I’ve been thinking a lot about how to evaluate LLM-generated output. Evals are essential for teams looking to create more scalable and reliable AI-powered experiences. Sadly, out of all the patterns for building with LLMs, I’ve found evals the hardest to scale. That said, I’ve made some progress and am excited to share about AlignEval. It’s an app that tries to make evals easy, fun, and semi-automated.
How important evals are to the team is a differentiator between folks rushing out hot garbage and those seriously building products. — Hackernews
In AlignEval, in addition to aligning AI to human feedback (e.g., prompt engineering, finetuning, RAG), we also align human criteria to AI output.
This addresses a common mistake I see many teams make, where they design intricate evaluation criteria without first looking at the data. This is akin to theorizing from the ivory tower without hands-on experience in the trenches. The paper Who Validates the Validators puts it well: “It is impossible to completely determine evaluation criteria prior to human judging of LLM outputs.”
Because of this mistake, the chosen criteria are either irrelevant or have unrealistically high expectations. If the criteria are irrelevant, teams waste time evaluating overly generic criteria (e.g., helpfulness), or defects that don’t actually occur (e.g., grammar, spelling). If the criteria are unrealistic, teams waste effort trying to achieve something the technology isn’t ready for (e.g., agents back in 2023). Either way, this effort would have been better invested in evaluating defects that are actually generated with moderate probability.
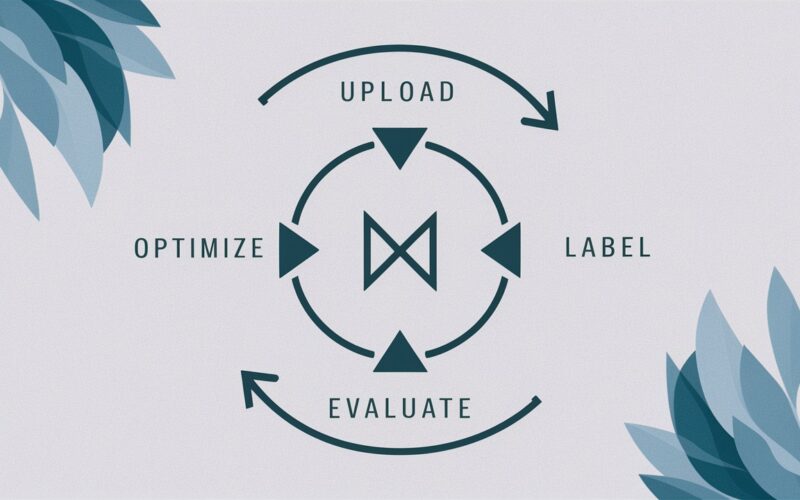
The solution is to work backward from the data. AlignEval facilitates this by making it easy to look at the data, label it, run and evaluate LLM-evaluators, and optimize them.
Three easy pieces: Label, Evaluate, Optimize
When you first visit AlignEval, you’re greeted with a popup that explains how to use it.
To get started, upload a CSV file containing the following columns:
- id: Allows you to match labeled and evaluated samples to your data
- input: Provided to the LLM to generate the output (e.g., text to classify, news to summarize, retrieved documents for answering questions)
- output: Generated by the LLM (e.g., classification label, summary, answer)
- label: Your judgment on whether the output passes (0) or fails (1)

If you don’t have a CSV handy, download a sample based on the Factual Inconsistency Benchmark. The sample contains 50 news articles and their summaries. Each news article has a pair of summaries where one is factually consistent (aka faithful) while the other is not (i.e., contains hallucinations).
After uploading the CSV, you’ll see a table that flexes to the width of the browser. This allows you to control how wide or narrow you want the table and columns to be.

In labeling mode, our only job is to look at the data. AlignEval streamlines the process into a comparison between the input and output fields. For each sample, we make a binary decision of whether the output passes or fails.

DoorDash also collects labels via binary questions. Their goal is to simplify the task for annotators to increase precision and throughput. Similarly, the Llama2 paper shares how they focus on collecting binary human preferences. The authors also shared at a meetup that collecting binary preferences was much faster than writing samples for supervised finetuning. Overall, by keeping the task simple and focused, we can ensure accurate labels and high throughput, while keeping cognitive load low.
Notice that we can’t define criteria for, or run evals with, our LLM-evaluator yet. First, we have to look at our data. This reduces the risk of defining criteria for defects that don’t occur, or writing criteria with unrealistic expectations. By doing this, we get more meaningful criteria that align better with what the LLM actually generates.
From Jason Liu’s RAG course; sign up for his next RAG course here
As we review each row, we label the output as pass or fail. After labeling 20 rows, we unlock evaluation mode. (Note that 20 samples are probably the bare minimum to understand the data well enough to start defining evaluation criteria. Also, it may be too small a sample to start evaluating our LLM-evaluators. Personally, I’d label around ~200 samples before writing criteria and running evals. Thus, don’t let AlignEval’s guideline of 20 samples discourage you from labeling more samples.)
After unlocking evaluation mode, we can now write our task-specific evaluation criteria. When writing criteria and prompts, it helps to start simple. My suggestion is to evaluate the output on a single dimension and return a binary result, either 0 (pass) or 1 (fail).

Here’s the prompt I use for factual inconsistency classification. We start with only two sentences that define what a pass or fail looks like. We can refine it after running the LLM-evaluator and examining the explanations and predictions.

Before running the LLM evaluator, we need to decide which model to use and what fields to consider. Model-wise, we can choose between gpt-4o-mini and claude-3-haiku. For the fields, we can either use both the input and output, or evaluate the output only.
In most use cases (e.g., classification, summarization, Q&A), we want to compare the output to the input. Nonetheless, there are tasks where only the output is necessary, such as assessing adherence to a style guide or evaluating tone of voice. By only considering the output field, we allow the LLM-evaluator to focus its attention on the output while reducing input token cost and latency.
At this stage, it’s also important to evaluate our LLM-evaluators. Since we’ve labeled some data, we can evaluate our LLM-evaluator against it. As soon as we hit the “Evaluate” button, we’ll see metrics in the top right corner. These metrics include the number of evaluated samples, recall, precision, F1, and Cohen’s $kappa$. We also include the count of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).

If our sample size is low (e.g., 20), these metrics can fluctuate a lot, even when we rerun the same LLM-evaluator. This is because LLM(-evaluator) outputs are stochastic. The best way to improve metric stability is to add more labels. Labeling more data also unlocks optimization mode which requires at least 50 labeled samples.
Optimization mode is where we try to improve our LLM-evaluator. Click the “Optimize” button and let AlignEval do its thing. Admittedly, it’s still in early beta and doesn’t reliably improve the LLM-evaluator. Nonetheless, for the few use cases I’ve tried, it’s been able to achieve decent improvements within 10 trials. (And no, it’s not dspy.)

Behind the scenes, the optimization process splits the labeled data into two halves: dev and test. (In machine learning, data is typically divided into train-test or train-val-test splits. However, since we’re developing an LLM-evaluator instead of training a model, we’ll call it a development split.) The optimizer then works to improve the LLM-evaluator with the model and fields used in evaluation mode. It runs $n$ optimization trials on the dev set to improve the F1 score. After $n$ trials, the improved LLM-evaluator is run on the test split.

Sometimes, we see a significant difference between the metrics on the dev and test split. Given the small sample size (25 for dev, 25 for test, 50 in total), this is likely due to the dev split having too few samples and not being representative of the full data distribution (including the test split). As a result, the LLM-evaluator may overfit on the dev split and not generalize well to the test set.
To improve generalization across the dev and test splits, we can label more data, ensuring that it’s diverse and representative. To be diverse is to be balanced in both 0 and 1 labels, and the variety of inputs and outputs. To be representative is to be similar to real-world examples. We can also run multiple LLM-evaluators in parallel and ensemble their scores. PoLL showed that an ensemble of three smaller LLM-evaluators outperformed gpt-4.
Here’s a 5-minute video where I upload some data and go through the process end to end.
https://www.youtube.com/watch?v=H5GrAyUNQxA
Behind the scenes: How AlignEval was built
I’m new to frontend development (this is my first TypeScript app!) Thus, I ran polls on Twitter and LinkedIn to draw on the wisdom of the crowd. I also got a feel of several frameworks by using them to build the same app five times. I tried FastHTML, Next.js, SvelteKit, and FastAPI + HTML (my go-to for prototyping).
I found Next.js to be the most intuitive. It could also scale to become a full-fledged app. Plus, it gave me an excuse to learn TypeScript. Although it was my first time coding in TypeScript, thanks to Cursor senpai, I had all my beginner questions answered easily. (What’s the difference between const and let? What is a prop?) Cursor also made it easier to build UI components and fix bugs. Without a coding assistant, I would probably have taken 2-3x more time and had to slog through as motivation decreased over time.
For the backend, I opted for Python and FastAPI. Python’s ecosystem for data analysis and machine learning tasks made it easier to experiment with optimization mode.
For LLMs, I went with the smolest models from the biggest labs: gpt-4o-mini and claude-3-haiku (will update to claude-3.5-haiku when it’s GA). Both are cheap and fast while being decently capable, making them good value for money (essential when hosting a free app!) And with each release, these small models just keep getting stronger.
For gpt-4o-mini, I used the structured output functionality that’s still in beta. It allows users to define the desired output schema using Zod for JavaScript and Pydantic for Python. Here’s an example in Javascript and its equivalent in Python:
import { z } from "zod";
const EvaluationResponse = z.object({
explanation: z.string(),
prediction: z.string().refine((val) => val === '0' || val === '1')
});
from pydantic import BaseModel
class EvaluationResponse(BaseModel):
explanation: str
prediction: str
For claude-3-haiku, I indicated the XML output via the prompt. From what I’ve seen on the job and in AlignEval, this works 99.9% of the time. Here’s the prompt I used for AlignEval.
Evaluate the output based on the provided criteria. First, in the <sketchpad> provided, think through your evaluation step by step.
Then, provide a binary prediction (0 or 1) within <prediction>.
To decide on hosting, I conducted a Twitter poll. I also consulted documentation for various platforms like Dokku, Coolify, Vercel, etc. I also found Hamel’s writeup on Dokku helpful. While I initially considered hosting the app on a Hetzner server (yay, I get to learn Dokku in the process), I ultimately decided to take the lazy path (read: prioritize ruthlessly) and start with hosting on Railway.
Hosting on Railway has been a breeze. After setting up the project via their web UI and linking it via the CLI (railway link), pushing new updates is as simple as railway up. Railway also has several database options, including Postgres and Redis. While I’d likely scale more cheaply with a VPS, given the current stage of AlignEval, YAGNI. Setting up a VPS would have been a distraction from figuring out the UX, implementing features, and experimenting with optimization mode.

If you’d like to get started on Railway, please use my affiliate code—it’ll help with hosting costs!
Going from a prototype that works on my laptop to a beta that’s open to public took some effort. There was a lot of polishing involved, including:
- Splitting into Next.js frontend, FastAPI backend, migrating from SQLite to Postgres
- Providing real-time feedback during labeling, evaluation, and optimization
- Features to simplify labeling (pass/fail buttons), customize models and fields (dropdowns, integration with model providers), and more
- Improving the UI (as rough as it looks now, it was way worse before lol)
- Squashing lots of bugs (and there are probably more I’ve not come across)
Here’s the to-do list I had for the app; there were many more tasks and bugs that I neglected to track. And I couldn’t finish everything because I timeboxed the effort to October. Perhaps I’ll get to them if folks find AlignEval useful and there’s traction.
## Todos
- [x] Split deployment into frontend and backend
- https://help.railway.app/questions/how-to-expose-a-fast-api-backend-service-a1712631
- https://help.railway.app/questions/econnrefused-when-calling-another-servic-5662d969#p-1
- ~~[ ] Or consider something like this: https://vercel.com/templates/next.js/nextjs-fastapi-starter~~ (only works with Vercel)
- [x] Add external database (Railway Postgres)
- [x] Write interface to ensure compatibility between SQLite and Postgres
- [x] Connect label-app to Railway Postgres
- [x] Connect label-hpo to Railway Postgres
- [x] Show feedback to users while optimization is running
- [x] Update table names to use CSV file name
- [x] Add support for multiple tables
- [x] Replace tablename parameter with filename parameter
- [x] Uploading a CSV file with an existing name should return the existing table
- [x] Add llm-evaluator optimization to label-hpo
- [x] Add dropdown to select evaluation fields
- [x] Add ability to delete optimization table, with password
- [x] Add progress bar to gamify labeling, evaluation and optimization
- [x] Add buttons to click pass and fail
- [x] Add usage count (upload (files, rows), evaluate (files, rows), optimize (files, trials))
- [x] Add info button intro next to header to explain the site
- [x] Update favicon
- [x] Add support for OpenAI models
- [x] Add balanced val-test split for optimization
- [x] Add columns to optimization metrics: split (dev, test), model, evaluation_fields
- [x] Set max upload rows to env variable
- [ ] Fix bug where alert pops up: "Failed to handle optimization: Unexpected token '<', "<!DOCTYPE "... is not valid JSON"
- Still pops up every now and then
- [x] Fix bug where evaluation alert pops up even when optimization is unlocked
- [x] Add popup to see full prompt
- [x] Add button to copy prompt
- [x] Add completion bar to optimization sticky
- [x] Make site look retro and like a game
- [x] Prompt users to rename sample data before downloading
- [x] Update delete optimization to reset optimization, and set password to Twitter handle
- [x] Add "don't show me this again" checkbox
- [ ] Improve how we poll for data
- [ ] Add button to donate with Stripe payment
- [ ] Add button to optimize more with Stripe payment
## Todos (OE)
- [x] Separate out data definitions to definitions.ts
- [x] Separate out fetch data queries to data.ts
- [x] Separate out data mutations to actions.ts
- [x] Separate out components into component.tsx under ui which are imported in page.tsx
• • •
I had a ton of fun building AlignEval as well as writing about it. (This is probably my favorite thing I’ve written this year. That said, there’s still two months in 2024.) If you want to build and align LLM-evaluators in hours instead of days or weeks, try AlignEval. It’s designed to streamline the workflow and focus on what matters most: (i) looking at and labeling the data, (ii) defining meaningful criteria, (iii) evaluating the LLM-evaluator, and (iv) semi-automatically optimizing it.
You may also be interested in the code on GitHub. It’s my first TypeScript project, so constructive feedback is welcome! What else have you found helpful when building LLM-evaluators? Comment below or DM me.
Thanks to the following folks who made discussing this topic so much fun, and provided helpful feedback at early demos: Shreya Shankar, Hamel Husain, Kyle Corbitt, David Corbitt, Saumya Gandhi, Swyx, Eugene Cheah, and Dennis Taylor.
Further reading
If you found this useful, please cite this write-up as:
Yan, Ziyou. (Oct 2024). AlignEval: Building an App to Make Evals Easy, Fun, and Automated. eugeneyan.com.
https://eugeneyan.com/writing/aligneval/.
or
@article{yan2024aligneval,
title = {AlignEval: Building an App to Make Evals Easy, Fun, and Automated},
author = {Yan, Ziyou},
journal = {eugeneyan.com},
year = {2024},
month = {Oct},
url = {https://eugeneyan.com/writing/aligneval/}
}Share on:
Join 8,800+ readers getting updates on machine learning, RecSys, LLMs, and engineering.
Source link
lol