
Recommender systems (RecSys) have become an integral part of modern digital experiences, powering personalized content suggestions across various platforms. These sophisticated systems and algorithms analyze user behavior, preferences, and item characteristics to predict and recommend items of interest. In the era of big data and machine learning, recommender systems have evolved from simple collaborative filtering approaches to complex models that leverage deep learning techniques.
It can be challenging to scale these recommender systems, especially when dealing with millions of users or thousands of products. To do so requires finding a balance between cost, efficiency, and accuracy. A common approach to address this scalability issue involves a two-stage process: an initial, efficient “broad search” followed by a more computationally intensive “narrow search” on the most relevant items. For example, in movie recommendations, an effective model might first narrow the search space from thousands to about 100 items per user, and then apply a more complex model for precise ordering of the top 10 recommendations. This strategy optimizes resource utilization while maintaining recommendation quality, addressing scalability challenges in large-scale recommendation systems.
Many companies don’t have the resources to build and scale recommender systems of this size, but Databricks offers all the essential components — including data processing, feature engineering, model training, monitoring, governance and serving — that can be combined to create a state-of-the-art recommender system, as well as the technical support resources to help implement them. This article is the first in a series designed to demonstrate effective techniques for training and deploying recommendation models at scale on Databricks. In this installment, we focus on distributed data loading and training. Subsequent articles will explore distributed checkpointing, inference, and the integration of complementary components, such as vector stores, to create a robust, end-to-end recommender system pipeline.
This article presents a suite of reference solutions that serve as a robust foundation for training enterprise-scale recommender systems on the Databricks Data Intelligence Platform. These solutions use Mosaic Streaming as the dataloader and TorchDistributor as the orchestrator for distributed training, both of which were developed in-house at Databricks. By using TorchRec, a highly scalable recommender system package leveraging PyTorch, we showcase implementations of two advanced deep learning models that align with the two-stage approach mentioned earlier: the Two Tower model, ideal for the efficient “broad search” phase, and Meta’s DLRM (Deep Learning Recommendation Model), suited for the more intensive “narrow search” phase. Both models are capable of handling millions of users and items efficiently, with the Two Tower model quickly narrowing down the candidate set from potentially millions to thousands, and DLRM providing precise ordering of the most relevant items. To facilitate seamless integration into your workspaces and projects, we’ve made these models available through the Databricks marketplace.
Two Tower
The Two Tower model is an efficient architecture for large-scale recommender systems. As illustrated in the diagram, it comprises two parallel neural networks: the “query tower” for users and the “candidate tower” for products. Each tower processes its input (User ID or Product ID) to generate dense embeddings, representing users and products in a shared space. The model predicts user-item interactions by computing the similarity between these embeddings using a dot product, enabling quick identification of potentially relevant items from a vast catalog. This makes it ideal for the initial “broad search” phase in recommendation systems.
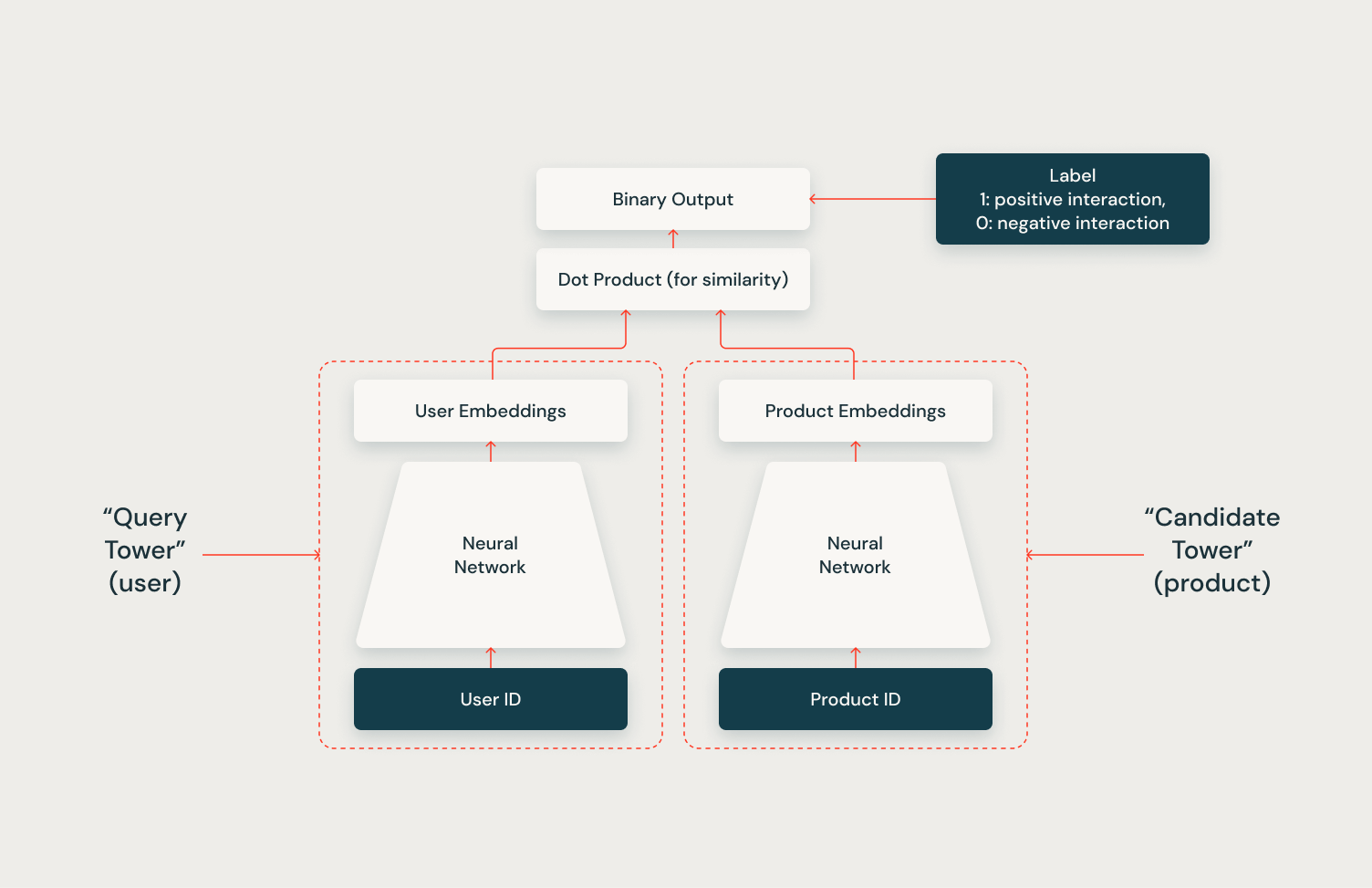
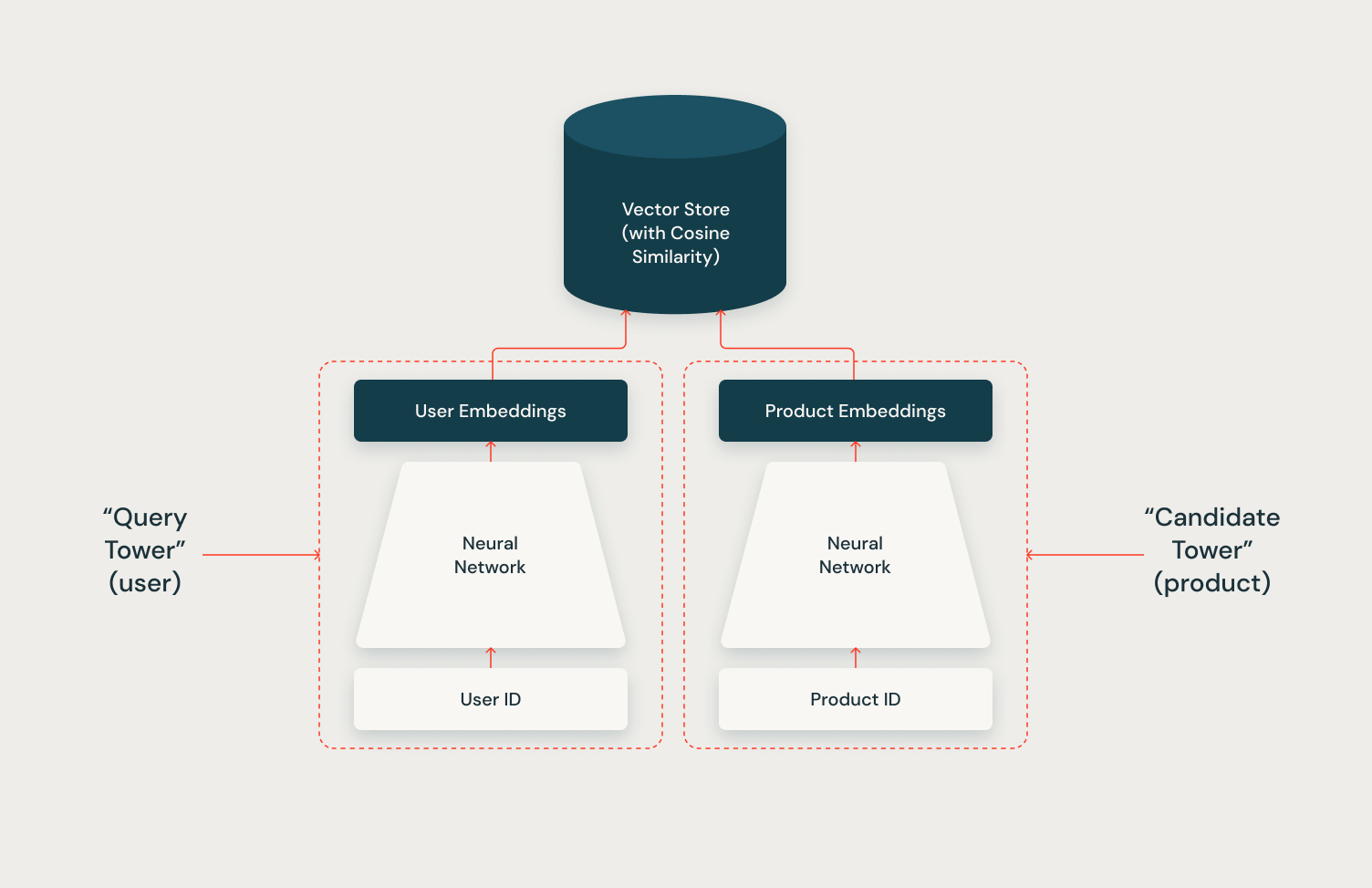
The Two Tower architecture’s full potential is realized through its integration with a vector store. By leveraging a vector store to index candidate vectors, the system can efficiently and scalably retrieve hundreds of relevant candidates for each user during inference. In a future article in this series, we will demonstrate how to implement this integration using the Mosaic AI Vector Store and the Two Tower model, showcasing the power of this combined approach.
DLRM
The Deep Learning Recommendation Model (DLRM) by Meta, as illustrated in the following diagram, is a sophisticated architecture designed for large-scale recommendation systems. It efficiently handles both categorical (sparse) and numerical (dense) features, making it highly versatile for various recommendation tasks. The model uses lookup tables to embed categorical features, and these embeddings, along with numerical features are then processed through a feature interaction layer. This layer captures complex relationships between different feature types. The combined features are then fed into a neural network, which further processes the information to generate the final output. This output can be used for various tasks such as regression or multi-class classification, depending on the specific recommendation problem, but is most often used for predicting click-through rates. The DLRM’s ability to handle diverse feature types and capture intricate feature interactions makes it particularly effective in the “narrow search” phase for precise item ranking in recommendation systems.

For production-level DLRM model training, we recommend leveraging the Databricks Feature Store. This powerful tool enables the seamless creation of training datasets with diverse feature arrangements for both users and items. While the current Databricks documentation provides examples for simpler recommender systems, a future article in this series will demonstrate how to integrate the Databricks Feature Store with the models discussed here.
How to Train a Recommendation Model
Both examples of training recommendation models share a similar overall structure, employing state-of-the-art techniques for large-scale distributed training.
Data Preprocessing and Data Loading with Mosaic Streaming
The examples in these stages leverage Mosaic Streaming, an essential tool for optimizing the training process on large datasets stored in cloud environments. This approach maximizes efficiency, cost-effectiveness, and scalability. When training large recommender systems, particularly those that need to accommodate millions of users and/or items, multi-node training is often necessary. However, distributed data loading introduces a range of challenges, including synchronization issues, memory management, and reproducibility across runs.
Mosaic Streaming is purpose-built to address these challenges. It’s specifically designed to support multi-node, distributed training of large models, with a focus on ensuring correctness guarantees, optimizing performance, providing flexibility, and enhancing ease-of-use. By tackling these critical aspects, Mosaic Streaming enables seamless scaling of recommender systems while mitigating the common pitfalls associated with distributed training environments.
The preprocessing stage involves several steps:
- Collecting training data from a table in Unity Catalog
- Performing necessary data transformations
- Utilizing Mosaic Streaming’s dataframe_to_mds API to materialize the processed data into a Unity Catalog Volume
def save_data(df, output_path, label, num_workers=40):
print(f"Saving {label} data to: {output_path}")
mds_kwargs = {'out': output_path, 'columns': columns, 'compression': compression}
dataframe_to_mds(df.repartition(num_workers), merge_index=True, mds_kwargs=mds_kwargs)
save_data(train_df, output_dir_train, 'train')
save_data(validation_df, output_dir_validation, 'validation')
save_data(test_df, output_dir_test, 'test')We then use Mosaic AI StreamingDataset and StreamingDataLoader APIs in our training function to easily load the relevant data for each node in a distributed environment. Note that StreamingDataLoader is required if you need mid-epoch resumption. If that’s not needed, using the native Torch DataLoader is fine as well!
def get_dataloader_with_mosaic(path, batch_size, label):
print(f"Getting {label} data from UC Volumes")
dataset = StreamingDataset(local=path, shuffle=True, batch_size=batch_size)
return StreamingDataLoader(dataset, batch_size=batch_size)
train_dataloader = get_dataloader_with_mosaic(input_dir_train, args.batch_size, "train")
val_dataloader = get_dataloader_with_mosaic(input_dir_validation, args.batch_size, "val")
test_dataloader = get_dataloader_with_mosaic(input_dir_test, args.batch_size, "test")Parallelizing Model Training with TorchRec and the TorchDistributor
Recommender systems that need to scale to millions of users or items can become overwhelming for a single node to handle. As a result, scaling to multiple nodes often becomes necessary for training these large deep recommendation models. To address this challenge, solutions leverage a combination of PyTorch’s TorchRec library and PySpark’s TorchDistributor to efficiently scale recommendation model training on Databricks.
TorchRec is a domain-specific library built on PyTorch, aimed at providing the necessary sparsity and parallelism primitives for large-scale recommender systems. A key feature of TorchRec is its ability to efficiently shard large embedding tables across multiple GPUs or nodes using the DistributedModelParallel and EmbeddingShardingPlanner APIs. Notably, TorchRec has been instrumental in powering some of the largest models at Meta, including a 1.25 trillion parameter model and a 3 trillion parameter model.
Complementing TorchRec, TorchDistributor is an open source module integrated into PySpark that facilitates distributed training with PyTorch on Databricks. It is designed to support all distributed training paradigms offered by PyTorch, such as Distributed Data Parallel and Tensor Parallel, in various configurations, including single-node multi-GPU and multi-node multi-GPU setups. Additionally, it provides a minimal API that allows users to execute training on functions defined within the current notebook or using external training files. An example usage of the TorchDistributor is as follows:
from pyspark.ml.torch.distributor import TorchDistributor
import torch.distributed as dist
import os
def main():
# basic setup of relevant variables
local_rank = int(os.environ["LOCAL_RANK"])
global_rank = int(os.environ["RANK"])
device = torch.device(f"cuda:{local_rank}")
torch.cuda.set_device(device)
# initializing process group
dist.init_process_group(backend="nccl")
# TRAINING LOOP USING `device` as the GPU to attribute to
# cleaning up process group
dist.destroy_process_group()
# optional output to return
return output
# this arrangement uses 8 GPUs on your databricks cluster for distributed training
output = TorchDistributor(num_processes=8, use_gpu=True, local_mode=False)The combination of TorchRec and the TorchDistributor enables the efficient handling of massive datasets and complex models typical in enterprise-grade recommendation systems.
Logging with MLflow
In the reference solutions provided, we use MLflow to log key items, like model hyperparameters, metrics, and the model’s state_dict. Note that while the approach taken in the example notebooks collects the distributed model onto one node before saving to MLflow, this wouldn’t work for models that are too big to fit on one node. To address this issue, the next article in this series will go into detail on how to do distributed model checkpointing and large-scale model inference on Databricks.
Next Steps
In this article, we introduced reference solutions for how to implement and train highly scalable deep recommendation models on Databricks. We briefly discussed the Two Tower architecture, the DLRM architecture and where they fit inside the extended recommender system pipeline. Finally, we delved into the specifics of distributed data loading and distributed model training of these recommendation models on Databricks. This is just the start: in future articles in this series, we will discuss additional aspects of productionizing recommender systems, including distributed model saving, inference, and integration with other tools on Databricks.
Source link
lol