
Segmentation projects are the cornerstone of personalization in games. Personalization of the player experience helps maximize player engagement, mitigate churn and increase player spend. Personalization mechanisms come in many forms including next best offer, in-game store ordering, difficulty setting, matchmaking, signposting, marketing and reengagement. Ideally each player’s experience would be unique but this isn’t feasible. As an alternative, we group players across a series of data points and then personalize that group’s experience.
In this solution accelerator we first leverage an LLM to help determine the right number of clusters for a given dataset. We then use standard, explainable, machine learning techniques, like K-means clustering. Explainability is important so we can build trust in the clusters, and can understand why a decision was made for a specific player. Once our clusters are created, we leverage an LLM to describe them enabling interested parties to make use of them.
Heuristics versus ML based segmentation
Basic heuristic based segmentation is straightforward. Many game companies will do this and call it a day. Payer vs non-payer, logged in within the last two weeks, PVP vs PVE and the likes are easy to calculate, communicate and make use of but only scratch the surface. For personalization projects to be effective, deeper insight is needed. Understanding a group of player’s behavior, their play style, social engagement and interactions with content within the game provides insight needed to maximize their play experience.
Non-heuristic segmentation projects are hard, slow and time consuming. Clustering on a set of data points isn’t difficult. Making sense of those clusters, what they tell you and how to use them, however, is a challenging human-in-the-middle problem. We encounter teams spending weeks on a segmentation effort, ultimately canceling it, or taking 6 months only to find that the clusters are no longer meaningful. These outcomes occur because analysts have to determine what makes the generated clusters unique. They then have to describe what the cluster means and when to use it. To do this effectively the number of clusters has to be kept small (3-4) as finding differences between a larger set of segments is often nuanced. This can lead to overfitting, grouping dissimilar people, causing your personalization efforts to fall flat.
Why iteration matters in segmentation projects
To further complicate things your cluster makeup will change over time as a result of new game content, new audiences joining the game, changes enacted upon the economy, your audience changing its desires, or the game reaching a steady state. Segmentation projects are a continuous effort, one that needs optimization. Keeping up with that change when these projects require so much effort is a challenge for studios. Studios will therefore often segment once and use the segments longer than they are appropriate. By taking advantage of a modern approach you can further build upon your intuition.
Cluster feature evaluation
As you consider which features to use in your clustering, you will rely on your deep knowledge of your datasets, and players, and may leverage tools like a correlation matrix to minimize highly correlated features. As with determining the number of clusters to consider, you can leverage an LLM to make recommendations as a result of these data points and provide you input as to which features to keep, or remove from, your clustering.
Using a correlation matrix to filter features
It’s important to ensure that the features included aren’t causing overfitting, or noise within your clusters. We accomplish this by consulting a correlation matrix and eliminating features that are highly correlated to each other. As an example, let’s imagine a game where you earn and spend gold with different factions to improve your reputation and progress the game. As a player progresses within the game, they’re going to accumulate that gold. Gold accumulation therefore provides little more information than “time played” and little differentiation between players. Including gold accumulation, as a whole, will cause your players to start to look more similar, and it’s the differences you are looking for. What might be a better differentiator is with which faction they spent their gold. If you include total gold accumulated, total gold spent and gold spent per faction you’ll muddy your results. Taken further, it is likely more useful to consider how much gold was accumulated within each of your game loops. In addition to improving your output, this type of analysis can shrink the amount of processing needed and data points considered in your clusters. By optimizing in this way you will provide faster and more useful results.
We can manually look at the correlation matrix below and see what we learn from it. As this data is generated, the specific correlations don’t reflect reality and may be nonsense. Putting that aside, for the purpose of our clustering effort there’s two pieces of information we’re looking for: Which data points are unrelated to each other (closest to zero), which ones are most correlated and may muddy our clusters (closest to 1 or -1). As an aside: Seeing which ones are closest to 1 and -1 can provide interesting insight for your team, unrelated to segmentation. While this data is nonsense, imagine it weren’t. We would see in this matrix that the more we provide free premium credits, the less premium credits an individual purchases.
This is another example of where an LLM can help us find insight. When we ask the LLM to explain what we’re seeing above it pulls out some interesting things that we didn’t notice when reviewing ourselves. The below image shows the output in this specific case. By reading through it we see a few features where we should use one, or the other, but not both. The explanation also suggests that we leverage Aggressive Battles and Trade Transactions in our clusters as they are not correlated to other features. Finally we see an example of why including values is important, as the 3rd highly correlated feature isn’t really that correlated!

We’re now ready to cluster your dataset. There are many clustering models out there, but more often than not K-Means is used. Whatever model is used, it is important to choose one that is explainable.
Determining the right number of clusters
As you cluster your players based on the features that you chose above you need to determine the number of clusters you should have. You will run your clustering with 2, 3, 4, 5, etc. to find the best number for your data. For this we leverage the Silhouette method, explained further in the solution accelerator. As the data we’ve used is generated data, the Silhouette score, and elbow, are highly pronounced. Your output may look quite different. The goal is to get your Silhouette Score as close to 1 as your data will allow, you may have to iterate on which features you’ve added, or not added to your clustering effort.
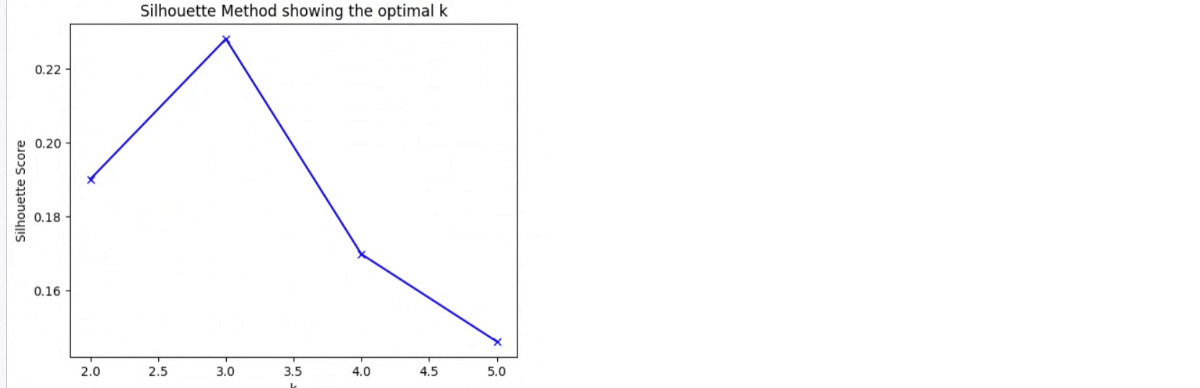
Populations can be complex and you could be looking at 20 or more figures attempting to determine the optimal number of clusters. By using an LLM to help with this, you have a programmatic and scalable way to make this decision. You can always override the LLM’s decision if you have external insight to add. Imagine you wanted to cluster players who have played for <30 days, 30-120, and 120+ to see how they differ. While we could guess, and put 3 clusters in each group, we could leverage an LLM to assist. Doing so we may find that 4, 2 and 3 are the right number of clusters. Once again the LLM has helped free analysts to focus on other tasks.
You may find that your clusters are not coming together, perhaps because too many unrelated features are being considered. There are many approaches to consider and this is where iteration begins. You may re-evaluate the features included in your model, or consider creating multiple sets of clusters focused on narrower datasets can help. Another thing to evaluate is whether creating (sub)segments inside of a larger segment would help. For example, taking a well defined segment such as Paying Customer, leaving out non-payers, and segmenting just your payers.
We have iterated and are comfortable with our clusters, it is time to define your clusters. To make these clusters useful we need to be able to understand what the clusters mean, and how its members were determined. In our notebook we output the metrics and metadata output into a Delta Table.
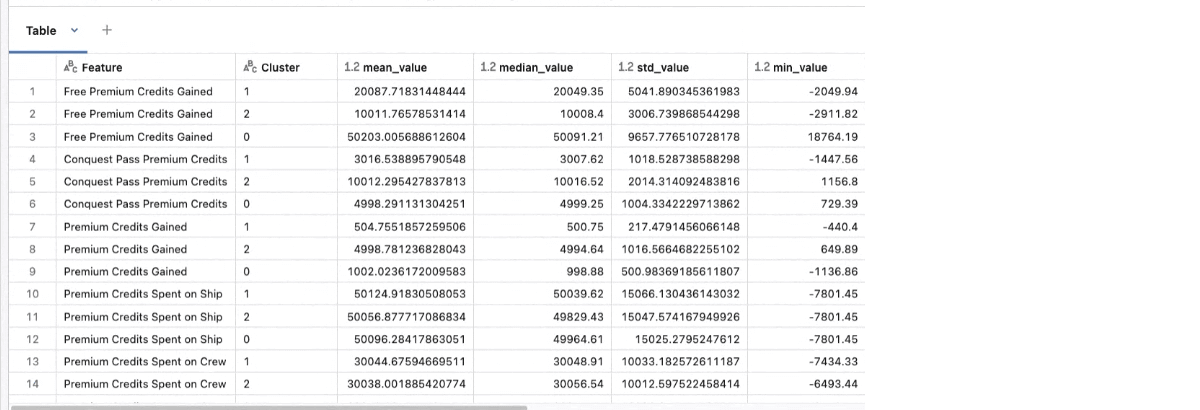
We might then use box plots looking at the metrics to find patterns in that data. Finding those patterns across 40 box plots can be hard on the eyes and time consuming. As such, we take an LLM and have it summarize the information found in the table and make our lives easier.

The introduction of LLMs as a way to streamline human-in-the-middle analysis is an exciting development for game analytics. By automating elements of your analytics pipeline with LLMs you are able to augment your data team, accelerate your time to value for analytics projects and provide your team more time to work on additional high value projects. This is just one example of a use case that can benefit from the combination of traditional machine learning and Generative AI. This approach can be applied within any workflow where optimization and application of well-known heuristics is useful. You may even have other techniques in your workflow that could be automated using the same approach.
We hope this blog will inspire you to ask: How could GenAI help us with other projects? For further details on how to take advantage of this approach, and see how easy it is to improve your personalization projects, check out our solution accelerator here. If you’d like to learn more about what we’re doing with game companies to better serve their players, explore this, or another use case please reach out to your account team. We look forward to collaborating with you and helping bring more play to the world.
Ready for more game data + AI use cases?
Download our Ultimate Guide to Game Data and AI. This comprehensive eBook provides an in-depth exploration of the key topics surrounding game data and AI, from the business value it provides to the core use cases for implementation. Whether you’re a seasoned data veteran or just starting out, our guide will equip you with the knowledge you need to take your game development to the next level.
Source link
lol