This is a Plain English Papers summary of a research paper called Reconciling Conflicting Scaling Laws in Large Language Models. If you like these kinds of analysis, you should join AImodels.fyi or follow me on Twitter.
Overview
- This paper reconciles two influential scaling laws in machine learning: the Kaplan scaling law and the Chinchilla scaling law.
- The Kaplan scaling law suggests that model performance scales as a power law with respect to model size and compute.
- The Chinchilla scaling law suggests that model performance scales more efficiently by tuning the compute and dataset size together.
- The paper aims to resolve the apparent contradiction between these two scaling laws and provide a unified framework for understanding model scaling.
Plain English Explanation
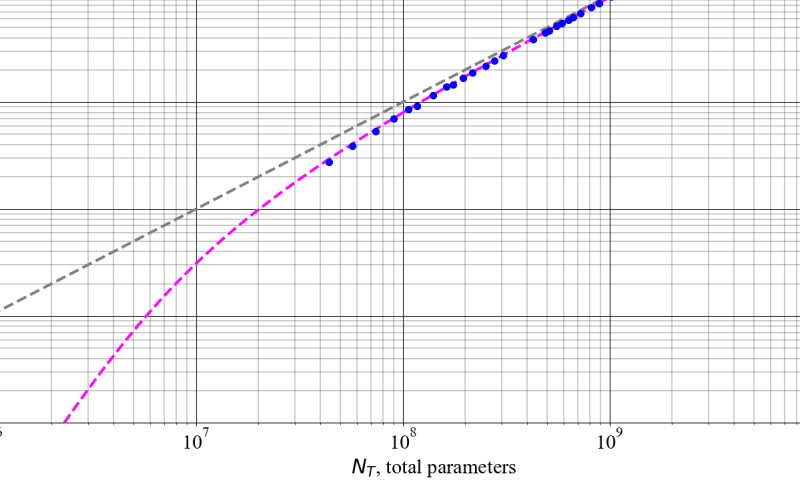
The paper explores how the performance of large machine learning models, like language models, improves as they get bigger and train on more data. There are two main theories, or “scaling laws,” that try to explain this relationship:
-
The Kaplan scaling law says that model performance scales as a power law – in other words, doubling the model size and compute leads to a predictable increase in performance.
-
The Chinchilla scaling law suggests that to get the most efficient scaling, you need to tune both the model size and the amount of training data together.
These two scaling laws seem to contradict each other. This paper tries to reconcile them and provide a unified way of understanding how large models scale. It does this through a careful analysis and some experiments that help explain the relationship between model size, compute, and dataset size.
Understanding scaling laws is important because it allows us to predict how much compute and data we’ll need to achieve certain performance targets as we build ever-larger machine learning models. This helps guide the development of future AI systems.
Technical Explanation
The paper first reviews the Kaplan scaling law and the Chinchilla scaling law. It then presents an analysis that shows how these two scaling laws can be reconciled.
The key insight is that the Kaplan scaling law describes a short-term or “transient” scaling regime, where performance scales as a power law with respect to model size and compute. But as training progresses and the model becomes more data-efficient, the scaling transitions to the Chinchilla regime, where tuning both model size and dataset size together leads to more efficient scaling.
The paper supports this analysis with experiments on language modeling tasks. It shows that early in training, performance follows the Kaplan scaling law, but later in training it transitions to the Chinchilla scaling regime. The authors also demonstrate that the transition point depends on factors like model architecture and task difficulty.
Overall, the paper provides a unifying framework for understanding scaling laws in machine learning. It suggests that different scaling regimes may apply at different stages of training, and that jointly optimizing model size and dataset size is key to achieving the most efficient scaling.
Critical Analysis
The paper provides a thoughtful analysis that helps resolve the apparent contradiction between the Kaplan and Chinchilla scaling laws. However, it’s important to note a few caveats and limitations:
-
The analysis and experiments are focused on language modeling tasks. It’s not clear how well the findings would generalize to other types of machine learning problems.
-
The paper doesn’t explore the underlying reasons why the scaling transitions from the Kaplan to the Chinchilla regime. Further research would be needed to fully explain the mechanisms driving this transition.
-
The paper doesn’t address potential issues with the Chinchilla scaling law, such as the challenges of obtaining massive datasets for training large models. Gzip has shown that data-dependent scaling laws can be difficult to generalize.
-
The paper could have provided a more in-depth discussion of the implications of this research for the development of future AI systems. How might it influence the way researchers and engineers approach model scaling and resource allocation?
Overall, the paper makes an important contribution to our understanding of scaling laws in machine learning. However, as with any research, there are still open questions and areas for further exploration.
Conclusion
This paper reconciles two influential scaling laws in machine learning – the Kaplan scaling law and the Chinchilla scaling law. It proposes a unifying framework that explains how different scaling regimes may apply at different stages of training.
The key insight is that early in training, performance follows the Kaplan scaling law, where it scales as a power law with respect to model size and compute. But as training progresses, the scaling transitions to the Chinchilla regime, where jointly optimizing model size and dataset size leads to more efficient scaling.
This research helps resolve the apparent contradiction between these two scaling laws and provides a more comprehensive understanding of how large machine learning models scale. It has important implications for the development of future AI systems, as it can help guide decisions about resource allocation and model architecture design.
While the paper focuses on language modeling tasks, the principles it establishes could potentially be applied to a wide range of machine learning problems. Further research would be needed to fully explore the generalizability of these findings and address some of the remaining open questions.
If you enjoyed this summary, consider joining AImodels.fyi or following me on Twitter for more AI and machine learning content.
Source link
lol