
Jupyter is a ubiquitous tool for data scientists and Python analysts. Its workflows for exploration, linear development, and sharing are intuitive and powerful. Further, packages like matplotlib, seaborn, ggplot and others turn their notebooks into visual tools.
No problem. You can now see ticking, updating, and other dynamic data in a widget in Jupyter. Crypto prices, system performance metrics, clickstream analytics, and IoT output in real time!
For example, below is a real-time table sourced from Twitter’s API, producing an updating count of particular words:
Free access to the Twitter API is no longer available. However, the code and concepts in this blog are still valid for users with a paid developer account.
Building ticking tables is very easy and requires just a few lines of code!
First of all, we need to install deephaven-server and deephaven-ipywidgets:
pip3 install deephaven-server deephaven-ipywidgets
Now we can launch the JupyterLab application and start the Deephaven server by running the following code in a cell:
from deephaven_server import Server
s = Server(port=8080)
s.start()
Then, we need to create a table to store our dynamic data. For this application, we’ll use DynamicTableWriter.
from deephaven import DynamicTableWriter
import deephaven.dtypes as dht
twitter_table_col_definitions = {"TWEET": dht.string, "TIMESTAMP": dht.DateTime, "KEYWORD1": dht.int32, "KEYWORD2": dht.int32, "KEYWORD3": dht.int32, "KEYWORD4": dht.int32, "KEYWORD5": dht.int32}
twitter_table_writer = DynamicTableWriter(twitter_table_col_definitions)
tweet_table = twitter_table_writer.table
Now, let’s pull some live data using Twitter streaming API and fill our table tweet_table with tweets:
Click to see the code!
import json
import requests
import threading
from deephaven.time import now, upper_bin
BEARER_TOKEN = <INSERT YOUR TOKEN>
TWITTER_ENDPOINT_URL = "https://api.twitter.com/2/tweets/search/stream"
KEYWORDS = {"news", "cats", "dogs", "covid", "monkeypox"}
NANOSEC_BIN = 5_000_000_000
def bearer_oauth(r):
"""
Method required by bearer token authentication.
"""
r.headers["Authorization"] = f"Bearer {BEARER_TOKEN}"
r.headers["User-Agent"] = "v2FilteredStreamPython"
return r
def set_rules():
"""
Method to add rules to the stream
"""
demo_rules = [{"value": word, "tag": word} for word in KEYWORDS]
payload = {"add": demo_rules}
response = requests.post(f"{TWITTER_ENDPOINT_URL}/rules", auth=bearer_oauth, json=payload)
if response.status_code != 201:
raise Exception(
"Cannot add rules (HTTP {}): {}".format(response.status_code, response.text)
)
def get_tweets():
"""
Method to get tweets
"""
response = requests.get(f"{TWITTER_ENDPOINT_URL}?tweet.fields=lang", auth=bearer_oauth, stream=True)
if response.status_code != 200:
raise Exception(
"Cannot get stream (HTTP {}): {}".format(
response.status_code, response.text
)
)
return response
set_rules()
def get_counts_by_keyword(tweet, keyword):
"""
The function to count the number of occurence of a keyword in a tweet
"""
count = tweet.count(keyword)
return count
def write_live_data():
"""
The function to write twitter data to a table
"""
response = get_tweets()
for response_line in response.iter_lines():
if response_line:
json_response = json.loads(response_line)
tweet = json_response["data"]["text"]
counts = []
for keyword in KEYWORDS:
count = get_counts_by_keyword(tweet, keyword)
counts.append(count)
time = now()
timestamp = upper_bin(time, NANOSEC_BIN)
twitter_table_writer.write_row(tweet, timestamp, *counts)
thread = threading.Thread(target=write_live_data)
thread.start()
Using the Deephaven table widget, you can easily view this live data right in your Jupyter notebook! All you need is just to pass the table name into a DeephavenWidget:
from deephaven_ipywidgets import DeephavenWidget
t = DeephavenWidget(tweet_table)
display(t)
Optionally, you can also pass in the width and height you’d like the widget to be:
display(DeephavenWidget(tweet_table, width=800, height=300))

Now let’s count the total number of keyword occurrences in tweets for five-second windows and apply color formatting to see the most popular keywords:
Click to see the code!
from deephaven import agg as agg
from deephaven import SortDirection
cols = []
heat_cols = []
for i, keyword in enumerate(KEYWORDS):
cols.append(f"{keyword.upper()} = KEYWORD{i+1}")
heat_cols.append(f"{keyword.upper()} = heatmap({keyword.upper()}, 0, 10, LEMONCHIFFON, GOLD)")
result = tweet_table.agg_by([agg.sum_(cols=cols)], by=["TIMESTAMP"])
result_heat = result.format_columns(heat_cols)
result_heat = result_heat.sort(order_by=["TIMESTAMP"], order=[SortDirection.DESCENDING])
display(DeephavenWidget(result_heat, width=800, height=300))
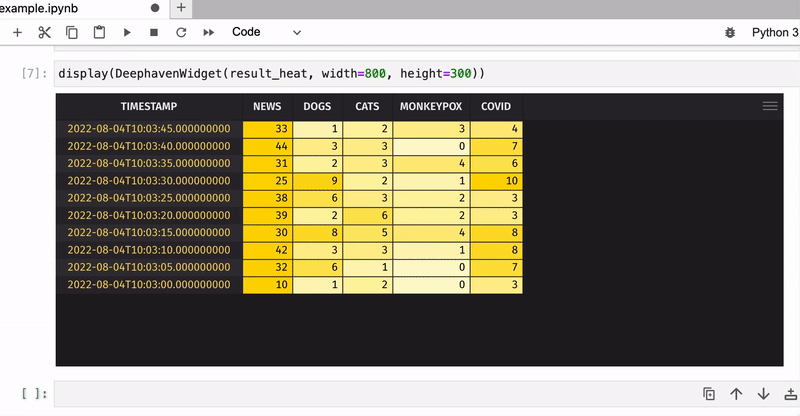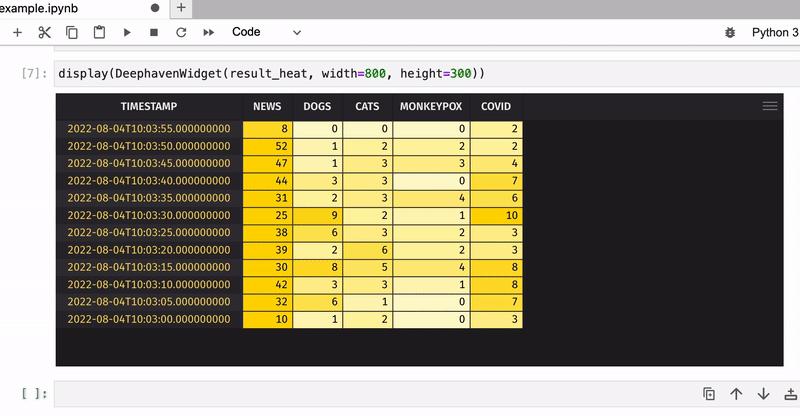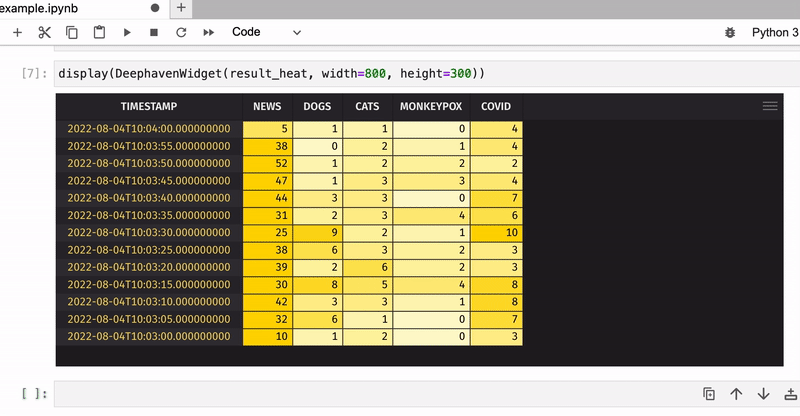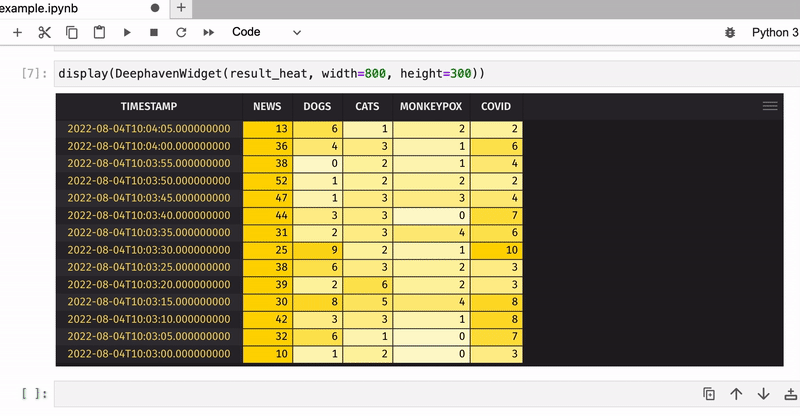
That was just an example of how to use Deephaven’s table widget in JupyterLab – what you will do with your real-time data is totally up to you!
Please contact us on Slack if you have any questions or feedback.
Source link
lol