
The momentum around data catalogs has never been higher than it is today. That said, it probably has never been more confusing to understand the changes and differences of each company and each product’s focus on how it delivers (and fails to deliver) at scale. The emergence of Apache Iceberg and the continued market consolidation for efficiencies and cost savings have left a number of executives reconsidering their previous make vs. buy decisions.
Historically, as a data leader in large enterprises, I realized that in order to break through the data and organizational silos, you have to address the technical challenges of catalogs that typically have required a full build strategy (rarely though open source even). Most organizations have too many platforms consuming, enriching, serving, and generally interacting with data. The list is long and it’s simply not realistic to expect that there are enough connectors in commercial catalogs to track the full lineage and provenance across them. Treating data as an asset requires tracking and understanding that asset over its lifecycle, including crossing platforms that may not integrate well, or at all. The emergence of Iceberg as a standard, including the flexibility of it to enable managing assets, has dramatically lowered the bar. But be warned, at a use case level, the daylight is now visible but it’s not solved yet and the finish line has yet to come into view.
Breaking Up the Data Catalog to Create an Enterprise Picture
I have presented at a number of conferences on going beyond basic governance and building an enterprise data strategy including catalogs. Every time, I use the below graphic to help break up the data catalog into four distinct functional areas: Business Terms & Glossary, Metadata Management (emphasizing the business level metadata here as a missing part in a lot of technology teams’ strategies), Integration & Messaging, and Discovery & Compliance.
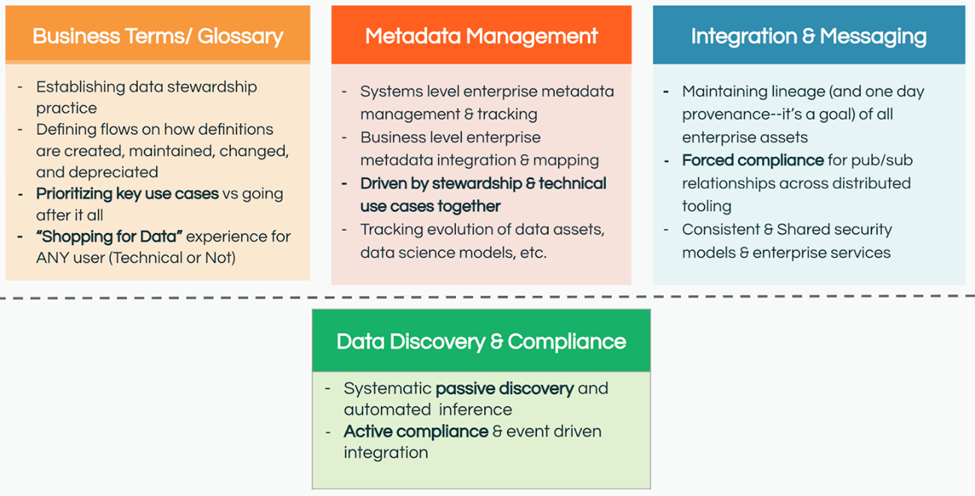
Classically, there has been an unfortunate split between business users and technology teams on understanding what problem data catalogs are solving. For technology teams, they mostly focus on metadata management and only look at integration as one directional consumption of technical metadata. Business users center their relationship with data catalogs around “shopping for data”. This shopping occurs through terms and glossaries: Searching to understand what data is available, its quality, ownership, and more. Those searches are not for column and table names, but rather the business terms and taxonomies tied to the problems the users are working on.
There is a dotted line separating discovery and compliance because this capability also crosses spectrums. First, it involves security teams performing bottom up registration and representation for spectrum level visibility of data across the enterprise. Second, the data teams worked to integrate these assets as they are registered. Then, platforms like Atlan have come up with more “active” metadata and have worked to incorporate advanced features for both terms and metadata management through active discovery and maturity processes. What teams discover is that it is a long and expensive process to marry these worlds, as the technology aspect is as difficult as the business side–especially when the outcomes are not aligned. The closer companies get, the quicker they find that scaling also depends on scaling the hiring of data and analytic engineers.
How Iceberg Takes the Heat Out of Traditional Data Catalog Challenges
So can Iceberg help solve all of these issues and challenges? Iceberg dramatically lowers the barrier on the technology side, making the equation more balanced and allows people and process to be the biggest challenge again. As noted above, the integration part of publishing/subscribing (“pub/sub”) data events across the enterprise to capture the lineage/provenance of data events becomes easier if those platforms natively use Iceberg format as well. 
We are already seeing the speed of support and commitment to Apache Polaris (Incubating) by customers, as well as technology providers trying to integrate and expand on this success. Thus, the data catalog space around metadata management is allowing data leaders to no longer be forced to do a full build of this platform component. Adoption of open source tools becomes a fast path to agnostic and speed to scale, as well as adoption and enablement of the rest of the ecosystem building their own connectors and support, creating a true win for all.
So, What’s Next?
Many organizations are either early in their journey or looking for a restart. After all, these new market developments have disrupted the previous paths available. Regardless of where the organization is in the process, there are a few tips to help get started:
- Look to Apache for Real Open Source. Some platforms claiming to be open source are still closed and run by single vendors who will consider your suggested enhancements but decide whether to accept them or not based on their own private reasoning.
- Think About Consumers and Work Backwards. To establish facts and to maintain them requires knowing the definition of those facts. Users are looking for facts when they look for data, or to get as close as possible so they can evolve those facts to their use cases. Those facts cross systems, change, etc., and may often do so concurrently. The old challenges of Survivorship Rules for Master Data Management (MDM) and similar practices get more complicated for any one system, so having a governance program is critical which brings me to the next consideration.
- Data Stewardship and Democratization: Enterprises have accepted that they cannot fully consolidate, so maturity now means integrations and ongoing management. In this case, establishing discipline on how facts are created, maintained and changed (i.e. contracts), and how data is supported or deprecated is critical. Having clear business and technical owners of data and presenting that in the catalog with the service commitments make the shopping experience easier, as well as clarify the relationship between creators and consumers.
In the end, the light that Iceberg has provided to the catalog space is the first that data leaders have seen in a long time. The promise of open specs, agnostic community open source support, and the momentum of technology companies behind Iceberg and emergent catalogs like Apache Polaris (incubating) is exciting since this has been a long time coming.
That said, creating an enterprise catalog strategy includes these capabilities, but they do not deliver an enterprise data catalog. Navigating the rest of the catalog that’s rapidly including entitlements or access services is another function that should be navigated with caution. For now, solving these problems is the immediate opportunity at hand, but consider the same recommendations of interoperability and switching cost risks.
About the author: Nik Acheson is Field Chief Data Officer at Dremio, the unified lakehouse platform for self-service analytics and AI. Nik is a business obsessed data & analytics leader with deep experience leading both digital and data transformations at massive scale in complex organizations, such as Nike, Zendesk, AEO, Philips, and more. Before joining Dremio, Nik was the Chief Data Officer at Okera (acquired by Databricks).
unified lakehouse platform for self-service analytics and AI. Nik is a business obsessed data & analytics leader with deep experience leading both digital and data transformations at massive scale in complex organizations, such as Nike, Zendesk, AEO, Philips, and more. Before joining Dremio, Nik was the Chief Data Officer at Okera (acquired by Databricks).
Related Items:
Dremio Unveils New Features to Enhance Apache Iceberg Data Lakehouse Performance
Snowflake Embraces Open Data with Polaris Catalog
Databricks Nabs Iceberg-Maker Tabular to Spawn Table Uniformity
Source link
lol