
Migrating your data warehouse workloads is one of the most challenging yet essential tasks for any organization. Whether the motivation is the growth of your business and scalability requirements or reducing the high license and hardware cost of your existing legacy systems, migrating is not as simple as transferring files. At Databricks, our Professional Services team (PS), has worked with hundreds of customers and partners on migration projects and have a rich record of successful migrations. This blog post will explore best practices and lessons learned that any data professional should consider when scoping, designing, building, and executing a migration.
5 phases for a successful migration
At Databricks, we have developed a five-phase process for our migration projects based on our experience and expertise.
Before starting any migration project, we begin with the discovery phase. During this phase, we aim to understand the reasons behind the migration and the challenges of the existing legacy system. We also highlight the benefits of migrating workloads to the Databricks Data Intelligence Platform. The discovery phase involves collaborative Q&A sessions and architectural discussions with key stakeholders from the customer, Databricks. Additionally, we use an automated discovery profiler to gain insights into the legacy workloads and estimate the consumption costs of the Databricks Platform to calculate TCO reduction.
After completing the discovery phase, we move on to a more in-depth assessment. During this stage, we utilize automated analyzers to evaluate the complexity of the existing code and obtain a high-level estimate of the effort and cost required. This process provides valuable insights into the architecture of the current data platform and the applications it supports. It also helps us refine the scope of the migration, eliminate outdated tables, pipelines, and jobs, and begin considering the target architecture.
In the migration strategy and design phase, we will finalize the details of the target architecture and the detailed design for data migration, ETL, stored procedure code translation, and Report and BI modernization. At this stage, we will also map out the technology between the source and target assets. Once we have finalized the migration strategy, including the target architecture, migration patterns, toolings, and selected delivery partners, Databricks PS, along with the chosen SI partner, will prepare a migration Statement of Work (SOW) for the Pilot (Phase I) or multiple phases for the project. Databricks has several certified Migration Brickbuilder SI partners who provide automated tooling to ensure successful migrations. Additionally, Databricks Professional Services can provide Migration Assurance services along with an SI partner.
After the statement of work (SOW) is signed, Databricks Professional Services (PS) or the chosen Delivery Partner carries out a production pilot phase. In this phase, a clearly defined end-to-end use case is migrated to Databricks from the legacy platform. The data, code, and reports are modernized to Databricks using automated tools and code converter accelerators. Best practices are documented, and a Sprint retrospective captures all the lessons learned to identify areas for improvement. A Databricks onboarding guide is created to serve as the blueprint for the remaining phases, which are typically executed in parallel sprints using agile Scrum teams.
Finally, we progress to the full-fledged Migration execution phase. We repeat our pilot execution approach, integrating all the lessons learned. This helps in establishing a Databricks Center of Excellence (CoE) within the organization and scaling the teams by collaborating with customer teams, certified SI partners, and our Professional Services team to ensure migration expertise and success.
Lessons learned
Think Big, Start Small
It’s crucial during the strategy phase to fully understand your business’s data landscape. Equally important is to test a few specific end-to-end use cases during the production pilot phase. No matter how well you plan, some issues may only come up during implementation. It’s better to face them early to find solutions. A great way to choose a pilot use case is to start with the end goal – for example, pick a reporting dashboard that’s important for your business, figure out the data and processes needed to create it, and then try creating the same dashboard in your target platform as a test. This will give you a good idea of what the migration process will involve.
Automate the discovery phase
We begin by using questionnaires and interviewing the database administrators to understand the scope of the migration. Additionally, our automated platform profilers scan through the data dictionaries of databases and hadoop system metadata to provide us with actual data-driven numbers on CPU utilizations, % ETL vs % BI usage, usage patterns by various users, and service principals. This information is very useful in estimating the Databricks costs and the resulting TCO Savings. Code complexity analyzers are also valuable as they provide us with the number of DDLs, DMLs, Stored procedures, and other ETL jobs to be migrated, along with their complexity classification. This helps us determine the migration costs and timelines.
Leverage Automated Code Converters
Utilizing automated code conversion tools is essential to expedite migration and minimize expenses. These tools aid in converting legacy code, such as stored procedures or ETL, to Databricks SQL. This ensures that no business rules or functions implemented in the legacy code are overlooked due to the lack of documentation. Additionally, the conversion process typically saves developers over 80% of development time, enabling them to promptly review the converted code, make necessary adjustments, and focus on unit testing. It is crucial to ensure that the automated tooling can convert not only the database code but also the ETL code from legacy GUI-based platforms.
Beyond Code Conversion—Data Matters Too
Migrations often create a misleading impression of a clearly defined project. When we think about migration, we usually focus on converting code from the source engine to the target. However, it’s important not to overlook other details that are necessary to make the new platform usable.
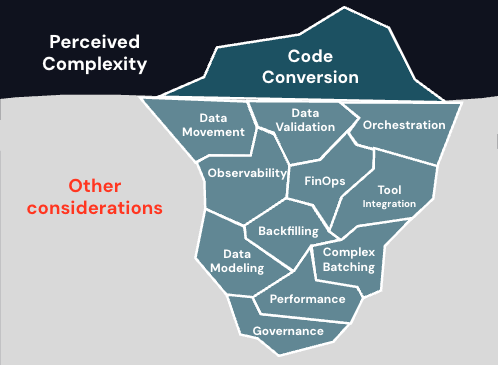
For example, it is crucial to finalize the approach for data migration, similar to code migration and conversion. Data migration can be effectively achieved by using Databricks LakeFlow Connect where applicable or by choosing one of our CDC Ingestion partner tools. Initially, during the development phase, it may be necessary to carry out historic and catch-up loads from the legacy EDW, while simultaneously building the data ingestion from the actual sources to Databricks. Furthermore, it is important to have a well-defined orchestration strategy using Databricks Workflows, Delta Live Tables, or similar tools. Additionally, your migrated data platform should align with your software development and CI/CD practices before the migration is considered complete.
Don’t ignore governance and security
Governance and security are other components that are often overlooked when designing and scoping a migration. Regardless of your existing governance practices, we recommend using the Unity Catalog at Databricks as your single source of truth for centralized access control, auditing, lineage, and data discovery capabilities. Migrating and enabling the Unity Catalog increases the effort required for the complete migration. Also, explore the unique capabilities that some of our Governance partners provide.
Data Validation and User Testing is essential for successful migration
It is crucial for the success of the project to have proper data validation and active participation from business Subject Matter Experts (SMEs) during User Acceptance Testing phase. The Databricks migration team and our certified System Integrators (SIs) use parallel testing and data reconciliation tools to ensure that the data meets all the data quality standards without any discrepancies. Strong alignment with executives ensures timely and focused participation of business SMEs during user-acceptance testing, facilitating a quick transition to production and agreement on decommissioning older systems and reports once the new system is in place.
Make It Real – operationalize and observe your migration
Implement good operational best practices, such as data quality frameworks, exception handling, reprocessing, and data pipeline observability controls, to capture and report process metrics. This will help identify and report any deviations or delays, allowing for immediate corrective actions. Databricks features like Lakehouse Monitoring and our system billing tables aid in observability and FinOps tracking.
Trust the experts
Migrations can be challenging. There will always be tradeoffs to balance and unexpected issues and delays to manage. You need proven partners and solutions for the people, process, and technology aspects of the migration. We recommend trusting the experts at Databricks Professional Services and our certified migration partners, who have extensive experience in delivering high-quality migration solutions in a timely manner. Reach out to get your migration assessment started.
Source link
lol