
Organizations increasingly rely on data to make business decisions, develop strategies, or even make data or machine learning models their key product. As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a data quality framework, its essential components, and how to implement it effectively within your organization.
What is a data quality framework?
A data quality framework refers to the principles, processes, and standards designed to manage and improve the quality of data within organizations. Such frameworks ensure that the data used for various analyses is of high quality and is fit for its intended purpose – supporting better decision-making.
Thanks to data quality frameworks, teams can identify their data quality goals and the actions they need to carry out to achieve these targets.
Why do we need a data quality framework?
As companies increasingly rely on data for decision-making, poor-quality data can lead to disastrous outcomes. This is why the famous saying “garbage in, garbage out” remains ever so relevant. Even the most sophisticated ML models, neural networks, or large language models require high-quality data to learn meaningful patterns. When bad data is inputted, it inevitably leads to poor outcomes. Let’s look at a few real-world examples of what can go wrong in such cases.
A coding error impacted credit scoring
In 2022, Equifax – a major credit bureau – reported inaccurate credit scores for millions of consumers. The issue was caused by a coding error within one of the legacy servers. Unfortunately, this error significantly impacted individuals’ ability to qualify for a loan or a credit card, and even affected the associated interest rates.
For the company, this resulted in regulatory fines, lawsuits, a drop of approximately 5% in its stock price, and naturally a big dent in its credibility.
Bad data leads to millions lost in revenue sharing
Another example is Unity, a company producing software used for video game development. In 2022, the company ingested bad data from one of its major customers. Then, that data was used as input for the ML model responsible for ad placement, which allowed users to monetize their games. This led to significant inaccuracies in the training sets, severely impacting the model’s performance.
As a result, the company lost around $110 million in revenue-sharing and its shares dropped by a massive 37%.
Sadly, these are not isolated cases
While these may seem like isolated incidents and horror stories, such scenarios are unfortunately quite common, even among large companies such as X (formerly Twitter), Samsung, or Uber. As a result, Gartner estimates that poor data quality costs organizations an average of $13 million annually.
Keeping these examples in mind, these are the main reasons why organizations should implement data quality frameworks:
- Reliable data is essential for making informed decisions that generate value, lead to a competitive advantage in the market, and contribute to any organization’s strategic goals.
- High-quality data significantly reduces the risk of costly errors, and the resulting penalties or legal issues. It also helps organizations comply with regulatory requirements.
- Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while data scientists require clean data for training machine learning models. Without high-quality data, even the most advanced models can’t deliver value.

What are the components of a data quality framework?
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. In this section, we will go over the key components of such a framework.
Data Governance
Data governance is the foundation of any data quality framework. It establishes the policies, roles, and procedures for managing and protecting data assets.
Within a robust data governance framework, clear roles and responsibilities are defined, for example:
- Data owners oversee data security.
- Data stewards ensure that the established policies are followed.
- Data custodians are responsible for the custody, transportation, and storage of data.
Data Quality Dimensions
Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following:
- Accuracy indicates how correctly data reflects the real-world entities or events it represents. For example, if a client’s address is recorded accurately, it corresponds to the actial real-world location.
- Completeness determines whether all required data fields are filled with appropriate and valid information. For example, in a customer dataset, a complete profile contains all mandatory fields, such as name, surname, address, email, and phone number.
- Consistency refers to data being uniform across different datasets or systems. For example, a customer’s birthday should be the same across different datasets and encoded in the same format.
- Timeliness measures how up-to-date the data is and whether it is available when needed by a machine learning model or for decision-making. For example, if our model uses weather forecasts, we should use the latest data available at the moment of inference.
- Relevance evaluates whether the data is appropriate and useful for its intended purpose. For example, while customer satisfaction survey results are relevant for assessing service quality, they are not directly relevant for calculating financial metrics.
Within a framework, specific metrics and thresholds are set for each dimension, thus enabling organizations to effectively assess and maintain their data quality.
Data Quality Rules and Standards
Defining data quality rules and standards helps with maintaining consistency and integrity across datasets within the organization.
Data quality rules can include checks based on business rules and checks against internal or external datasets. For example, a rule might state that dates have to be stored in a specific format (e.g., mm/dd/yyyy), otherwise they will be considered invalid.
For other modalities, let’s assume that we are talking about an e-commerce company:
- An example of a rule for text can be that there are no spelling mistakes (as identified by a spell checker) in the product’s description. Or the description can’t be longer than 500 words.
- For images, it might be the size of the image in pixels, the aspect ratio or that the images of a product must fully display the product without significant portions of it being cut off or obscured.
A data quality standard might specify that when storing client information, we must always include email addresses and phone numbers as part of the contact details. If any of these is missing, the client data is considered incomplete.
Data Profiling
Data profiling involves analyzing and summarizing data (e.g. using summary statistics) to understand its current state and identify any problems. At this step, the organizations use the previously defined rules and standards to make the analysis. For example, during profiling you might find out that 14% of customer profiles are incomplete or 7% of dates are incorrectly encoded.
It is one of the most effective ways to make sure that decisions are based on healthy data, as it helps identify issues such as missing values, outliers, duplicates, and invalid formats. Naturally, this step also applies to different modalities. For example, profiling might reveal that a certain fraction of images stored in our e-commerce platform is not of sufficient resolution or that 10% of the product descriptions are shorter than 5 words.
Data Cleaning
After potential data issues are identified, the next step is to correct them. Data cleaning might involve fixing errors, removing duplicates, adjusting data formats, or imputing missing values.
In general, through effective data issue management, we can improve the efficiency of resolving data-related problems, thus minimizing their potential impact on business operations.
Data Quality Monitoring and Reporting
Data quality monitoring is a continuous process of measuring and evaluating data to ensure compliance with established data quality rules and standards. By ongoing monitoring, organizations can detect issues in time and take appropriate measures to address them before the bad data is used for decision-making.
To gather insights from quality monitoring, companies can use automatically generated reports describing the state of data quality.
These two components are crucial to any data quality framework, as they are used to improve and iterate on the framework itself. Organizations should regularly review the adopted metrics, conduct audits of data against quality standards, and implement a feedback loop.
Continuous Improvement Processes
Continuous improvement processes refer to iterative approaches used to enhance data quality over time. These practices involve refining data quality standards, updating governance policies, and adopting new technologies and tools.

What are the popular frameworks?
We have already covered a lot of ground with all the different components. To make our lives easier, there are several established data quality frameworks that offer guidelines and best practices for maintaining and improving data quality.
DAMA-DMBOK (Data Management Body of Knowledge)
DAMA-DMBOK is a framework developed by the Data Management Association (DAMA). It provides best practices and guidelines for effective data management across an organization. It covers topics such as data governance, data quality, data architecture, and more.
TDWI Data Quality Framework
This framework, developed by the Data Warehousing Institute, focuses on practical methodologies and tools that address managing data quality across various stages of the data lifecycle, including data integration, cleaning, and validation. The framework is designed to help organizations ensure high-quality data, particularly within the context of data warehousing and business intelligence environments.
ISO 8000
The ISO 8000 data quality framework is an international standard that provides guidelines for ensuring the quality of data among various dimensions (accuracy, completeness, etc.). It offers a structured approach to managing data quality across its lifecycle, from creation to its usage. It includes specific requirements for components such as data governance, or data quality assessment.
Six Sigma
The Six Sigma framework applies the principles of Six Sigma (a set of methodologies and tools used to improve business processes) to minimize errors and variations in data processes. It uses statistical approaches to identify and eliminate issues with data, thus making sure that the data meets the required quality standards.
Data Quality Scorecard
The Data Quality Scorecard framework provides a structured approach to evaluating and monitoring data quality by defining key metrics across various data quality dimensions. Organizations can visually track and assess the health of their data over time, easily highlighting areas that require focus and improvement. This framework helps with prioritizing data quality initiatives and supports continuous improvement efforts by aggregating the metrics into a single, high-level score (e.g., percentage or grade).
What are the key differences?
I understand that even after reading these summaries, it might be difficult to pinpoint the exact differences between the frameworks. So, let’s summarize their scope as simply as possible:
- DAMA-DMBOK is the most comprehensive framework, covering all aspects of data management.
- TDWI’s framework focuses on data quality within the context of data warehousing and BI.
- ISO 8000 is a formal standard for data quality. As such, you can also get certification in it.
- Six Sigma applies broadly to process improvement, and in this case, also to data quality.
- Data Quality Scorecard is a practical approach for ongoing data quality monitoring.
A step-by-step approach to implementing a data quality framework
While the steps might vary depending on your organization’s specific situation, the following guidelines can help you establish a successful data quality framework. We break down the steps into four groups.
Research
- Assess the Current State – Conduct a thorough assessment of your organization’s existing data quality practices, capabilities, and challenges. By understanding current pain points you can target the most impactful areas for improvement.
- Understand Business Needs – Identify the business-critical data that drives decision-making. Typically it is used by various stakeholders in reports and dashboards. Or it is consumed by machine learning models that are either products on their own (e.g., real-time fraud detection) or produce outputs used for decision-making (e.g., revenue forecasts). By doing so, you will make sure that the framework aligns with key business objectives.

Defining objectives and initial assessment
- Define Goals – Establish clear data quality goals for your organization. While doing so, focus on key dimensions like accuracy, completeness, and timeliness. By aligning these goals with the business needs you have identified earlier, you will ensure they are relevant and effective.
- Set Up Standards – Specify detailed criteria for measuring data quality and determining if the data meets the required quality level for its intended use. When setting up standards, it is also very important to consider the modality of the data. Different modalities (tabular, images, text, audio) will require different approaches to determining what is acceptable.
- Perform a Data Quality Assessment – Profile your data to evaluate its current quality. You can use various summary statistics and other statistical analyses to detect patterns, anomalies, missing values, and errors.
Developing data quality policies and processes
- Set Up Data Governance – Find suitable colleagues and assign roles to oversee various aspects of the data quality process. With data quality frameworks, accountability is essential for achieving and maintaining data quality goals.
- Implement Data Quality Rules – Develop rules that validate data quality. Remember that they should cover all business-critical elements identified in earlier steps.
- Clean the Data – Address the issues identified during the assessment phase by removing duplicates, imputing missing values, and correcting errors.
- Automate Data Quality Processes – To ensure scalability, implement automation tools that continuously monitor and clean data.
Monitoring and improvement
- Establish Continuous Monitoring and Reporting – Continuously monitor data quality metrics and make sure that they are regularly reviewed by responsible data stewards to maintain standards.
- Commit to Continuous Improvement – The company has to recognize that data quality is an ongoing effort requiring regular review and refinement. As such, the data quality framework will evolve together with changing business needs and goals.
- Promote Training and Culture – Educate colleagues on the importance of data quality and the processes in place. By organizing training and knowledge-sharing sessions, foster a culture that values and maintains high data quality.
As always, there are many tools available on the market that can help you set up a data quality framework in your organization. Covering every tool in detail would simply be too much, so we will focus on some of the most popular tools that can be used for various steps or components of a framework.
Standalone software
IBM InfoSphere Information Server is a data integration platform with various data quality management features. It provides a unified platform for data governance, data integration, and data quality. It primarily caters to large organizations with complex data environments.
Talend Data Quality is a commercial tool that offers comprehensive data quality management, including profiling, cleaning, and monitoring. It is part of the broader Talend Data Fabric suite.
Informatica Data Quality is one of the leading enterprise tools for data quality management. It offers advanced features for data profiling, rule-based data cleaning, and governance across various data sources. It integrates well with both cloud and on-premise systems.
Datafold is a tool focused on data observability and quality. It is particularly popular among data engineers as it integrates well with modern data pipelines (e.g., dbt, Airflow) to detect issues before they impact downstream processes.
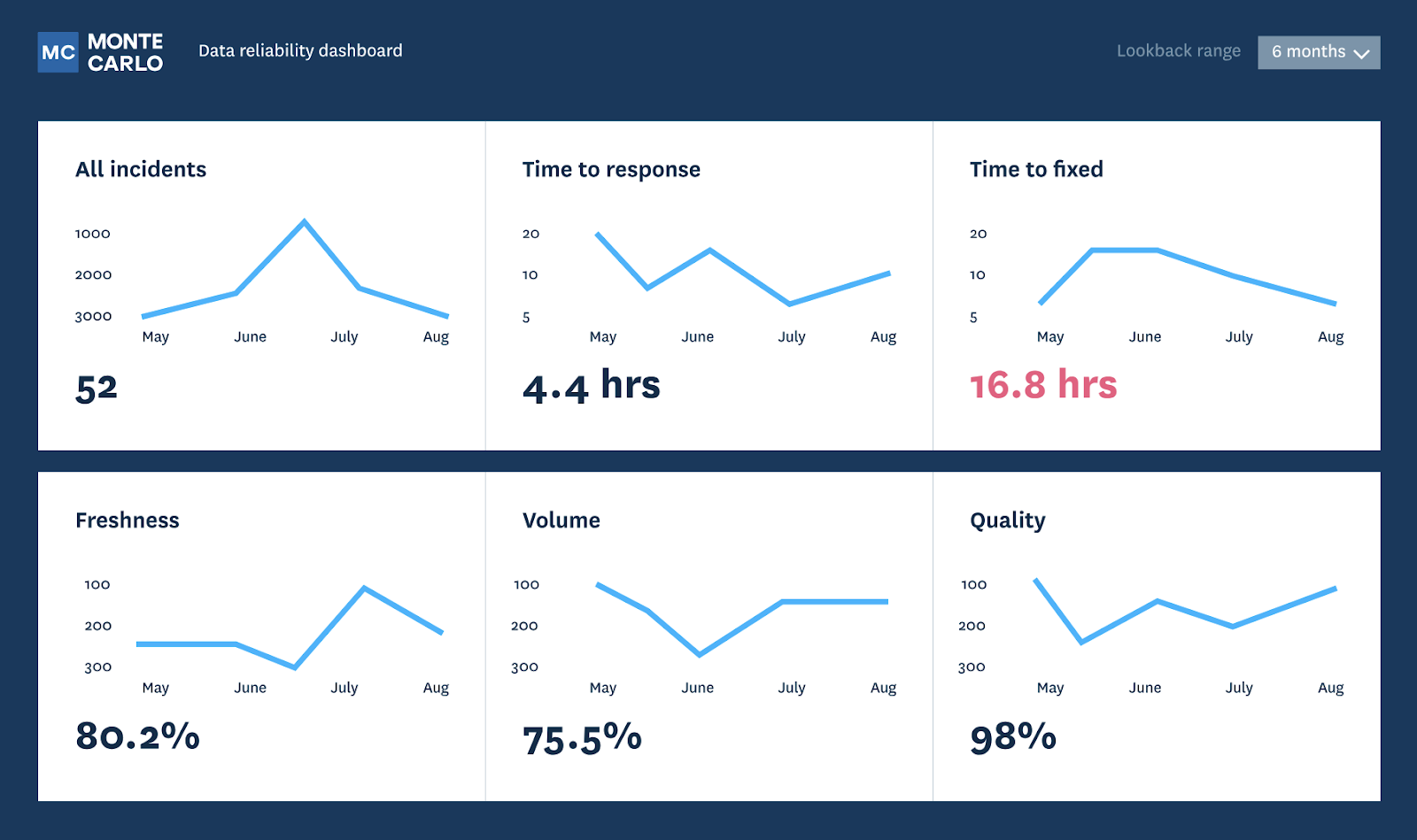
Monte Carlo is a code-free data observability platform that focuses on data reliability across data pipelines. To do that, it employs monitoring and real-time alerting on data quality issues. Additionally, it offers end-to-end data lineage and tools supporting root cause analysis. An interesting feature of the platform is that it uses machine learning to understand what your organization’s data looks like and to discover data issues proactively.
Databand is a data observability and quality platform designed to help data teams monitor and manage their data pipelines. It provides visibility into data flows, offers various data quality checks (including custom rules), and inspects pipeline performance (job execution times, data volumes, and error rates).
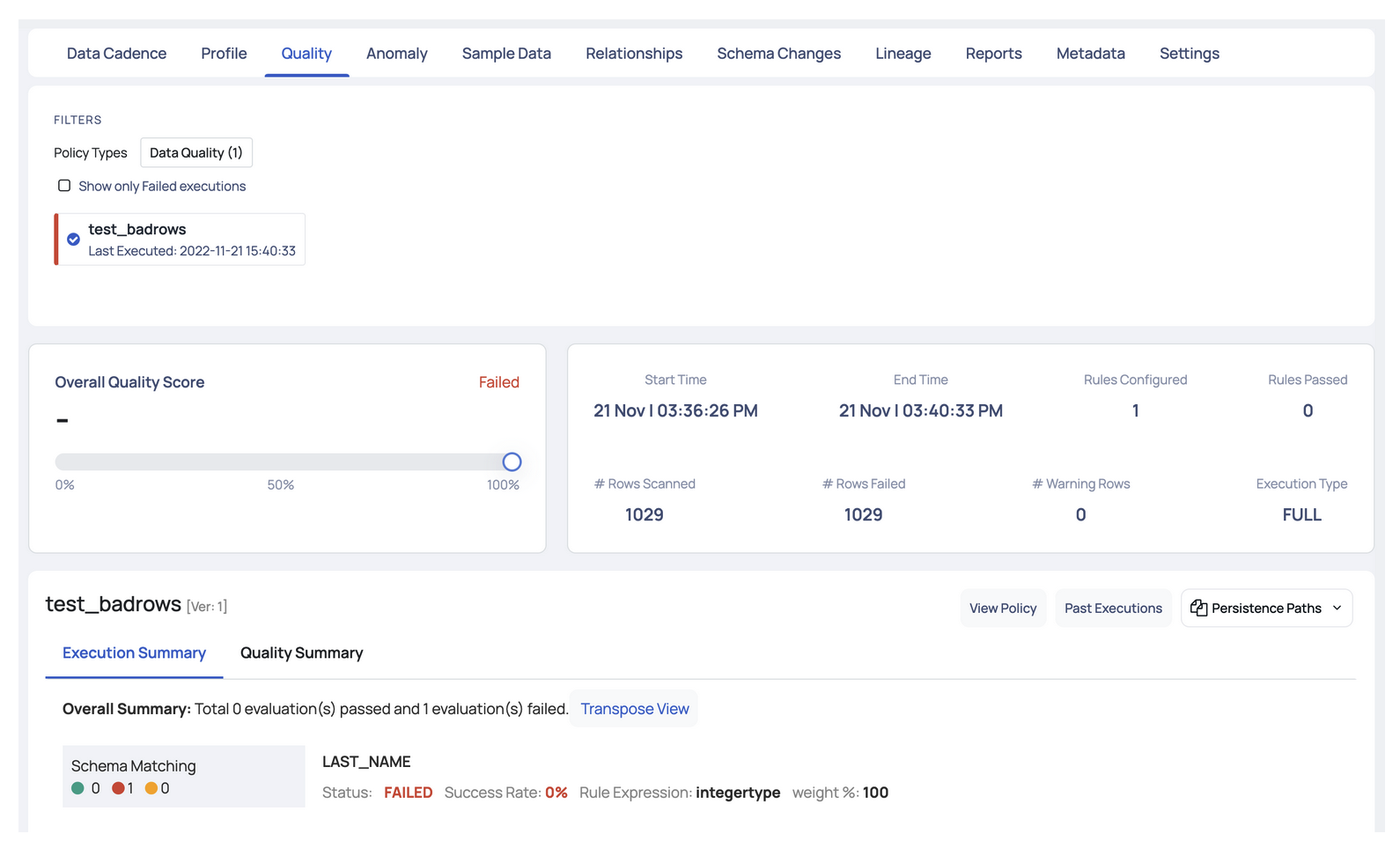
Torch by Acceldata (not connected to Torch/PyTorch deep learning frameworks) is a data observability platform that combines data quality, pipeline monitoring, and system performance management. With this tool, you can implement and monitor data quality rules across different data sources. You can either create your own tailor-made rules for your scenarios or use off-the-shelf ones available in a large library that comes with the tool.
DagsHub Data Engine is a centralized, out-of-the-box platform that enables effective management of data, including unstructured data like images, as well as metadata, labels, and predictions. With an interface similar to Pandas, you can curate your data, review it, resolve any issues you encounter, and easily stream it directly into your training pipelines. It also promotes collaboration among team members, as all data, annotations, metadata, and more are accessible to everyone without the need to create duplicates.
Python libraries
Great Expectations is an open-source tool that helps you define, manage, and validate expectations (i.e., quality) for your data. These expectations can include type checks, range checks, uniqueness constraints, and more advanced, tailor-made rules. It integrates well with modern data engineering pipelines (e.g., Airflow, dbt) and automatically generates documentation based on the set expectations.
Pandera is an open-source data validation tool built on top of Pandas. It allows users to define schemas for their data frames to enforce data types, ranges, and other constraints. As it seamlessly integrates with Pandas workflows, it is easy to add on top of existing pipelines.
Pydantic is an open-source data validation library for Python. It provides an easy way to enforce type checks and validation on Python data structures. One of its key strengths is that it easily parses and validates JSON data, which is useful for APIs and configurations.
Deepchecks is a tool for validating and monitoring the quality of data and machine learning models. It focuses on detecting issues in datasets (e.g., class imbalance, feature drift, or leakage) and models during development and once deployed to production.
Other
Apache Griffin is an open-source data quality solution for big data environments, particularly within the Hadoop and Spark ecosystems. It allows users to define, measure, monitor, and validate data quality.
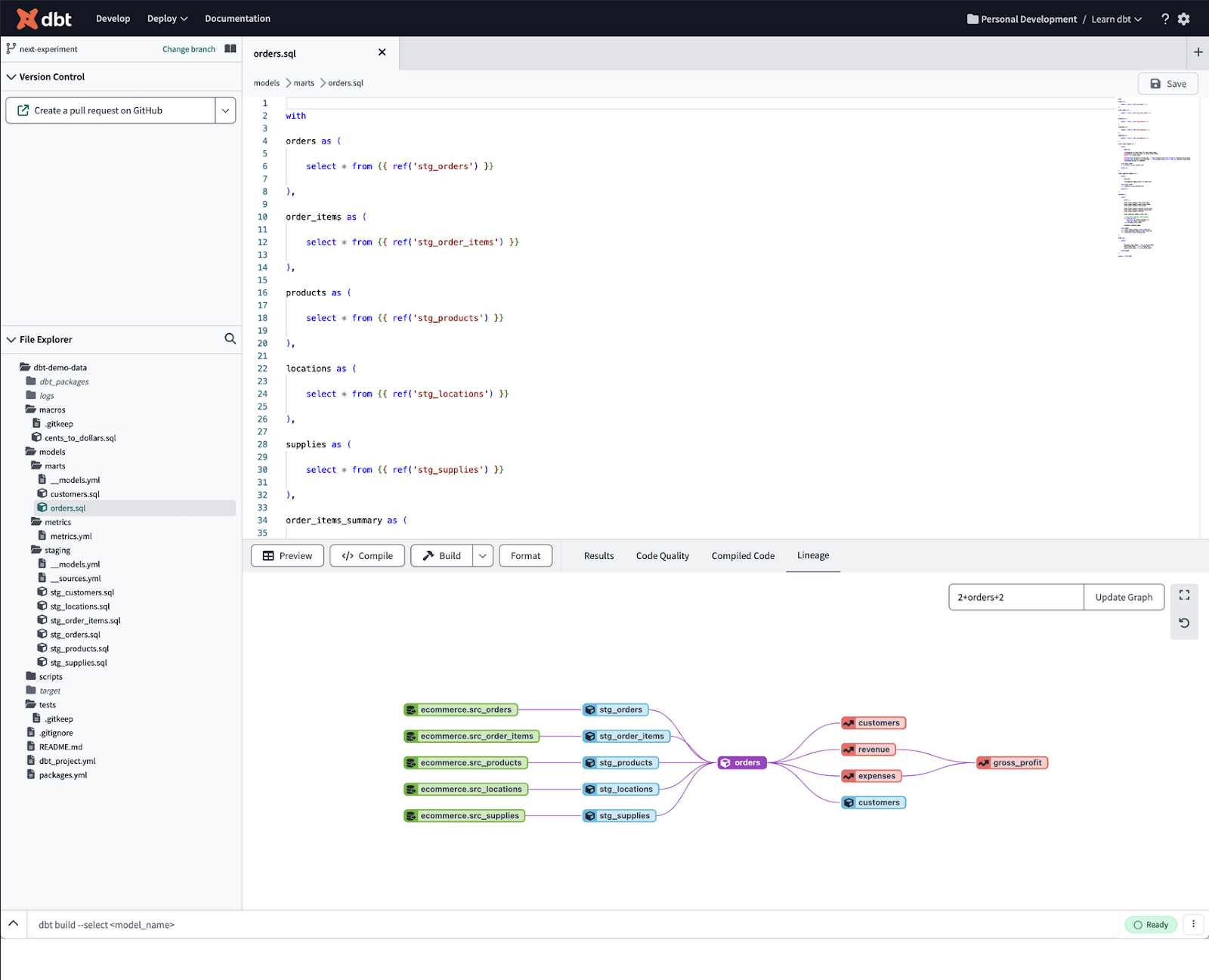
dbt is a data transformation tool with functionalities for defining data quality tests as part of the transformation process. It is SQL-based and integrates well with modern data warehouses. dbt automatically tests data quality and generates documentation.
Deequ is an open-source library developed by Amazon. The main idea behind it is to define unit tests for data. It is designed to handle big data and is built on top of Apache Spark. Additionally, it provides a Python interface through the PyDeequ library.
DVC is an open-source tool for data version control, focusing on the reproducibility of machine learning projects. It integrates with Git to version control large files, datasets, and ML models. DVC also offers extensive experiment tracking capabilities, and the dedicated VS Code extension makes working with DVC much easier from your IDE.
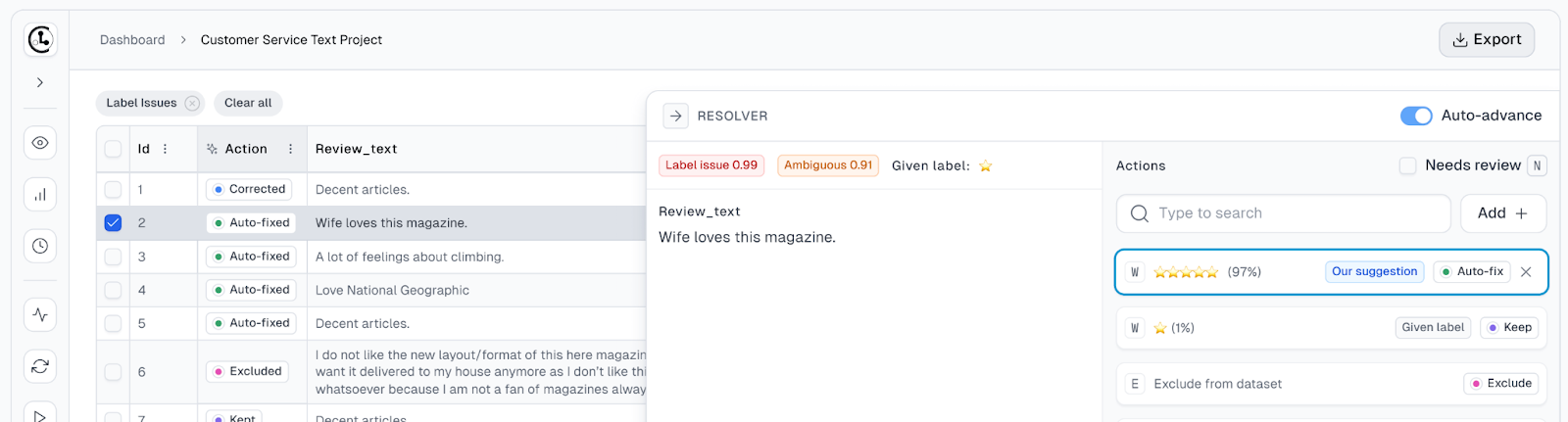
Cleanlab is an open-source tool designed to improve data quality. It focuses on datasets used for training ML models. As such, it identifies and corrects label errors, finds outliers, and handles noisy data. Additionally, there is an enterprise-ready version, Cleanlab Studio, which is a data curation platform that automates essential data science and engineering tasks related to preparing data for AI models. Recently, the tool also offers functionalities connected to monitoring and fixing issues connected to hallucinations from GenAI models.
Conclusions
In this article, we have explored what data quality frameworks are and why it is crucial to pay attention to data quality. Without high-quality data, your organization cannot make informed, data-driven decisions. Even worse, it might end up making poor decisions based on bad data, what can be disastrous for the business.
By following the steps outlined in this article and leveraging the tools available on the market, you should be able to assess your organization’s current practices, suggest improvements, and become an advocate for clean, high-quality data.
Source link
lol