In this article, we will create a Multimodal RAG application from scratch using Phi 3.5, without using any Agentic framework.
Creating chat RAG applications using LLMs is not straightforward. The process becomes even more complex when building a multimodal RAG application that supports text chat, PDF file upload, and chat with images & videos as well. Frameworks like LlamaIndex and LangChain help, however, they abstract away a lot of core components.
One option is to create the components from scratch in a simpler manner. Although creating every component from scratch makes it difficult to scale or productionize the application later, the understanding becomes solid.
The primary aim of this article is to cover all the small, yet core components that build the basis of a multimodal RAG application. We are not aiming to productionize the application here.
We will cover the following topics while building multimodal RAG
- What are the key components for building a multimodal RAG application?
- What will we be able to do after going through this project based article?
- Which GitHub codebase are we going to use?
- How do we tackle vector data storage locally for embedding search?
- What are the ways to handle PDFs, text files, images, and videos?
- How are we going to use Phi 3.5 and Phi 3.5 Vision for multimodal chat?
What are the Key Components for Building a Multimodal RAG Application?
A multimodal RAG application has three primary components:
- An embedding model that creates vectors of PDFs, and text files for initial storing and also for retrieval during chat.
- An LLM (Large Language Model) or SLM (Small Language Model) for chatting. This is can purely be a text-based model or a VLM (Vision Language Model) to chat with images and videos.
- And a proper user interface. Let’s face it, a terminal or Jupyter Notebook, although good starting points, are not user-friendly when creating chat applications.
Apart from the above, there are many other small, connected components. For example, helper scripts for reading and managing images & videos during chatting, managing chat history, and switching between models in between chat turns. We will figure all of these out in this article.
What Will We Be Able to Accomplish After This?
After going through this article and creating our custom multimodal RAG application, we will be able to accomplish the following:
- Learn how to create embeddings from PDF & text files and store them locally for similarity search.
- Learn how to create a UI for RAG based chat application using Phi 3.5.
- Chat with PDFs, text files, images, and videos using Phi 3.5 and Phi 3.5 Vision models.
What are the Primary Tools and Libraries that We are Using?
We are using the following libraries, tools, and frameworks:
- PyTorch as the base deep learning framework
- Hugging Face Transformers library for loading LLMs
- Sentence Transformers for embedding models as it has a close integration with the Hugging Face Transformers library
The local_file_search Application
You can also visit one of the previous posts, where we built a terminal based custom RAG pipeline from scratch using the same codebase. It also contains the link to download a stable version of the codebase so that you can you try out what is shown in the post. Since then, the project has changed substantially with an added Gradio UI for chatting. We will cover the updated components here and the stable code as of writing this will be provided with this article. However, feel free to visit the project on GitHub as well to see the updates that are happening.
The Project Directory Structure
Let’s take a look at the directory structure to have a better understanding of the project.
local_file_search-main ├── data │ ├── pdfs │ │ ├── pdf_llama │ │ │ └── 2302.13971v1.pdf │ │ ├── pdf_llama2 │ │ │ └── 2307.09288v2.pdf │ │ └── pdf_spreadsheet_llm │ │ └── 2407.09025v1.pdf │ ├── car_racing.mp4 │ ├── image.png │ ├── llama-flow.png │ ├── llama-report.png │ └── readme.txt ├── src │ ├── create_embeddings.py │ ├── csv_to_text_files.py │ ├── llm.py │ ├── pdf_file_check.py │ ├── search.py │ ├── train.py │ └── ui.py ├── LICENSE ├── README.md ├── requirements.txt └── setup.sh
- First, we have the
datadirectory that contains a few PDFs, images, and videos that we will use later for chatting with the language models. - The
srcdirectory contains all the source code files. - The root directory contains the requirements and other files necessary for a GitHub repository.
You can download a stable version of the codebase in zip file format from the download section.
Download Code
Installing Dependencies
After downloading and extracting the file, be sure to install the dependencies. It is recommended to use Anaconda to create a new environment and run the following command.
sh setup.sh
Creating a Multimodal RAG Application
Although there are several Python scripts inside the src directory, we will deal with the following only:
create_embeddings.pysearch.pyui.py
It will be very difficult to explain every line of code. So, for each file, we will have a general overview of the important functions that we are dealing with.
Embedding Creation
We will start with the code and functions present in create_embeddings.py.
Let’s begin with the import statements and the argument parser for command line arguments.
import os
import json
import argparse
import multiprocessing
import glob as glob
from sentence_transformers import SentenceTransformer
from tqdm.auto import tqdm
from pypdf import PdfReader
from joblib import Parallel, delayed
multiprocessing.set_start_method('spawn', force=True)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument(
'--add-file-content',
dest="add_file_content",
action='store_true',
help='whether to store the file content in the final index file or not'
)
parser.add_argument(
'--index-file-name',
dest="index_file_name",
help='file name for the index JSON file to be stored, '
'will be stored in ../data directory by default',
required=True
)
parser.add_argument(
'--directory-path',
dest="directory_path",
help='path to the directory either conteining text of PDF files',
required=True
)
parser.add_argument(
'--model',
default="all-MiniLM-L6-v2",
help='embedding model id from hugging face'
)
parser.add_argument(
'--chunk-size',
dest="chunk_size",
default=128,
type=int,
help='chunk size of embedding creation and extracing content if needed'
)
parser.add_argument(
'--overlap',
default=16,
type=int,
help='text overlap when creating chunks'
)
parser.add_argument(
'--njobs',
default=8,
help='number of parallel processes to use'
)
args = parser.parse_args()
return args
All of the above arguments are only helpful when executing this file directly from the terminal when creating embeddings of multiple files at once for chatting. Although we will not need it because we will deal with a user interface, it is still better to have an idea.
Later on, each of the code components is encapsulated in a function that we can use in different Python files.
Loading the Embedding Model
The following function is for loading the embedding model from Sentence Transformers.
# Load SBERT model
def load_model(model_id):
model = SentenceTransformer(model_id)
# Device setup (not needed for SentenceTransformer as it handles it internally)
device = model.device
print(device)
return model
The function accepts a model_id which it uses to load the model. By default, the model loads onto a GPU if a GPU is available.
Functions for File Manipulation and Embedding Creation
We have several functions to load, process, create chunks, and embed files.
# -1 = embed all files
total_files_to_embed = -1
def file_reader(filename):
if filename.endswith('.txt'):
with open(os.path.join(filename), 'r', errors="ignore") as file:
content = file.read()
return content
elif filename.endswith('.pdf'):
reader = PdfReader(os.path.join(filename))
all_text=""
for page in reader.pages:
all_text += page.extract_text() + ' '
return all_text
def extract_features(text, model):
"""
Extracts embeddings from a given text using the SentenceTransformer model.
:param text: The text to embed.
Returns:
embeddings: A list of embeddings.
"""
embeddings = model.encode(text)
return embeddings
In the above code block, the file_reader function identifies the file type, whether PDF or text file, and loads the text accordingly. The extract_feature function accepts a chunk of text and passes it through the Sentence Transformer model that we loaded above to create the embeddings and returns them.
def chunk_text(text, chunk_size=512, overlap=50):
"""Chunk the text into overlapping windows."""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
if i + chunk_size >= len(words):
break
return chunks
def encode_document(
filename,
documents,
add_file_content,
content,
chunk_size=512,
overlap=50,
model=None
):
"""Encode the document in chunks."""
chunks = chunk_text(content, chunk_size, overlap)
if not chunks: # If no chunks are possible.
features = extract_features(content, model).tolist()
if add_file_content: # If original file content to be added.
documents.append({
'filename': filename,
'chunk': 0,
'content': content,
'features': features
})
else:
documents.append({
'filename': filename,
'chunk': 0,
'features': features
})
else:
for i, chunk in enumerate(chunks):
features = extract_features(chunk, model).tolist()
if add_file_content: # If original file content to be added.
documents.append({
'filename': filename,
'chunk': i,
'content': chunk,
'features': features
})
else:
documents.append({
'filename': filename,
'chunk': i,
'features': features
})
return documents
The chunk_text function creates chunks out of the entire document based on the specified chunk size and overlap. All of these are controllable through the command line.
Next, the encode_document function passes the chunks to the extract_features function based on whether chunks are created or not. Sometimes, small enough files are encoded as they are. These embeddings are added to a documents list as a dictionary that we will later save as a JSON file on disk.
def load_and_preprocess_text_files(
documents,
filename,
add_file_content=False,
chunk_size=128,
overlap=16,
model=None
):
"""
Loads and preprocesses text files in a directory.
:param directory: The directory containing the text files.
Returns:
documents: A list of dictionaries containing filename and embeddings.
"""
content = file_reader(filename)
documents = encode_document(
filename,
documents,
add_file_content,
content,
chunk_size=chunk_size,
overlap=overlap,
model=model
)
return documents
The load_and_preprocess_text_files is called iteratively through a for loop based on the number of files in a directory. It extracts the content from the files, encodes them, and populates the documents variable.
Although we will not be using the next main code block, when we execute the file from the terminal, it uses multiprocessing to process several files in a directory in parallel based on the number of jobs we pass. This is helpful when creating embeddings of thousands of files.
if __name__ == '__main__':
args = parse_opt()
model = load_model(args.model)
results = []
all_files = glob.glob(os.path.join(args.directory_path, '**'), recursive=True)
all_files = [filename for filename in all_files if not os.path.isdir(filename)]
print(all_files)
all_files.sort()
if total_files_to_embed > -1:
files_to_embed = all_files[:total_files_to_embed]
else:
files_to_embed = all_files
results = Parallel(
n_jobs=args.njobs,
backend='multiprocessing'
)(delayed(load_and_preprocess_text_files)(
results,
filename,
args.add_file_content,
args.chunk_size,
args.overlap,
model
)
for filename in tqdm(files_to_embed, total=len(files_to_embed))
)
documents = [res for result in results for res in result]
# Save documents with embeddings to a JSON file
with open(os.path.join('..', 'data', args.index_file_name), 'w') as f:
json.dump(documents, f)
Defining the Search Functionality
The search.py file contains all the logic to carry out the nearest embedding search according to the user query. The functions can be imported to be used by other Python files or the search script can be run standalone from the terminal. In our use case, we will import the necessary functions in another file. However, let’s go through the entire file.
The following are the import statements and the command line arguments.
import json
import argparse
import torch
from sentence_transformers import SentenceTransformer
from tqdm import tqdm
from llm import generate_next_tokens
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig
)
def parser_opt():
parser = argparse.ArgumentParser()
parser.add_argument(
'--index-file',
dest="index_file",
# required=True,
help='path to an indexed embedding JSON file'
)
parser.add_argument(
'--extract-content',
dest="extract_content",
action='store_true',
help='whether to print the related content or not
as the index file does not always contain file content'
)
parser.add_argument(
'--model',
default="all-MiniLM-L6-v2",
help='embedding model id from hugging face'
)
parser.add_argument(
'--llm-call',
dest="llm_call",
action='store_true',
help='make call to an llm to restructure the answer'
)
parser.add_argument(
'--topk',
default=5,
type=int,
help='number of chunks to retrieve'
)
args = parser.parse_args()
return args
All the command line arguments have a default value that the functions accept as parameters so that when calling from other files, we can override them.
Loading the Embedding Model
The next function is to load the embedding model based on the model_id passed.
def load_embedding_model(model_id=None):
# Load SBERT model
model = SentenceTransformer(model_id)
return model
It is essential to note that we need to use the same model for embedding search as for creating embeddings.
Processing the User Query
The next three functions process the user query, convert them into embeddings, and search the nearest embedding in the indexed file.
def extract_features(text, model):
"""Generate SBERT embeddings for the input text."""
return model.encode(text)
def process_query(query, model):
"""Preprocess the query and generate SBERT embeddings."""
query_features = extract_features(query, model).tolist()
return query_features
def search(query, documents, model, top_k=5):
"""Search for the most relevant documents to the query."""
print('SEARCHING...')
query_features = process_query(query, model)
scores = []
for document in tqdm(documents, total=len(documents)):
score = model.similarity([query_features], [document['features']])[0][0]
scores.append((document, score))
scores.sort(key=lambda x: x[1], reverse=True)
return scores[:top_k]
In the above search function, documents refers to the indexed file that contains the vectors of the PDF or text file.
Showing the Most Relevant Part
For convenience, we add an extra functionality of showing the most relevant part in each top-matching chunk. These top-matching parts will be highlighted in red and displayed in the terminal, be it direct execution of the search script or if using the functions by importing them.
def chunk_text(text, chunk_size=100, overlap=50):
"""Chunk the text into overlapping windows."""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
if i + chunk_size >= len(words):
break
return chunks
def extract_relevant_part(query, content, model, chunk_size=32, overlap=4):
"""Extract the part of the content that is most relevant to the query."""
chunks = chunk_text(content, chunk_size, overlap)
if not chunks:
return content # Return full content if it can't be split
chunk_embeddings = model.encode(chunks)
query_embedding = extract_features(query, model)
scores = model.similarity([query_embedding], chunk_embeddings).flatten()
best_chunk_idx = scores.argmax()
return chunks[best_chunk_idx]
This gives the user a visual cue as to which of the parts of the indexed file are responsible for the LLM’s answer. Furthermore, this also gives an idea of whether we need to improve/change our embedding model based on a specific use case.
Loading the Documents and Searching for Relevant Chunks
The following two functions load the indexed file and carry out the search functionality respectively.
def load_documents(file_path):
"""Load preprocessed documents and embeddings from a JSON file."""
with open(file_path, 'r') as f:
documents = json.load(f)
return documents
def main(documents, query, model, extract_content, topk=5):
RED = "�33[31m"
RESET = "�33[0m"
# Perform search.
results = search(query, documents, model, topk)
relevant_parts = []
retrieved_docs = []
for result in results:
document = result[0]
print(f"Filename: {result[0]['filename']}, Score: {result[1]}")
# Search for relevevant content if `--extract-content` is passed.
if extract_content:
try:
document['content']
retrieved_docs.append(document['content'])
except:
raise AssertionError(f"It looks like you have passed "
f"`--extract-content` but the document does not contain "
f"original file content. Please check again... "
f"Either create a new index file with the file content or "
f"remove `--extract-content` while executing the search script"
)
relevant_part = extract_relevant_part(query, document['content'], model)
relevant_parts.append(relevant_part)
# Few color modifications to make the output more legible.
document['content'] = document['content'].replace(relevant_part, f"{RED}{relevant_part}{RESET}")
print(f"Retrieved document: {document['content']}n")
return retrieved_docs
The main function accepts the loaded indexed document, the user query, the embedding model, and other relevant parameters to carry out the search functionality. If the user has passed extract_content=True while calling the function, then the most relevant parts will be displayed in the terminal.
The following is the main block which only gets executed when executing the script from the terminal.
if __name__ == '__main__':
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
RED = "�33[31m"
RESET = "�33[0m"
args = parser_opt()
topk = args.topk
extract_content = args.extract_content
# Load embedding model.
embedding_model = load_embedding_model(args.model)
# Load documents.
documents_file_path = args.index_file
documents = load_documents(documents_file_path)
# Load the LLM only when if `args.llm` has been passed by user.
if args.llm_call:
quant_config = BitsAndBytesConfig(
load_in_4bit=True
)
tokenizer = AutoTokenizer.from_pretrained(
'microsoft/Phi-3-mini-4k-instruct', trust_remote_code=True
)
llm_model = AutoModelForCausalLM.from_pretrained(
'microsoft/Phi-3-mini-4k-instruct',
quantization_config=quant_config,
device_map=device,
trust_remote_code=True
)
# Keep on asking the user prompt until the user exits.
while True:
query = input(f"n{RED}Enter your search query:{RESET} ")
context_list = main(documents, query, embedding_model, extract_content, topk)
if args.llm_call:
context="nn".join(context_list)
generate_next_tokens(
user_input=query,
context=context,
model=llm_model,
tokenizer=tokenizer,
device=device
)
It combines everything together using the argument parsers’ default values and initiates the search functionality.
Creating the Gradio UI for Multimodal RAG
The final piece of the puzzle is creating the Gradio user interface for our multimodal RAG application. We will combine a lot of components together, so, it will be slightly complex. In the article, we create a Gradio UI for chatting with just images and videos. However, here we will add the functionality for PDF, text, images, and video chat.
The code for creating the user interface is present in ui.py.
Let’s start with the import statements, the argument parsers, and defining a few global variables.
import gradio as gr
import json
import os
import threading
import argparse
import cv2
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TextIteratorStreamer,
AutoProcessor
)
from search import load_documents, load_embedding_model
from search import main as search_main
from create_embeddings import load_and_preprocess_text_files
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument(
'--share',
action='store_true'
)
args = parser.parse_args()
device="cuda"
model_id = None
model = None
tokenizer = None
streamer = None
processor = None
In the above code block, we have imported all the relevant functions from the different scripts discussed above. Along with that, we define the computation device and a few global variables whose use case we will see shortly.
Loading the Phi-3.5 Chat and Phi-3.5 Vision Models
As we are dealing with both text and image files here, we need to load Phi’s chat and vision instruct models.
def load_llm(chat_model_id):
global model
global tokenizer
global streamer
global processor
gr.Info(f"Loading model: {chat_model_id}")
quant_config = BitsAndBytesConfig(
load_in_4bit=True
)
processor = AutoProcessor.from_pretrained(
chat_model_id,
trust_remote_code=True,
num_crops=4
)
tokenizer = AutoTokenizer.from_pretrained(
chat_model_id, trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
chat_model_id,
quantization_config=quant_config,
device_map=device,
trust_remote_code=True,
_attn_implementation='eager'
)
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
Along with the models, we load the respective tokenizer and processor. Note that the Phi-3.5 VLM requires an image processor internally. Also, as we will provide a dropdown to the user to choose between different Phi models, we override the global variables that we initialized earlier. This way, the model, tokenizer, and processor get overridden whenever a new model is chosen.
Function to Handle Images and Videos
We have two helper functions to handle images and videos the user uploads.
def load_and_preprocess_images(image_path):
image = Image.open(image_path)
return image
def load_and_process_videos(file_path, images, placeholder, counter):
cap = cv2.VideoCapture(file_path)
length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
for i in range(length):
counter += 1
cap.set(cv2.CAP_PROP_POS_FRAMES, i)
ret, frame = cap.read()
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
images.append(Image.fromarray(image))
placeholder += f"<|image_{counter}|>n"
return images, placeholder, counter
It is worthwhile to note that the VLMs do not process the videos directly. Instead, they work on the frames of the videos. So, the load_and_process_videos function accepts a video file path, an images list, a placeholder string, and a counter to extract the frames and add them to the images list.
The placeholder is a string template meant for the Phi-3.5 Vision model only. It is a way to recognize the number of images/frames that have been passed to the processor. Do take a look at the documentation to get a better idea.
The next code block defines a few more variables that we need along the way.
embedding_model = load_embedding_model('all-MiniLM-L6-v2')
CONTEXT_LENGTH = 3800 # This uses around 9.9GB of GPU memory when highest context length is reached.
GLOBAL_IMAGE_LIST = []
documents = None
results = []
By default, we use the all-MiniLM-L6-v2 from Sentence Transformers to keep things simple. As the user loads the PDFs or text files to the UI and the embeddings are generated on the fly, there is a very low risk of embedding mismatch during embedding creation and search.
Function to Generate Next Token
The next function does most of the heavy lifting and is quite large.
def generate_next_tokens(user_input, history, chat_model_id):
global documents
global results
global model_id
# If a new PDF file is uploaded, create embeddings, store in `temp.json`
# and load the embedding file.
images = []
placeholder=""
if len(user_input['files']) != 0:
for file_path in user_input['files']:
counter = 0
if file_path.endswith('.mp4'):
GLOBAL_IMAGE_LIST.append(file_path)
images, placeholder, counter = load_and_process_videos(
file_path, images, placeholder, counter
)
elif file_path.endswith('.jpg') or
file_path.endswith('.png') or
file_path.endswith('.jpeg'):
counter += 1
GLOBAL_IMAGE_LIST.append(file_path)
image = load_and_preprocess_images(
file_path
)
images.append(image)
placeholder += f"<|image_{counter}|>n"
elif file_path.endswith('.pdf') or
file_path.endswith('.txt'):
results = load_and_preprocess_text_files(
results,
file_path,
add_file_content=True,
chunk_size=128,
overlap=16,
model=embedding_model
)
embedded_docs = [result for result in results]
# Save documents with embeddings to a JSON file.
with open(os.path.join('..', 'data', 'temp.json'), 'w') as f:
json.dump(embedded_docs, f)
documents = load_documents(os.path.join('..', 'data', 'temp.json'))
if chat_model_id == 'microsoft/Phi-3.5-vision-instruct' and len(images) == 0:
counter = 0
for i, file_path in enumerate(GLOBAL_IMAGE_LIST):
if file_path.endswith('.mp4'):
images, placeholder, counter = load_and_process_videos(
file_path, images, placeholder, counter
)
else:
counter += 1
image = load_and_preprocess_images(
file_path
)
images.append(image)
placeholder += f"<|image_{counter}|>n"
if chat_model_id == 'microsoft/Phi-3.5-vision-instruct' and len(images) == 0:
gr.Warning(
'Please upload an image to use the Vision model. '
'Or select one of the text models from the advanced '
'dropdown to chat with PDFs and other text files.',
duration=20
)
if chat_model_id != 'microsoft/Phi-3.5-vision-instruct' and len(images) != 0:
gr.Warning(
'You are using a text model. '
'Please select a Vision model from the advanced '
'dropdown to chat with images.',
duration=20
)
if chat_model_id != model_id:
load_llm(chat_model_id)
model_id = chat_model_id
# print(f"User Input: ", user_input)
# print('History: ', history)
print('*' * 50)
final_input=""
user_text = user_input['text']
if len(images) != 0:
final_input += placeholder+user_text
chat = [
{'role': 'user', 'content': placeholder+user_text},
]
template = processor.tokenizer.apply_chat_template(
chat,
tokenize=False,
add_generation_prompt=True
)
else:
# Get the context.
context_list = search_main(
documents,
user_text,
embedding_model,
extract_content=True,
topk=3
)
context="nn".join(context_list)
final_input += user_text + 'n' + 'Answer the above question based on the following context:n' + context
chat = [
{'role': 'user', 'content': 'Hi'},
{'role': 'assistant', 'content': 'Hello.'},
{'role': 'user', 'content': final_input},
]
template = tokenizer.apply_chat_template(
chat,
tokenize=False,
add_generation_prompt=True
)
# Loading from Gradio's `history` list. If a file was uploaded in the
# previous turn, only the file path remains in the history and not the
# content. Good for saving memory (context) but bad for detailed querying.
if len(history) == 0 or len(images) != 0:
prompt="<s>" + template
else:
prompt="<s>"
for history_list in history:
prompt += f"<|user|>n{history_list[0]}<|end|>n<|assistant|>n{history_list[1]}<|end|>n"
prompt += f"<|user|>n{final_input}<|end|>n<|assistant|>n"
print('Prompt: ', prompt)
print('*' * 50)
if len(images) != 0:
inputs = processor(prompt, images, return_tensors="pt").to(device)
generate_kwargs = dict(
**inputs,
eos_token_id=processor.tokenizer.eos_token_id,
streamer=streamer,
max_new_tokens=1024,
)
else:
inputs = tokenizer(prompt, return_tensors="pt").to(device)
input_ids, attention_mask = inputs.input_ids, inputs.attention_mask
generate_kwargs = dict(
{'input_ids': input_ids.to(device), 'attention_mask': attention_mask.to(device)},
streamer=streamer,
max_new_tokens=1024,
)
# A way to manage context length + memory for best results.
print('Global context length till now: ', input_ids.shape[1])
if input_ids.shape[1] > CONTEXT_LENGTH:
input_ids = input_ids[:, -CONTEXT_LENGTH:]
attention_mask = attention_mask[:, -CONTEXT_LENGTH:]
print('-' * 100)
if len(images) != 0:
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output="".join(outputs)
yield final_output
else:
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output="".join(outputs)
yield final_output
Let’s summarize what the above function does.
- Based on whether a file has been uploaded or not, it loads the PDF/text file, creates an indexed file, stores it to disk as
temp.json, and loads it for embedding search. - If the user has uploaded an image or a video, it extracts the frames and appends them to the
imageslist. - If it is a second-turn chat and the user has not uploaded anything, then the
GLOBAL_IMAGE_LISTis used to load the images and videos from the previous chat, if any. Else, the chat history is used for text-only chat. - If the user chooses the wrong modality for the chat, then a warning pops up on the screen.
- Then the function manages the chat templates based on whether the user uploaded an image/video or is just using text chat.
- It manages the chat history accordingly as well.
- Finally, the function does a forward pass through a model in parallel and yields the new tokens to the Gradio output box as they are generated.
The Main Code Block
In the end, we have the main function that creates the Gradio UI and launches the application.
def main():
iface = gr.ChatInterface(
fn=generate_next_tokens,
multimodal=True,
title="Image, PDF, and Text Chat with Phi Models",
additional_inputs=[
gr.Dropdown(
choices=[
'microsoft/Phi-3.5-mini-instruct',
'microsoft/Phi-3-small-8k-instruct',
'microsoft/Phi-3-medium-4k-instruct',
'microsoft/Phi-3-small-128k-instruct',
'microsoft/Phi-3-medium-128k-instruct',
'microsoft/Phi-3.5-vision-instruct'
],
label="Select Model",
value="microsoft/Phi-3.5-mini-instruct"
)
],
theme=gr.themes.Soft(primary_hue="orange", secondary_hue="gray")
)
iface.launch(share=args.share)
if __name__ == '__main__':
main()
We give the user to choose between several Phi family of text models. For the vision model, we only have Phi-3.5 VLM which is the best performing till now.
Launching the Multimodal Gradio App
To launch the application, execute the ui.py script within the src directory and open the localhost link (http://127.0.0.1:7860) that appears on the terminal.
python ui.py
Demo Use Cases
Following are some videos showcasing the capabilities of the multimodal RAG application that we built.
First, we have a demo while chatting with the Llama 3 PDF.
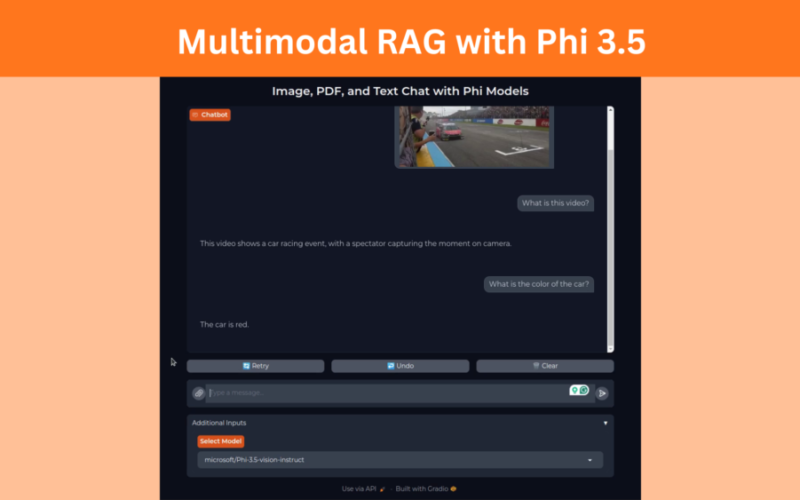
The next demo shows using the VLM to chat with an image.
Finally, we have a demo for chatting with a video file.
The above are simple demos. We can surely do a lot more with this application, for example, switching between vision and text models to have long context chat about images and videos. Do give them a try on your own.
Summary and Conclusion
In this article, we create a multimodal RAG application using Phi-3.5 models. Starting from the process of chunking, embedding creation, and searching, to creating the UI, we covered everything. However, this may prove difficult to scale. For scaling and getting it production ready, it is always better to use a vector database. We will try to cover that in one of the future articles. I hope that this article was worth your time.
If you have doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol