
Large Language Models (LLMs) are excellent tools that can do anything from producing text that sounds human to comprehending actual language. But immense power comes with great responsibility. It is important to deploy LLMs safely and securely to protect sensitive data and prevent misuse.
When we talk of safety in the context of LLM deployment, we mean making sure the models function as intended and don’t produce any adverse or unexpected results. This includes making sure the models are applied responsibly and preventing biased, deceptive, or harmful content. On the other hand, security refers to protecting the models and the data they handle from malicious activities, breaches, and unauthorized access. Protecting the infrastructure, enforcing encryption, and limiting access to sensitive data are all part of securing an LLM model.
This article discusses the importance of these aspects in detail, including potential risks, challenges, good practices, case studies, and future trends in LLM deployment.
For several reasons, it is important to deploy LLMs safely and securely. Let’s identify those first.
- Preventing Misuse: Unsafeguarded LLMs may be used for inappropriate purposes, including creating false information or automating phishing attacks.
- Protecting Sensitive Data: LLMs frequently process and produce information from large volumes of data, sometimes including sensitive personal information. Thus, protecting this data from interception is vital for privacy and confidentiality.
- Users’ Confidence: Regulatory standards like GDPR or CCPA must be followed so as not to lose users’ trust or face legal consequences.
With the key reasons in mind, let’s now try to understand why current LLMs pose a challenge to safe and secure deployment.
The rapid development of advanced LLMs presents complex risks and challenges that differ significantly from traditional machine learning models, particularly regarding ethical issues and interpretability. Let’s consider these two aspects one by one.
Ethical Concerns
Conventional machine learning models, such as linear regressions and decision trees, often operate within well-defined domains. Although their outputs are usually derived from structured data with easily recognizable patterns, they can still present ethical challenges.
On the contrary, large and diverse datasets, such as unstructured text from the internet encompassing a wide range of human knowledge, language, and biases, are utilized for training LLMs like GPT-4 or BERT.
Because of this large training dataset, LLMs are exposed to a broader range of ethical issues, including:
- Misinformation: Although LLMs can produce writing that seems human, they can also provide information that is true or fabricated information through hallucination. This presents serious ethical issues, particularly when LLMs are applied to factually accurate applications like news production or medical advice.
- Privacy Concerns: LLMs trained on vast datasets may unintentionally remember and repeat sensitive information. Sophisticated privacy-preserving approaches are necessary to ensure that LLMs respect user privacy, introducing layers of complexity over traditional models.
Interpretability
Classical models, like decision trees or logistic regression, are often inherently interpretable. Their decision-making procedures are transparent and simple enough for anybody to understand. This transparency is important for applications like healthcare or finance, where knowing the reasoning behind a choice is critical.
However, deep learning architectures—particularly transformer models, which are infamously opaque—are the foundation of LLMs. With millions or even billions of parameters, these models make it difficult to understand how they produce particular results. There are many risks associated with LLMs’ lack of interpretability.
- Accountability: It is challenging to attribute accountability for the outcomes of LLMs due to their lack of clear interpretability. This is especially problematic for high-stakes applications where biased or inaccurate outputs can have negative consequences.
- Debugging and Improvement: LLMs are black-box systems; finding and fixing problems with them is more difficult. Grasping mistakes in LLMs necessitates a thorough inspection of their complex structures and training procedures, in contrast to conventional models where errors may be linked to particular characteristics or rules.
In order to ensure the efficient and safe use of LLMs, we need to carefully go through the many obstacles that come with their deployment.
Data security
Data security is the first and most important concern. Large datasets, many of which contain sensitive data, are used to train these models.
To avoid unwanted access and possible security breaches, it is important to safeguard this data throughout both the training and inference stages. We need to employ modern techniques such as data encryption, safe data storage, and strict access control procedures to protect this information.
- Data encryption: A process of transforming data into a coded format that is only accessible to those who hold the required decryption keys. This ensures that information, even if intercepted, is difficult for unauthorized parties to decipher.
- Safe data storage: Safe data storage safeguards against loss, corruption, and unwanted access to data by securing both the electronic and physical settings in which it is kept. If there is a probability of one storage device failing, you can think about using redundancy solutions like RAID (Redundant Array of Independent Disks) to make sure data is not lost.
- Strict Access Control Procedures: Access control procedures that involve managing who can view or use resources within a system, ensuring that only authorized users have access to sensitive data. Role-based access control is one of the methods that can be easily implemented to secure LLMs.
Model bias
Model bias is another major challenge. Biases from the training set of LLMs, especially in open-source models that you haven’t trained yourself, may be inherited, producing unfair or discriminatory outcomes. This is a major problem, particularly in highly regulated industries like banking and healthcare, where biased findings may have practical repercussions.
In order to address this, we need to take great care when selecting our datasets, putting bias detection methods in place, and using mitigation techniques to make sure the models provide results that are fair and equal. You can consider the guidelines below to address bias in Large Language Models (LLMs).
Always try to select better representative datasets – this ensures that data is balanced from the beginning.
Incorporate Bias Detection Methods:
- Pre-processing stage: consider data auditioning and label distribution analysis.
- Processing stage: consider techniques such as adversarial debiasing to avoid the LLM learning from biased associations.
- Post-processing stage: outcome testing and counterfactual fairness testing are some methods to detect whether there are any disparities in predictions.
Apply Bias Mitigation Techniques:
- Pre-processing stage: consider data re-sampling and re-weighting
- Processing stage: Use algorithmic methods such as fair representation learning and minimize sensitive information used in decision-making.
- Post-processing stage: validate the outcome through threshold adjustments and calibrations.
Furthermore, as per recent research findings (https://arxiv.org/html/2404.02650v1), you can use both bias detection and mitigation methods to reduce the model biases significantly.
Compliance
Compliance presents another challenge with laws such as the California Consumer Privacy Act (CCPA), Health Insurance Portability and Accountability Act (HIPAA), and the General Data Protection Regulation (GDPR).
For companies using LLMs in their products, whether you’re training models on your own data or using open-source solutions, ensuring compliance involves several vital actions:
- Data Governance: Implement strong data governance practices to manage how data is collected, stored, processed, and shared. This includes creating clear policies for data handling that align with relevant regulations ensuring that all data processing activities are transparent and documented.
- User Consent: Obtain explicit consent before collecting and processing their data. This is especially important under regulations like GDPR, which require that users be fully informed about how their data will be used and that they can opt-out or withdraw consent at any time.
- Transparency: Ensure transparency in data use, particularly in how LLMs process and generate outputs. Users should be informed about the involvement of LLMs in decision-making processes, especially in contexts where the outputs of the LLMs may impact them directly, such as in healthcare or financial services.
These standards mandate strict data processing and privacy procedures to safeguard user information. Strong data governance principles, obtaining required user consent, and transparency regarding data processing procedures are all essential to ensuring compliance. According to these guidelines, compliance is important for keeping users’ trust and avoiding legal issues.
Below is a summary of key challenges we discussed, together with key considerations and actions to address them when deploying an LLM.
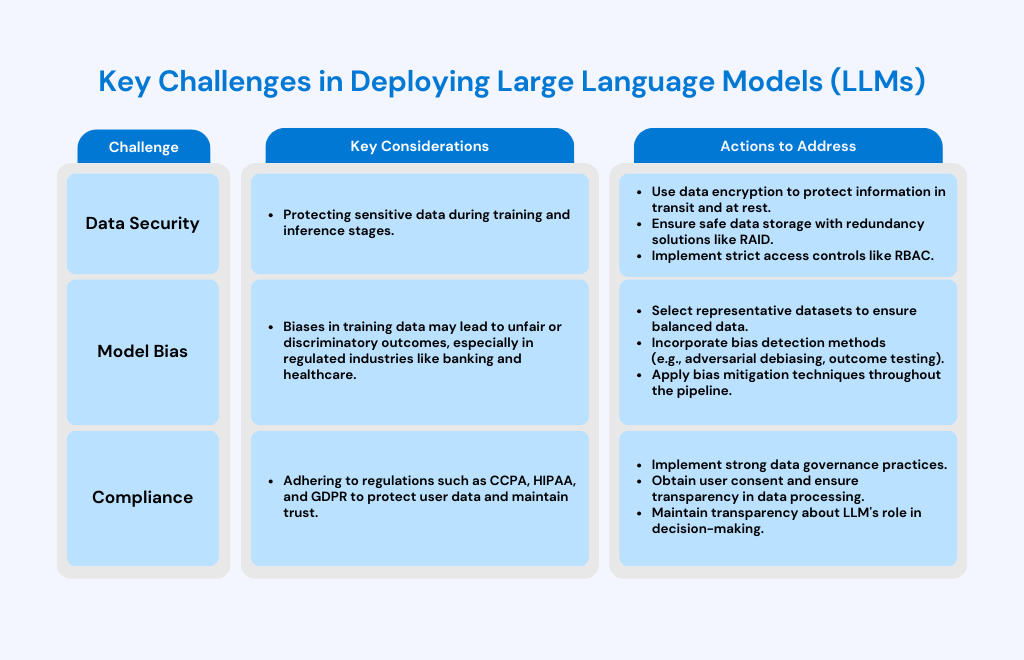
By addressing these challenges, we can maximize the benefits of LLMs while lowering the risks involved.
At this point, we have a general understanding of the significance of safe and secure LLM deployment as well as the difficulties involved, so let’s examine some best practices next.
- Anonymize data whenever possible to remove identifying information, reducing the risk of exposing sensitive details.
- Explore using differential privacy techniques to add noise to the outputs of your queries, which helps protect individual data points from being traced back to specific users.
- Regularly validate and test your models to ensure they are performing as expected and producing fair outcomes.
- Incorporate performance testing into your development cycle to verify that your model consistently meets the desired results.
- Don’t overlook security testing—identify potential vulnerabilities before they become issues.
- Set up continuous logging and monitoring to monitor any irregularities or security risks. This will allow you to respond quickly to issues and maintain compliance.
- Make monitoring a habit to ensure your deployment remains secure and stable over time.
- Implement role-based access control (RBAC) to ensure users only have access to the data and functions necessary for their roles.
- Add multi-factor authentication (MFA) to strengthen security further and protect against unauthorized access.
- Perform Regular Audits including routine audits and upgrades. This requires penetration testing, analyzing access records, and conducting security audits.
- Keep detailed audit trails to track all changes and access attempts, providing a clear record of activities within your system.
By adhering to these best practices, you can ensure the secure and efficient functioning of LLMs, safeguarding sensitive data and upholding user confidence.
Let’s look at two illustrative case studies that show secure LLM deployment in the financial and healthcare sectors.
Case Study 1: A Financial Institution
A major financial institution aimed to improve its customer experience by utilizing LLMs to handle customer inquiries and give tailored financial advice. However, because financial information is sensitive, strict security measures were necessary. Given the highly regulated nature of the financial industry, government regulations play a critical role in influencing the security provisions adopted by such institutions. Therefore, below are some of the security provisions adopted by the institution.
1. Data Encryption: The organization ensured the encryption of customer data at rest and both ways. This encryption, thus, is further protected from unauthorized access and potential breaches.
2. Access Control Based on Roles (RBAC): The LLM was made inaccessible by means of RBAC. Therefore, only those authorized to do so can interact with sensitive information. In addition to this, multi-factor authentication (MFA) enabled this additional layer of security.
3. Regular Audits and Assessments: In order to identify vulnerabilities and ensure compliance with financial regulations, frequent security audits were conducted. Some of the audits involved reviewing access logs as well as executing penetration tests.
4. Continuous Monitoring Strategies: Systems for monitoring in real-time were put in place to identify and address possible security concerns quickly. Security information and event management (SIEM) and intrusion detection systems (IDS) were primarily used to do this.
As a result of the above actions taken by the institution, responses to queries from customers were prompt and accurate. Moreover, the institution’s rigorous security measures protected customer data, improving their overall experience. In addition, it ensures customer data security, ultimately enhancing customer satisfaction.
Case Study 2: A Healthcare Provider
Assume a well-known healthcare provider who has integrated LLMs into their clinical operations with the goal of increasing diagnostic accuracy. Ensuring patient privacy and data security while supporting medical experts in the analysis and provision of precise diagnoses was the main focus. Therefore, they implemented the security measures below.
1. Differential Privacy Strategies: To make sure that specific patient data could not be identified, the healthcare provider used differential privacy approaches. By adding randomization to the input, their method preserved individual anonymity while enabling the model to learn from aggregated data.
2. Strict Access Controls: Role-based permissions and multifactor authentication were used to strictly manage access to patient data. The LLM and the sensitive patient data it processed were only accessible to approved medical practitioners and data scientists.
3. Continuous Monitoring and Compliance: Continuous monitoring systems were used to find anomalies or unapproved access. Regular compliance audits were carried out to guarantee compliance with healthcare laws like HIPAA.
The incorporation of LLMs led to faster and more precise diagnoses, which greatly improved patient outcomes. Thanks to the implementation of stringent access controls and differential privacy, patient data was kept secure and private. Ongoing monitoring and compliance audits made maintaining regulatory compliance and public confidence in the healthcare provider’s services possible.
Looking ahead, a number of trends and factors come into sharp relief, each with the capacity to fundamentally alter the landscape of LLM deployment.
Decentralized Data Learning via Federated Learning
Federated learning, a method that enables models to be trained across several decentralized devices or servers without the need to centralize data, is one of the most promising trends. By keeping data confined, this technique not only improves privacy but also lowers the danger of data breaches. Each device that takes part in federated learning trains the model using its local data; only the model updates—not the raw data—are shared with a central server.
By ensuring that sensitive data stays on local devices, this method preserves security and privacy while allowing for the benefits of collaborative learning.
Advanced Privacy Methods: Creating Synthetic Data
Cutting-edge privacy strategies, like creating synthetic data, are getting more and more important. Synthetically manufactured data that replicates the statistical characteristics of real data but excludes personal information is called synthetic data.
By using this method, organizations can address privacy concerns by training LLMs without disclosing sensitive information. When real data is difficult to collect or when regulatory considerations restrict data sharing, synthetic data can be especially helpful.
AI Governance Frameworks: Ethical Implementation
With the increasing popularity of LLMs, the significance of AI governance frameworks cannot be underscored. These frameworks provide guidelines for the ethical use of AI models including LLMs, ensuring their objectivity, responsibility, and transparency.
This will make sure LLMs used by organizations to comply with the legal requirements, minimizing biases, and guaranteeing model explainability while fostering confidence among stakeholders and users.
Transparency and Explainability in LLMs
Explainability and transparency are becoming more and more important in LLMs. Understanding how LLMs make decisions is important since they have an impact on numerous aspects of society.
Explainability provides the internal workings of LLMs comprehensible to humans, ensuring that users of LLMs understand and have faith in the outcomes.
On the other hand, transparency refers to disclosing publicly all data, techniques, and protocols utilized in the building of artificial intelligence models. Thus, explainability and transparency are essential for building confidence and ensuring that LLMs are used responsibly.
Interdisciplinary Collaboration: Addressing Multifaceted Challenges
In order to effectively address the complex difficulties posed by the deployment of LLMs, interdisciplinary collaboration is important.
Integrating knowledge from domains like artificial intelligence, cybersecurity, ethics, and law can result in comprehensive solutions that address the many problems related to LLM implementation.
For example, cooperation between ethicists and AI researchers can assist in detecting and reducing biases in models, and legal professionals’ participation can guarantee adherence to regulations. Using a comprehensive approach guarantees that every facet of LLM deployment is considered, resulting in more reliable and morally sound solutions.
This article discussed the importance of safe and secure deployment of state-of-the-art LLMs, key challenges, and best practices to overcome them.
I hope it helps you deploy LLMs ethically and ensure they are highly secured.
Source link
lol