
Artificial intelligence training data provider Scale AI Inc., which serves the likes of OpenAI and Nvidia Corp., today published the results of its first-ever SEAL Leaderboards.
It’s a new ranking system for frontier large language models based on private, curated and unexploitable datasets that attempts to rate their capabilities in common use cases, such as generative AI coding, instruction following, math and multilinguality.
The SEAL Leaderboards show that OpenAI’s GPT family of LLMs ranks first in three of the four initial domains it’s using to rank AI models, with Anthropic PBC’s popular Claude 3 Opus grabbing first place in the fourth category. Google LLC’s Gemini models also did well, ranking joint-first with the GPT models in a couple of the domains.
Scale AI says it created the SEAL Leaderboards because of the lack of transparency around the performance of AI, in a world where there are now hundreds of LLMs available for companies to use. The rankings were developed by Scale AI’s Safety, Evaluations, and Alignment Lab and claim to maintain neutrality and integrity by refusing to divulge the nature of the prompts it uses to evaluate LLMs.
The company notes that though there are other efforts to rank LLMs, such MLCommons’ benchmarks and Stanford HAI’s transparency index, its expertise in AI training data means it’s uniquely positioned to overcome some challenges faced by AI researchers. These include problems around the lack of high-quality evaluation datasets that aren’t contaminated, inconsistent reporting of evaluations, the unverified expertise of evaluators and the lack of adequate tooling to properly understand evaluation results. For instance, Scale AI points out that MLCommon’s benchmarks are publicly available, so companies might train their models specifically to respond accurately to the prompts they use.
SEAL has developed private evaluation datasets to maintain the integrity of its rankings, and its tests are said to be created by verified domain experts. Moreover, both the prompts used and the rankings given are carefully evaluated to ensure trustworthiness, while transparency is ensured by publishing a clear explanation of the evaluation methodology used.
Scale AI said that in the Scale Coding domain, each model was compared with every other model in the evaluation on a randomly selected prompt, at least 50 times to ensure the accuracy of the results. The Coding evaluation attempts to assess each model’s ability to generate computer code, and the leaderboard shows that OpenAI’s GPT-4 Turbo Preview and GPT-4o models came in joint-first with Google’s Gemini 1.5 Pro (post I/O).
They are ranked joint first because Scale AI only claims a 95% confidence in its evaluation scores, and there was very little difference among the top three. That said, GPT-4 Turbo Preview appears to have a slight edge, generating a score of 1155, with GPT-4o coming second with 1144 and Gemini 1.5 Pro (Post I/O) earning 1112 points.
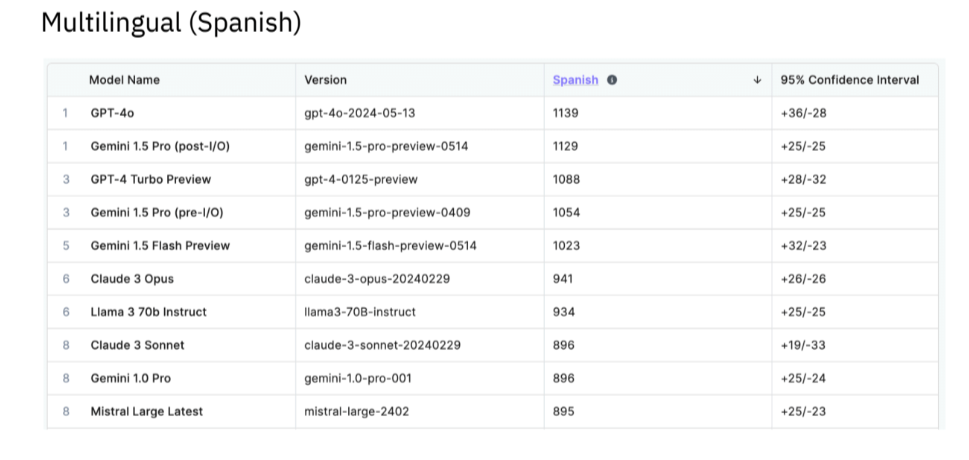
In the Multilingual domain, GPT-4o and Gemini 1.5 Pro (Post I/O) shared first place, with scores of 1139 and 1129, respectively, followed by GPT-4 Turbo and Gemini Pro 1.5 (Pre I/O) sharing third place.
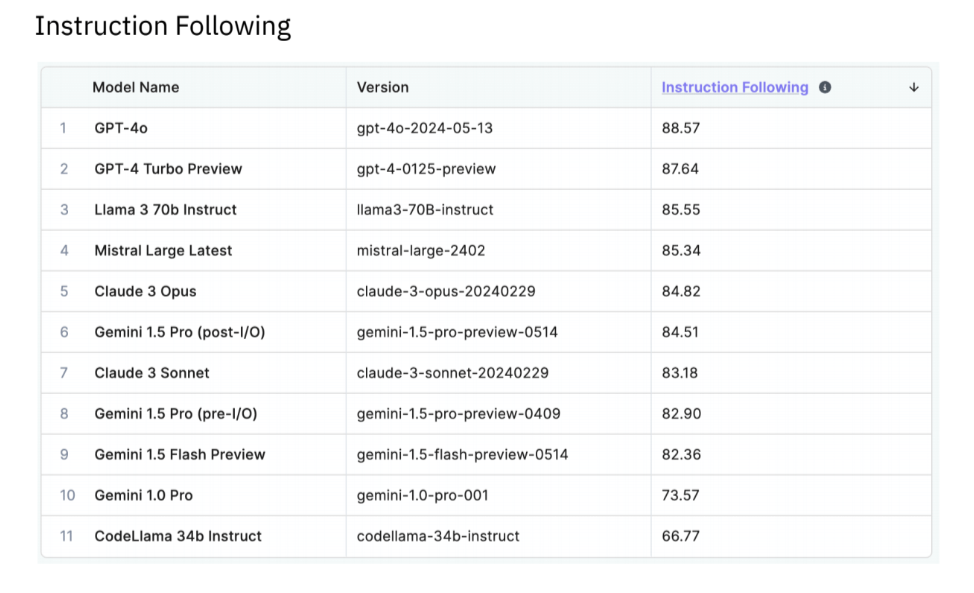
GPT-4o also came out on top in the Instruction Following domain, registering a score of 88.57, with GPT-4 Turbo Preview claiming second at 87.64. The results suggest Google still has some work to do in this area, because OpenAI’s closest competitors were Meta Platforms Inc.’s open-source Llama 3 70b Instruct, with a score of 85.55, and Mistral’s Mistral Large Latest LLM, which recorded a score of 85.34.
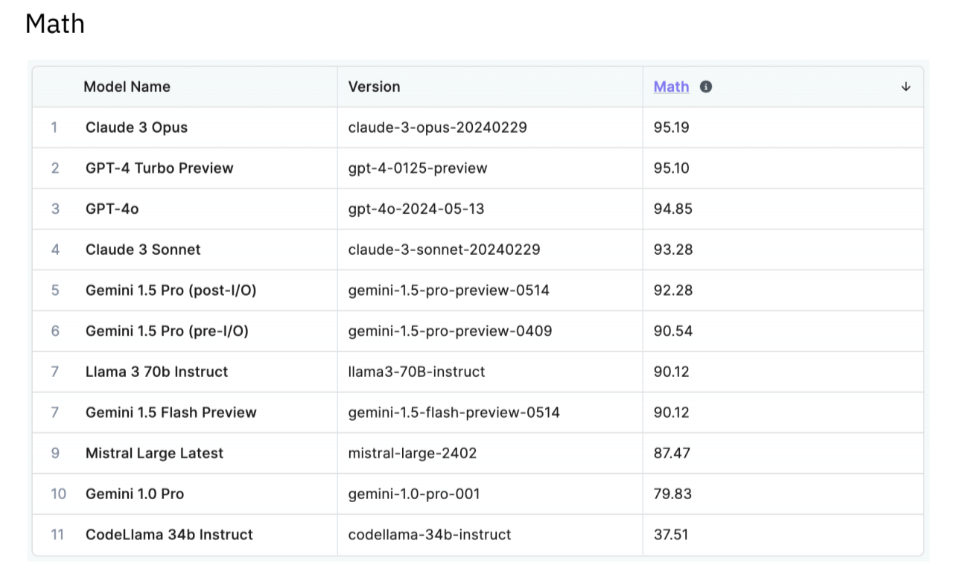
Finally, Scale AI tested the LLMs on their Math abilities. Anthropic’s Claude 3 Opus proved to be top dog, with a 95.19 score, enough to give it an undisputed first place, ahead of GPT-4 Turbo Preview at 95.10 and GPT-4o, which achieved 94.85.
The comparisons are interesting, but it seems they don’t yet tell the full story, as there are plenty of high-profile LLMs that appear to have been left out of the evaluations. For instance, AI21 Labs Inc.’s Jurassic and Jamba and Cohere Inc.’s Aya and Command LLMs are notably absent from all four of the assessments, as are the Grok models built by Elon Musk’s generative AI startup xAI Corp.
The good news is that Scale AI may address the incompleteness of the SEAL Leaderboards. It says it intends to update its rankings multiple times a year to ensure they’re kept up to date. It will add new frontier models “as they become available.” In addition, it plans to add new domains to the leaderboards, as it bids to become the most trusted third-party evaluator of LLMs.
Featured image: SiliconANGLE/Microsoft Designer
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
THANK YOU
Source link
lol