
Machine Learning Visualization is the art and science of representing machine learning models, data, and their relationships through graphical or interactive means. It’s a crucial tool for understanding the complex inner workings of these models and making them more accessible to both technical and non-technical stakeholders. Visualization is crucial to any machine learning project to understand complex data. It is a powerful tool that illuminates patterns, trends, and anomalies, enabling data scientists and stakeholders to make informed decisions.
Data Visualization unveils data characteristics, distributions, and relationships, guiding feature engineering and preprocessing. It also identifies outliers or unusual data points that might impact model performance. Furthermore, It facilitates the identification and correction of inconsistencies or errors. Data Visualization effectively conveys data insights to technical and non-technical audiences.
Model Visualization provides insights into the decision-making process of a model, especially for complex models like neural networks. By visually interpreting the performance metrics, it helps in the efficient evaluation of the ML models. Moreover, it helps identify model training or prediction issues by visualizing training curves, loss functions, and feature importance. It contributes to building trust in models by visualizing how they reach their conclusions. Besides, Model Visualization also reveals which features contribute most to the model’s predictions.
In this article, you will learn various tools and techniques to visualize different models along with their Python implementation.
While there are many elements to visualize in a machine-learning model, we will discuss some of the most critical visualization and monitoring components here:
Loss and Performance Metrics
Loss and performance metrics are two of the main key indicators of a machine learning model’s effectiveness. While loss measures the error difference between the actual and prediction values, visualizing the training and validation loss curves helps understand how well the model is performing over time. It helps in diagnosing issues like slow learning, underfitting, etc., and allows for stopping the training runs when the model doesn’t go well, or making some adjustments to the model to improve overall performance.
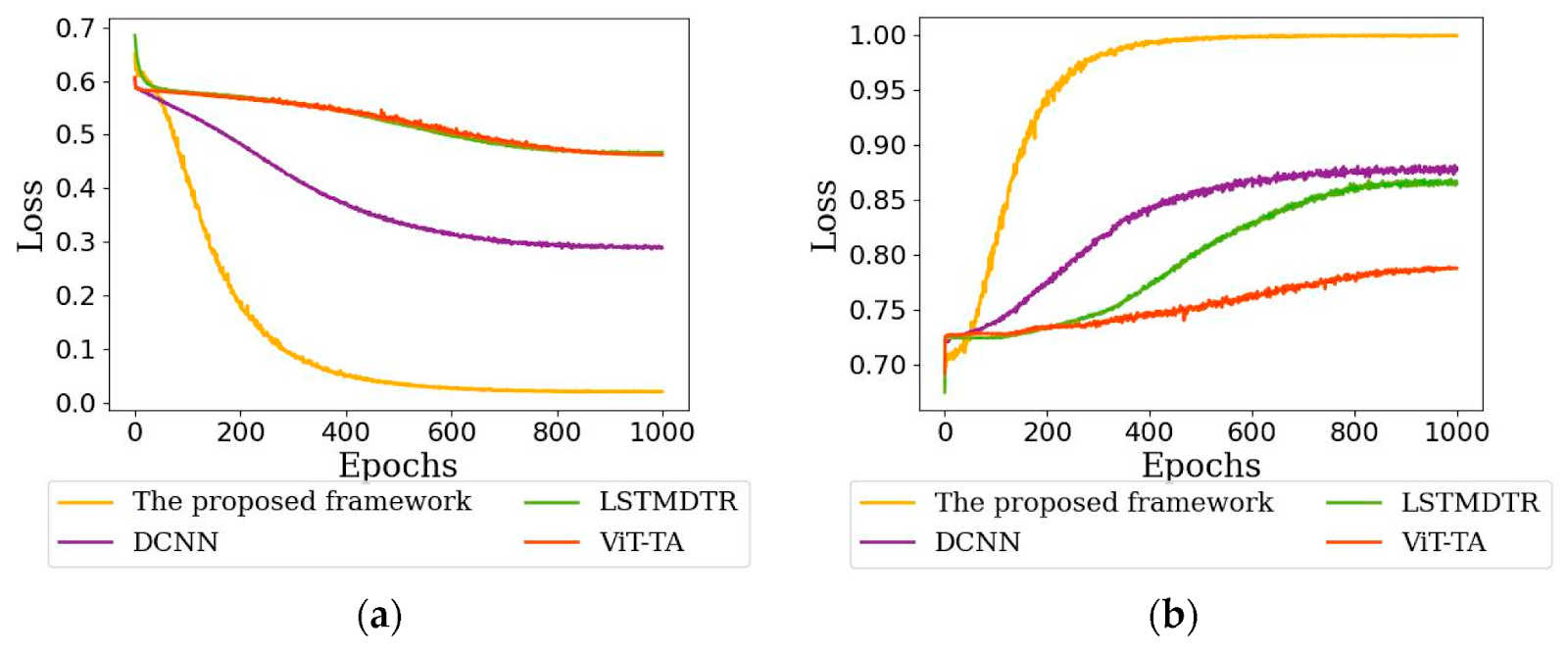
Plotting performance metrics such as accuracy, precision, recall, F1-score, etc. over epochs gives insights into model performance and improvement. These performance metrics visualizations help in identifying the model weaknesses, spot trends, and compare the model performance on training and testing sets.
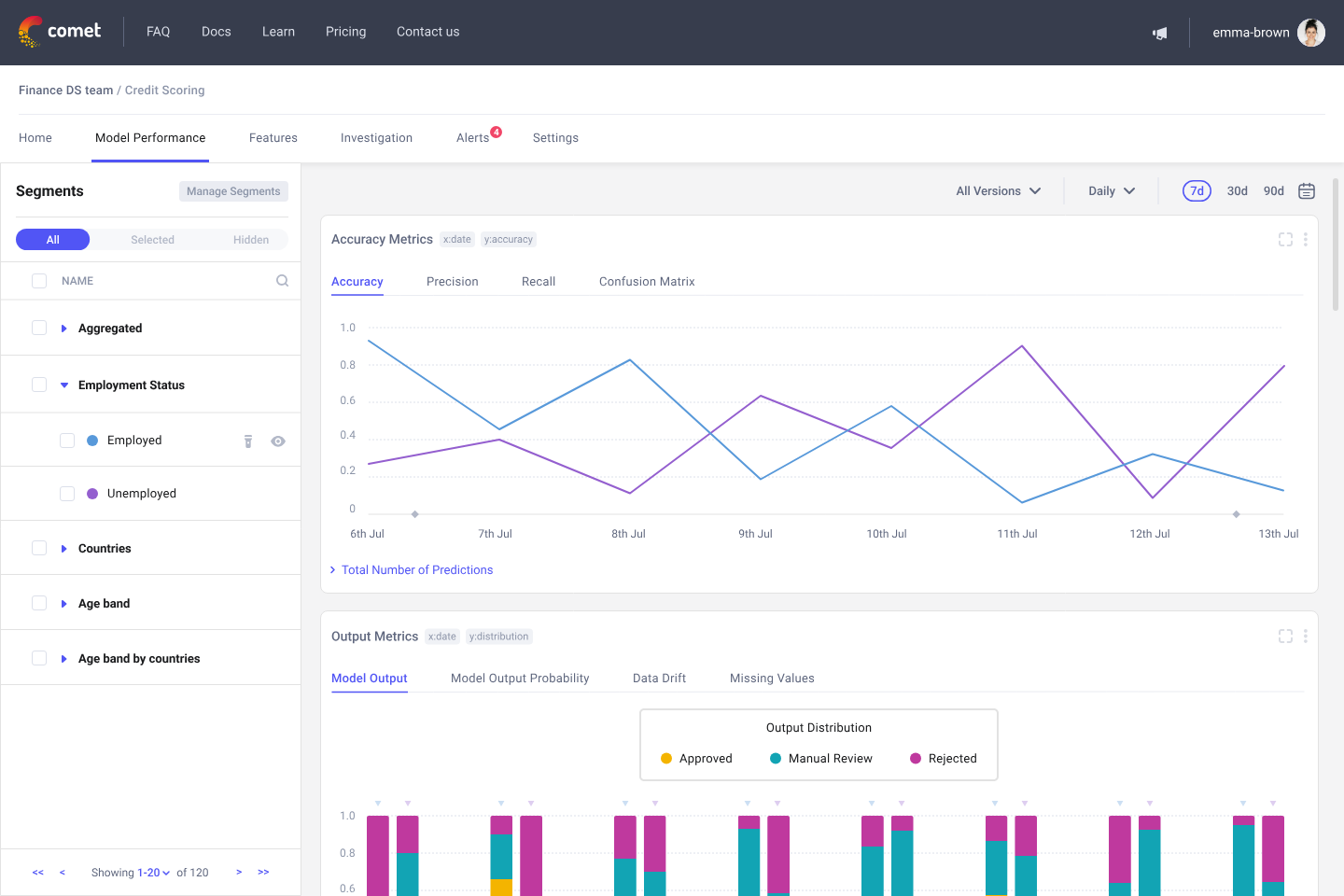
Weights and Biases
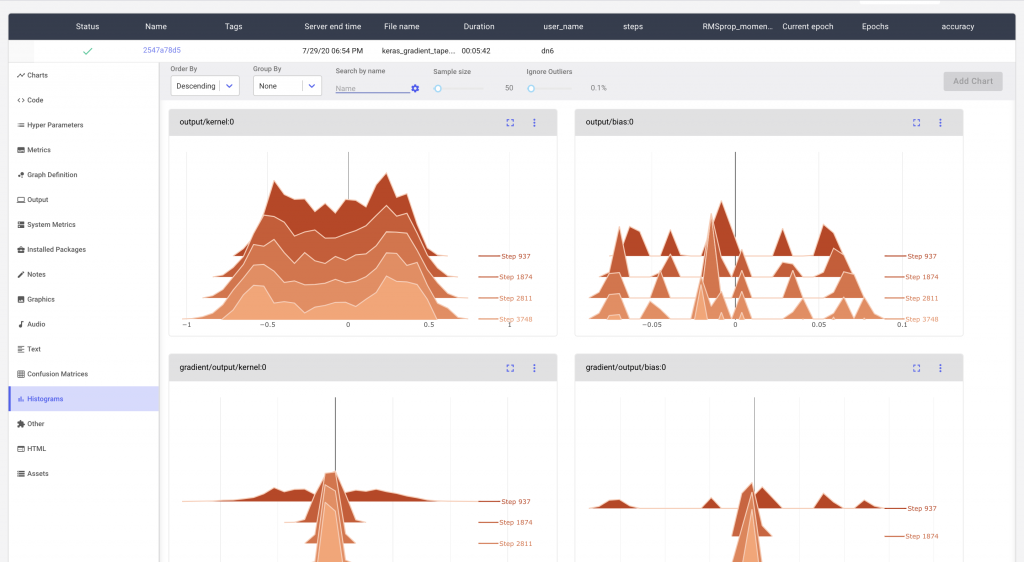
Weights and biases are the key components of the deep learning architectures that affect the model performance. Visualizing histograms or kernel density plots of weights and biases helps to understand the distribution of these parameters during training. Using these visualizations, you can easily spot issues like vanishing and exploding weights, identify biases, and ensure that the weights are updated properly throughout the training.
For convolutional neural networks, visualizing weight matrices as heatmaps can help you understand the relationship between input parameters and the learned parameters of the model. Heatmaps represent the magnitude of the weights with different color intensities which helps developers to rapidly spot patterns like which weights are dominant or inactive. This can help in making adjustments to the model architecture, regularization, training methods, etc. for better model performance.
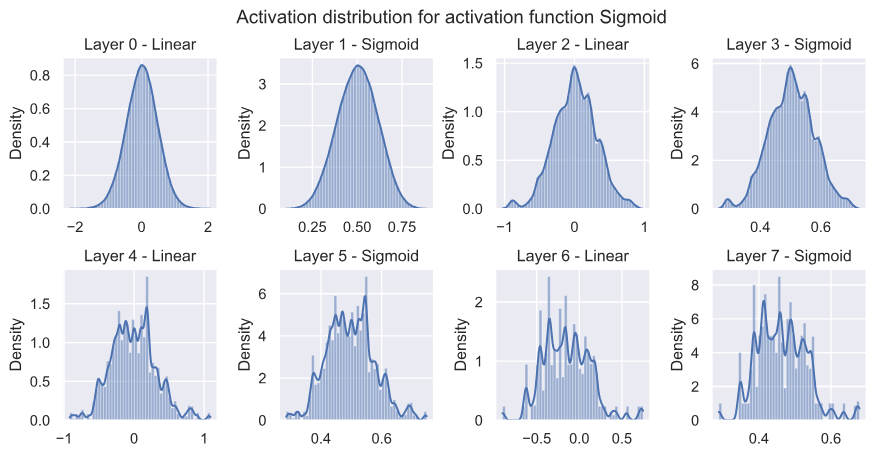
Activations
Analyzing activation distributions can help developers understand how neurons in a network are responding to the input. By analyzing these distributions, developers can identify problems like dead neurons where activations are stuck at zero, or saturation in other activation functions where the output of the activation becomes close to the upper or lower limit and causes the gradient shrinkage during backpropagation. Getting these insights helps in optimizing the neural network depth, activation functions, and learning rates to make sure that balanced activations are used across the network.
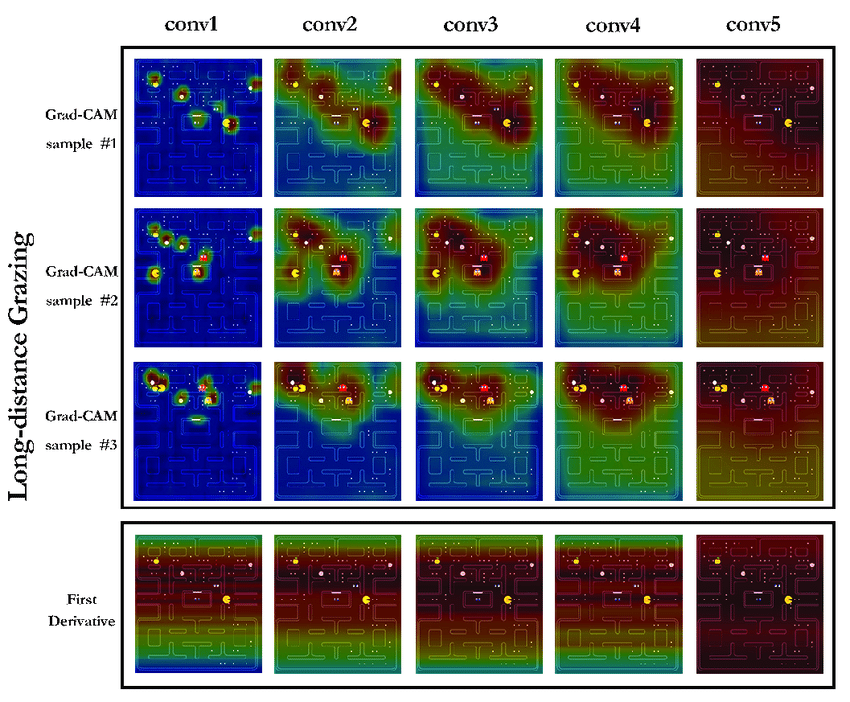
Visualizing activations on input data (e.g., image segmentation masks) can provide insights into how various layers of the neural network respond to the specific features in the dataset. This visualization helps developers learn about features that the model is focusing on and things like whether the model is learning the meaningful patterns or just irrelevant noise. An example of this visualization looks like this:
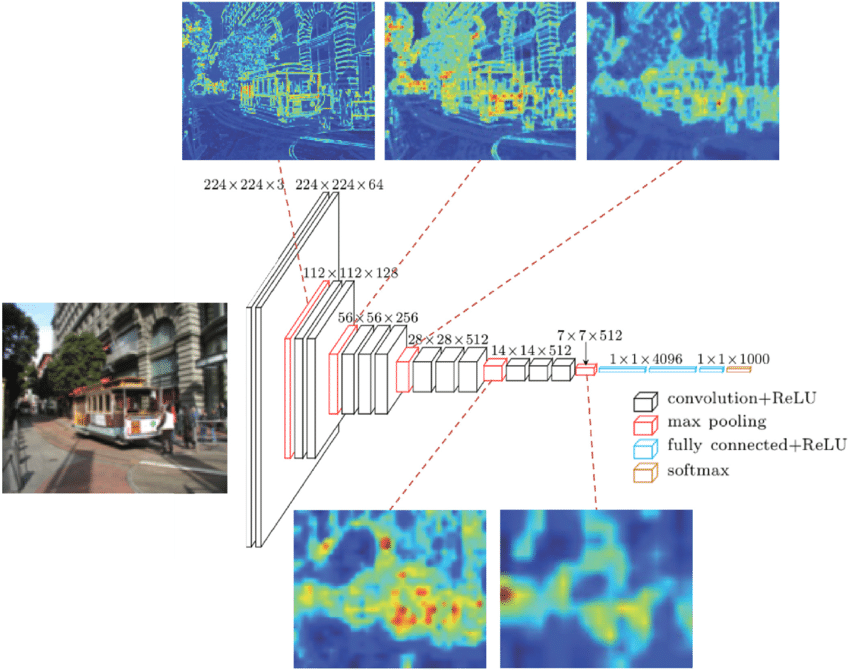
Gradients
Plotting gradient magnitudes can help identify exploding or vanishing gradient problems that can affect the model’s ability to update the weights properly. This visualization provides information on unstable gradients i.e. whether the gradients are too small (leads to slow learning) or too large (causes unstable training). By identifying these details, developers can adjust the learning rate, activation functions, or optimization algorithms for the model. For example, the vanishing gradient visualization might look something like this:
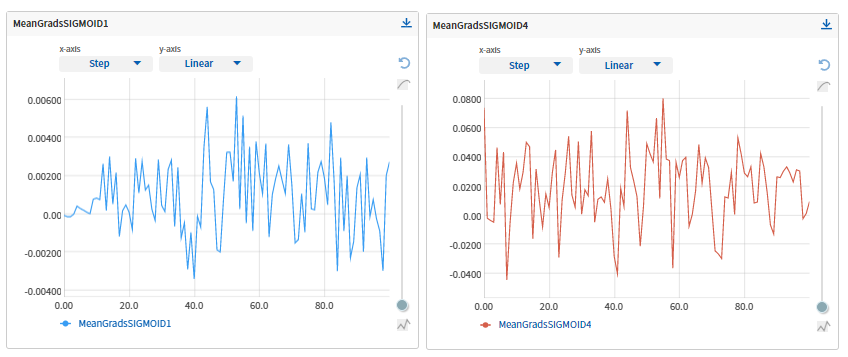
Visualizing gradient directions can provide insights into the optimization process by revealing how gradients guide the model’s weight updates. By examining the gradient directions, developers can check if the model is consistently moving toward minimizing the loss function or if it’s experiencing issues like poor convergence. For example, a simple plot for visualizing the gradients might look something like this:
Model Architecture
Visualizing the model architecture helps understand the model’s complexity and flow. This visualization helps developers ensure that the model is designed correctly, spot any architectural mistakes, or identify potential bottlenecks. For example, a sample model architecture visualization can look something like this:
Other Potentially Visualizable Components
Plotting the learning rate over time can show the impact of the learning rate on the training process. By plotting the learning rate over time, especially in techniques like learning rate schedules or warm start, developers can understand whether the learning rate is too high which causes unstable learning, or too low which causes slow training.
Moreover, visualizing input and output data distributions helps assess the data quality and model behavior. Developers can detect issues such as class imbalance, outliers, distribution shifts, etc. using these visualizations. Visualizing the output distribution also helps in getting insights into how well the model is generalizing or if it is biased toward certain predictions.
When choosing a visualization tool, it’s essential to consider several key factors to ensure it aligns with your specific needs and goals. Here are some of the most critical criteria:
Ease of Use
A user-friendly interface is crucial for efficient visualization. The tool should be intuitive to navigate, with clear labeling and easy-to-understand controls. Complex visualizations should be achievable without requiring extensive technical knowledge. A steep learning curve can hinder productivity and adoption within a team.
Integration with ML Frameworks
For those working with machine learning models, the ability to seamlessly integrate the visualization tool with popular frameworks like TensorFlow, PyTorch, or Scikit Learn is essential. This integration allows for direct visualization of model outputs, predictions, and feature importance, providing valuable insights into the model’s behavior.
Visualization Capabilities
The tool should offer various visualization features to communicate the insights. General visualizations include line charts, bar charts, scatter plots, histograms, heat maps, and 3D plots. Additionally, specialized visualizations for specific domains, such as network graphs for social media analysis or geographical maps for spatial data, can be valuable.
Community Support and Documentation
A strong community and comprehensive documentation are vital for troubleshooting issues, learning new features, and finding inspiration. An active community can provide valuable assistance and share best practices. Good documentation ensures that users can easily understand the tool’s functionalities and learn how to use them effectively.
Scalability and Performance
The tool should be able to handle large datasets without compromising performance or responsiveness. Scalability is crucial for organizations dealing with growing data volumes. Additionally, the tool should be optimized for speed, allowing for quick visualization of complex data structures and interactive exploration.
Additional Considerations
When selecting a visualization tool, it’s crucial to consider its cost, whether it’s open-source, subscription-based, or a perpetual license. Additionally, evaluate its collaboration features for sharing and working on visualizations together. Finally, consider the tool’s deployment options, such as its ability to integrate seamlessly into web applications or dashboards. These factors will impact the tool’s suitability for your requirements and budget.
By carefully considering these factors, you can select a visualization tool that aligns with your project’s needs and enhances your machine-learning workflow.
So far, we have discussed the importance of visualization, crucial visualization components, and criteria for selecting the visualization tool. It is time to learn about some crucial model visualization tools with Python implementation.
Here’s a rundown of 10 popular tools for machine learning visualization, including their key features, functionalities, and how they can help you visualize your models.
TensorBoard (by Google)
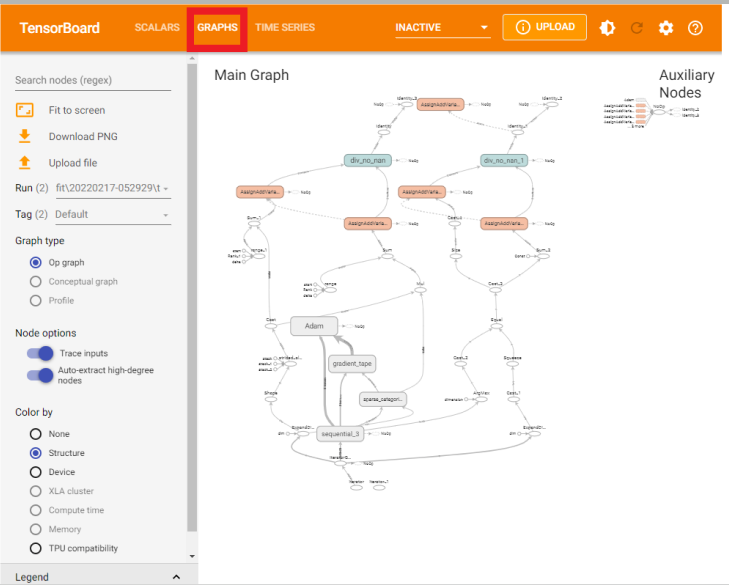
TensorBoard is a powerful visualization tool primarily used to understand and debug machine learning models. It is an integral part of the TensorFlow ecosystem. However, you can also use it with other frameworks like PyTorch. TensorBoard provides a web-based interface that allows users to visualize various aspects of their model, including the model graph, training metrics, embeddings, and more.
By visualizing the model graph, users can gain insights into the architecture of their network, identify potential bottlenecks, and understand how data flows through the model. Additionally, TensorBoard can plot metrics such as loss and accuracy over time, enabling users to monitor the training process and identify areas for improvement. You can visualize embeddings, which are low-dimensional representations of high-dimensional data, in TensorBoard to develop a better understanding of the relationships between different data points.
Moreover, it provides various visualizations like loss curves, accuracy metrics, histograms of weights and biases, activation distributions, and embedded projections. It offers real-time monitoring and interactive exploration. You can build a TensorBoard dashboard for a TensorFlow model using the Python code as follows:
import tensorflow as tf
from tensorflow.keras import layers, models
import datetime
# Load and preprocess the MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # Normalize the images
# Add a channel dimension to the images (28, 28) -> (28, 28, 1)
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# Define the model
model = models.Sequential([
layers.Input(shape=(28, 28, 1)), # Input layer with shape (28, 28, 1)
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10) # Output layer with 10 classes
])
# Compile the model
model.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Set up TensorBoard callback
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Train the model
history = model.fit(x_train, y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
# Launch TensorBoard (in a notebook, you can use %tensorboard magic command)
print("Run 'tensorboard --logdir=logs/fit' in your terminal to view TensorBoard.")We are using the MNIST Dataset and CNN model to classify digit images. In the above code, the model is monitored using a TensorBoard callback which is already available in TensorFlow Keras. Then you can launch the TensorBoard to visualize the model metrics.
To launch the TensorBoard in Jupyter Notebook use the following commands:
%load_ext tensorboard
%tensorboard --logdir logs/fit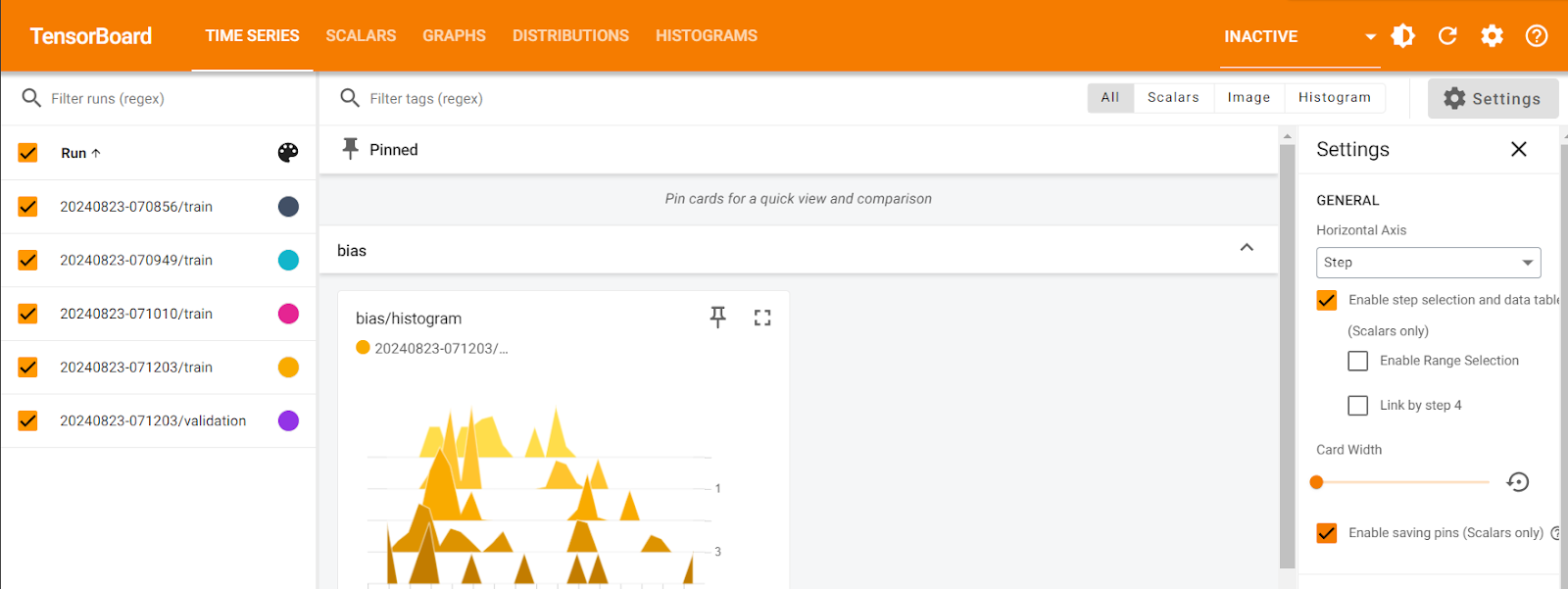
You can see here that Tensorboard provides various methods to visualize the models, such as Time Series, Graphs, Histograms, etc. You can click on any of these to select the visual of your choice to understand the model performance.
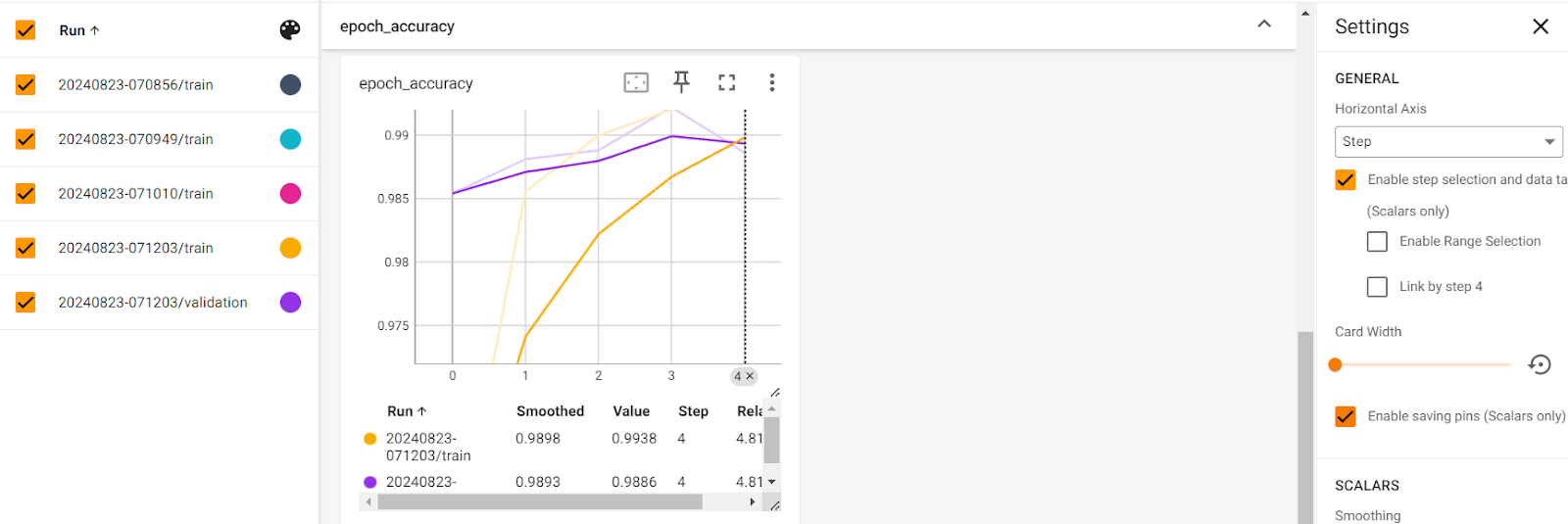
The above Tensorboard dashboards depict the change in model accuracy score with each epoch.
Comet (by Comet.ml)
Comet ML is a comprehensive machine learning experimentation platform that offers various tools to streamline the development, tracking, and comparison of machine learning models. It provides a centralized workspace where users can organize experiments, log metrics and hyperparameters, visualize results, and collaborate with team members.
Comet ML offers a variety of features that make it a valuable tool for machine learning practitioners. These include experiment tracking, hyperparameter tuning, model versioning, artifact management, and integration with popular frameworks like TensorFlow, PyTorch, and Scikit-Learn. By automating many of the routine tasks involved in the machine learning process, Comet ML allows users to focus on building better models and gaining insights from their experiments. Comet ML offers features for visualizing loss curves, metrics, hyperparameters, code, and data distributions.
You can build a Comet ML Experiment tracker for a TensorFlow model using the Python code as follows:
from comet_ml import Experiment
# Log hyperparameters to Comet
experiment.log_parameters({
'epochs': 5,
'batch_size': 32
})
# Log metrics manually to Comet (optional)
metrics = history.history
for epoch in range(5):
experiment.log_metrics({
'loss': metrics['loss'][epoch],
'accuracy': metrics['accuracy'][epoch],
'val_loss': metrics['val_loss'][epoch],
'val_accuracy': metrics['val_accuracy'][epoch]
}, step=epoch)
print("Comet logging completed.")For using Comet, you will need the API Key which you need to create on the Comel ML platform. We are using the same CNN model trained above and the model is monitored using Comet. Now, you can visualize the model metrics on the Comet.ml platform.
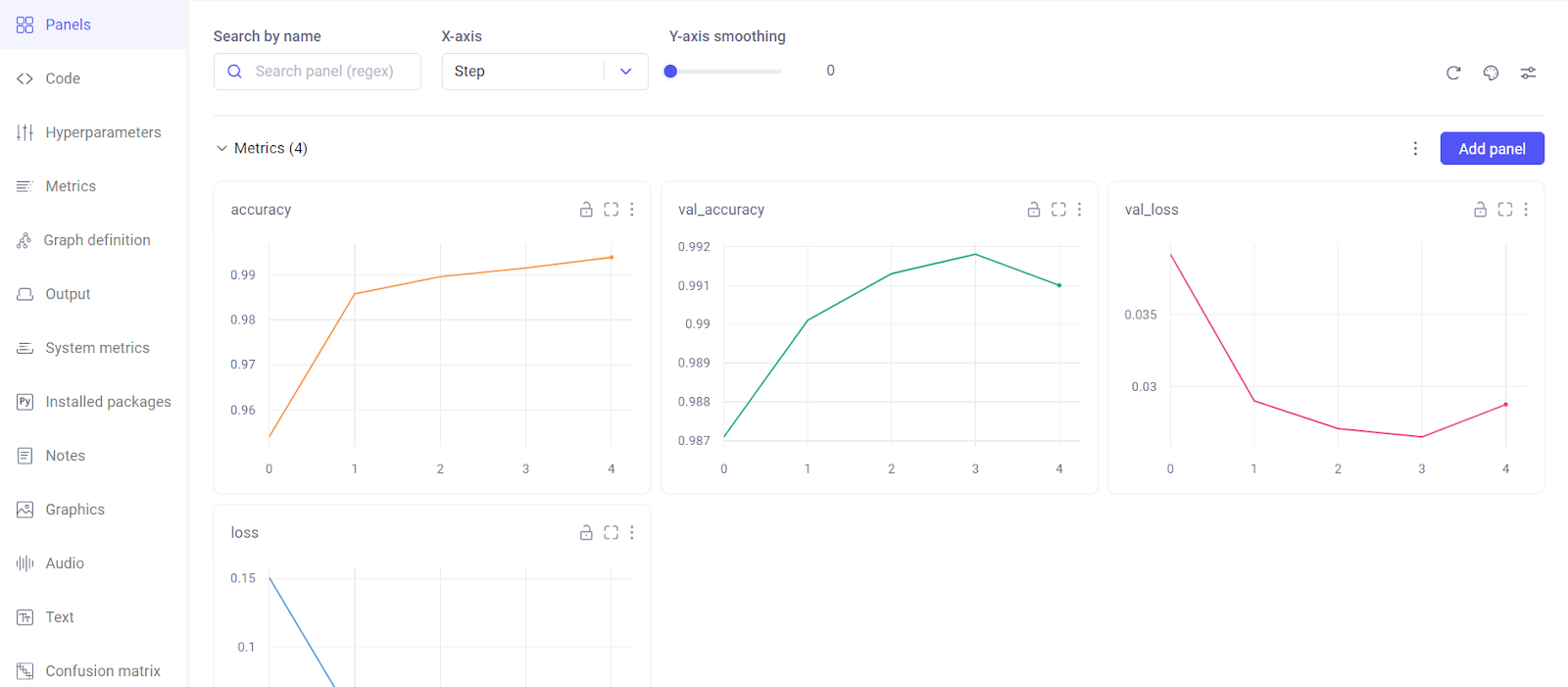
Comet dashboard is more interactive with more additional features as you can see in the above image. The visual shows the accuracy and loss for training and validation sets. You can choose to view any feature with just a click.
Neptune.ai
Neptune.ai is an innovative platform designed to manage and track learning experiments. Unlike traditional visualization tools, Neptune.ai goes beyond simply displaying results. It offers a comprehensive solution for logging, organizing, and visualizing all aspects of your experiment workflow. Imagine keeping track of model metrics, parameters, code versions, and even hyperparameter tuning configurations, all within a unified and user-friendly interface.
This platform shines in its ability to handle large-scale projects efficiently.
Neptune.ai boasts impressive scalability, allowing you to track complex experiments with massive datasets without sacrificing performance. Real-time visualizations ensure you can monitor progress and identify potential issues as they arise. Furthermore, Neptune.ai caters to collaboration, enabling seamless sharing of experiments and fostering team communication around your machine learning endeavors.
Neptune logs code, data, metrics, models, and visualizations. Users can compare experiments, analyze model performance, and collaborate effectively. Moreover, It tracks experiment runs and visualizes metrics, model architectures, weight distributions, and data distributions for comparison.
You can build a Neptune AI Experiment tracker for a TensorFlow model using the Python code as follows:
…
import neptune
# from neptune.new.integrations.tensorflow_keras import NeptuneCallback
# Initialize a Neptune run
run = neptune.init_run(
project="common/quickstarts", # Replace with your project path
api_token = neptune.ANONYMOUS_API_TOKEN # Replace with your API token
)
# Log hyperparameters
run['parameters'] = {
'epochs': 5,
'batch_size': 32
}
# Log a single value
# Specify a field name ("seed") inside the run and assign a value to it
run["seed"] = 0.42
# Log a series of values
from random import random
epochs = 5
offset = random() / 5
for epoch in range(epochs):
acc = 1 - 2**-epoch - random() / (epoch + 1) - offset
loss = 2**-epoch + random() / (epoch + 1) + offset
run["accuracy"].append(acc)
run["loss"].append(loss)
# Define the Neptune callback
# neptune_cbk = NeptuneCallback(run=run)
# Train the model with Neptune callback
history = model.fit(x_train, y_train,
epochs=epochs,
validation_data=(x_test, y_test))
# Close the Neptune run
run.stop()
print("Neptune logging completed.")Again, you will need the API Key to use Neptune AI which you need to create on the Neptune platform. We have used the same CNN model and parameters and metadata is logged into Neptune. Now, you can visualize the model metrics on the Naptune.ai platform.
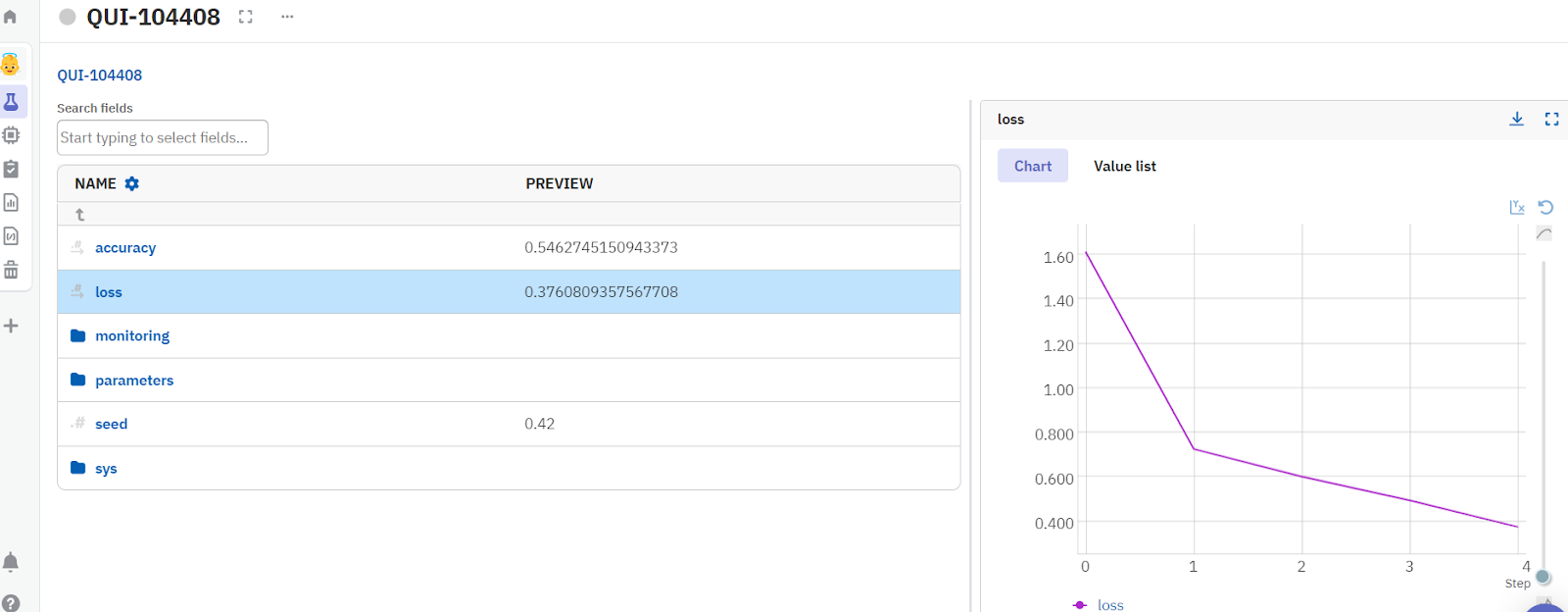
The Neptune dashboard helps you monitor the accuracy, loss, and other hyperparameters. Moreover, You can download the chart or list of values of any metric you need from Neptune dashboard.
Weights & Biases (wandb.ai)
Weights & Biases, also known as Wandb (wandb.ai), is an MLOps platform designed to streamline the entire machine learning workflow, from experimentation to production. It offers a comprehensive suite of tools for building, training, and monitoring machine learning models.
One of its core strengths lies in its visualization capabilities. Wandb integrates seamlessly with popular ML frameworks. This tool allows users to log data, metrics, and hyperparameters.
This data is then visualized in a user-friendly interface, providing real-time insights into model performance, training progress, and hyperparameter tuning.
Additionally, Wandb offers various visualizations, including line charts, heat maps, and interactive plots. This tool allows for in-depth exploration of model behavior and facilitates effective communication of results to stakeholders.
Wandb offers robust logging capabilities, version control, collaboration features, and visualizations for loss curves, metrics, hyperparameters, data distributions, and model architectures. Besides, It tracks experiment runs and visualizes training progress, model parameters, data distributions, and code versions for comparison.
You can build a wandb model visualizer for a TensorFlow model using Python code as follows:
…
import wandb
config = {
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"log_step": 200,
"val_log_step": 50,
"architecture": "CNN",
"dataset": "CIFAR-10"
}
run = wandb.init(project="my-tf-integration mnist", config=config)
config = wandb.config
print("Weights & Biases logging completed.")To run the above code, you will need to initialize the run with the wandb project configuration. This configuration includes the model metrics which you would like to monitor. We have used the same CNN model CNN model to classify the digit image. The model is monitored using wandb. Now you can visualize the model metrics on wandb platform.

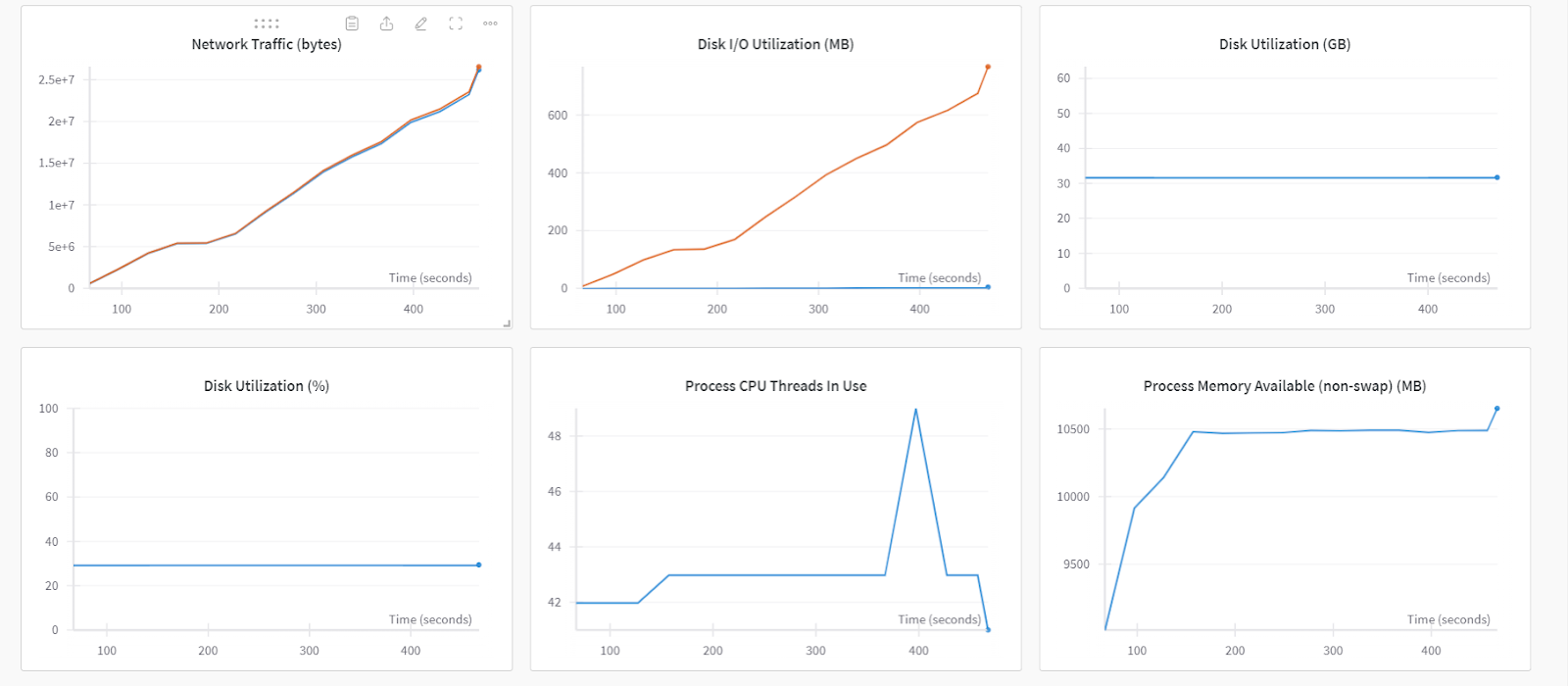
As you can see, wandb also provides monitoring of system metrics to help you visualize the CPU, Disk, and Memory utilization, Network Traffic, etc.
MLflow
MLflow is a platform designed to streamline the machine learning lifecycle. It provides tools and services that help data scientists manage, track, and deploy their models. MLflow consists of three main components: Tracking, Projects, and Models.
The Tracking component allows users to log and record experiments, parameters, metrics, and artifacts associated with their Machine learning models. This feature helps to track the model’s evolution over time and compare different model configurations. The Projects component provides a way to package and reproduce machine learning projects. This component makes it easy to share and collaborate on experiments. MLflow also offers the Models component for managing and deploying models to various environments, such as production servers or cloud platforms.
MLFlow provides logging, tracking, model registry, deployment tools, and integrations with various ML frameworks. While visualization capabilities are not its core strength, it offers basic visualizations for metrics and models. Additionally, It offers basic visualizations for model performance metrics and limited model architecture exploration. You can use MLFlow to track deployed models.
You can build an MLFLow Experiment tracker for a Random Forest Model using the Python code as follows:
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
mlflow.set_experiment('hotel_occupancy')
# Load dataset
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run():
# Train a model
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Log the model
mlflow.sklearn.log_model(clf, "random_forest_model")
# Log metrics (e.g., accuracy)
accuracy = clf.score(X_test, y_test)
mlflow.log_metric("accuracy", accuracy)We will used the IRIS Dataset and Random Forest model to classify the Iris data points. Then the model is monitored using mlflow which you have installed using pip. After running the code you will find a folder named mlruns which contains metadata of all the runs for the experiment you have created.
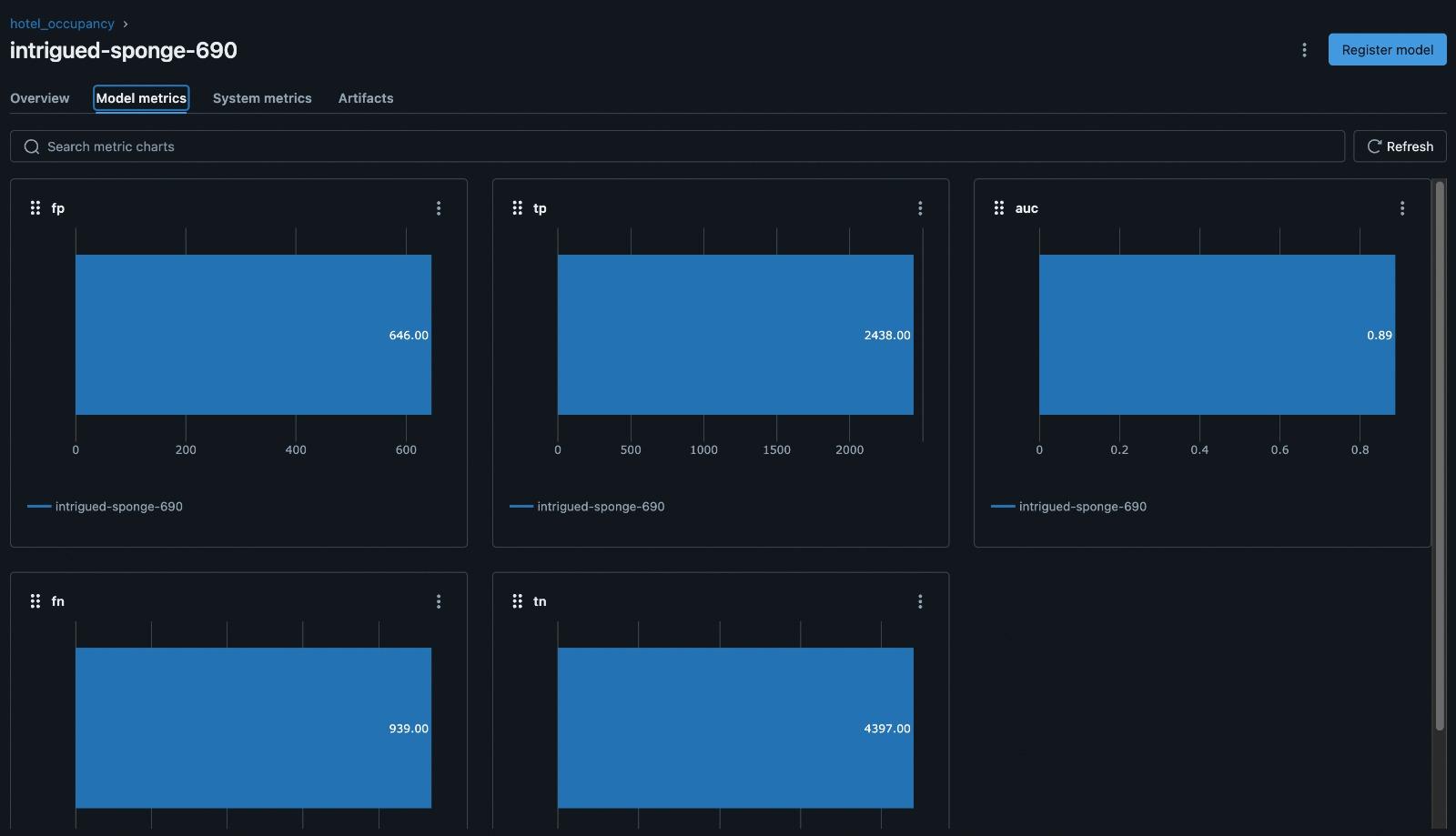
The above visual is the MLFlow dashboard showing metrics like AUC and entries of the confusion matrix.
LIME (Local Interpretable Model-Agnostic Explanations)
LIME is a machine learning library designed to provide interpretable explanations for the predictions made by complex models. It works by creating simpler, locally linear models around individual predictions. These simpler models, known as “surrogate models,” can be easily understood and interpreted.
LIME’s primary advantage is its ability to explain the predictions of any black-box model, regardless of its complexity or architecture.
This feature makes it a valuable tool for understanding the decision-making process of opaque models, such as deep neural networks. LIME can help improve model transparency, build trust, and ensure that models make fair and unbiased decisions by identifying the key features that are more relevant in prediction-making.
LIME provides explanations for individual predictions by approximating the model locally with an interpretable model like a decision tree. Moreover, It explains individual model predictions by highlighting the features most influential for a specific prediction.
Let’s build a churn prediction model to predict the churn based on age, tenure, and total charge features.
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import lime
import lime.lime_tabular
# Simulate a dataset (replace with your actual data)
data = {
'age': np.random.randint(18, 65, size=1000),
'tenure': np.random.randint(1, 72, size=1000),
'total_charge': np.random.uniform(0, 1000, size=1000),
'churn': np.random.choice([0, 1], size=1000, p=[0.8, 0.2])
}
df = pd.DataFrame(data)
# Split data into features and target
X = df.drop('churn', axis=1)
y = df['churn']
# Train a logistic regression model (replace with your desired model)
model = LogisticRegression()
model.fit(X, y)
# Create an explainer object
explainer = lime.lime_tabular.LimeTabularExplainer(
X.values,
feature_names=X.columns,
class_names=["No Churn", "Churn"]
)
# Explain the prediction for a specific instance
index_to_explain = 10 # Replace with the desired index
explanation = explainer.explain_instance(
X.iloc[index_to_explain].values,
model.predict_proba,
num_features=10
)
# Print the explanation
Since it is a binary classification problem, we have used the Logistic Regression algorithm to build the model and then have used LIME to get the model explanation including feature importance. Now, run the following command to see the model visualization:
explation.as_pyplot_figure()
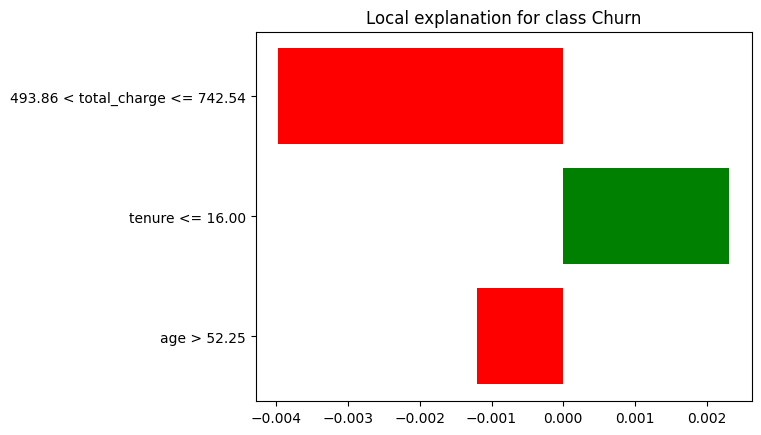
The above image clearly illustrates the feature’s importance for predicting the churn. The total_charge value ranges from 493.86 to 742.54, negatively impacting churn while tenure less than or equal to 16 will lead to positive churn.
Grad-CAM (Gradient-weighted Class Activation Mapping)
Grad-CAM is a visualization technique that helps understand the most important parts of an image for a deep neural network’s classification decision. It does this by creating a heatmap that highlights the regions of the image that contribute most significantly to the network’s prediction.

Grad-CAM works by calculating the gradient of the class-specific output score concerning the feature maps of the final convolutional layer. Then, it calculates the average of these gradients to produce a class-specific weight for each feature map. Finally, these weights are multiplied by the corresponding feature maps and summed to generate the heatmap. The heatmap overlaps the original image to visualize the most relevant regions for the classification task. You can check the image and code of Grad-CAM visualization here.
SHAP (SHapley Additive exPlanations)
SHAP is a game-theoretic approach to explain the output of any machine learning model. It provides a method to quantify the contribution of each feature to a prediction, helping users understand the underlying decision-making process of the model. SHAP is based on the Shapley values concept from cooperative game theory, which measures the average marginal contribution of a player to the coalition’s payoff.
In a similar fashion, SHAP calculates the contribution of each feature to the prediction by considering how the model’s output changes when the feature is present or absent. This is done by iterating over all possible permutations of the features and calculating the marginal contribution of each feature to the prediction. The final SHAP value for a feature represents its average marginal contribution across all possible permutations. SHAP provides a global explanation for each feature as well as feature-level explanations for individual predictions.
import shap
import xgboost as xgb
model = xgb.XGBClassifier()
model.fit(x_train, y_train)
# # Define the SHAP explainer
# explainer = shap.KernelExplainer(model.predict, x_train)
explainer = shap.TreeExplainer(model)
# For a single sample:
# sample_index = 0
# shap_values = explainer.shap_values(x_train.iloc[sample_index])
# For a batch of samples:
batch_size = 100
shap_values = explainer.shap_values(x_train.head(batch_size))
shap.summary_plot(shap_values, x_train.columns)
To understand SHAP, the XGBoost model was built for the same churn prediction dataset and the explainer was built on 100 samples of the training set to visualize the correlation of each feature with the target variable.
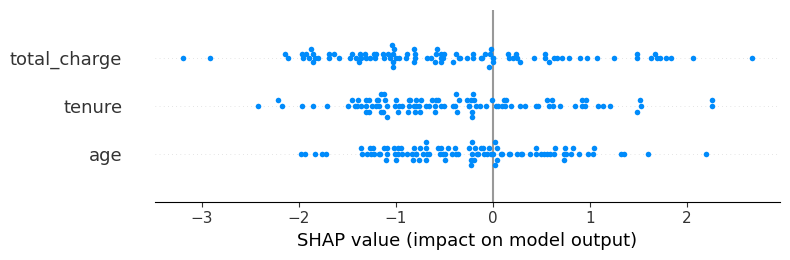
In the above chart, the x-axis represents the SHAP values and the y-axis represents the features in the dataset. Here, there is no certain pattern but the lower values of `total_charge` are resulting in lower churn which really makes sense.
Yellowbrick
Yellowbrick is a machine-learning visualization library that provides a simple and effective way to visualize the inner workings of your models. It is built on top of scikit-learn, making it easy to integrate into existing machine-learning pipelines. Yellowbrick offers a variety of visualizations, including scatter plots, line plots, bar charts, and more, that can help you understand your model’s behavior and identify areas for improvement.
One of the crucial features of Yellowbrick is its ability to create visualizations directly within your Jupyter Notebook or Python script. This feature makes it easy to explore your data and model interactively without switching between different tools. Yellowbrick also provides a variety of metrics and scoring functions to evaluate your model’s performance, such as accuracy, precision, recall, and F1-score.
Yellowbrick offers a variety of visualizers for different machine-learning tasks, including classification, regression, clustering, and model selection. It integrates seamlessly with Scikit-learn’s pipeline and estimator API. It also Visualizes model selection processes (e.g., hyperparameter tuning, learning curves), feature importances, classification reports, and regression residuals.
We will use the same churn prediction dataset for the model visualization using yellowbrick. For this, a Logistic Regression classifier is used to build the model and then we will visualize the classification report and ROC-AUC curve using yellowbrick.
import yellowbrick as yb
import pandas as pd
import sklearn.linear_model as lm
from yellowbrick.classifier import ClassificationReport
model = lm.LogisticRegression()
visualizer = ClassificationReport(model)
visualizer.fit(x_train, y_train)
visualizer.score(x_train, y_train)
visualizer.show()
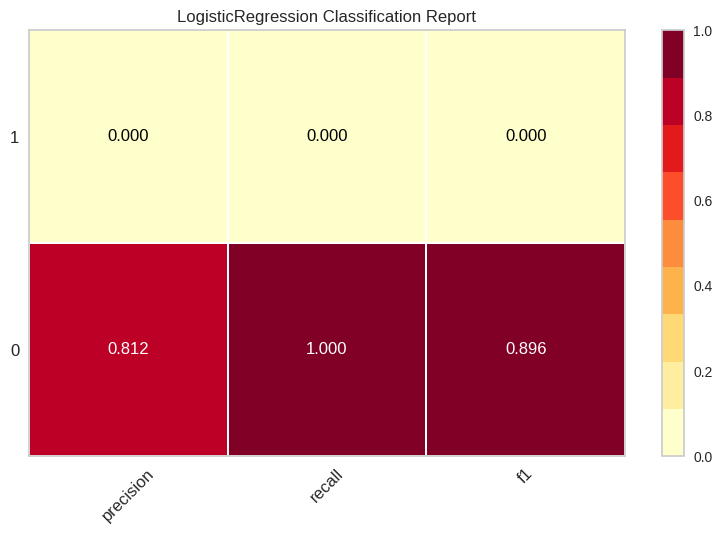
The above visual drawn using Yellowbrick shows the classification report with metrics such as precision, recall, and f1-score.
from yellowbrick.classifier import ROCAUC
visualizer = ROCAUC(model)
visualizer.fit(x_train, y_train)
visualizer.score(x_train, y_train)
visualizer.show()
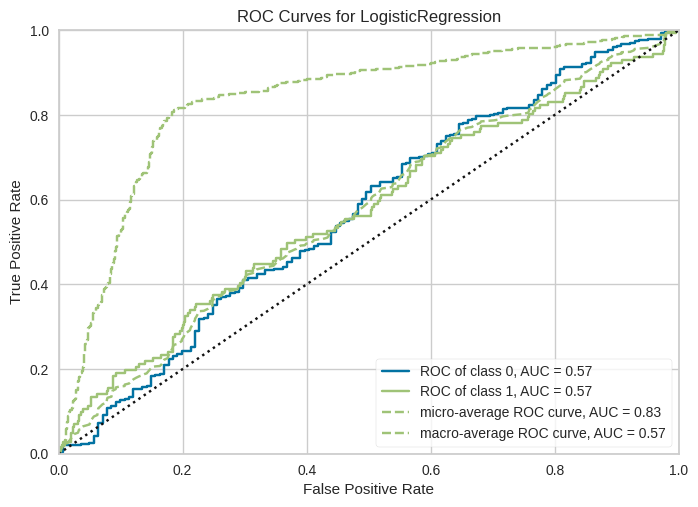
As you can see in the above chart, the ROC and AUC curve is plotted for the two classes present in the data. And as expected, the model is not performing well, given that it is overfitting.
Netron
Netron is a versatile visualization tool designed to inspect and understand neural network architectures. It supports multiple deep learning frameworks, including TensorFlow, PyTorch, Caffe, ONNX, and MXNet. Netron provides a user-friendly interface that allows users to visualize various aspects of neural networks, such as the network architecture, layer details, weights, and biases.
By visualizing the network architecture, users can understand the data flow through the model and identify potential bottlenecks or inefficiencies. Additionally, Netron allows users to inspect the details of individual layers, including their types, activation functions, and parameters. This tool can be helpful for debugging models and understanding how they make predictions.
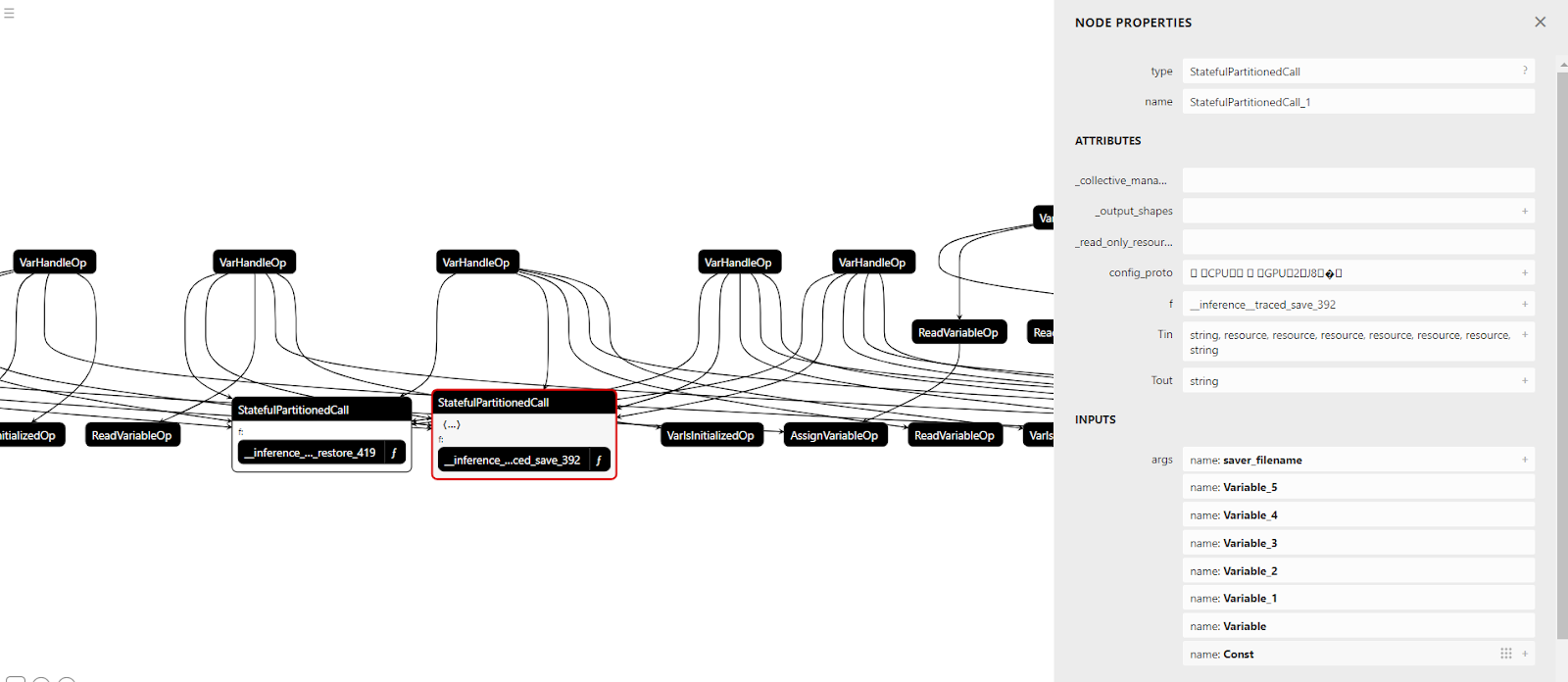
The above visual shows the model architecture with the breakdown of each node of a deep learning model.
While each tool provides unique features and visualization options, you will have to utilize multiple of them for different types of visualization needs. Managing multiple tools can be challenging at times, so you need a unified solution through which you can utilize almost all these mentioned tools. DagsHub is one of the most powerful platforms that supports collaborative model visualization in machine learning projects. Most of the model and data visualization tools can be integrated with DagsHub to track and visualize experiments, parameters, and metrics across multiple runs. It can work as an optimal choice for visualizing and understanding the evolution of machine learning models.
You need to consider the following factors mentioned in the table below:
Furthermore, a comparison of the tools discussed in this article will also help you make the right choice.
Conclusion
Machine learning models can be complex and difficult to understand. Hence, model visualization becomes crucial to help data scientists gain deeper insights into these models, their data, and the relationships between them. By carefully selecting and visualizing different components like loss curves, weights, activations, and model architecture, data scientists can:
- Identify potential issues with model training or prediction.
- Make informed decisions to improve model performance.
- Effectively communicate findings to both technical and non-technical stakeholders.
This article explored various popular visualization tools like TensorBoard, Comet, Neptune.ai, Yellowbrick, and others, each offering unique functionalities and strengths. You also know that choosing the right tool depends on factors like ease of use, integration with ML frameworks, visualization capabilities, and project needs.
While there are different tools for different visualization needs, sometimes it can get confusing to know what tools to use for your project. In this case, tools like DagsHub come to the rescue. DagsHub can be integrated with almost all of these mentioned visualization tools to provide you with a unified platform for all your modeling and visualization needs. You can learn more about it in its official documentation.
Source link
lol