
Phi-3.5 redefined what SLMs (Small Language Models) are capable of. Phi-3.5 Mini Instruct, Phi-3.5 MOE Instruct, and particularly, Phi-3.5 Vision Instruct, all beat models more than twice and even sometimes thrice their size in active parameters when running benchmarks. Among these, the Phi-3.5 Vision Instruct model is perhaps the most astonishing. With just 4.2B parameters, on-device multimodal chat is now extremely accessible. In this article, we will build a Gradio application using Phi-3.5 with support for multi-turn multimodal chat with images and videos.
We will cover the following topics for Phi-3.5 multimodal chat
- Why do we need multimodal chat?
- How do we handle images and videos with Phi-3.5 multimodal chat?
- How do we manage history with Phi-3.5 multimodal chat?
- What are some of the limitations of our Phi-3.5 multimodal chat and how to overcome them?
Why Do We Need Multimodal Chat?
Conversational models like ChatGPT and Claude have become ubiquitous and to some level indispensable as well. They have both text and multimodal capabilities. We can chat with images, PDFs, and PPTs. However, they cannot handle videos yet, and we cannot control our data at all when using their interface. That is one of the foremost reasons for creating our multimodal chat application. We can control our data closely and can decide how to use it.
The second reason is primarily because of use cases. We can use a multimodal chat application using Phi-3 for understanding images, and videos, and have multi-turn conversations to gain deeper insights.
For example, you upload a page from a presentation in the form of an image to the application. You get some initial insights into what that particular slide is about. You can next feed that information to another Phi-3 Chat only model to elaborate the answer and gain an even deeper understanding.
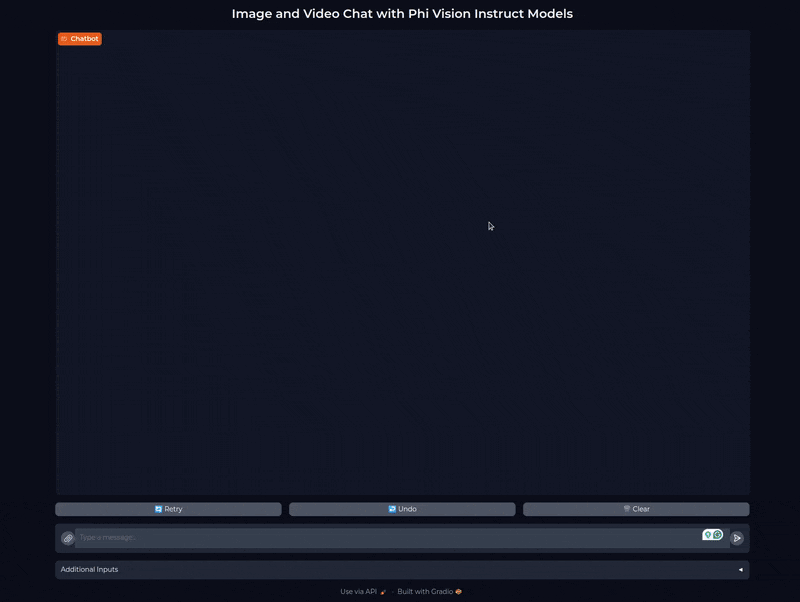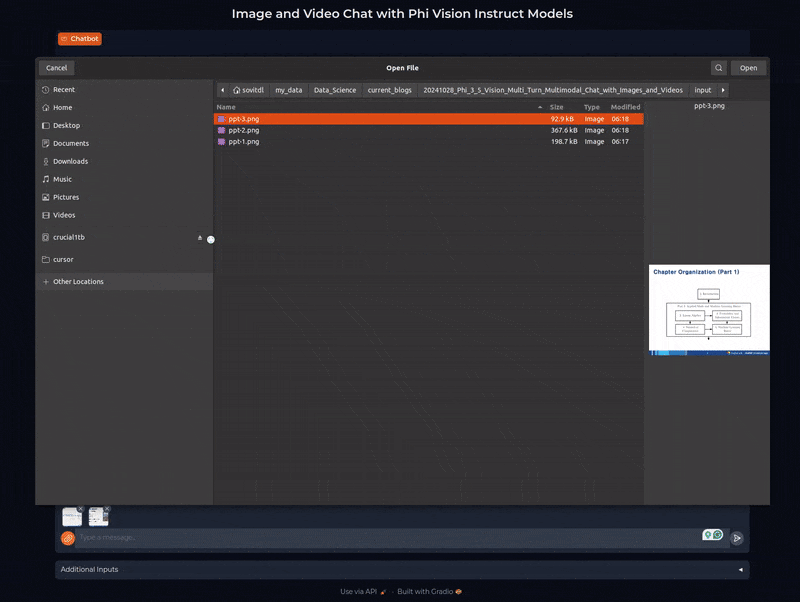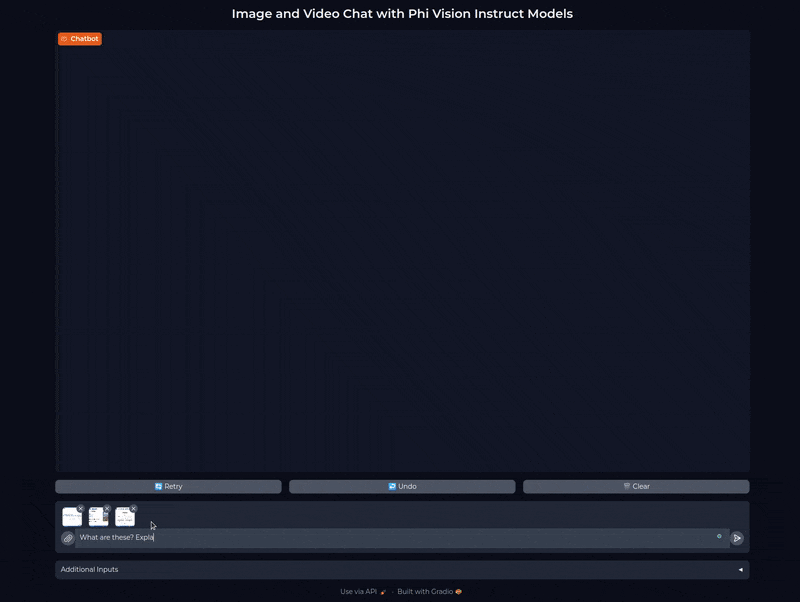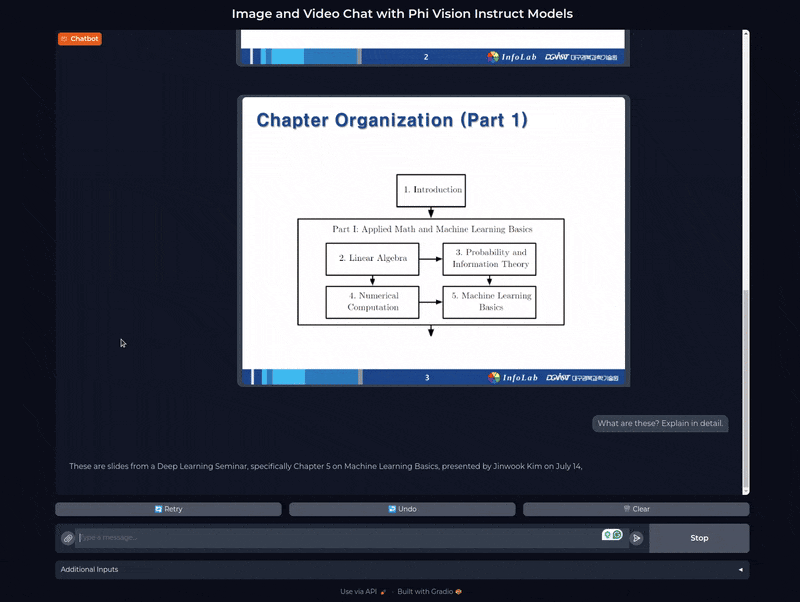
This is just a small example, we can use multimodal chat applications and models for various use cases as we traverse the world of NLP, LLMs, and frontier models.
Project Directory Structure
Let’s take a look at the project directory structure before moving forward.
├── input │ ├── car_racing.mp4 │ ├── image.png │ ├── llama-flow.png │ └── llama-report.png ├── phi3_vision.py └── requirements.txt
- The
inputdirectory contains the images and videos that we will use to chat with the Phi-3 Vision model. - We have a Python file containing all the code to build the Gradio application.
- The
requirements.txtfile contains all the necessary requirements for the applications.
The script, input files, and requirements files are downloadable via the download section.
Download Code
After downloading the code, you can install all the necessary requirements with the following command.
pip install -r requirements.txt
Building a Gradio Application for Multimodal Chat using Phi-3.5 Vision
For simplicity, all the code is contained within a single file. This is great for understanding how each component works. As you expand this project, moving different functions to utility modules will make more sense.
If you want to know how to build a text-chat application using Phi-3, read the Custom Phi-3 Gradio Chat with File Upload article.
Let’s start with the discussion of the code that is present in the phi3_vision.py script.
We will start with the import statements and define a few important components.
import gradio as gr
import threading
import argparse
import cv2
from transformers import (
AutoModelForCausalLM,
BitsAndBytesConfig,
TextIteratorStreamer,
AutoProcessor
)
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument(
'--share',
action='store_true'
)
args = parser.parse_args()
device="cuda"
# A list to maintain the paths of all images and videos.
GLOBAL_IMAGE_LIST = []
model_id = None
model = None
streamer = None
processor = None
- We import
AutoModelForCausalLMandAutoProcessorto load the Phi-3.5 Vision model and its processor. - The
TextIteratorStreamerandthreadingmodules are necessary for streaming text to the Gradio output box. - OpenCV and PIL Image are required to read video frames and images.
- Finally, we will load the model in 4-bit quantized format to save GPU memory. For this, we need
BitsAndBytesConfig.
We have one command line argument to indicate whether we want a public URL for the Gradio application or not.
Then we mention the computation device which is CUDA and initialize a few variables with None. As we move forward, it will become clearer why we have done so.
Also, we have a GLOBAL_IMAGE_LIST list to store all the image and video paths that are being uploaded. This is crucial to maintain the history and load the images and videos during the chat.
Loading the Phi-3.5 Vision Model, Processor, and Streamer
Next, we need to load the Phi-3.5 model, its corresponding processor, and the text iterator streamer as well.
def load_llm(chat_model_id):
global model
global streamer
global processor
gr.Info(f"Loading model: {chat_model_id}")
quant_config = BitsAndBytesConfig(
load_in_4bit=True
)
processor = AutoProcessor.from_pretrained(
chat_model_id,
trust_remote_code=True,
num_crops=4
)
model = AutoModelForCausalLM.from_pretrained(
chat_model_id,
quantization_config=quant_config,
device_map=device,
trust_remote_code=True,
_attn_implementation='eager'
)
streamer = TextIteratorStreamer(
processor.tokenizer, skip_prompt=True, skip_special_tokens=True
)
In the application, we will give the option to choose either Phi-3 Vision or Phi-3.5 Vision. That’s why we maintain global variables for them. When the user chooses a different model, the changes need to happen application-wide.
Also, whenever a different model is chosen, we provide a Gradio Information pop-up so that the user also knows what is happening in the background.
Helper Functions to Load Images and Videos
We need two helper functions to load images and video frames. The following code block shows that.
def load_and_preprocess_images(image_path):
image = Image.open(image_path)
return image
def load_and_process_videos(file_path, images, placeholder, counter):
cap = cv2.VideoCapture(file_path)
length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
for i in range(length):
counter += 1
cap.set(cv2.CAP_PROP_POS_FRAMES, i)
ret, frame = cap.read()
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
images.append(Image.fromarray(image))
placeholder += f"<|image_{counter}|>n"
return images, placeholder, counter
The Phi-3.5 Vision Processor expects the images in PIL format. That’s how we load the image in load_and_preprocess_images.
The load_and_process_videos is slightly more nuanced. We pass the video file path, an images list, a placeholder string variable, and a counter as arguments. We first extract the number of frames in the videos and store it in the length variable. Then we iterate that many times while setting the frame to capture each time. We read the frame, convert it to PIL Image, and append it to the images list. We also keep on updating the placeholder string in a chat template format incrementing the image_{number} as we iterate through the video. This placeholder is crucial to building the final chat template, as we will see later.
Function to Feed User Prompt and Generate Text
The most crucial part of this application is the generate_next_tokens function.
Let’s take a look at the code first.
def generate_next_tokens(user_input, history, chat_model_id):
global model_id
global GLOBAL_IMAGE_LIST
# If a new PDF file is uploaded, create embeddings, store in `temp.json`
# and load the embedding file.
images = []
placeholder=""
# Check if the user uploaded a new image/video with the current prompt.
if len(user_input['files']) != 0:
# Reset global file paths if new files are uploaded. Necessary
# to maintain proper recent context.
GLOBAL_IMAGE_LIST = []
counter = 0
for file_path in user_input['files']:
if file_path.endswith('.mp4'):
GLOBAL_IMAGE_LIST.append(file_path)
images, placeholder, counter = load_and_process_videos(
file_path, images, placeholder, counter
)
else:
counter += 1
GLOBAL_IMAGE_LIST.append(file_path)
image = load_and_preprocess_images(
file_path
)
images.append(image)
placeholder += f"<|image_{counter}|>n"
# If no video is uploaded, then use the image/video paths from history
else:
counter = 0
for i, file_path in enumerate(GLOBAL_IMAGE_LIST):
if file_path.endswith('.mp4'):
images, placeholder, counter = load_and_process_videos(
file_path, images, placeholder, counter
)
else:
counter += 1
image = load_and_preprocess_images(
file_path
)
images.append(image)
placeholder += f"<|image_{counter}|>n"
if chat_model_id == 'microsoft/Phi-3.5-vision-instruct' and len(images) == 0:
gr.Warning(
'Please upload an image to use the Vision model. '
'Or select one of the text models from the advanced '
'dropdown to chat with PDFs and other text files.',
duration=20
)
if chat_model_id != model_id:
load_llm(chat_model_id)
model_id = chat_model_id
# print(f"User Input: ", user_input)
# print('History: ', history)
print('*' * 50)
final_input=""
user_text = user_input['text']
if len(images) != 0:
chat = [
{'role': 'user', 'content': placeholder+user_text},
]
template = processor.tokenizer.apply_chat_template(
chat,
tokenize=False,
add_generation_prompt=True
)
print(template)
# Loading from Gradio's `history` list. If a file was uploaded in the
# previous turn, only the file path remains in the history and not the
# content. Good for saving memory (context) but bad for detailed querying.
if len(history) == 0 or len(images) != 0:
prompt="<s>" + template
else:
prompt="<s>"
for history_list in history:
prompt += f"<|user|>n{history_list[0]}<|end|>n<|assistant|>n{history_list[1]}<|end|>n"
prompt += f"<|user|>n{final_input}<|end|>n<|assistant|>n"
print('Prompt: ', prompt)
print('*' * 50)
inputs = processor(prompt, images, return_tensors="pt").to(device)
print('-' * 100)
generate_kwargs = dict(
**inputs,
eos_token_id=processor.tokenizer.eos_token_id,
streamer=streamer,
max_new_tokens=1024,
)
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output="".join(outputs)
yield final_output
It does the following tasks:
- Accepts the current user query along with an uploaded image or video file. If a new file has been uploaded, then determine its type, load the images/frames, and append them to the
imageslist (lines 83 to 101). - If no images or video files have been uploaded, then use the paths from the
GLOBAL_IMAGE_LIST. It reads these images and videos to manage context history and continue the chat (lines 104 to 117). - Here, we can see how the
placeholdervariable is being used. It is a continuous string in a certain template that Phi-3.5 and Phi-3 Vision models accept and it contains the"<|image_{counter}|>n"text as many times as number of images or frames in the current chat context. - We give the user the option to choose between Phi-3.5 Vision and Phi-3 Vision models. So, whenever the model ID changes from the dropdown a new model and its processor are loaded (lines 127 to 129).
- Lines 153 to 159 create the chat template in case it is not the first prompt and chat history is present.
- Starting from line 164, we preprocess the input chat template, define the keyword arguments, create the thread for forward pass, and yield the output tokens to the output box as they are generated.
Creating the Chat UI
The final code block contains the code to build the UI and launch the application.
def main():
iface = gr.ChatInterface(
fn=generate_next_tokens,
multimodal=True,
title="Image, PDF, and Text Chat with Phi Models",
additional_inputs=[
gr.Dropdown(
choices=[
'microsoft/Phi-3-vision-128k-instruct',
'microsoft/Phi-3.5-vision-instruct'
],
label="Select Model",
value="microsoft/Phi-3.5-vision-instruct"
)
],
theme=gr.themes.Soft(primary_hue="orange", secondary_hue="gray")
)
iface.launch(share=args.share)
if __name__ == '__main__':
main()
We use Gradio’s ChatInterface template which provides a pre-built interface for LLM and chat applications. It makes the process of storing user prompts and the chat history easier for us. We just need to manage the history by extracting the text from the list. We also provide the user a dropdown to choose from the two Phi Vision Instruct Models.
Launching the Phi-3.5 Vision Multimodal Chat
To launch the application, we can execute the phi3_vision.py script in the terminal and open the localhost URL that is shown.
python phi3_vision.py
The default UI looks like the following.
Following is a video showing the chat application.
As we can see, our Phi-3.5 multimodal chat application works “mostly” well.
The following demo shows uploading a video to the chat UI.
To manage GPU memory, the video contains just 3 frames. However, we can see that the model answers the questions correctly about the racing event and the color of the car.
Takeaways and Improvements for Our Phi-3.5 Vision Multimodal Chat Application
- We can continuously chat with the current image without uploading it every time.
- However, the model faces difficulty in establishing connections between currently uploaded and previous images. This is because whenever we upload a new image or video file, we delete the previous image/frames from history. This is mostly to manage the GPU usage as more files in history means every chat will keep on adding new memory. If you have a GPU with 24GB VRAM, then you can easily keep on chatting without emptying the
GLOBAL_IMAGE_LISTevery time a new image/video file is uploaded. - Additionally, we can provide a Phi-3 text model chat component to have long-form conversations with the image information that we get.
Summary and Conclusion
We built a multimodal image and video chat application using the Phi-3.5 Vision model in this article. Starting from the setting up of the environment to the discussion of the code, we covered it all. After analyzing the results, we also discussed some potential drawbacks and improvements. Let us know in the comment section if you implement the above improvements. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol