We’ve talked to William Arias, Staff Developer Advocate at GitLab, about how his team built scalable pipelines to process a year’s worth of support tickets from different platforms, to better understand their community’s needs and improve the support and documentation provided to their users.
GitLab is a popular DevSecOps platform, with over 40 million registered users, including developers at 50% of Fortune 100 companies. GitLab’s aim is to help teams ship software faster and support the entire software delivery lifecycle with workflows covering development, security, and operations.
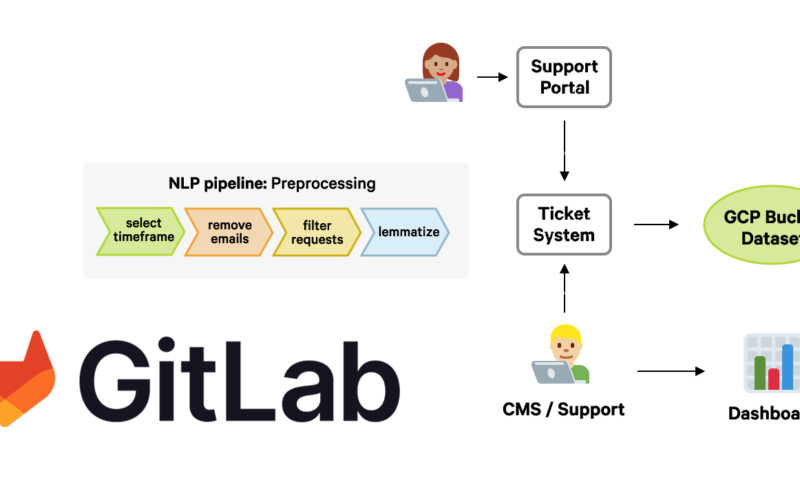
Every day, the GitLab team receives support tickets and usage questions via their internal support portal and third-party platforms like Stack Overflow. The team continuously analyzes the data to better serve the needs of their community. GitLab’s developer relations and education teams also use the data to determine the most useful content to create, to address common questions and use cases, and help developers use GitLab more efficiently.

GitLab’s system for analyzing support tickets and questions from different platforms features custom spaCy pipelines for preprocessing, removal of sensitive data, and information extraction. The analysis pipeline includes named entity recognition components augmented with rules, and custom components for their business logic and information extraction specific to GitLab’s products and features.
To process the tickets at scale and continuously as they come in, high inference speed and efficiency are important. The workflows need to be integrated into their internal CI/CD processes and re-run whenever needed, without having to worry about compute costs. Another vital step: All support tickets are anonymized using custom post-processing and matcher logic, and processed in a secure and hardened offline environment.
Our spaCy pipelines run on a secure virtual machine and are very easy to operationalize. Because they’re designed in a modular way, I can easily plug in custom components to combine and connect the existing predictions in different ways.
— William Arias, Staff Developer Advocate
Based on the structured information extracted from the tickets and questions, William isn’t only able to produce statistics and dashboards – he can also give the team concrete and actionable feedback that oftentimes they can apply immediately. For example, such feedback has helped provide better resources to the support team for solving user problems, or helped the developer relations team improve the documentation and decide which topics to cover in the GitLab University learning center.

Factoring out business logic
An important goal of the project was to build a solution that’s adaptable to new scenarios and business questions. For example, what problems do users report with the latest releases, how popular is an older version of the self-hosted platform, and are people adopting new features? And which topics could be documented better?
Instead of approaching those questions as separate machine learning tasks, William and the GitLab team first worked on identifying the general-purpose features they needed, like product names, versions, and topics, and separating them from the logic producing the insights. This way, simpler components can be added to analyze the data whenever new business questions come in, without having information that changes over time hard-coded in the model weights.
| General | Business logic | ||
|---|---|---|---|
| number | 15.6.8 |
GitLab version | GitLab 15 |
| URL | https://... |
GitLab docs | https://docs.gitlab.com/... |
Entity and topic analysis
For their analysis, William developed several custom pipeline components and patterns, for example, to associate tickets with different versions of the GitLab platform and track which versions users are on and report problems with.
Match patterns for versions and URLs
version_pattern = [{"LOWER": "gitlab"}, {"LIKE_NUM": True}]
url_pattern = [{"LIKE_URL": True}]
Additionally, spaCy is used to preprocess the ticket contents for unsupervised topic extraction, a simple yet very effective method to determine the most common themes and topics raised by users, find semantically related tickets and messages, and track how this information changes over time.

Interestingly, experiments showed that thanks to the ranking analysis and NLP pipeline, the system achieved similar and sometimes better results using only the question title, which also made processing even faster. This highlights the importance of iterating on a solution and having efficient workflows in place that allow the team to try out as many ideas as possible.
William has also published a more in-depth blog post on the operational process of analyzing Stack Overflow questions using GitLab’s platform and a Kubernetes cluster, extracting and visualizing the most common topics and taking into account other meta information like user reputation.

Pipelines in production
For the initial development, the team experimented with different time windows and processed different amounts of tickets. Once full automation is implemented, GitLab plans to make the tracking cadence monthly. To run the pipelines in production, GitLab uses 2 VMs, each with 8 vCPUs with 52 GB of RAM and an NVIDIA T4 GPU with an Intel Skylake processor on a deep learning Debian image.
spaCy lets me do a lot of optimization for the different things we want to find out. I can turn components on and off to only run what I need, which made the text preprocessing pipeline using spaCy 6× faster.
— William Arias, Staff Developer Advocate
While the pipelines produce a lot of useful structured information, this format isn’t always the best fit for communicating the results to different stakeholders. To provide human-readable summaries of the insights, William is exploring using a self-hosted open-source large language model (LLM) to create sentences out of the main topic keywords generated by the NLP pipeline, for example with the prompt:
Example prompt and response
Create a short, concise and to the point sentence based on
the following keywords:
['upgrade', 'migration', 'path', 'assistance']
Do not provide solutions. No need to use all the keywords.
LLM Response:
"Assistance is needed for the migration path during upgrade"
More iteration is currently planned to improve the prompt that generates these sentences. What makes this task more manageable and reliable is that there’s already a source of truth, the structured data. So all the model has to do is turn it into a sentence, which constrains the possible output and allows using a smaller and self-hosted LLM targeted at only this specific task.
Early on, William noticed that reviewing the data almost always turned up new edge cases and examples not previously covered well by the model. To work more closely with the data, he’s currently exploring Prodigy, a scriptable tool for data development and annotation that also integrates with spaCy out of the box. Tickets that come in via the internal support system are already sorted into pre-defined categories by the user, which the team can use to improve the model needed for uncategorized tickets. With Prodigy, data scientists can then evaluate how often the model agrees or disagrees with the human-assigned categories. The team also wants to use human-in-the-loop evaluation to improve their automated anonymization and ensure no sensitive information is left in the data.
Our support engineers have a lot of domain knowledge, which is very valuable. We want to include them in the development process and give them better tools so they can focus on what’s most important: supporting our community.
— William Arias, Staff Developer Advocate
Going forward, GitLab is continuing to enhance its features to help teams identify the impact and ROI of AI-assisted tools across their entire software delivery cycle, as well as automated root cause analysis for broken CI/CD pipelines by using AI to analyze failure logs.
For every new rollout, the analysis pipelines developed by William and his team are instrumental in understanding how GitLab’s users are adopting the new features and, most importantly, making sure they receive the best possible support along the way.
Resources
Source link
lol