
Over the years, organizations have amassed a vast amount of unstructured text data—documents, reports, and emails—but extracting meaningful insights has remained a challenge. Large Language Models (LLMs) now offer a scalable way to analyze this data, with batch inference as the most efficient solution. However, many tools still focus on online inference, leaving a gap for better batch processing capabilities.
Today, we’re excited to announce a simpler, faster, and more scalable way to apply LLMs to large documents. No more exporting data as CSV files to unmanaged locations—now you can run batch inference directly within your workflows, with full governance through Unity Catalog. Simply write the query below and execute it in a notebook or workflow.
With this release, you can now run ai_query at scale with unmatched speed, ensuring fast processing of even the largest datasets. We’ve also expanded the interface to support all AI models, allowing you to securely apply LLMs, traditional AI models, or compound AI systems to analyze your data at scale.
SELECT ai_query('finetuned-llama-3.1-405b', "Can you evaluate this call transcript and write me a summary with action items of the main grievances: " || transcript_raw_text) AS summary_analysis FROM call_center_transcripts LIMIT 10;
Figure 1: A batch inference job of any scale – millions or billions of tokens – is defined using the same, familiar SQL interface
“With Databricks, we processed over 400 billion tokens by running a multi-modal batch pipeline for document metadata extraction and post-processing. Working directly where our dta resides with familiar tools, we ran the unified workflow without exporting data or managing massive GPU infrastructure, quickly bringing generative AI value directly to our data. We are excited to use batch inference for even more opportunities to add value for our customers at Scribd, Inc. “ – Steve Neola, Senior Director at Scribd
What are people doing with Batch LLM Inference?
Batch inference enables businesses to apply LLMs to large datasets all at once, rather than one at a time, as with real-time inference. Processing data in bulk provides cost efficiency, faster processing, and scalability. Some common ways businesses are using batch inference include:
- Information Extraction: Extract key insights or classify topics from large text corpora, supporting data-driven decisions from documents like reviews or support tickets.
- Data Transformation: Translate, summarize, or convert unstructured text into structured formats, improving data quality and preparation for downstream tasks.
- Bulk Content Generation: Automatically create text for product descriptions, marketing copy, or social media posts, enabling businesses to scale content production effortlessly.
Current Batch Inference Challenges
Existing batch inference approaches present several challenges, such as:
- Complex Data Handling: Existing solutions often require manual data export and upload, leading to higher operational costs and compliance risks.
- Fragmented Workflows: Most production batch workflows involve multiple steps, like preprocessing, multi-model inference, and post-processing. This often requires stitching together various tools, slowing execution and increasing the risk of errors.
- Performance and Cost Bottlenecks: Large-scale inference requires specialized infrastructure and teams for configuration and optimization, limiting analysts’ and data scientists’ ability to self-serve and scale insights.
Batch LLM Inference on Mosaic AI Model Serving
“With Databricks, we could automate tedious manual tasks by using LLMs to process one million+ files daily for extracting transaction and entity data from property records. We exceeded our accuracy goals by fine-tuning Meta Llama3 8b and, using Mosaic AI Model Serving, we scaled this operation massively without the need to manage a large and expensive GPU fleet.” – Prabhu Narsina, VP Data and AI, First American
Effortless AI on Governed Data
Mosaic AI allows you to perform batch LLM inference directly where your governed data resides withno data movement or preparation needed. Applying batch LLM inference is as simple as creating an endpoint with any AI model and running an SQL query (as shown in the figure). You can deploy any AI models—base, fine-tuned, or traditional—and execute SQL functions from any development environment on Databricks, whether interactively in the SQL editor or notebook or scheduled through Workflows and Delta Live Tables (DLT).
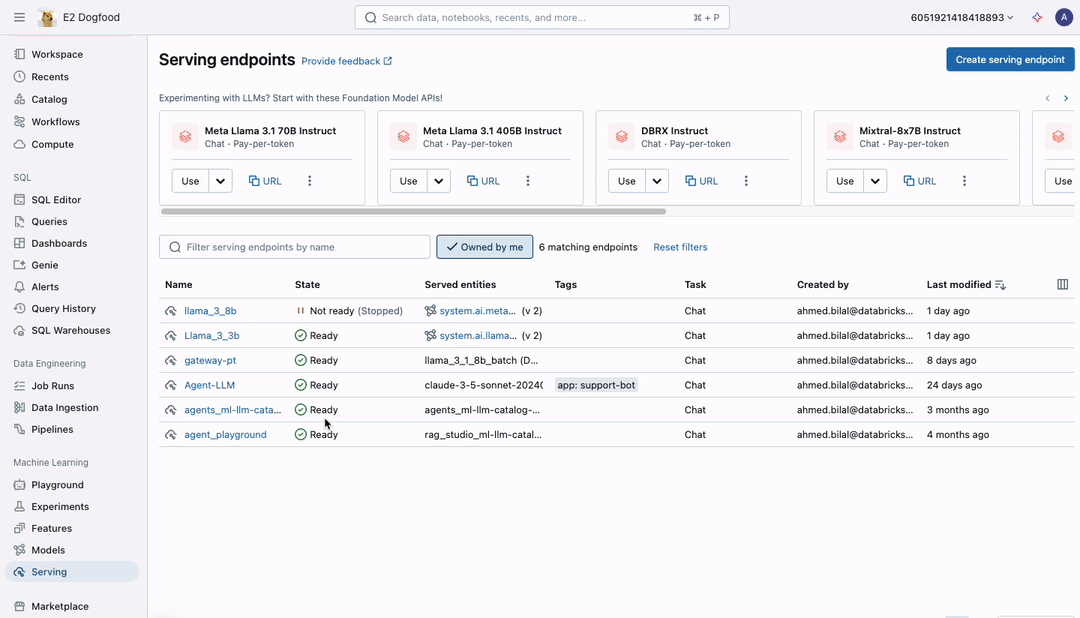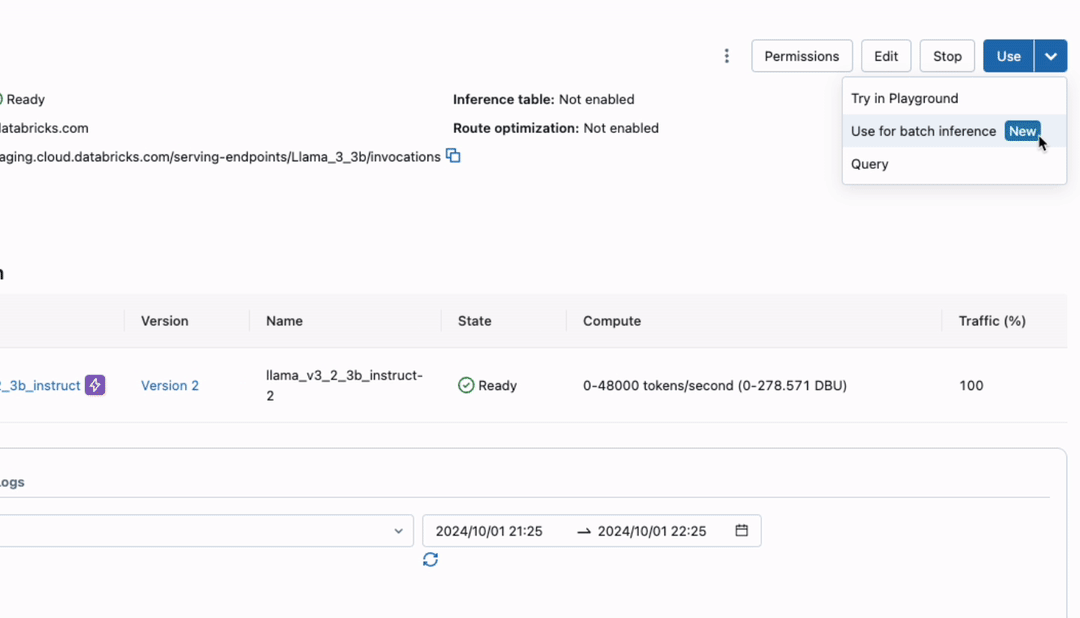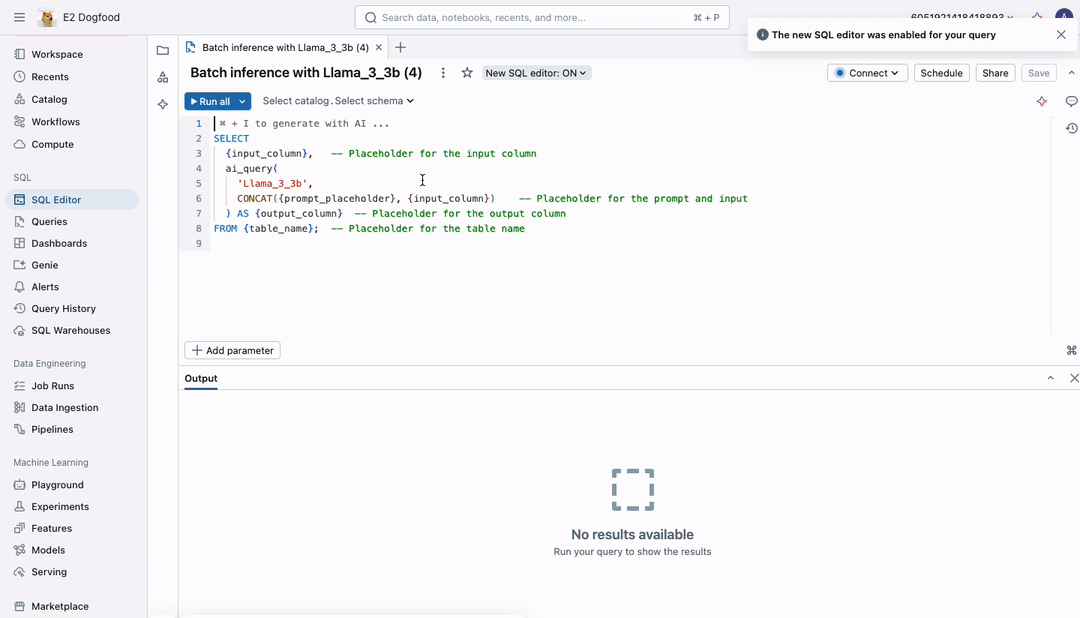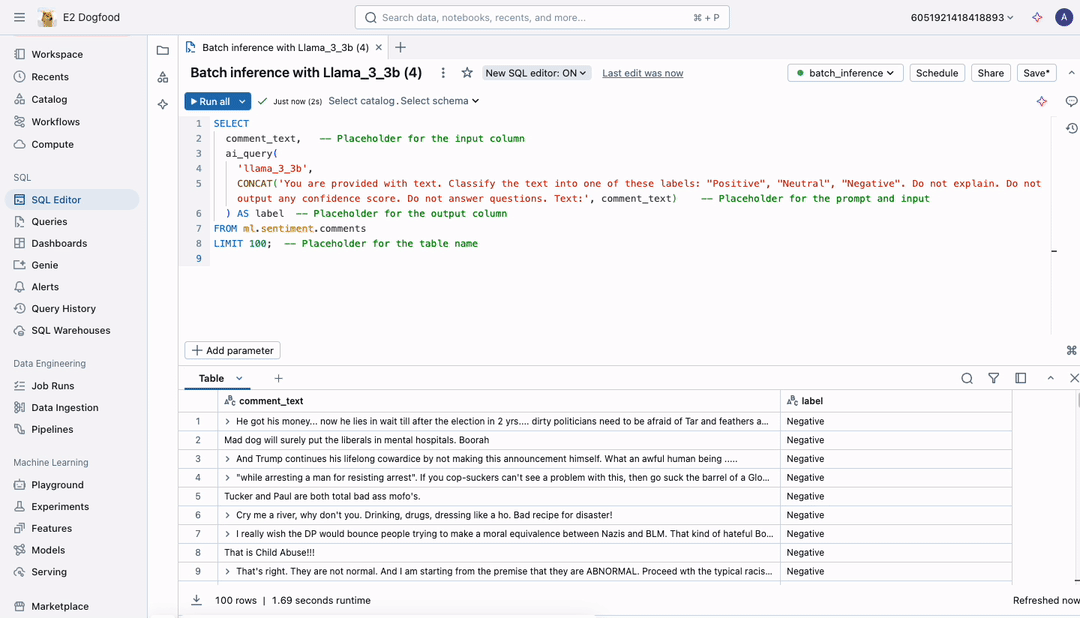
End-to-End Batch Workflows Simplified
Real-world use cases require preprocessing and post-processing, with LLM inference often just one part of a broader workflow. Instead of piecing together multiple tools and APIs, Databricks enables you to execute the entire workflow on a single platform, reducing complexity and saving valuable time. Below is an example of how to run an end-to-end workflow with the new solution.
— Step 1: Preprocessing WITH cleaned_data AS ( SELECT LOWER(regexp_replace(transcript_raw_text, '[^a-zA-Z\s]', '')) AS transcript_text, call_id, call_timestamp FROM call_center_transcripts ), -- Step 2: LLM Inference inference_result AS ( SELECT call_id, call_timestamp, ai_query('databricks-meta-llama-3-1-70b-instruct', transcript_text) AS summary_analysis FROM cleaned_data ), -- Step 3: Post-processing final_result AS ( SELECT call_id, call_timestamp, summary_analysis, CASE WHEN summary_analysis LIKE '%angry%' THEN 'High Risk' WHEN summary_analysis LIKE '%upset%' THEN 'Medium Risk' ELSE 'Low Risk' END AS risk_level, CASE WHEN summary_analysis LIKE '%refund%' THEN 'Refund Request' WHEN summary_analysis LIKE '%complaint%' THEN 'Complaint' ELSE 'General Inquiry' END AS action_required FROM inference_result ) -- Retrieve Results SELECT call_id, call_timestamp, summary_analysis, risk_level, action_required FROM final_result WHERE risk_level IN ('High Risk', 'Medium Risk');
Run Fast Inference on Millions of Rows
This release introduces multiple infrastructure improvements, enabling you to process millions of rows quickly and cost-effectively. The infrastructure scales automatically, adjusting resources to handle even the largest workloads efficiently. Additionally, built-in fault tolerance with automatic retries allows you to run large workflows confidently, seamlessly handling any errors along the way.

Getting Started with Batch LLM Inference
- Explore our getting started guide for step-by-step instructions on batch LLM inference.
- Watch the demo.
- Discover other built-in SQL AI functions that allow you to apply AI directly to your data.
Source link
lol