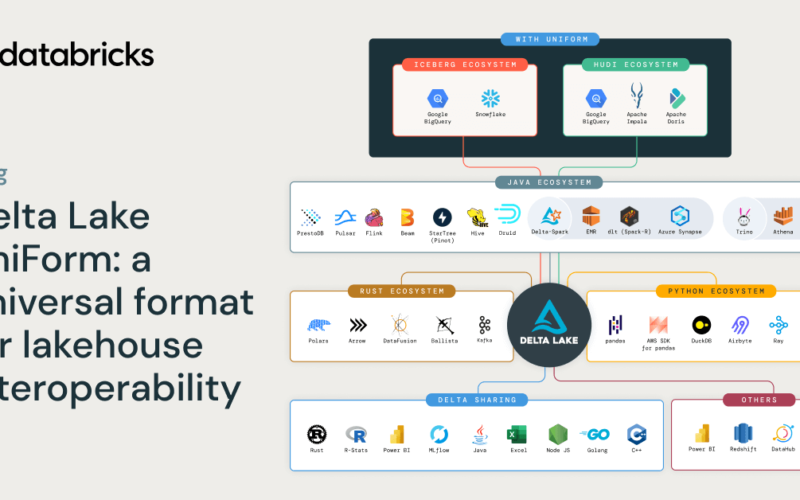
Delta Lake has proven to be the most popular and fastest lakehouse format over the years. Delta Lake Universal Format (UniForm), now available in GA, builds on Delta Lake’s rich connector ecosystem to combine Delta Lake’s superior price-performance with access to every tool in your stack. With Delta Lake UniForm, you can write a single copy of your data and make it available to any engine that supports any of the primary open table formats: Linux Foundation Delta Lake, Apache Iceberg, and Apache Hudi (coming soon). In this blog, we cover the following:
- Building the open data Lakehouse with Delta Lake UniForm
- Getting fast performance in any engine
- Using advanced Delta Lake features, like Liquid Clustering, with Delta Lake UniForm
Building the Open Lakehouse
Delta Lake offers a vibrant connector ecosystem with support from many popular open source frameworks and commercial engines. UniForm expands Delta Lake’s ecosystem by taking advantage of the inherent similarities among the 3 open table formats. Delta Lake, Iceberg, and Hudi all store data in the Apache Parquet file format but diverge in how they store additional metadata. Delta Lake UniForm generates Iceberg metadata alongside Delta Lake while maintaining a single copy of the Parquet files. By writing once to Delta Lake UniForm, you can access your data using any engine that supports any one of the open formats:
Delta Lake UniForm enables you to choose the best tool for your workload. With Delta Lake UniForm, you get the data flexibility to support any architecture you choose today or in the future.
Fast performance, everywhere
With more platforms embracing open table formats, you can write Delta Lake UniForm to access a broader range of tools without expensive data duplication. This provides greater flexibility and lower costs for data previously stored in a proprietary format. With Delta Lake UniForm, you can take advantage of Databricks’ best-in-class ingestion and ETL price-performance and connect with any data warehousing or BI tool in your stack. These cost savings can be realized without compromising on query performance downstream.
The benchmarks below compare performance ingesting Parquet files into Delta Lake UniForm using Databricks and into Iceberg using Snowflake.
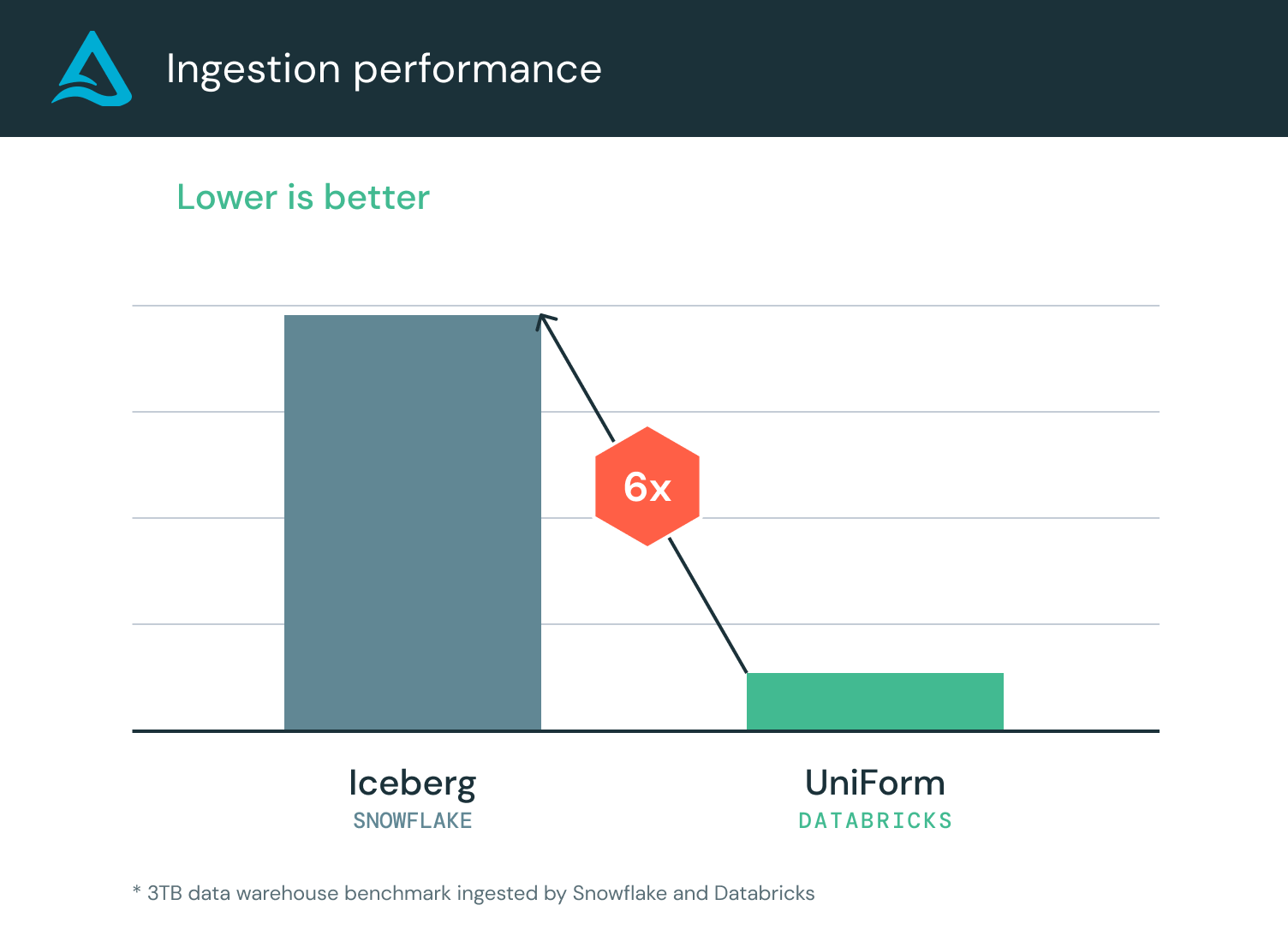
Databricks ingested Parquet 6x faster than Snowflake. Databricks was also 90% less expensive than Snowflake. Because Delta Lake UniForm writes both Delta and Iceberg metadata, the table remains accessible to Snowflake. In Snowflake, Delta Lake UniForm can be read using an Iceberg catalog integration. A catalog integration enables you to create an Iceberg table in Snowflake referencing an external Iceberg catalog or object storage. Benchmarks show that out-of-box read performance for Delta Lake UniForm is comparable to Snowflake managed Iceberg:
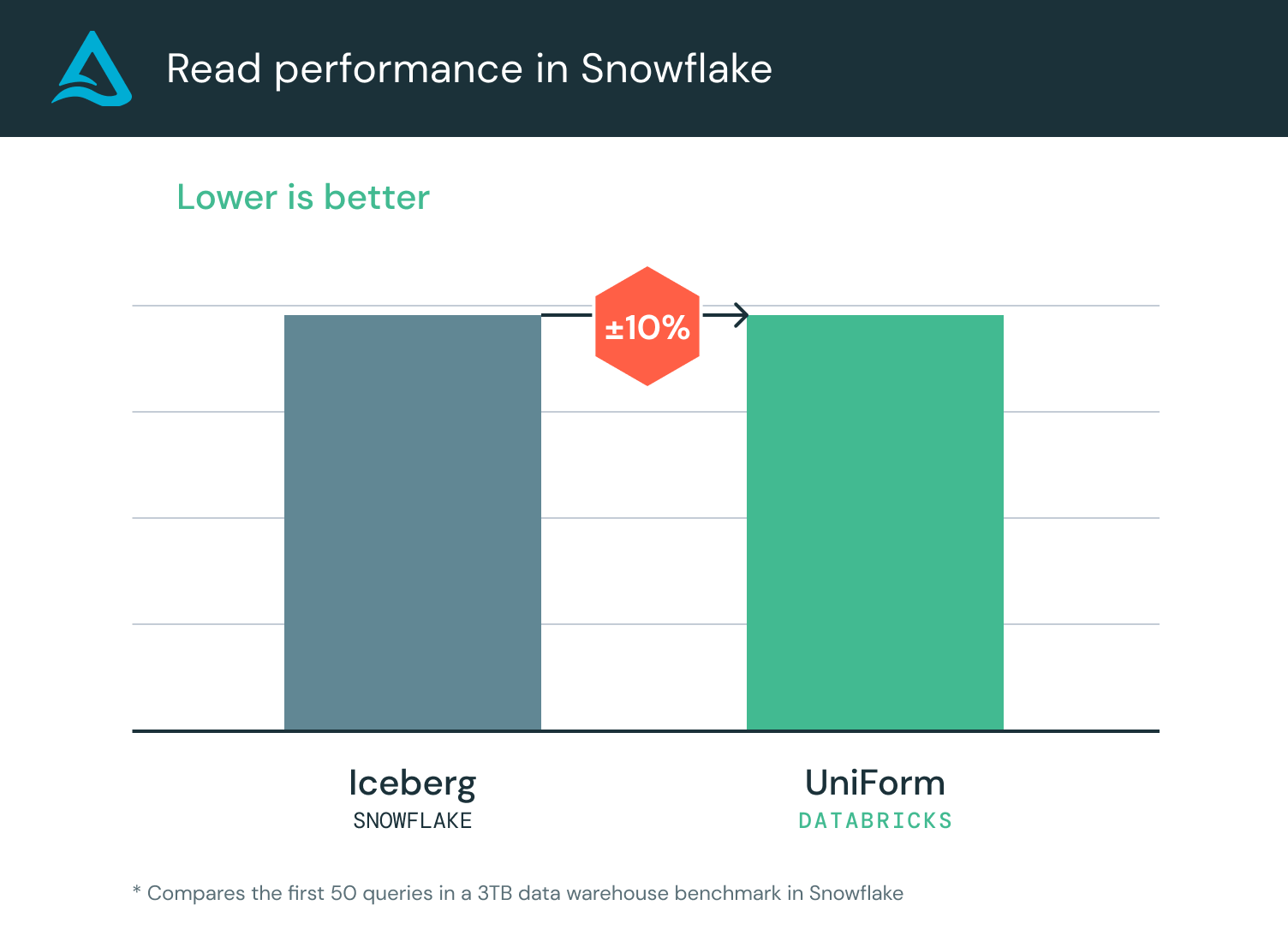
The difference in query performance is nearly zero! With Delta Lake UniForm, you get the fastest performance and universal connectivity all from a single copy of data in your own storage bucket!
With Delta Lake UniForm you get the best of all formats
When writing Delta Lake UniForm, you can continue to take advantage of Delta Lake’s advanced table features. For example, Delta Lake UniForm can now be enabled on Delta tables using Liquid Clustering, a new feature available in Public Preview. Liquid Clustering is an intelligent data management technique that dynamically clusters Delta tables, allowing data layout to evolve alongside analytics needs.
Together, Delta Lake UniForm and Liquid Clustering provide fast query performance even when reading from Iceberg or Hudi engines. This works because when Liquid Clustering optimizes the physical data layout, Delta Lake UniForm reflects these improvements in both Delta Lake and Iceberg metadata. Because Delta Lake UniForm is only writing additional metadata, there is negligible overhead on writes. Liquid also automatically clusters new data during ingestion, so query performance remains fast over time.
How customers are using Delta Lake UniForm
During Public Preview, organizations proved Delta Lake UniForm’s compatibility with popular Iceberg reader clients including Snowflake, BigQuery, Redshift, and Athena for a range of BI and analytics use cases.
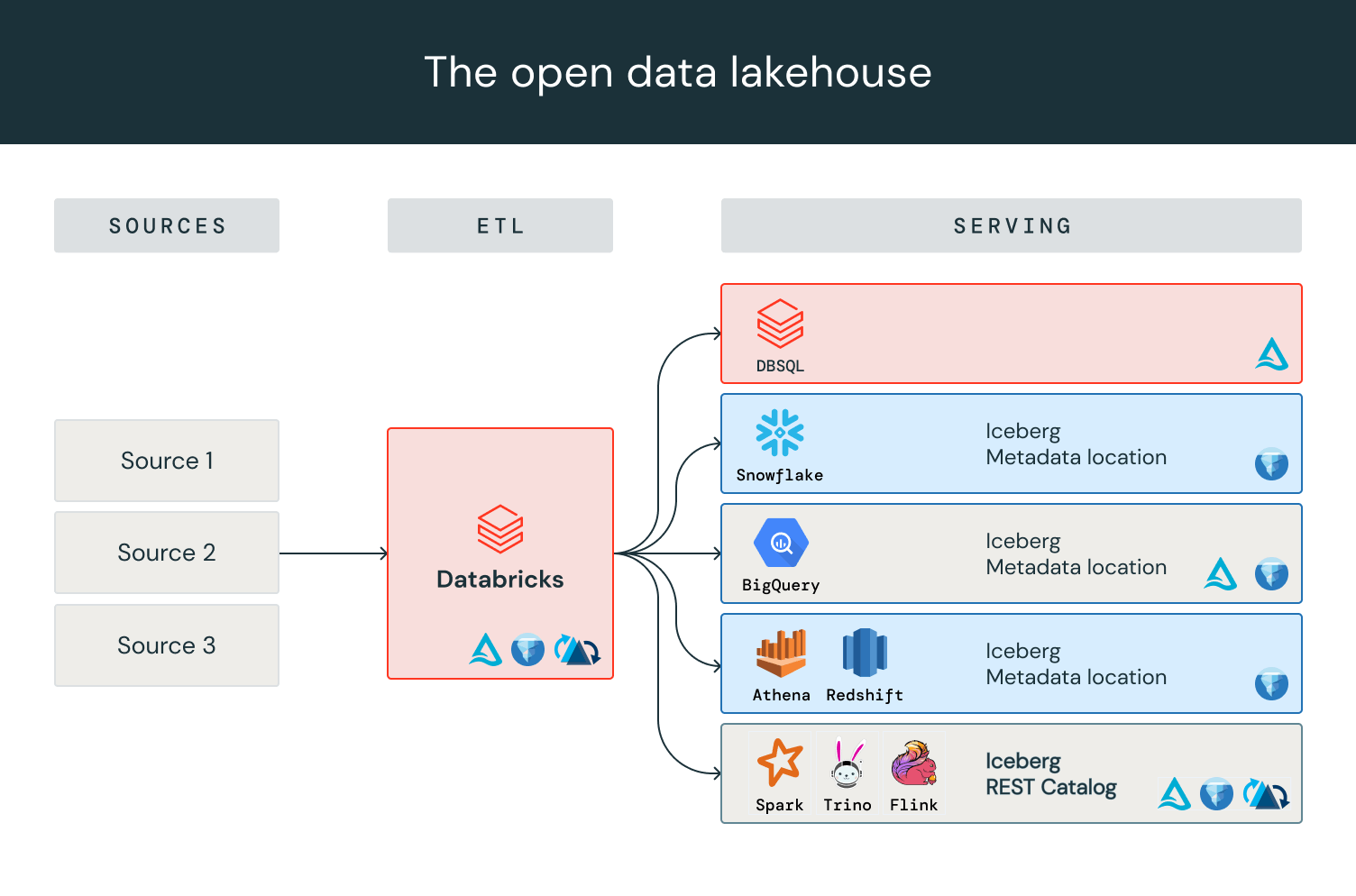
Now in GA, Delta Lake UniForm is ready for your production workloads. At Databricks, our customers have already started to see the benefits of writing UniForm:
At M Science, UniForm provides us with the flexibility to write a single copy of our data that can be queried by any engine that supports Delta or Iceberg – this is key to reducing costs and accelerating time-to-value
— Ben Tallman, Chief Technology Officer at M Science

We are excited to see customers and commercial vendors choose the open Lakehouse architecture for its simplicity, flexibility, and lower costs. Post GA, we will continue to invest in making Delta Lake UniForm more interoperable and seamless so that users can use any tool in their ecosystem.
New Delta Lake UniForm features are available as part of the Delta Lake 3.2 release. Databricks customers can use these features by upgrading to Databricks Runtime version 14.3.
You can learn more about how to read Delta Lake UniForm from your choice Iceberg reader in the links below:
Source link
lol