
We’re excited to announce that looping for Tasks in Databricks Workflows with For Each is now Generally Available! This new task type makes it easier than ever to automate repetitive tasks by looping over a dynamic set of parameters defined at runtime and is part of our continued investment in enhanced control flow features in Databricks Workflows. With For Each, you can streamline workflow efficiency and scalability, freeing up time to focus on insights rather than complex logic.
Looping dramatically improves the handling of repetitive tasks
Managing complex workflows often involves handling repetitive tasks that require the processing of multiple datasets or performing multiple operations. Data orchestration tools without support for looping present several challenges.
Simplifying complex logic
Previously users often resorted to manual and hard to maintain logic to manage repetitive tasks (see above). This workaround often involves creating a single task for each operation, which bloats a workflow and is error-prone.
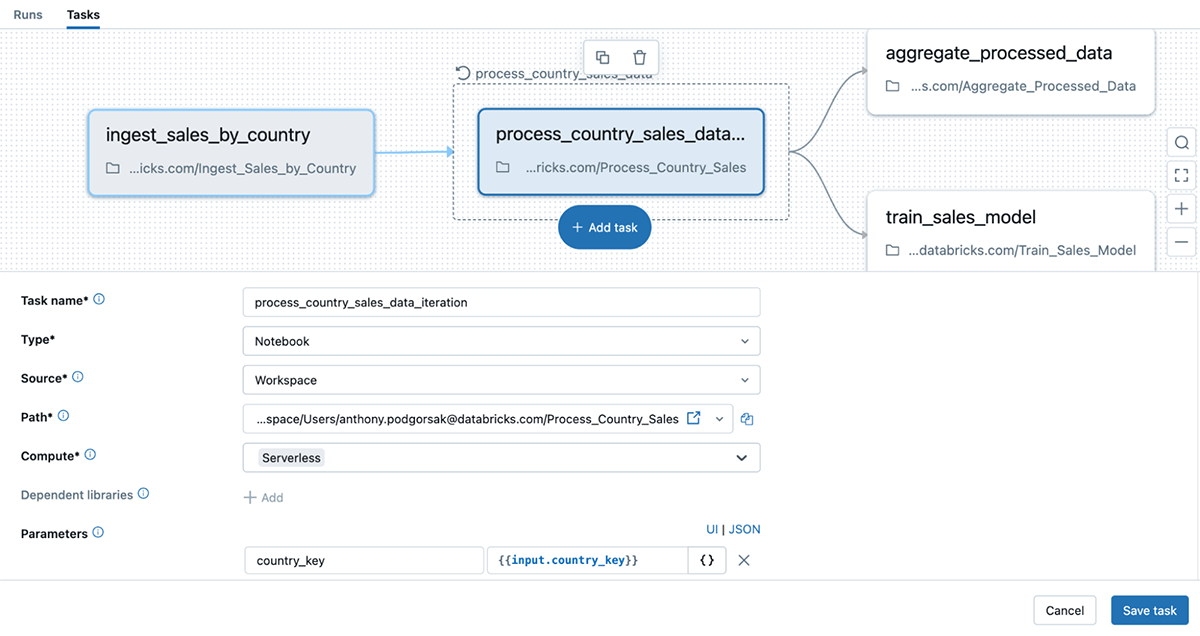
With For Each, the complicated logic required previously is greatly simplified. Users can easily define loops within their workflows without resorting to complex scripts to save authoring time. This not only streamlines the process of setting up workflows but also reduces the potential for errors, making workflows more maintainable and efficient. In the following example, sales data from 100 different countries is processed before aggregation with the following steps:
- Ingesting sales data,
- Processing data from all 100 countries using For Each
- Aggregating the data, and train a sales model.
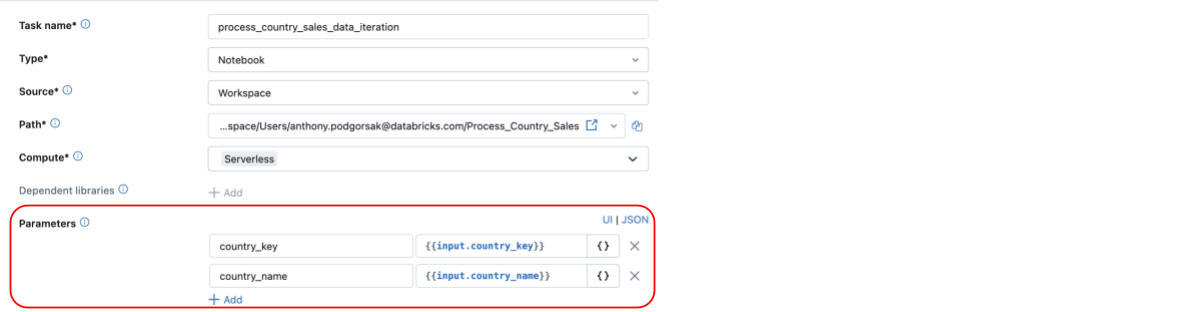
Enhanced flexibility with dynamic parameters
Without For Each, users are limited to scenarios where parameters do not change frequently. With For Each, the flexibility of Databricks Workflows is significantly enhanced via the ability to loop over fully dynamic parameters defined at runtime with task values, reducing the need for hard coding. Below, we see that the parameters of the notebook task are dynamically defined and passed into the For Each loop (you may also notice it’s utilizing serverless compute, now Generally Available!).
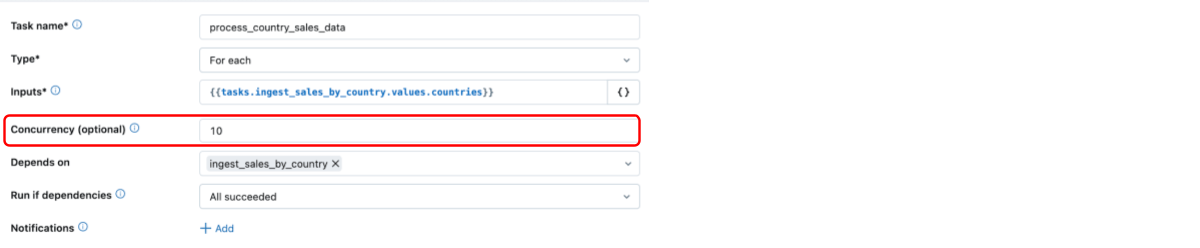
Efficient processing with concurrency
For Each supports truly concurrent computation, setting it apart from other major orchestration tools. With For Each, users can specify how many tasks to run in parallel improving efficiency by reducing end to end execution time. Below, we see that the concurrency of the For Each loop is set to 10, with support for up to 100 concurrent loops. By default, the concurrency is set to 1 and the tasks are run sequentially.
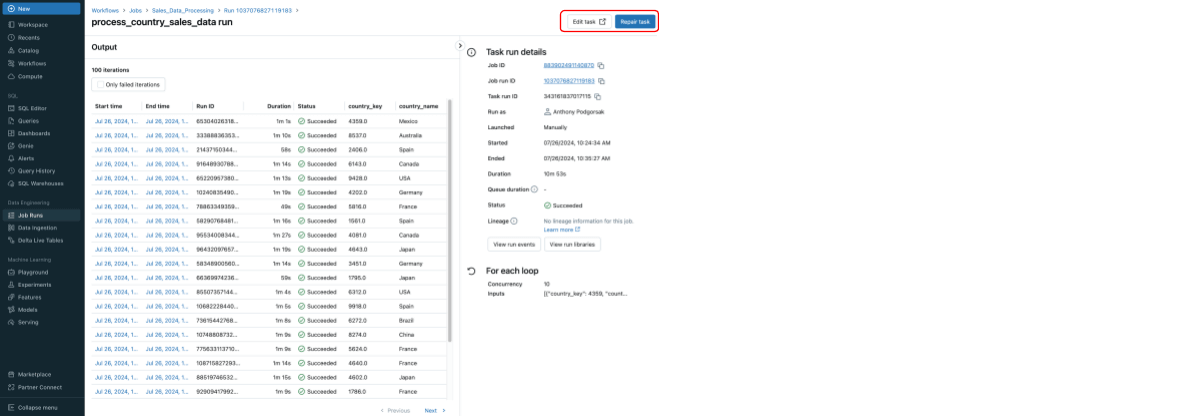
Debug with ease
Debugging and monitoring workflows become more difficult without looping support. Workflows with a large number of tasks can be difficult to debug, reducing uptime.
Supporting repairs within For Each makes debugging and monitoring much smoother. If one or more iterations fail, only the failed iterations will be re-run, not the entire loop. This saves both compute costs and time, making it easier to maintain efficient workflows. Enhanced visibility into the workflow’s execution enables quicker troubleshooting and reduces downtime, ultimately improving productivity and ensuring timely insights. Below shows the final output of the example above.
These enhancements further expand the wide set of capabilities Databricks Workflows offers for orchestration on the Data Intelligence Platform, dramatically improving the user experience, making customers workflows more efficient, flexible, and manageable.
Get started
We are very excited to see how you use For Each to streamline your workflows and supercharge your data operations!
To learn more about the different task types and how to configure them in the Databricks Workflows UI please refer to the product docs
Source link
lol