
All the code is available in this GitHub repository.
Introduction
Synchronizing data from external relational databases like Oracle, MySQL, or a data warehouse into the Databricks Data Intelligence Platform is a common use case. Databricks offers multiple approaches ranging from LakeFlow Connect’s simple and efficient ingestion connectors to Delta Live Tables’ (DLT) flexibility with APPLY CHANGES INTO statement, which accepts change data capture (CDC) input datasets. Previously, in “Simplifying Change Data Capture with Databricks Delta Live Tables“, we described how DLT pipelines enable you to develop scalable, reliable, and low-latency data pipelines to perform CDC processing in your data lake with the minimum required computation resources and automatic out-of-order data handling.
However, while LakeFlow Connect and DLT APPLY CHANGES INTO work seamlessly with databases that can provide a change data feed (CDF) to stream changes from, there are environments and systems where a CDF stream is not available. For these sources, you can compare snapshots to identify changes and process them. In this blog, we will show you how to implement SCD Type 1 and SCD Type 2 in Databricks Delta Live Tables using table snapshots.
Understanding Slowly Changing Dimensions
Slowly changing dimensions (SCD) refers to the unpredictable and sporadic change of data across certain dimensions over time. These changes can result from correcting an error in the data or can represent a true update and value change in that particular dimension, such as customer location information or product detail information. A classic example is when a customer moves and changes their address.
When working with data, it is critical to ensure that changes are accurately reflected without compromising data consistency. The decision to overwrite old values with new ones or capture changes while keeping historical records can significantly impact your data pipelines and business processes. This decision depends heavily on your specific business requirements. To address different use cases, there are various types of Slowly Changing Dimensions (SCD). This blog will focus on the two most common ones: SCD Type 1, where the dimension is overwritten with new data, and SCD Type 2, where both new and old records are maintained over time.
What are snapshots and why do they matter?
Snapshots represent a stable view of the data at a specific point in time and can be explicitly or implicitly timestamped at a table or file level. These timestamps allow the maintenance of temporal data. A series of snapshots over time can provide a comprehensive view of the business’s history.
Without tracking the history of records, any analytical report built on old records will be inaccurate and can be misleading for the business. Thus, tracking the changes in dimensions accurately is crucial in any data warehouse. While these changes are unpredictable, comparing snapshots makes it straightforward to track changes over time so we can make accurate reports based on the freshest data.
Efficient Strategies for RDBMS Table Snapshots Management: Push vs. Pull
Push-Based Snapshots: Direct and Efficient
The Push-Based approach involves directly copying the entire content of a table and storing this copy in another location. This method can be implemented using database vendor-specific table replication or bulk operations. The key advantage here is its directness and efficiency. You, as the user, initiate the process, resulting in an immediate and complete replication of the data.
Pull-Based Snapshots: Flexible but Resource-Intensive
On the other hand, the Pull-Based approach requires you to query the source table to retrieve its entire content. This is typically done over a JDBC connection from Databricks, and the retrieved data is then stored as a snapshot. While this method offers more flexibility in terms of when and how data is pulled, it can be expensive and might not scale well with very large table sizes.
When it comes to handling multiple versions of these snapshots, there are two main strategies:
Snapshot Replacement Approach (Approach 1): This strategy is about maintaining only the latest version of a snapshot. When a new snapshot becomes available, it replaces the old one. This approach is ideal for scenarios where only the most current data snapshot is relevant, reducing storage costs and simplifying data management.
Snapshot Accumulation Approach (Approach 2): Contrary to the Replacement Approach, here you keep multiple versions of table snapshots. Each snapshot is stored at a unique path, allowing for historical data analysis and tracking changes over time. While this method provides a richer historical context, it demands more storage and a more complex system management.
Introduction to Delta Live Tables Apply Changes From Snapshot
DLT has a capability called “APPLY CHANGES FROM SNAPSHOT“, which allows data to be read incrementally from a sequence of full snapshots. Full snapshot includes all records and their corresponding states, offering a comprehensive view of the data as it exists at that moment. Using APPLY CHANGES FROM SNAPSHOT statement you can now seamlessly synchronize external RDBMS sources into the Databricks platform using full snapshots of the source databases.
APPLY CHANGES FROM SNAPSHOT offers a simple, declarative syntax to efficiently determine the changes made to the source data by comparing a series of in-order snapshots while allowing users to easily declare their CDC logic and track history as SCD types 1 or 2.
Before we dive deeper and go through an example using this new feature, let’s look at the requirements and notes a user should review before leveraging this new capability in DLT:
- This feature only supports Python.
- The feature is supported on serverless DLT pipelines, and on the non-serverless DLT pipeline with Pro and Advanced product editions,
- Snapshots passed into the statement must be in ascending order by their version.
- The snapshot version parameter in the APPLY CHANGES FROM SNAPSHOT statement must be a sortable data type (e.g. string and number types).
- Both SCD Type 1 and SCD Type 2 methods are supported.
Following this blog you can leverage the APPLY CHANGES FROM SNAPSHOT statement and implement either the snapshot replacement or accumulation approach in both the Hive Metastore and Unity Catalog environments.
Define your source table
Let’s explore this concept using online shopping as an example. When you shop online, item prices can fluctuate due to supply and demand changes. Your order goes through stages before delivery, and you might return and reorder items at lower prices. Retailers benefit from tracking this data. It helps them manage inventory, meet customer expectations, and align with sales goals.
To showcase the online shopping example using the first approach (snapshot replacement approach), we will use the full snapshot data stored in the storage location, and as soon as a new full snapshot becomes available, we will replace the existing snapshot with the new one. For the second approach (snapshot accumulation approach), we will rely on the hourly full data snapshots. As each new snapshot becomes available, we write the newly arrived data to the storage location storing all the existing snapshots. Snapshots of data load frequency can be set to whatever frequency is required for processing snapshots. You might need to process the snapshots more or less frequently. Here for simplicity, we pick the hourly full snapshots, meaning that every hour a full copy of the records with their latest updates for that corresponding hour is loaded and stored in our storage location. Below is an example of how our hourly full snapshots are stored in the managed Unity Catalog Volumes.
The below table represents the records stored as an example of a full snapshot:
| order_id | price | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | shipping | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| … | … | … | … | … | … |
When creating snapshot data, you must have a primary key for each record in your data and a single timestamp or version number that applies to all records in each snapshot that allows simple tracking of the order of changes in a series of ingested snapshots. In this daily snapshot example, order_id serves as the primary key. The date associated with loading of the snapshots into the storage location is used to name the files, enabling us to access the snapshot for that specific date, and we rely on these date-based file names to track changes between consecutive snapshots.
For this example, we’ve created a sample dataset using the fields from the table mentioned earlier. To demonstrate an update operation, we change the order_status from ‘pending’ to ‘shipping’, ‘delivered’, or ‘cancelled’ for existing orders. To illustrate inserts, we add new orders with unique order_ids. Lastly, to show how deletes work, we remove a small, random selection of existing orders. This approach provides a comprehensive example that includes all key operations: INSERT, UPDATE, and DELETE. You can find all the notebooks used for this blog, including the data generator, here. The processing steps and results are demonstrated in the following sections.
Implementation of a DLT pipeline to process CDC data from Full Snapshots
In order to leverage “APPLY CHANGES FROM SNAPSHOT”, similar to APPLY CHANGES INTO, we must first create the target streaming table that will be used to capture and store the record changes over time. The below code is an example of creating a target streaming table.
import dlt
dlt.create_streaming_table(name="target",
comment="Clean, merged final table from the full snapshots")Now that we have a target streaming table, we can examine the APPLY CHANGES FROM SNAPSHOT statement more closely and examine the arguments it needs to process the snapshot data effectively. In Approach 1, when every existing snapshot is periodically replaced by a new snapshot, the apply_changes_from_snapshot Python function reads and ingests a new snapshot from a source table and stores it in a target table.
@dlt.view(name="source")
def source():
return spark.read.table("catalog.schema.table")
def apply_changes_from_snapshot(
target="target",
source="source",
keys=["keys"],
stored_as_scd_type,
track_history_column_list = None,
track_history_except_column_list = None)APPLY CHANGES FROM SNAPSHOT requires specifying the “keys” argument. The “keys” argument should refer to the column or combination of columns that uniquely identify a row in the snapshot data. This is a unique identifier that allows the statement to identify the row that has changed in the new snapshots. For example in our online shopping example, “order_id” is the primary key and is the unique identifier of orders that got updated, deleted, or inserted. Thus, later in the statement we pass order_id to the keys argument.
Another required argument is stored_as_scd_type. The stored_as_scd_type argument allows the users to specify how they wish to store records in the target table, whether as SCD TYPE 1 or SCD Type 2.
In Approach 2, where snapshots accumulate over time and we already have a list of existing snapshots, instead of using the source argument, we need another argument called snapshot_and_version that must be specified. The snapshot version must be explicitly provided for each snapshot. This snapshot_and_version argument takes a lambda function. By passing a lambda function to this argument, the function takes the latest processed snapshot version as an argument.
Lambda function: lambda Any => Optional[(DataFrame, Any)]
Return: it could either be None or a tuple of two values:
- The first value of the returned tuple is the new snapshot DataFrame to be processed.
- The second value of the returned tuple is the snapshot version that represents the logical order of the snapshot.
Each time the apply_changes_from_snapshot pipeline gets triggered, we will:
- Execute the snapshot_and_version lambda function to load the next snapshot DataFrame and the corresponding snapshot version.
- If there are no DataFrame returns, we will terminate the execution and mark the update as complete.
- Detect the changes introduced by the new snapshot and incrementally apply them to the target.
- Jump back to the first step (#1) to load the next snapshot and its version.
While the above-mentioned arguments are the mandatory fields of APPLY CHANGES FROM SNAPSHOT, other optional arguments, such as track_history_column_list and track_history_except_column_list, give users more flexibility to customize the representation of the target table if they need to.
Going back to the online shopping example and taking a closer look at how this feature works using the synthetically generated data from [table 1]: Starting with the first run, when no initial snapshots existed, we generate order data to create the first snapshot table in case of Approach 1, or store the generated initial snapshot data into the defined storage location path using managed Unity Catalog volume in case of Approach 2. Regardless of the approach, the generated data would look like below:
| order_id | price | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | returned | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | cancelled | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | shipping | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | delivered | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | pending | 2023-09-15 03:22:52 | 10488 | 2033 |
| 8 | 23 | returned | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | pending | 2023-09-28 22:50:24 | 18909 | 2039 |
| 10 | 79 | cancelled | 2023-09-29 15:06:21 | 14775 | 2017 |
The next time the job triggers, we get the second snapshot of orders data in which new orders with order ids of 11 and 12 have been added, and some of the existing orders in initial snapshots (order ids of 7 and 9) are getting updated with the new order_status, and the order id 2 which was an old returned order is no longer exists. So the second snapshot would look like below:
| order_id | price | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | cancelled | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | shipping | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | delivered | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | delivered | 2023-10-10 23:08:24 | 10488 | 2033 |
| 8 | 23 | returned | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | shipping | 2023-10-10 23:08:24 | 18909 | 2039 |
| 10 | 79 | cancelled | 2023-09-29 15:06:21 | 14775 | 2017 |
| 11 | 91 | returned | 2023-10-10 23:24:01 | 18175 | 2089 |
| 12 | 24 | returned | 2023-10-10 23:39:13 | 13573 | 2068 |
In the case of Approach 1, the snapshot table of “orders_snapshot” is now being overwritten by the most recent snapshot data. To process the snapshot data we first create a target streaming table of “orders”.
import dlt
from datetime import datetime
import datetime
database_name = spark.conf.get("snapshot_source_database")
table = "orders_snapshot"
table_name = f"{database_name}.{table}"
snapshot_source_table_name = f"{database_name}.orders_snapshot"
@dlt.view(name="source")
def source():
return spark.read.table(snapshot_source_table_name)
dlt.create_streaming_table(
name = "orders"
)Then we use the apply_changes_from_snapshot as below to apply the latest changes on every order_id from the most recent snapshot data into the target table. In this example, because we want to process the new snapshot, we read the new snapshot from the snapshot data source and store the processed snapshot data in the target table.
dlt.apply_changes_from_snapshot(
target = "orders",
source = "source",
keys = ["order_id"],
stored_as_scd_type = 1
)Similar to Approach 1, to process the snapshots data for Approach 2 we first need to create a target streaming table. We call this target table “orders”.
import dlt
from datetime import timedelta
from datetime import datetime
dlt.create_streaming_table(name="orders",
comment= "Clean, merged final table from the full snapshots",
table_properties={
"quality": "gold"
}
)For Approach 2, every time the job is triggered and new snapshot data is generated, the data is stored in the same defined storage path where the initial snapshot data was stored. In order to evaluate if this path exists and to find the initial snapshot data, we list the contents of the defined path, then we convert the datetime strings extracted from the paths into datetime objects, and compile a list of these datetime objects. After we have the whole list of datetime objects, by finding the earliest datetime in this list we identify the initial snapshot stored in the root path directory.
snapshot_root_path = spark.conf.get("snapshot_path")
def exist(path):
try:
if dbutils.fs.ls(path) is None:
return False
else:
return True
except:
return False
# List all objects in the bucket using dbutils.fs
object_paths = dbutils.fs.ls(snapshot_root_path)
datetimes = []
for path in object_paths:
# Parse the datetime string to a datetime object
datetime_obj = datetime.strptime(path.name.strip('/"'), '%Y-%m-%d %H')
datetimes.append(datetime_obj)
# Find the earliest datetime
earliest_datetime = min(datetimes)
# Convert the earliest datetime back to a string if needed
earliest_datetime_str = earliest_datetime.strftime('"%Y-%m-%d %H"')
print(f"The earliest datetime in the bucket is: {earliest_datetime_str}")As mentioned earlier in Approach 2, every time the apply_changes_from_snapshot pipeline gets triggered, the lambda function needs to identify the next snapshot that needs to be loaded and the corresponding snapshot version or timestamp to detect the changes from the previous snapshot.
Because we are using hourly snapshots and the job triggers every hour, we can use increments of 1 hour along with the extracted datetime of the initial snapshot to find the next snapshot path, and the datetime associated with this path.
def next_snapshot_and_version(latest_snapshot_datetime):
latest_datetime_str = latest_snapshot_datetime or earliest_datetime_str
if latest_snapshot_datetime is None:
snapshot_path = f"{snapshot_root_path}/{earliest_datetime_str}"
print(f"Reading earliest snapshot from {snapshot_path}")
earliest_snapshot = spark.read.format("parquet").load(snapshot_path)
return earliest_snapshot, earliest_datetime_str
else:
latest_datetime = datetime.strptime(latest_datetime_str, '%Y-%m-%d %H')
# Calculate the next datetime
increment = timedelta(hours=1) # Increment by 1 hour because we are
provided hourly snapshots
next_datetime = latest_datetime + increment
print(f"The next snapshot version is : {next_datetime}")
# Convert the next_datetime to a string with the desired format
next_snapshot_datetime_str = next_datetime.strftime('%Y-%m-%d %H')
snapshot_path = f"{snapshot_root_path}/{next_snapshot_datetime_str}"
print("Attempting to read next snapshot from " + snapshot_path)
if (exist(snapshot_path)):
snapshot = spark.read.format("parquet").load(snapshot_path)
return snapshot, next_snapshot_datetime_str
else:
print(f"Couldn't find snapshot data at {snapshot_path}")
return NoneOnce we define this lambda function and can identify changes in data incrementally, we can use the apply_changes_from_snapshot statement to process the snapshots and incrementally apply them to the created target table of “orders”.
dlt.apply_changes_from_snapshot(
target="orders",
snapshot_and_version=next_snapshot_and_version,
keys=["order_id"],
stored_as_scd_type=2,
track_history_column_list=["order_status"]
)Regardless of the approach, once the code is ready, to use the apply_changes_from_snapshot statement, a DLT pipeline using the Pro or Advanced product edition must be created.
Develop Workflows with Delta Live Tables Pipeline as Tasks Using Databricks Asset Bundles (DABs)
To simplify the development and deployment of our sample workflow, we used Databricks Asset Bundles (DABs). However, the APPLY CHANGES functionality does not mandate the use of DABs, but it is considered a best practice to automate the development and deployment of Databricks Workflows and DLT pipelines.
For both common approaches we are covering in this blog we leveraged from DABs in this repo. Thus in the repo there are source files called databricks.yml which serve as an end-to-end project definition. These source files include all the parameters and information about how DLT pipelines as tasks within workflows can be tested and deployed. Given that DLT pipelines provide you two storage options of Hive Metastore and Unity Catalog, in the databricks.yml file we considered both storage options for implementations of both Approach 1 and Approach 2 jobs. The target “development” in databricks.yml file refers to the implementation of both approaches using Hive Metastore and in DBFS location, while target called “development-uc” in the databricks.yml file refers to the implementation of both approaches using Unity Catalog and storing data in managed UC Volumes. Following the README.md file in the repo you will be able to deploy both approaches in either storage option of your choice only by using a few bundle commands.
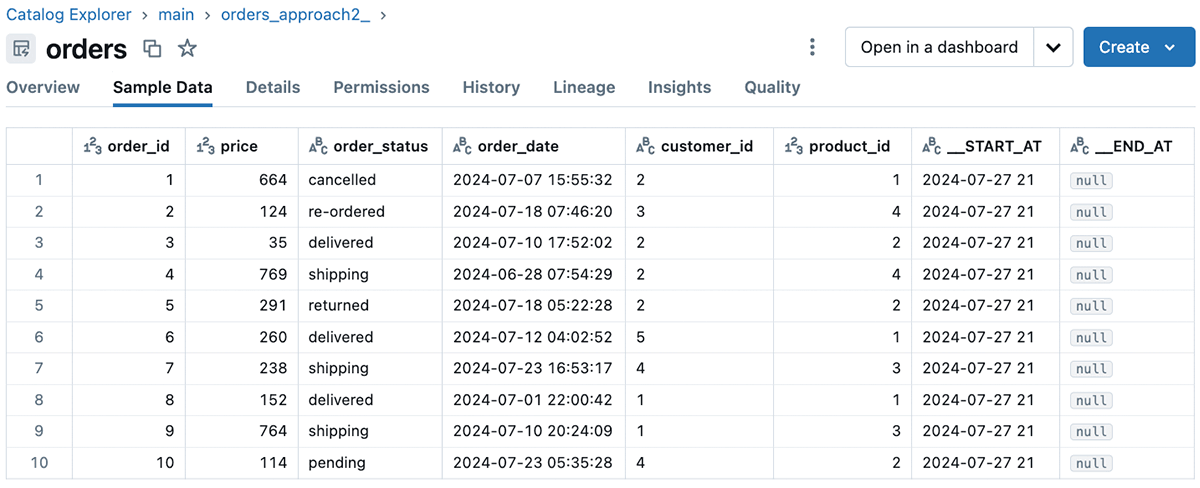
In the example we covered Approach 2 we used SCD Type 2 target table through passing 2 to the stored_as_scd_type argument to store all the historical and current values of the order ids in the target table. Navigating to the target table through Catalog Explorer, we can see the columns of the target table, sample data, details, and more insightful fields associated with the target table. For SCD Type 2 changes, Delta Live Tables propagates the appropriate sequencing values to the __START_AT and __END_AT columns of the target table. See below for an example of sample data from the target table in Catalog Explorer when using Unity Catalog. The catalog “main” in the image below is the default catalog in the Unity Catalog metastore, which we are relying on in this example for simplicity.
Getting Started
Building a scalable, reliable incremental data pipeline based on snapshots has never been easier. Try Databricks for free to run this example.
Source link
lol