I’ve been applying typical unit testing practices to machine learning code and it hasn’t been straightforward. In software, units are small, isolated pieces of logic that we can test independently and quickly. In machine learning, models are blobs of logic learned from data, and machine learning code is the logic to learn and use these derived blobs of logic. This difference makes it necessary to rethink how we unit test machine learning code.
How ML code differs from regular software
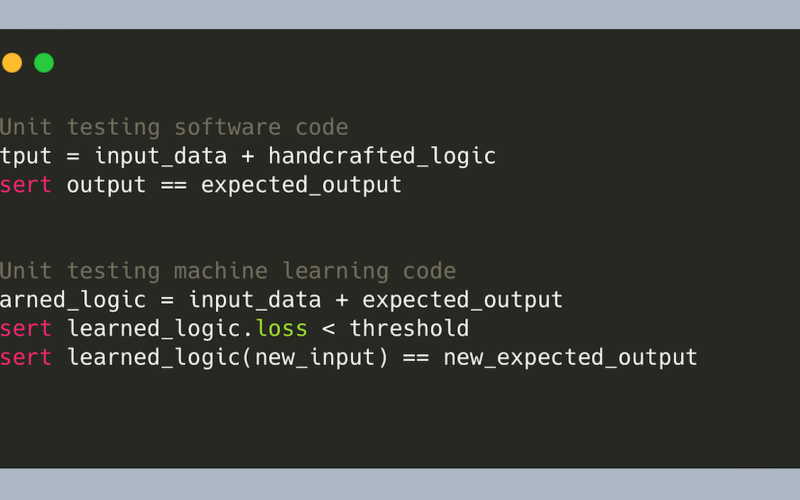
In software, we write code that contains logic; in ML, we write code that learns logic and then uses that learned logic. Software code transforms input data + handcrafted logic into expected output. We can then test these outputs against asserts. In contrast, machine learning code transforms input data + expected output into learned logic (i.e., a model).
[text{Software}: text{Input Data} + Handcrafted text{ Logic} = text{Expected Output}]
[text{Machine Learning}: text{Input Data} + text{Expected Output} = Learned text{ Logic}]
Thus, in machine learning, instead of writing code that contains logic, we write code to learn logic, such as via building a decision tree or finetuning a hallucination classifier. Because the logic that acts on the input data is embedded within the model, if we want to test the learned logic, we’ll need to load the model, perform inference on some sample output, and then assert if the output matches the expected input.
In software, we typically mock dependencies like APIs; in ML, we want to test the actual model (sometimes). When unit testing software, it’s good practice to mock database calls, filesystem access, sending emails/push notifications, etc. However, in ML, there are scenarios where we’ll want to test against the actual model.
For example, we want to test that loss decreases with each batch and the model can overfit (before wasting compute on an hopeless run.) If the model is a classifier, we want to check that the inference logic is correct. For instance, two models may have different output classes: Google’s T5 NLI model classifies factual consistency with class = 1 while Meta’s BART NLI model classifies it with class = 2!
Machine learning / language models can be large and unwieldy. Some neural networks can be in the billions of parameters, exceeding what a laptop or standard dev environment can load. And even if we have the memory for smaller models, they are slow to load and perform inference on, testing our patience as we unit test while coding.
Some guidelines for unit testing ML code & models
(These are a work in progress and my thinking’s still evolving—all feedback welcome!)
Use small, simple data samples. Avoid loading CSVs or Parquet files as sample data. (It’s fine for integration tests and evals but not unit tests.) Define sample data directly in unit test code—so that the test is self-contained—to test key functionality such as:
- Splitting into train/test tests when you have custom logic
- Custom implementations, such as Cosine or Euclidean distance in Java
- Preprocessing such as data augmentation or encoding
- Postprocessing such as diversification or filtering recommendations
- Error handling for empty or malformed input
When viable, test against random or empty weights. For example, we can initialize a model configuration with random weights to test output shape and device movement (from CPU to GPU and back). Here’s an example of how to initialize a model without having to download the weights and then assert the output shape:
from transformers import AutoConfig, AutoModelForSequenceClassification
model_name = "valhalla/distilbart-mnli-12-1"
config = AutoConfig.from_pretrained("valhalla/distilbart-mnli-12-1")
model = AutoModelForSequenceClassification.from_config(config)
assert model.classification_head.out_proj.out_features == 3
The accelerate library also has an example of initializing a model with empty weights:
def test_dispatch_model_bnb(self):
"""Tests that `dispatch_model` quantizes int8 layers"""
from huggingface_hub import hf_hub_download
from transformers import AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.utils.bitsandbytes import replace_with_bnb_linear
with init_empty_weights():
model = AutoModel.from_config(AutoConfig.from_pretrained("bigscience/bloom-560m"))
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = replace_with_bnb_linear(
model, modules_to_not_convert=["lm_head"], quantization_config=quantization_config
)
model_path = hf_hub_download("bigscience/bloom-560m", "pytorch_model.bin")
model = load_checkpoint_and_dispatch(
model,
checkpoint=model_path,
device_map="balanced",
)
assert model.h[0].self_attention.query_key_value.weight.dtype == torch.int8
assert model.h[0].self_attention.query_key_value.weight.device.index == 0
assert model.h[(-1)].self_attention.query_key_value.weight.dtype == torch.int8
assert model.h[(-1)].self_attention.query_key_value.weight.device.index == 1
Write critical tests against the actual model. If they take a while to run, mark them as slow and run only when needed (e.g., pre-commit and pre-merge). Some essentials include:
- Verify training is done correctly, such as loss going down, model overfitting, and training till convergence on a small sample of data
- Verify model outputs match expectation, such as 0.99 = unsafe instead of safe
- Verify model server can start, take batch input, and return the expected output
Don’t test external libraries. We can assume that external libraries work. Thus, no need to test data loaders, tokenizers, optimizers, etc.
• • •
What are your best practices for unit testing machine learning code and models? I would love to hear from you. Please reach out!
Further reading
The problem when mocks happen when all your unit test passes and the program fails on integration. The mocks are a pristine place where your library unit test works like a champ. Bad mocks or bad library? Or both. Developers are then sent to debug the unit test… overhead.
Probablistic tests create an impossible problem: if you tighten your assertions you struggle with meaningless failing tests and normalize ignoring test failures, while if you loosen your assertions your tests aren’t really asserting anything any more. And there isn’t a happy balance: if you go somewhere in the middle, you end up having both problems.
How does it matter whether I inline my test data inside the unit test code, or have my unit test code load that same data from a checked-in file instead?
It makes tests self-contained and easier to reason about. As a side-effect, random tests won’t accidentally break whenever you change some seemingly unrelated csv file.
As a rule of thumb, I also only assert on input/output values that are explicitly defined as part of the test body. Saves a ton of time chasing down fixture definitions.
I was expecting an article about side effects of hurting an LLM’s feelings in tests.
If you found this useful, please cite this write-up as:
Yan, Ziyou. (Feb 2024). Don’t Mock Machine Learning Models In Unit Tests. eugeneyan.com.
https://eugeneyan.com/writing/unit-testing-ml/.
or
@article{yan2024unit,
title = {Don't Mock Machine Learning Models In Unit Tests},
author = {Yan, Ziyou},
journal = {eugeneyan.com},
year = {2024},
month = {Feb},
url = {https://eugeneyan.com/writing/unit-testing-ml/}
}Share on:
Join 6,700+ readers getting updates on machine learning, RecSys, LLMs, and engineering.
Source link
lol