
Today, we are excited to announce the support for named parameter markers in the SQL editor. This feature allows you to write parameterized code in the SQL editor, that can then be copied and run directly in a dashboard or notebook without any syntax changes. This marks a significant milestone on our journey to unify parameters across queries, notebooks, and dashboards.
Using named parameter markers
Parameters enable you to substitute values into dataset queries at runtime, allowing you to filter data by criteria such as dates and product categories. This results in more efficient querying and precise analysis before data is aggregated in a SQL query.
Parameter markers are supported across queries, notebooks, dashboards, workflows, and the SQL Execution API. They are strongly typed and more resilient to SQL injection attacks by clearly separating provided values from the SQL statements. The named parameter marker syntax can be used by simply adding a colon (:) to the beginning of an alphabetic word, for example, :parameter_name or :`parameter with a space`.

To specify a keyword like a column or table name, use the identifier() clause as a wrapper. For example, identifier(:parameter_name).

We recommend updating existing parameters using the named parameter marker syntax. We will soon provide an assistant action to convert parameters automatically.

Common use cases
Here are several use cases that parameters are useful for:
Add a parameterized date range to a query to select records within a specific time frame.
SELECT * FROM samples.nyctaxi.trips where tpep_pickup_datetime BETWEEN :start_date AND :end_date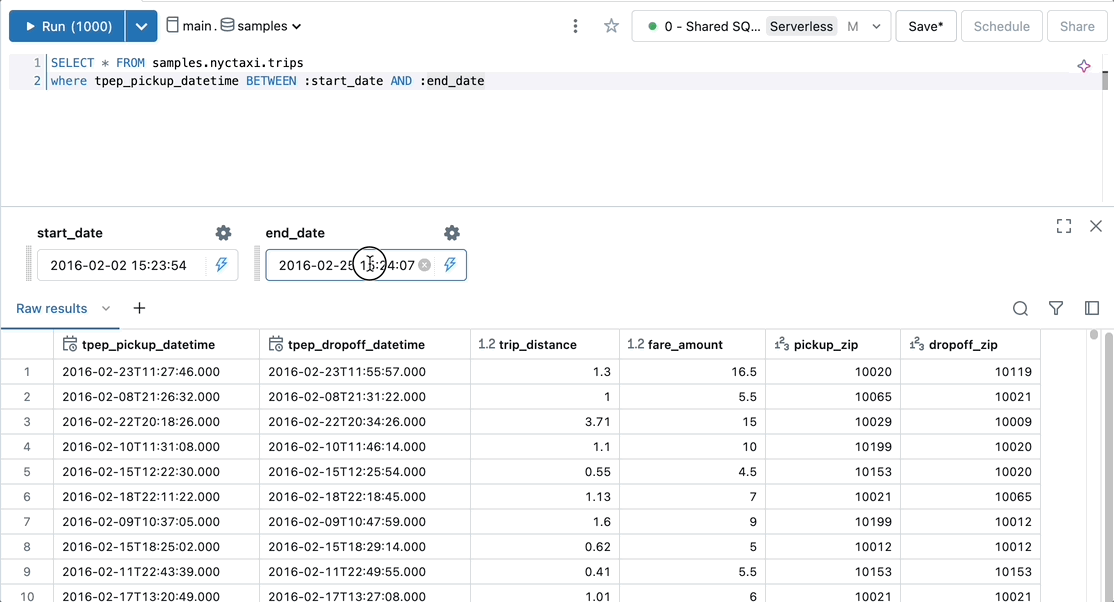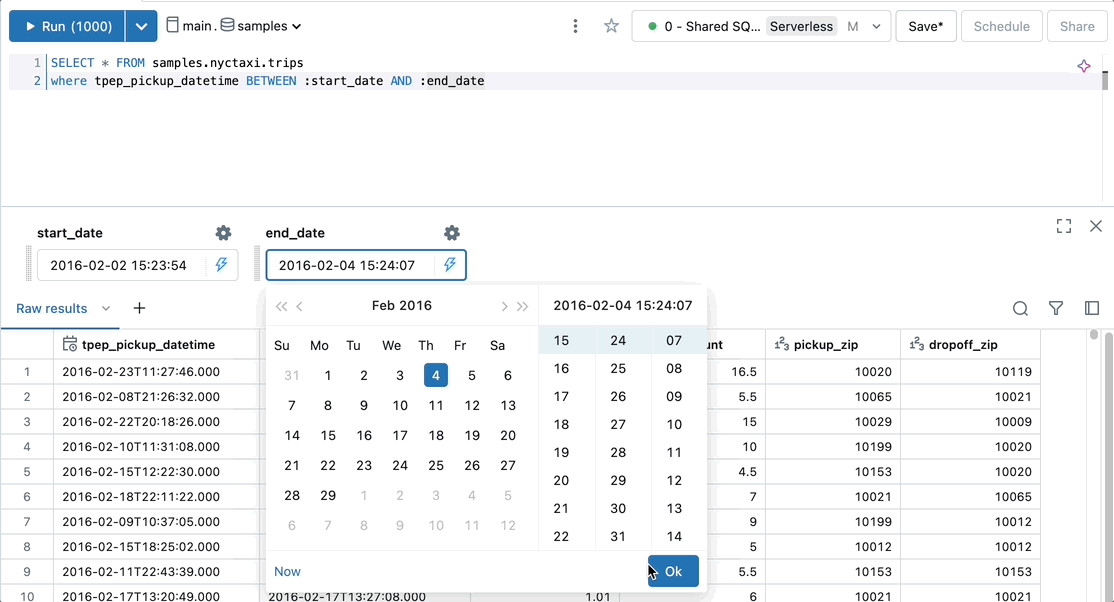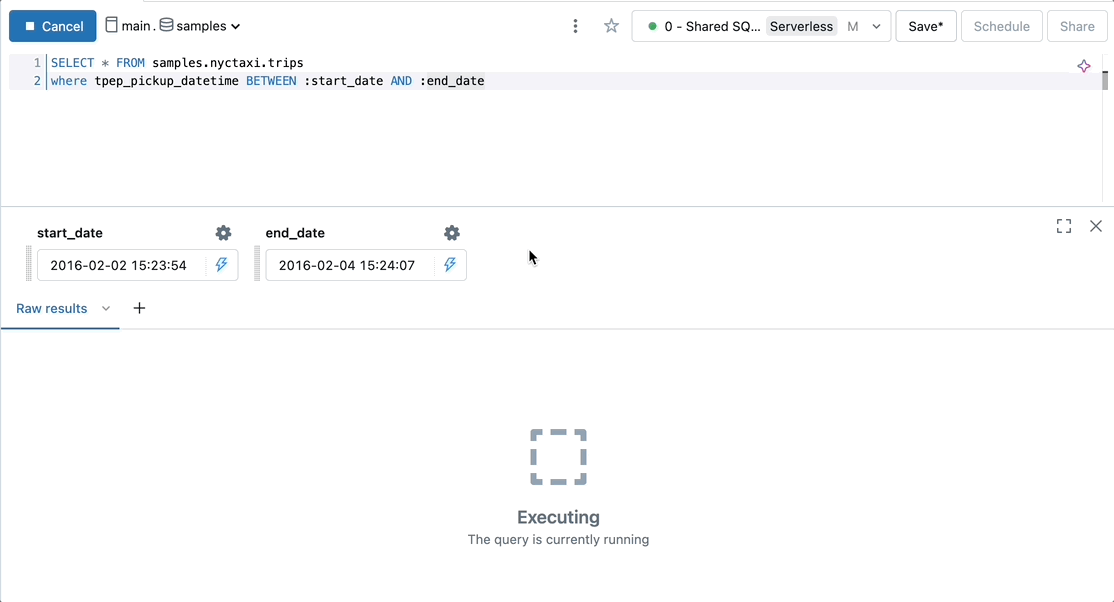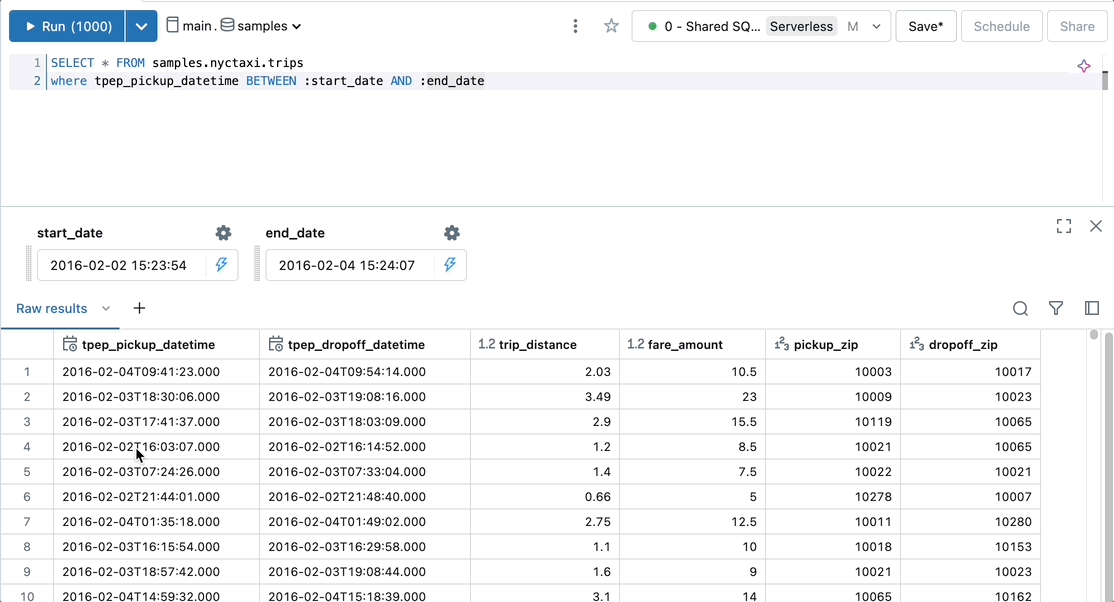
Dynamically select or create a catalog, schema, and table.
SELECT * FROM IDENTIFIER(:catalog || '.' || :schema || '.' || :table)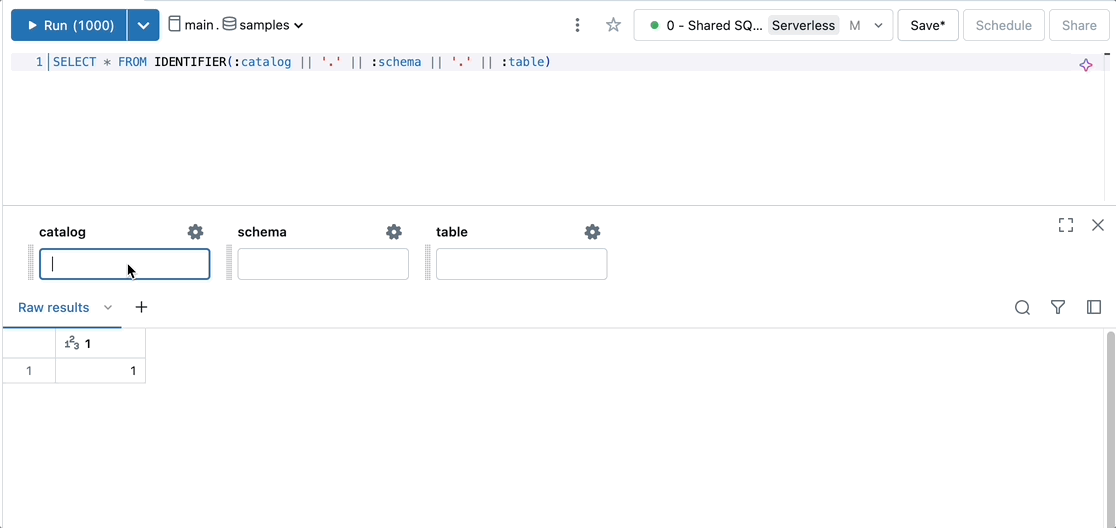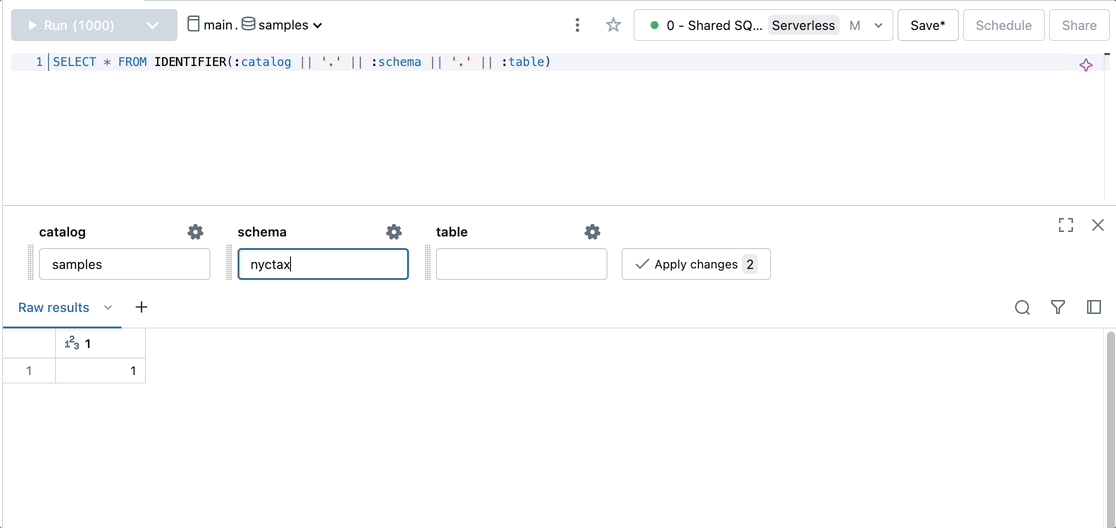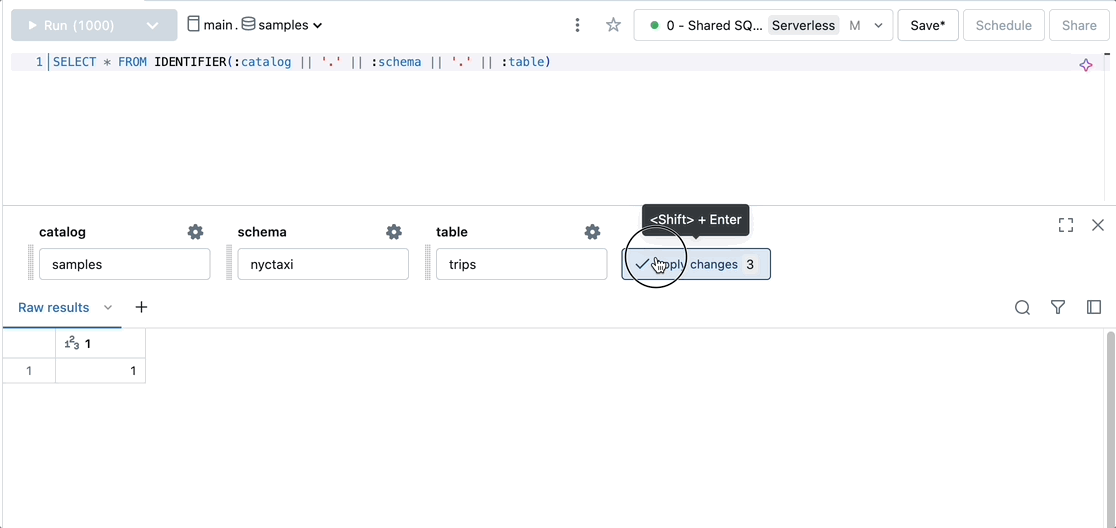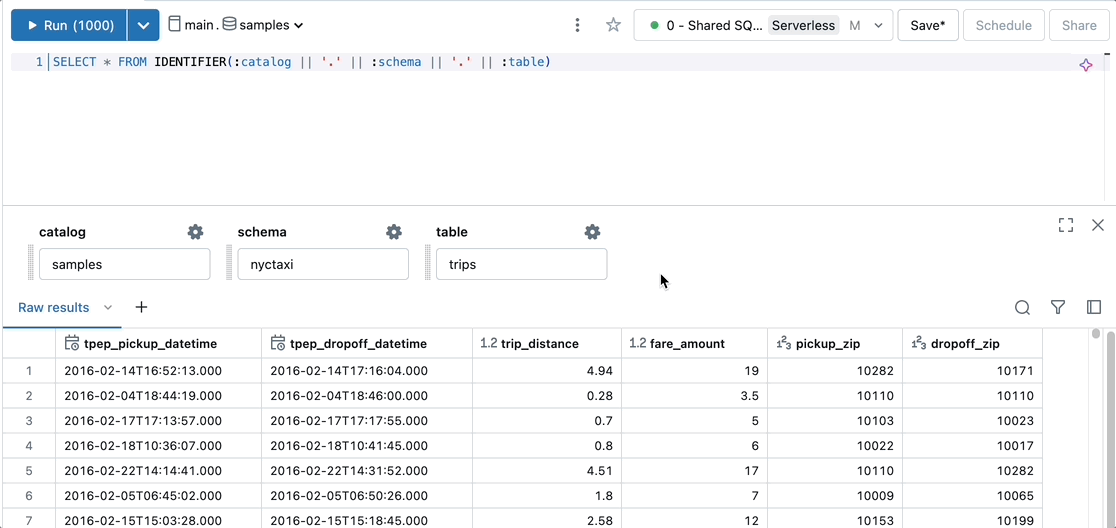
CREATE TABLE IDENTIFIER(:catalog || '.' || :schema || '.' || :table) AS SELECT 1;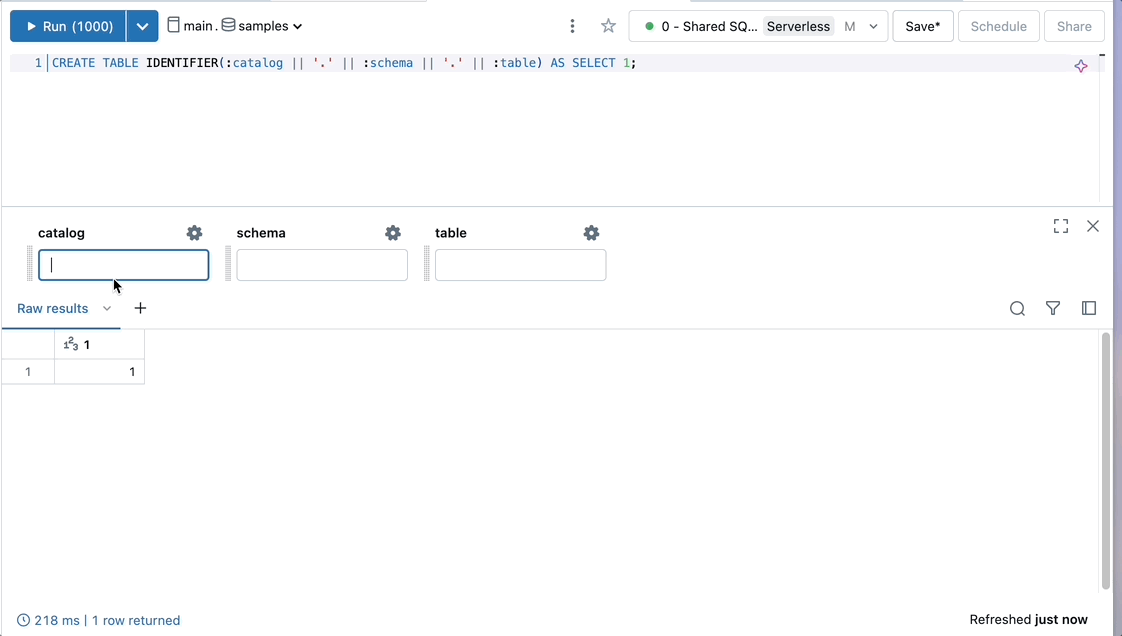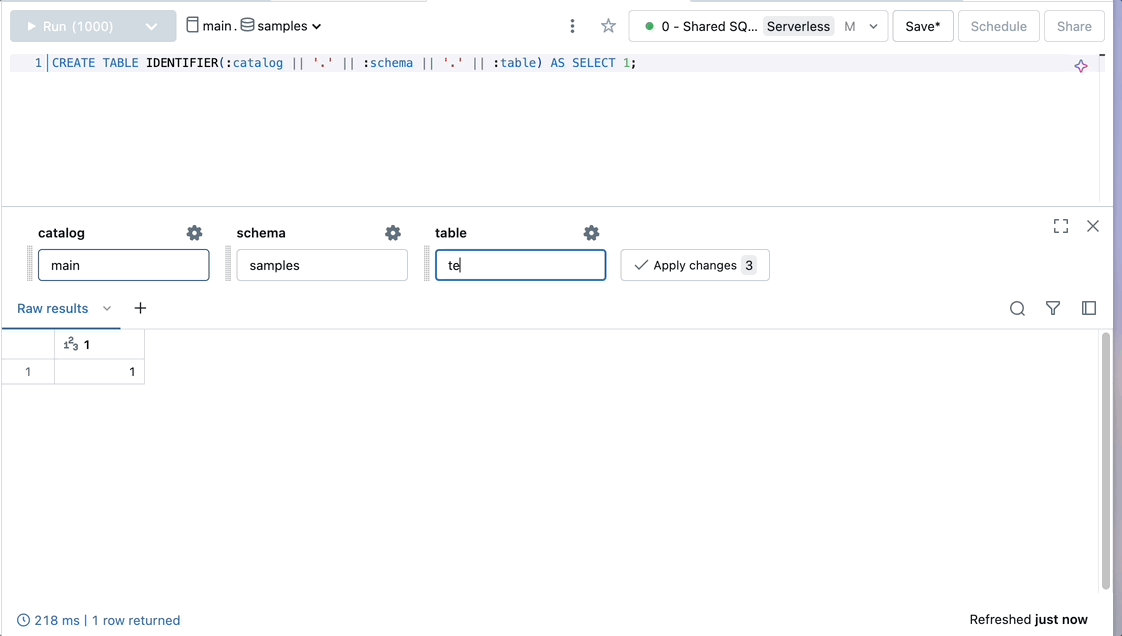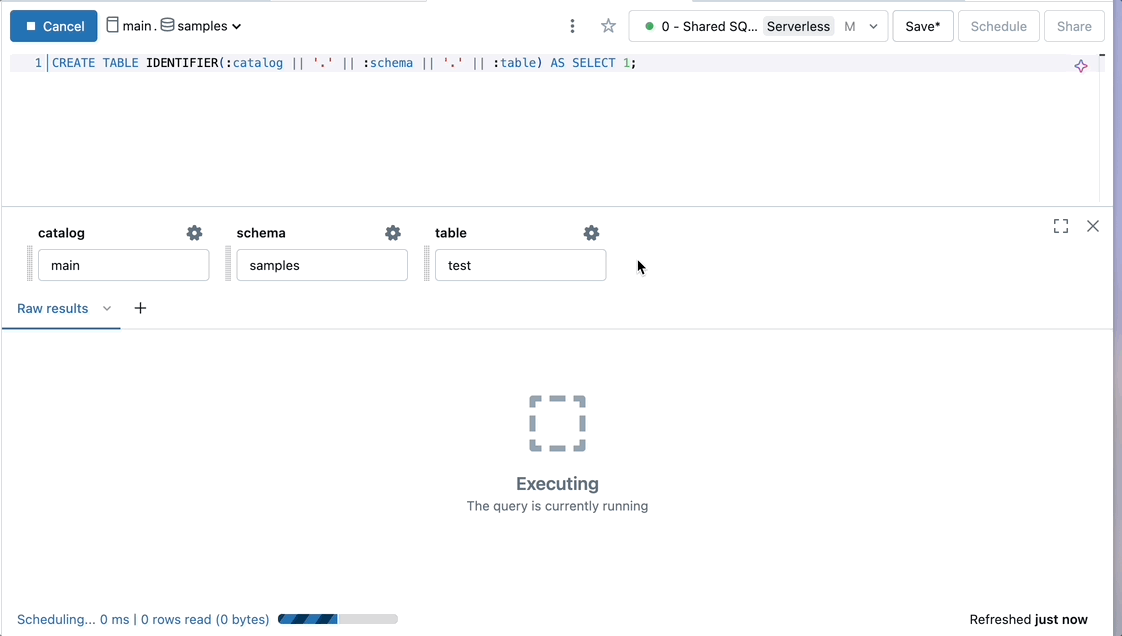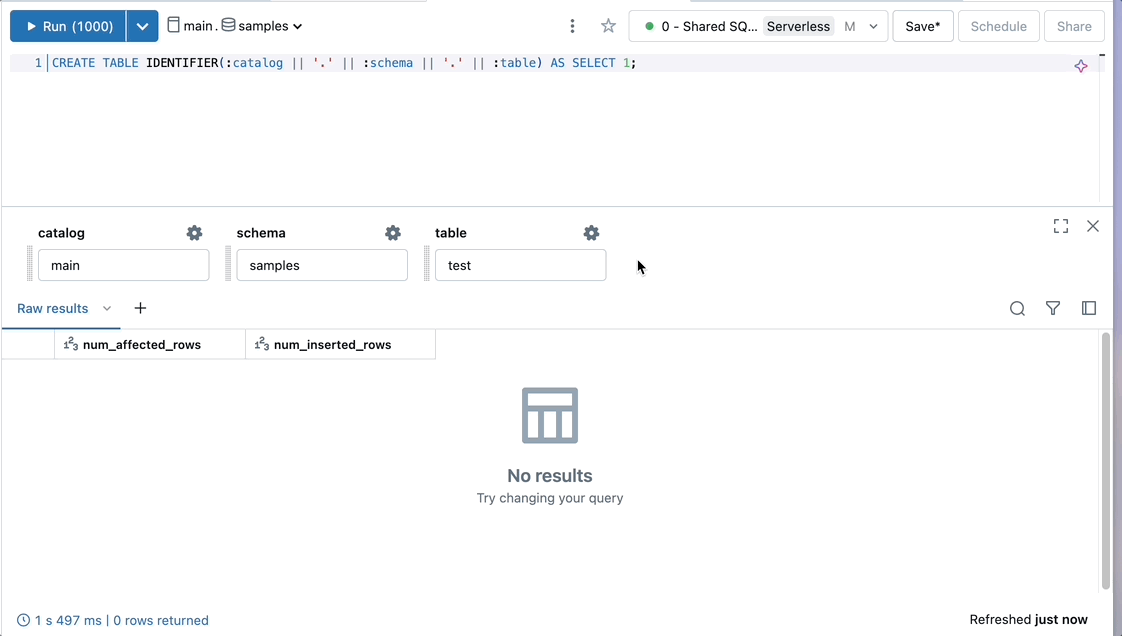
Define the query schema with a parameter.
USE SCHEMA IDENTIFIER(:selected_schema)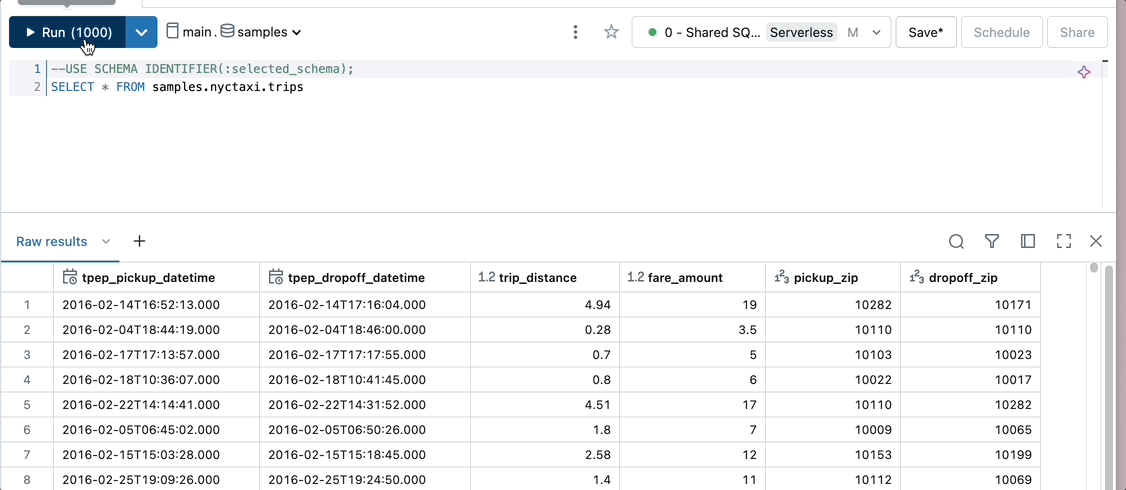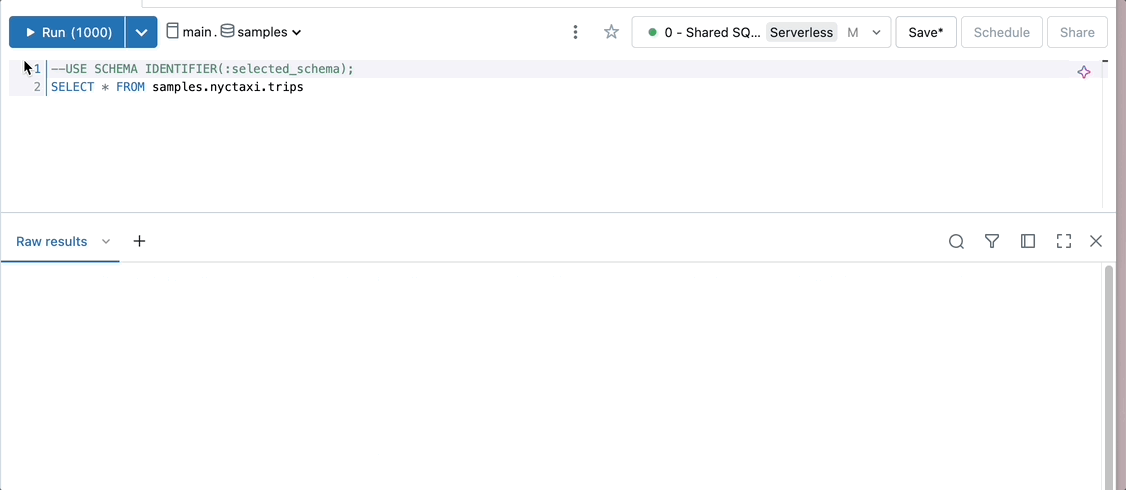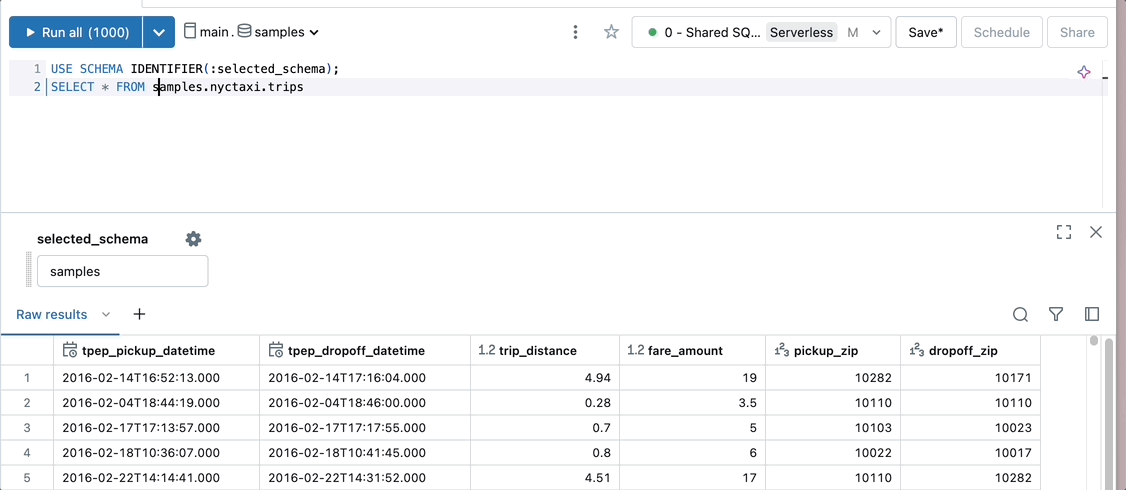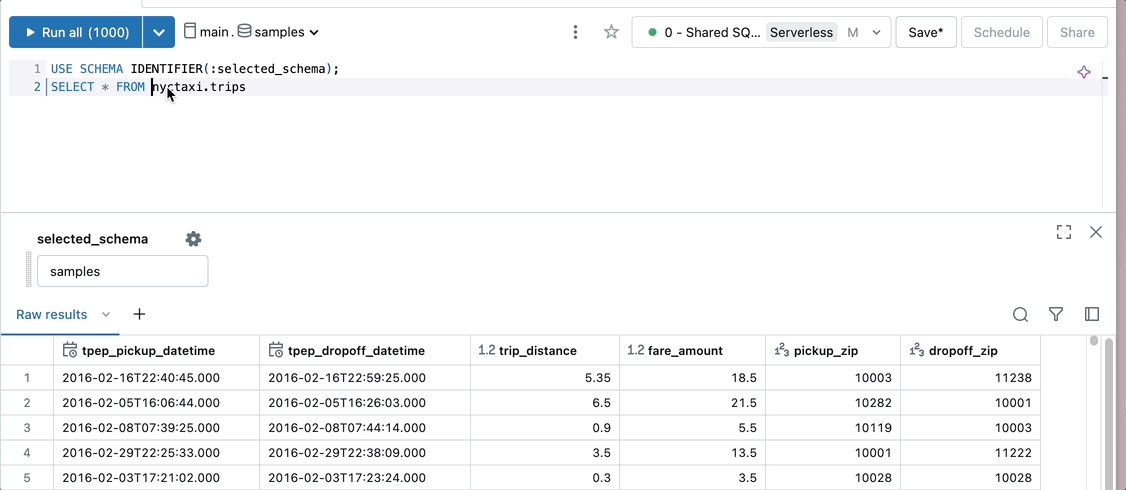
Parameterize templated strings to format outputs, such as phone number.
SELECT format_string("(%d) %d", :area_code, :phone_number) as phone_number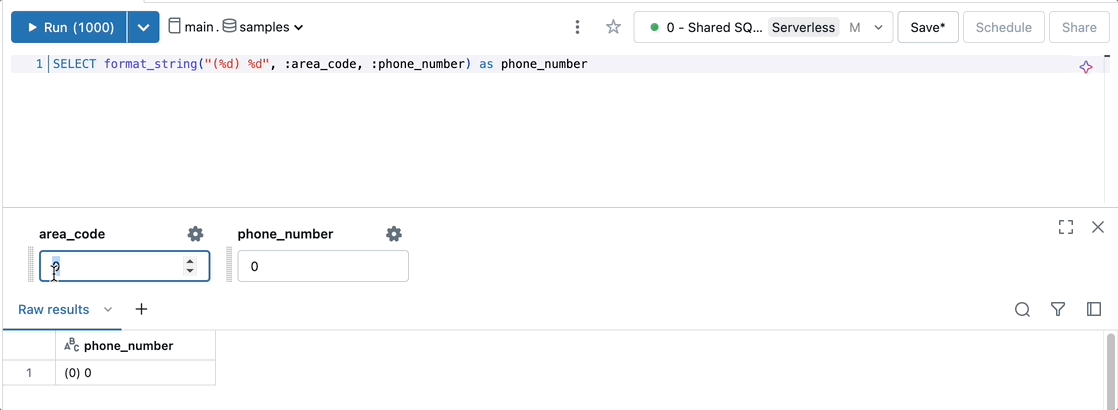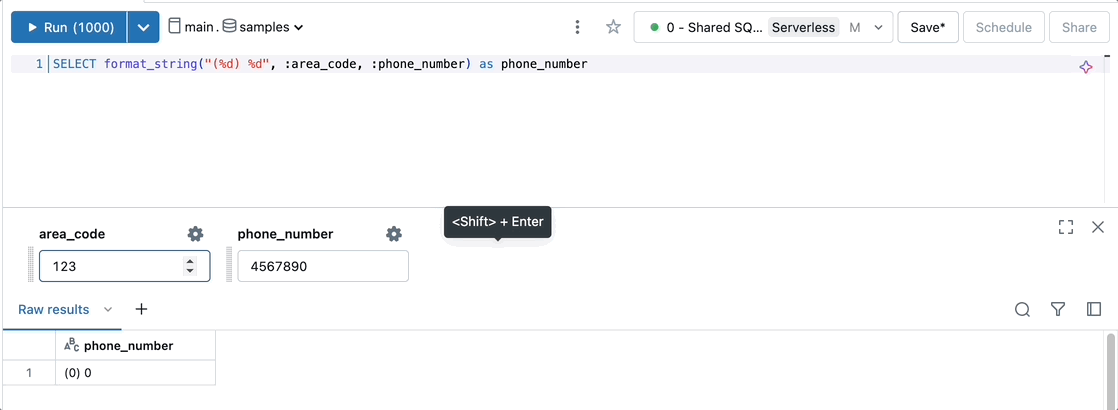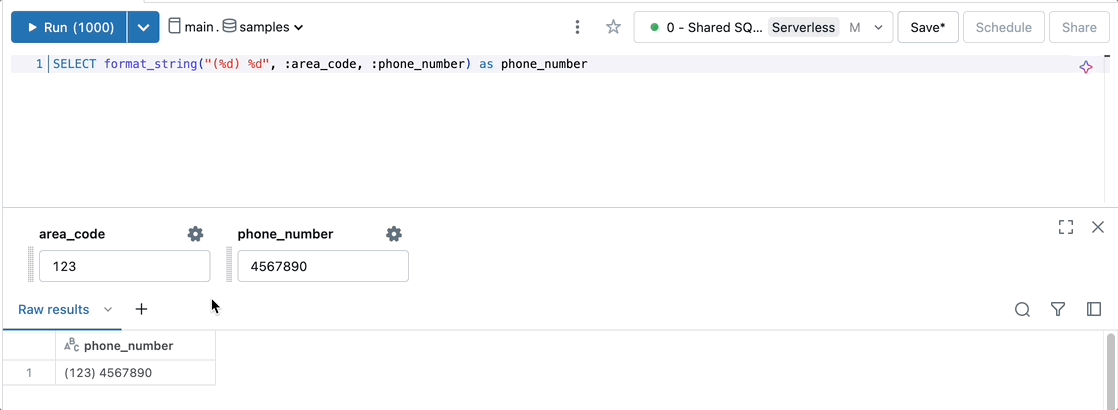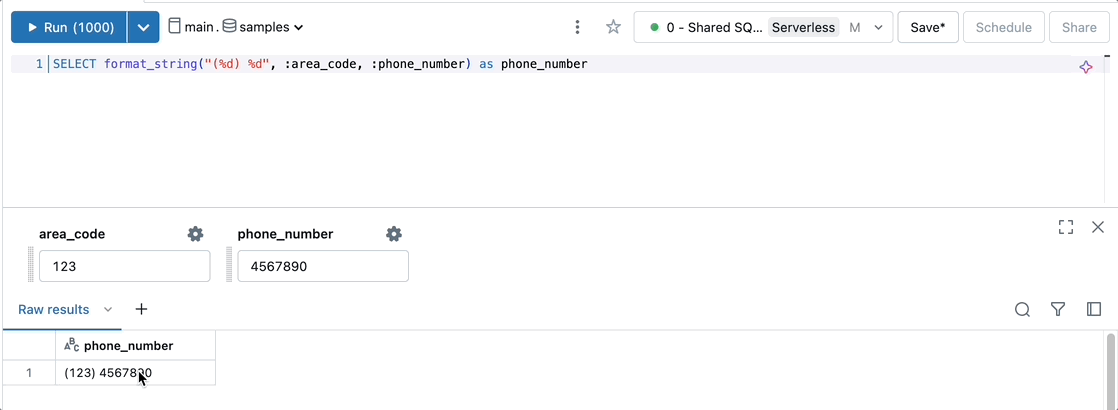
Parameterize rollups by day, month, or year.
SELECT DATE_TRUNC(:date_granularity, tpep_pickup_datetime) AS date_rollup, COUNT(*) AS total_trips FROM trips GROUP BY date_rollup
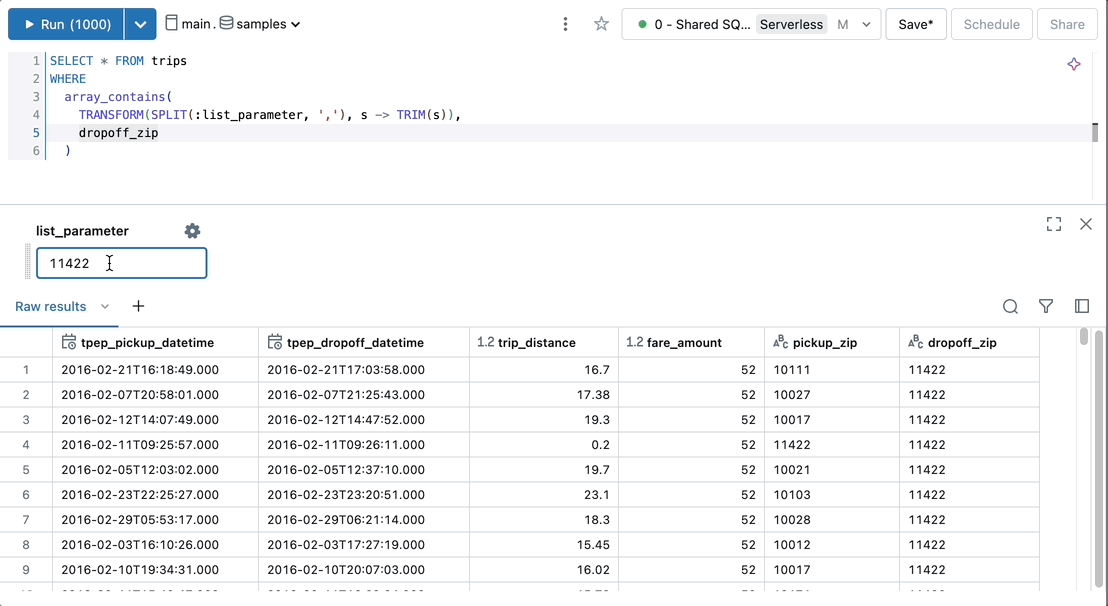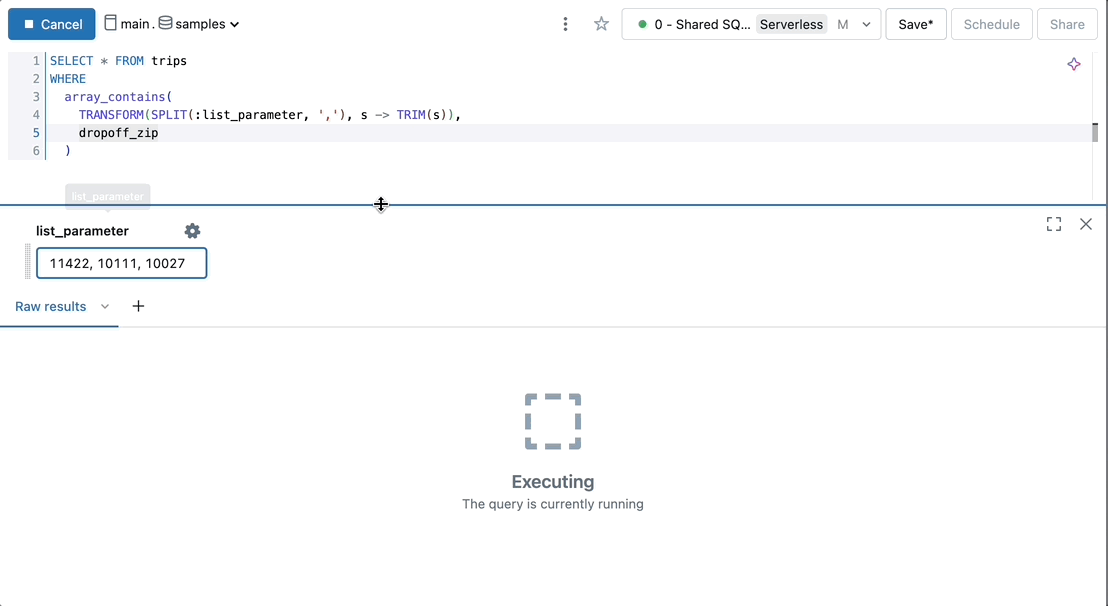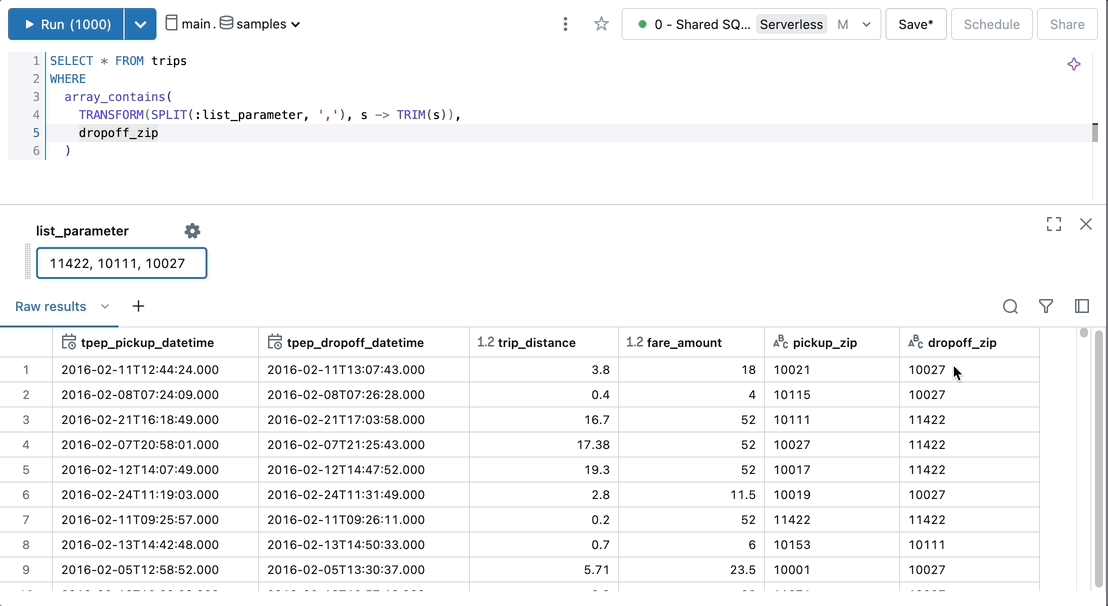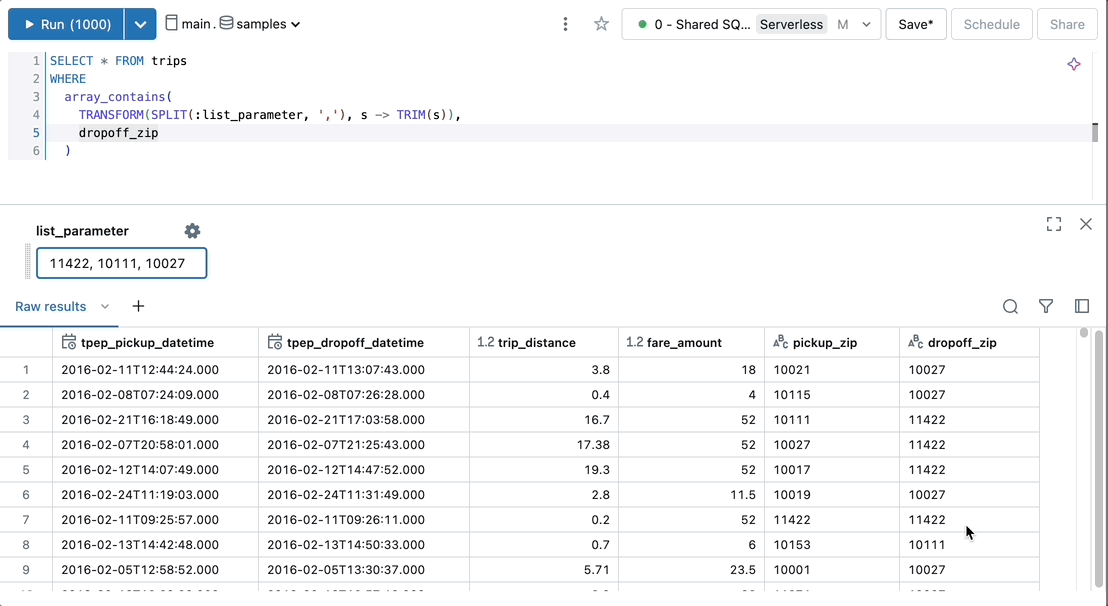
Select multiple parameter values in a single query.
SELECT * FROM trips WHERE
array_contains(
TRANSFORM(SPLIT(:list_parameter, ','), s -> TRIM(s)),
dropoff_zip
)
Coming soon
We look forward to providing even more simplicity and flexibility in field and parameter filtering with date range and multi-value parameters. For example,
SELECT * FROM trips where tpep_pickup_datetime BETWEEN :date.min AND :date.max and
SELECT * FROM trips where WHERE array_contains(:zipcodes, dropoff_zip)Get started with named parameter marker syntax
Named parameter marker syntax for queries, notebooks, dashboards, workflows, and the SQL Execution API is available today. If you have any feedback or questions, please contact us at [email protected]. Check the documentation page for more detailed resources on getting started parameters on Databricks.
To learn more about Databricks SQL, visit our website or read the documentation. You can also check out the product tour for Databricks SQL. If you want to migrate your existing warehouse to a high-performance, serverless data warehouse with a great user experience and lower total cost, then Databricks SQL is the solution — try it for free.
Source link
lol