tasks such as clustering similar data points and makes classifying data into pre-defined categories smoother and faster.
Dimensionality Reduction
Usually, unstructured data exist in high-dimensional spaces. It could be computationally expensive to process high-dimensional data.

We can use techniques like Principal Component Analysis (PCA) to reduce dimensionality while preserving significant information. They compress data in a low-dimensional latent space and then reconstruct it, keeping the most important features while reducing general complexity. This would lead to a dataset of the same dimensions as the original. Still, this new data would only be similar to the original and skip all the minor details lost in the dimensionality reduction process. Hence, the primary usage of PCA is not trying to rebuild a dataset like the original but to use fewer dimensions and smaller data for particular tasks, such as creating visuals, speeding up calculations, or noise reduction.
Similarly, multimodal embeddings convert high-dimensional data like text, images, and audio into smaller, dense vector representations. The embeddings preserve the rich feature content of the data and make it easier to process and analyse by reducing the complexity of large volumes of data. PCA and embeddings enable us to work more efficiently with big amounts of data by focusing on the most relevant information.
Integrating these methods into the ETL pipeline simplifies the dataset, improving ML models’ speed and performance through reduced computational burden and simplified data representations.
Data Cleaning and Normalization
Through cleaning and transformation tasks, AI-powered algorithms can improve the quality and consistency of unstructured text, images, and audio data. Regarding text data, NLP techniques eliminate unnecessary information, such as stop words and grammatical or spelling errors, and can even standardize slang and abbreviations to make text easier to analyze.
For instance, in customer feedback analysis, NLP will clean up social media posts, removing casual language or emojis that may distort the meaning of the feelings expressed. NLP models can also recognize and correct errors related to document formatting or writing style and thus standardize extensive collections of texts, preparing them for easier processing.
These AI models use multimedia data to understand and improve more complicated information. In image processing, AI can enhance images by correcting the image’s lighting, removing blurriness, or removing extra background elements to emphasize the essential portions of the image, like objects that matter. For instance, AI in healthcare can enhance medical images by removing noise or problems that would appear in MRI or CT scan results.
Applications in audio processing include suppression of unwanted background noise or equalization in voice records using AI methods. In all these cases, AI helps in making the data more understandable. This is helpful in places like call centre analysis, where better speech recognition contributes significantly to understanding customer conversations. By refining data this way, AI-driven approaches ensure the data becomes more structured, reliable, and ready for further analysis.
Finding the perfect storage solutions is necessary with the vast volumes of unstructured data originating from text, images, audio, and video. Unstructured data requires specialized storage solutions to manage its diversity, volume, and complexity.
1. Vector Databases
With unprecedented data being generated, we must store and retrieve it efficiently. One of the best ways to store unstructured data is through Vector Databases. These vector databases store complex data by transforming the original unstructured data into numerical embeddings; this is enabled through deep learning models. As reiterated earlier, embeddings take the critical components of various kinds of data, like text, images, and audio, and project them into one vector space.
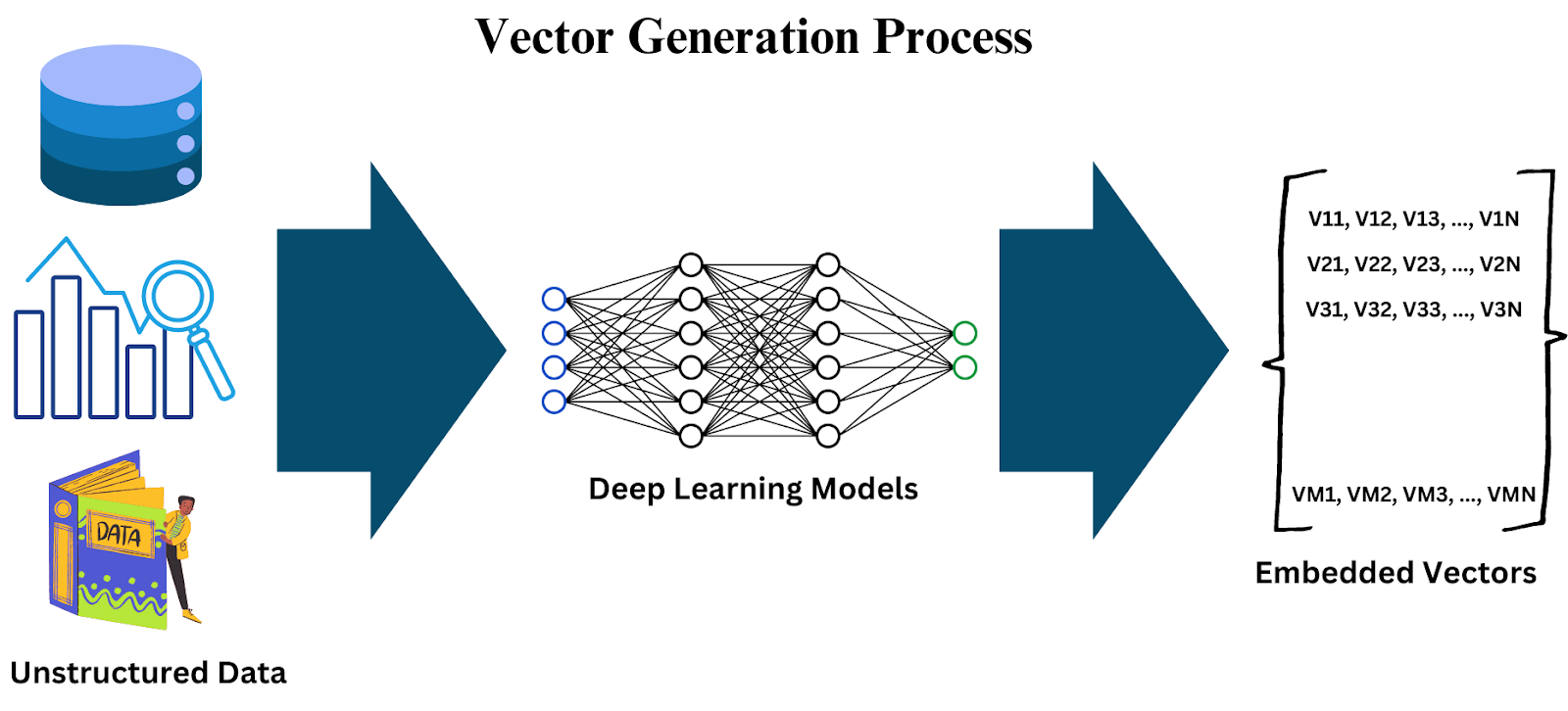
AI also plays an important role in this process because it uses deep learning methods to create embeddings that find all the key features of the original data. This enables the searching, analysis, and filtering of information within large datasets, which can be useful in many areas, such as recommendation systems, image recognition, and NLP.
Unlike traditional databases, they efficiently manage vectorized data, allowing faster storage, indexing, and searching of large unstructured datasets by processing the embedded vectors of DL models.
Pinecone and Milvus are scalable platforms that provide real-time similarity searches, including facial recognition and semantic search.
2. NoSQL Databases
NoSQL databases can handle unstructured and semi-structured data quite well, setting flexible schemas for various data types that do not require strict tables. This includes the leading NoSQL databases like MongoDB and Cassandra, which can support JSON, XML, and binary formats.

NoSQL databases play a crucial role in supporting AI-driven systems by efficiently managing the vast amounts of unstructured and semi-structured data that AI models rely on. Their scalability and performance enable AI systems to process large datasets in real-time, powering use cases such as AI-based content management systems, real-time analytics, and AI-driven log management. Key benefits include horizontal scalability, high availability, and performance optimised for high-speed read and write operations.
3. Object Storage
Object storage systems treat unstructured data as objects containing the data, metadata, and a unique identifier. These storages play a crucial role in the AI pipeline, as they provide scalable and efficient ways to store large volumes of unstructured data required for training and analysis by AI models.
Amazon S3 and Google Cloud Storage are examples of object storage systems that provide highly scalable and economical ways of storing large unstructured data such as images, videos, and binary files.

MinIO is another example of object storage optimised explicitly for AI workloads with on-premise and private cloud needs. It offers low-latency performance, horizontal scalability, and high availability to support AI-driven workloads such as real-time analytics, deep learning, and distributed training.
Consider an example, such as hospitals containing unstructured data, high-resolution medical images, and clinical and patient records. Medical records must be managed and stored correctly to ensure patient care and streamline healthcare operations.
Most cloud services use AI to automatically classify and transfer data across storage tiers based on usage trends, which helps in further cost reductions without loss of efficiency. AI is pivotal in sorting, indexing, and storing medical records, which helps improve operational efficiency for healthcare organisations, ensure better patient care, and comply with data protection regulations.
These storages are low-cost, highly available, have extensive metadata capabilities, and can be seamlessly integrated with AI pipelines. This metadata will help make the data labelling, feature extraction, and model training processes smoother and easier. These processes are essential in AI-based big data analytics and decision-making.
4. Data Lakes
Data lakes are crucial in effectively handling unstructured data for AI applications. They serve as centralized repositories where raw data, whether structured or unstructured, can be stored in its native format.
Having a Data Lake means starting with a strategic advantage for quick adaptation by businesses and extracting maximum value from their data with AI-driven products. It acts as a common ground wherein data is systematically collected, integrated, and processed in an efficient manner. Data Lakes enable companies to accelerate their AI initiatives, save time and resources, and unlock the full potential of data-driven innovations.
Platforms like Azure Data Lake and AWS Lake Formation can facilitate big data and AI processing. They are ideal for big data analytics and ML, thus allowing complete exploration of data and business intelligence.
5. Distributed File Systems
Distributed file systems (DFSs), like Hadoop HDFS, are essential for storing and managing large amounts of unstructured data that AI systems need for analysis and training models. These systems allow unstructured data, like text, images, and video, to be stored and processed simultaneously across a cluster of nodes, making them flexible and able to handle failures.
AI models thus rely on DFSs’ high throughput and distributed architecture for easy access to unstructured data, especially in the case of large-scale AI programs using massive amounts of data.
Integrating AI tools with DFSs, such as Apache Spark for distributed computing, enables organizations to process data in real-time. This speeds up the training of models and ensures better handling of unstructured data.
This section proves that AI processes unstructured data and provides compelling insights. Each of these examples shows the different ways AI serves organizations in solving some of their most daunting challenges attributed to data, focusing on those use cases where AI has unlocked the value in unstructured data.
Example 1: Finance
The financial industry handles vast volumes of unstructured data, such as transaction logs, customer feedback, and market reports. Management of this type of data is imperative for regulatory compliance, risk management, and customer relationship management.
- Transaction logs: AI manages to extract patterns and fraudulent transaction logs and stores data in data lakes and NoSQL databases for timely retrieval related to auditing and compliance.
- Unstructured customer feedback is prioritized from high to low urgency. Because of its sentimental nature, it comes from diversified sources and is then pipelined into NoSQL databases like MongoDB.
Example 2: Customer Service
Customer service departments are usually flooded with unstructured data, from chat logs and emails to customer feedback. All this information must be sorted out and implemented for better service and customer satisfaction.
- Emails: AI-driven systems like AI-Driven Customer Service can sort and index customer emails by content and priority and store them in structured databases for easy access. Google’s Natural Language AI can perform sentiment analysis and help annotate these data.
- Customer Feedback: AI processes and categorizes feedback from surveys and social media, then structures it for detailed analysis that helps businesses refine their products and services to enhance customer loyalty.
With the developments in AI and machine learning, there will be breakthroughs, besides challenges, when dealing with unstructured data. Newer technologies promise to ease the processes for better efficiency and derive more valuable insight from previously untapped sources.
- Advanced NLP Models: The latest advancements emphasise decoder-based transformer architectures, especially in models like GPT-3, GPT-4, and Claude by Anthropic. These models are more capable of handling delicate tasks in unstructured text data, ranging from complex NLP to effective multi-turn conversation.
- Improved Computer Vision: Future enhancements of 3D vision, video understanding, and self-supervised learning will enable AI to leap forward in visual data processing, constructing AI applications more accurately in healthcare, autonomous driving, and security.
- Integration with Other Technologies: AI will continue integrating with IoT for real-time processing of sensor data and blockchain for secure and transparent data management, thereby unlocking innovations across industries like smart cities, finance, and healthcare.
- Ethical Considerations: As AI advances, concerns over data privacy, bias, and transparency will become critical, requiring more robust ethical frameworks and regulations to ensure fair, responsible, and secure use of AI in unstructured data analysis.
Handling unstructured data efficiently will unlock valuable industry insights and improve decision-making processes. However, due to its complexity, advanced AI-based tools are required. AI plays a significant role in efficient processing, categorising, and storing unstructured data.
Adopting AI technologies can ensure that organisations enhance management to a higher level, smoothen operations, and rapidly make better, more informed, and more correct decisions.
Source link
lol