
(3rdtimeluckystudio/Shutterstock)
Financial services businesses are eager to adopt generative AI to cut costs, grow revenues, and increase customer satisfaction, as are many organizations. However, the risks associated with GenAI are not trivial, especially in financial services. TCI Media recently hosted experts from EY to help practitioners in FinServ get started on their responsible AI journeys.
During the recent HPC + AI on Wall Street event, which took place in New York City in mid-September, TCI Media welcomed two AI experts from EY Americas, including Rani Bhuva, a principal at EY and EY Americas Financial Services Responsible AI Leader, and Kiranjot Dhillon, a senior manager at EY and the EY Americas Financial Services AI Leader.
In their talk, titled “Responsible AI: Regulatory Compliance Trends and Key Considerations for AI Practitioners,” Bhuva and Dhillon discussed many of the challenges that financial services firms face when trying to adopt AI, including GenAI, as well as some of the steps that companies can take to get started.
FinServ companies are no stranger to regulation, and they’ll find plenty of that happening in GenAI around the world. The European Union’s AI Act has gained a lot of attention globally, while here in the US, there are about 200 potential data and AI bills being drawn up at the state level, according to Bhuva.
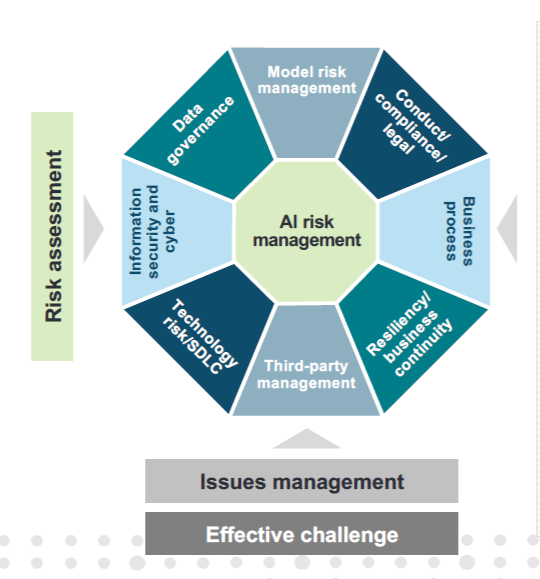
Companies must bring a number of experts to the table to develop and deploy AI responsibly (Image courtesy EY)
At the federal level, most of the action to date has occurred with the NIST AI Framework from early 2023 and President Joe Biden’s October 2023 executive order, she said. The Federal Communications Commission (FCC) and the Federal Reserve have instructed financial firms to take the regulations they have passed over the past 10 years around model risk management and governance, and apply that to GenAI, she said.
Federal regulators are still mostly in learning mode when it comes to GenAI, she said. Many of these agencies, such as US Treasury and Consumer Financial Protection Board (CFPB), have issued requests for information (RFIs) to get feedback from the sector, while others, like the Financial Industry Regulatory Authority (FINR) and the Securities and Exchange Commission (SEC) have clarified some regulations around customer data in AI apps.
“One thing that has clearly emerged is alignment with the NIST,” Bhuva said. “The challenge from the NIST, of course, is that it hasn’t taken into account all of the other regulatory issuances within financial services. So if you think about what’s happened in the past decade, model risk management, TPRM [third-party risk management], cybersecurity–there’s a lot more detail within financial services regulation that applies today.”
So how do FinServ companies get started? EY recommends that companies take a step back and look at the tools they already have in place. To ensure compliance, companies should look at three specific areas.
- AI governance framework – An overarching framework that encompasses model risk management, TPRM [third-party risk management], and cybersecurity;
- AI inventory – A document describing all of the AI components and assets, including machine learning models and training data, that your company has developed so far;
- AI reporting – A system to monitor and report on the functionality of AI systems, in particular high-risk AI systems.
GenAI is changing quickly, and so are the risks that it entails. The NIST recently issued guidance on how to cope with GenAI-specific risks. EY’s Bhuva called out one of the risks: the tendency for AI models to make things up.
“Everyone’s been using the term ‘hallucination,’ but the NIST is specifically concerned with anthropomorphization of AI,” she said. “And so the thought was that hallucination makes AI seem too human. So they came up with the word confabulation to describe that. I haven’t actually heard anyone use confabulation. I think everyone is stuck on hallucinations, but that’s out there.”

Rani Bhuva (left), a principal at EY and EY Americas Financial Services Responsible AI Leader, and Kiranjot Dhillon, a senior manager at EY and the EY Americas Financial Services AI Leader, present at 2024 HPC + AI on Wall Street
There are a lot of aspects to responsible AI development, and bringing them all together into a cohesive program with effective controls and validation is not an easy task. To do it right, a company must adapt a variety of separate programs, everything from model risk management and regulatory compliance to data security and business continuity. Just getting everyone to work together towards this end is a challenge, Bhuva said.
“You really need to make sure that the appropriate parties are at the table,” she said. “This gets to be fairly complicated because you need to have different areas of expertise, given the complexity of generative AI. Can you talk about whether or not you’ve effectively addressed all controls associated with generative AI unless you check the box on privacy, unless you check the box on TPRM, data governance, model risk management as well?”
Following principles of ethical AI is another ball of wax altogether. Since the rules of ethical AI typically aren’t legally enforceable, it’s up to an individual company whether they will avoid using large language models (LLMs) that have been trained on copyrighted data, Bhuva pointed out. And even if an LLM provider indemnifies your company against copyright lawsuits, is it still ethical to use the LLM if you know it was trained on copyrighted data anyway?
“Another challenge, if you think about all of the assurances at the global level, they all talk about privacy, they talk about fairness, they talk about explainability, accuracy, security–all of the principles,” Bhuva said. “But a lot of these principles conflict with each other. So to ensure that your model is accurate, you necessarily need a lot of data, but you might be violating potential privacy requirements in order to get all that data. You might be sacrificing explainability for accuracy as well. So there’s a lot that you can’t solve for from a regulatory or legislative perspective, and so that’s why we see a lot of interest in AI ethics.”
Implementing Responsible GenAI
EY’s Kiranjot Dhillon, who is an applied AI scientist, provided a practitioner’s view of responsible AI to the HPC + AI on Wall Street audience.
One of the big challenges that GenAI practitioners are facing right now–and one of the big reasons why many GenAI apps haven’t been put into production–is the difficulty in knowing exactly how GenAI systems will actually behave in operational environments, Dhillon said.
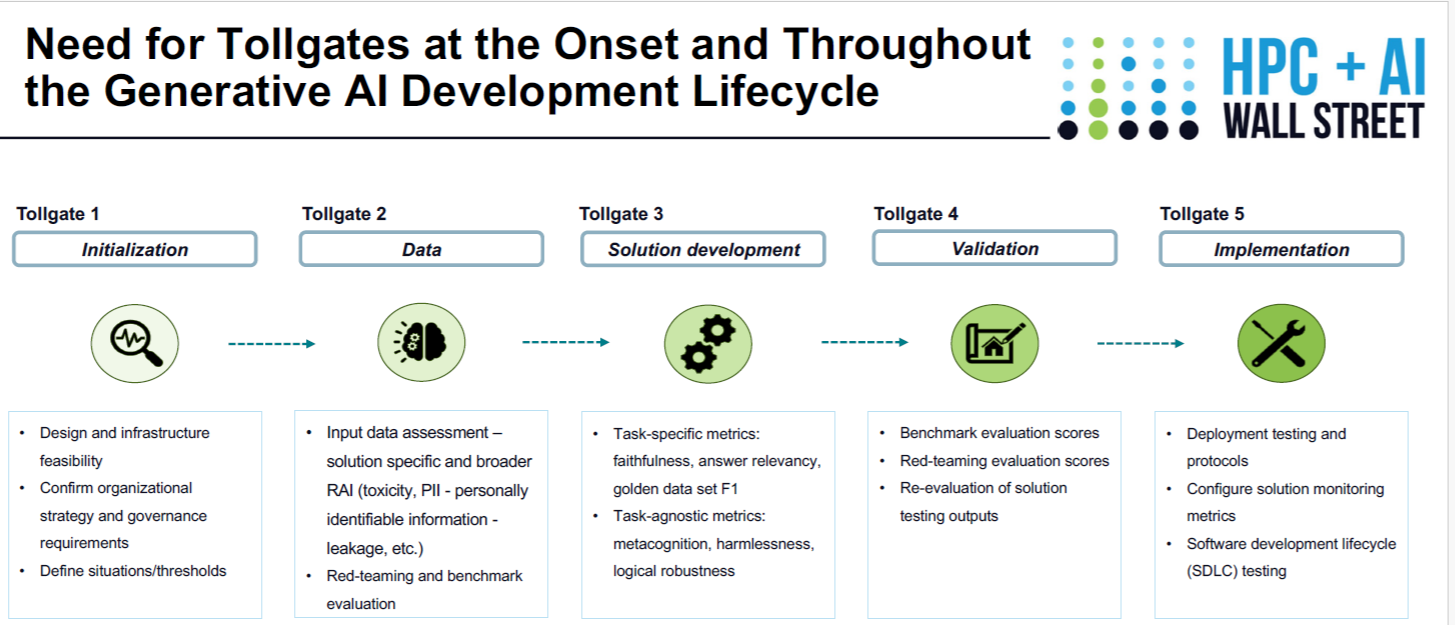
Tollgates are important to building responsible AI systems (Image courtesy EY)
“One of the key root causes is thinking through responsible AI and these risk mitigation practices towards the end of the solution-build life cycle,” she said. “It’s more retrofitting and overlaying these requirements to make sure that they are met, as opposed to thinking about that all the way on the onset.”
It’s hard to get clarity into that when you build the instrumentation that will inform that question into the system after-the-fact. It’s much better to do it from the beginning, she said.
“Responsible requirements need to be thought through right at the initialization stage,” Dhillon said. “And appropriate toll gates need to be then trickled through the individual subsequent steps and go all the way through operationalization and obtaining approvals in these individual steps as well.”
As the bones of the GenAI systems are laid down, it’s important for the developers and designers to think about the metrics and other criteria they want to collect to ensure that they’re meeting their responsible AI goals, she said. As the system, it’s up to the responsible AI team members–and possibly even a challenge team, or a “red team”–to step in and judge whether the requirements actually are being met.
Dhillon supports the use of user guardrails to build responsible GenAI systems. These systems, such as Nvidia’s Nemo, can work on both the input to the LLM as well as the output. They can prevent certain requests from reaching the LLM, and instruct the LLM not to respond in certain ways.
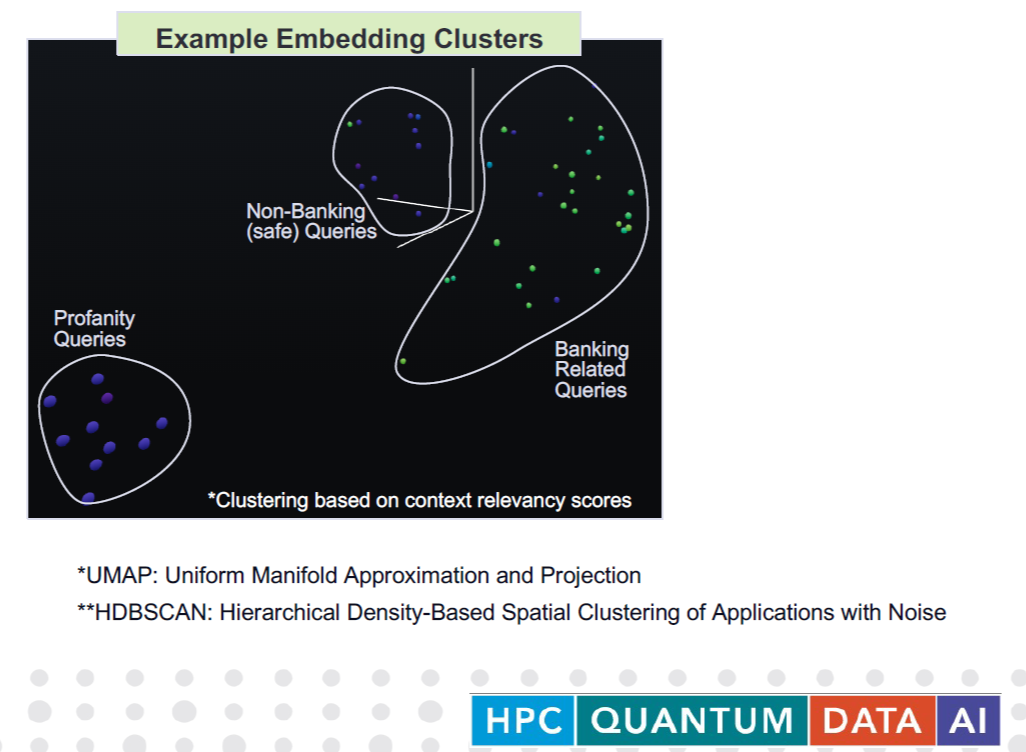
Visualization tools are useful for human assessment of GenAI behavior (Image courtesy EY)
“You could think about topical guardrails where the solution is not digressing from the topic at hand,” Dhillon said. “It could be safety and security guardrails, like trying to reduce hallucinations or confabulations, when we talk in the NIST terms, and trying to ground the solution more and more. Or preventing the solution from reaching out to an external, potentially unsafe applications right at the source level. So having those scenarios identified, captured, and tackled is what guardrails really provide us.”
Sometimes, the best guardrail for an LLM is a second LLM that will oversee the first LLM and keep an eye out for things like logical correctness, answer relevancy, or context relevancy, which are very popular in the RAG space, Dhillon said.
There are also some best practices when it comes to using prompt engineering in a responsible manner. While the data is relied upon to train the model in traditional machine learning, in GenAI, it’s sometimes best to give the computer explicit instructions to follow, Dhillon said.
“It’s thinking through what you’re looking for the LLM to do and instructing it exactly what you expect for it to do,” she said. “And it’s really as simple as that. Be descriptive. Be verbose in what your expectations of the LLM and instructing it to not answer when certain queries are asked, or answered in this way or that way.”
Depending on which type of prompting you use, such as zero-shot prompting, few-shot prompting, or chain-of-thought prompting, the robustness of the final GenAI solution will differ.
Finally, it’s necessary to have a human in the loop to monitor the GenAI system and ensure that it’s not going off the rails. During her presentation, Dhillon showed how having a visualization tool that can use automated statistical techniques to cluster a large number of responses can help the human quickly spot any anomalies or outliers.
“The idea here is that a human evaluator could quickly look at it and see that stuff that’s falling within that bigger, bean shaped cluster is very close to what the knowledge base is, so it’s most likely relevant queries,” she said. “And as you start to kind of go further away from that key cluster, you are seeing queries which could maybe be tangentially related. All the way to the bottom left is a cluster which is, upon manual review, turned out to be profane queries. So that’s why it’s very far off in the visualized dimensional space from the stuff that you would expect the LLM to be answered. And at that point, you can create the right types of triggers to bring in manual intervention.”
You can watch Bhava and Dhillon’s full presentation, as well as the other recorded HPC +
AI on Wall Street presentations, by registering at www.hpcaiwallstreet.com.
Related Items:
Biden’s Executive Order on AI and Data Privacy Gets Mostly Favorable Reactions
Bridging Intent with Action: The Ethical Journey of AI Democratization
NIST Puts AI Risk Management on the Map with New Framework
Source link
lol