
1. Introduction
The research and engineering community at large have been continuously iterating upon Large Language Models (LLMs) in order to make them more knowledgeable, general-purpose, and capable of fitting into increasingly complex workflows. Over the last few years, LLMs have progressed from text-only models to having multi-modal capabilities; now, we are increasingly seeing a progression toward LLMs as part of compound AI systems. This paradigm envisions an LLM as an integral part of a larger engineering setting, as opposed to an end-to-end pipeline in and of itself. At Databricks, we have found that this compound AI system model is more aligned with real-world applications.
In order for an LLM to operate as part of a larger system, it needs to have tool use capabilities. Such capabilities enable an LLM to receive inputs from and produce outputs to external sources. Currently, the most commonly used tool is function calling, or the ability to interact with external code such as APIs or custom functions. Adding this capability transforms LLMs from isolated text processors into integral parts of larger, more complex AI systems. However, function calling needs an LLM that can do three things: interpret user requests accurately, decide if the request needs external code, and construct a correctly formatted function call with the right arguments.
Consider the following simple example:
System: You are an AI Assistant who can use function calls to help answer the user's queries. You have access to several climate-related functions: get_weather(city, state_abbr), get_timezone(latitude, longitude), get_nearest_station_id...
User: What is the weather in San Francisco?Given that the LLM has been made aware of several functions using the system prompt, it first needs to understand what the user wants. In this case, the question is fairly straightforward. Now, it needs to check if it needs external functions and if any of the available functions are relevant. In this case, the get_weather() function needs to be used. Even if the LLM has gotten this far, it now needs to plug in the correct arguments. In this case, it is clear that city=”San Francisco” and state_abbr=”CA”. Therefore, it needs to generate the following output:
Assistant: get_weather("San Francisco", "CA")Now, the compound system built on top of the LLM can use this output to make the appropriate function call, get the output, and either return it to the user or feed it back into the LLM to format it nicely.
From the above example, we can see that even a simple query involving function calling requires the LLM to get many things right. But which LLM to use? Do all LLMs possess this capability? Before we can decide that, we need to first understand how to measure it.
In this blog post, we’ll explore function calling in more detail, starting with what it is and how to evaluate it. We will focus on two prominent evals: the Berkeley Function Calling Leaderboard (BFCL) and the Nexus Function Calling Leaderboard (NFCL). We will discuss the specific aspects of function calling that these evals measure as well as their strengths and limitations. As we will see, it is sadly not a one-size-fits-all strategy. To get a holistic picture of a model’s ability to perform function calling, we need to consider multiple factors and evaluation methods.
We’ll share what we’ve learned from running these evaluations and discuss how it can help us choose the right model for certain tasks. We also outline strategies for improving an LLM’s function calling and tool use abilities. In particular, we demonstrate that the performance of smaller, open source models like DBRX and LLama-3-70b can be elevated through a combination of careful prompting and parsing techniques, bringing them closer to or even surpassing GPT-4 quality in certain aspects.
What is function calling, and why is it useful?
Function calling is a tool that allows an LLM to interact with external systems using APIs and custom functions. Note that “tool use” and “function calling” are often used interchangeably in the literature; function calling was the first type of tool introduced and remains one of the most popularly used tools to date. In this blog, we refer to function calling as a specific type of tool use. In order to use function calling, the user first provides the model with a set of available functions and their required arguments, typically described using JSON schemas. This gives the model the syntactical structure of the function as well as descriptions of each argument. When presented with a user query, the model identifies which (if any) functions are relevant. It then generates the correct function call, complete with the necessary arguments.
At Databricks, we’ve observed two primary enterprise use cases that leverage function calling:
- Agents and complex multi-turn chatbots
- Batch inference feature extraction
Agents
There is a growing interest in “agentic” capabilities for LLMs. Generally speaking, an LLM Agent should be able to complete a complex task that may require multiple steps with minimal user intervention. In practice, function calling is often necessary to complete several of these steps: as discussed earlier, it is the underlying capability that enables an LLM to interact with existing software infrastructure such as databases, e.g. via REST APIs.
Consider the following scenario: You are a large enterprise with a large amount of financial projection data in a SQL database. With function calling, you can now build a chatbot that has read access to that data. An internal user can ask the chatbot a complex question like “What is the projected revenue for our XYZ product in this fiscal year based on last year’s trends?” and the chatbot can use function calling to request financial data between two dates which it can then use to give an accurate estimate. Here’s an example of what this may look like:
User: "What is the projected revenue for our XYZ product in this fiscal year based on last year's trends?"
Chatbot: To answer this question, I'll need to retrieve some financial data. Let me check our database.
[Function Call: get_financial_data]
Parameters:
- product: "XYZ"
- start_date: "2023-07-01" // Assuming last fiscal year started on this date
- end_date: "2024-06-30" // Current fiscal year end
- columns: ["last_year_revenue", "growth_rate"]
# this could either be directly executed by designing the chatbot as a compound AI
# system wrapping the model, or manually executed by the user who returns the
# response
[Function Response]
{
"last_year_revenue": 10000000,
"growth_rate": 0.15,
}
Chatbot: Based on the data I've retrieved, I can provide you with a projection for XYZ's revenue this fiscal year:
Last year's revenue for XYZ was $10 million. The product has shown a growth rate of 15% year-over-year.
Projecting this trend forward, we can estimate that the total revenue for XYZ this fiscal year will be approximately $11.5 million. This projection takes into account the current growth rate and the performance so far this year.
Would you like me to break down this calculation further or provide any additional information about the projection?Batched Feature Extraction
Function calling usually refers to the LLM’s ability to call a function from user-provided APIs or functions. But it also means the model must output the function call in the exact format defined by the function’s signature and description. In practice, this is accomplished by using JSON as a representation of the function. This aspect can be exploited to solve a prevalent use case: extracting structured data in the form of JSON objects from unstructured data. We refer to this as “batched feature extraction,” and find that it is fairly common for enterprises to leverage function calling in order to perform this task. For example, a legal firm could use an LLM with function-calling capabilities to process huge collections of contracts to extract key clauses, identify potential risks, and categorize each document based on its content. Using function calling in this manner allows this legal firm to convert a large amount of data into simple JSONs that are easy to parse and gain insights from.
2. Evaluation Frameworks
The above use cases show that by bridging the gap between natural language understanding and practical, real-world actions, function calling significantly expands the potential applications of LLMs in enterprise settings. However, the question of which LLM to use still remains unanswered. While one would expect most LLMs to be extremely good at these tasks, on closer examination, we find that they suffer from common failure modes rendering them unreliable and difficult to use, particularly in enterprise settings. Therefore, like in all things LLM, reliable evals are of paramount importance.
Despite the rising interest in function calling (especially from enterprise users), existing function calling evals do not always agree in their format or results. Therefore, evaluating function calling properly is non-trivial and requires combining multiple evals and more importantly, understanding each one’s strengths and weaknesses. For this blog, we will focus on simple, single-turn function calling and leverage the two most popular evals: Berkeley Function Calling Leaderboard (BFCL) and Nexus Function Calling Leaderboard (NFCL).
Berkeley Function Calling Leaderboard
The Berkeley Function Calling Leaderboard (BFCL) is a popular public function-calling eval that is kept up-to-date with the latest model releases. It is created and maintained by the creators of Gorilla-openfunctions-v2, an OSS model built for function calling. Despite some limitations, BFCL is an excellent evaluation framework; a high ranking on its leaderboard generally indicates strong function-calling capabilities. As described in this blog, the eval is composed of the following categories. (Note that BFCL also contains test cases with REST APIs and also functions in different languages. But the vast majority of tests are in Python which is the subset that we consider.)
- Simple Function contains the simplest format: the user provides a single function description, and the query only requires that function to be called.
- Multiple Function is slightly harder, given that the user provides 2-4 function descriptions and the model needs to select the best function among them to invoke in order to answer the query.
- Parallel Function requires invoking multiple function calls in parallel with one user query. Like Simple Function, the LLM is given only a single function description.
- Parallel Multiple Function is the combination of Parallel and Multiple. The model is provided with multiple function descriptions, and each of them may need to be invoked zero or multiple times.
- Relevance Detection consists purely of scenarios where none of the provided functions are relevant, and the model should not invoke any of them.
One can also view these categories from the lens of what skills it demands of the model:
- Simple merely needs the model to generate the correct arguments based on the query.
- Multiple requires that the model be able to choose the correct function in addition to choosing its arguments.
- Parallel requires that the model decide how many times it needs to invoke the given function and what arguments it needs for each invocation.
- Parallel Multiple tests if the model possesses all of the above skills.
- Relevance Detection tests if the model is able to discern when it needs to use function calling and when not to. However, Relevance Detection only contains examples where none of the functions are relevant. Therefore, a model that is unable to ever perform function calling would seemingly score 100% on it. Nonetheless, given that a model performs well in the other categories, it becomes an extremely valuable eval. This once again underscores the importance of understanding these evals well and viewing them holistically.
Each of the above categories can be evaluated by checking the Abstract Syntax Tree (AST) or actually executing the function call. The AST evaluation first constructs the abstract syntax tree of the function call, then extracts the arguments and checks if they match the ground truth’s possible answers. (Footnote: For more details refer to: https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html#bfcl)
We found that the AST evaluation accuracy correlates well with the Executable evaluation and, therefore, only considered AST.
| Strengths | Weaknesses |
|---|---|
| BFCL is fairly diverse and has several categories in each category. | The reference implementation applies bespoke parsing for several models which makes it difficult to compare fairly across models (Note: in our implementation, we normalize the parsing across models to only include minimal parsing of the model’s output.) |
| Widely accepted in the community. | Several categories in BFCL are far too easy and not representative of real-world use cases. Categories like simple and multiple appear to be saturated and we believe that most of the best models have already crossed the noise ceiling here. |
| Relevance detection is a very important capability, particularly in real-world applications. |
Nexus Function Calling Leaderboard
The Nexus Function Calling Leaderboard (NFCL) is also a single turn function calling eval; unlike BFCL, it does not include relevance detection. However, it has several other features that make it an effective eval for enterprise function calling. It is from the creators of the NexusRaven-v2 which is an OSS model aimed at function calling. While the NFCL reports that it outperforms even GPT-4, it only gets 68.06% on BFCL. This discrepancy once again reveals the importance of understanding what the eval numbers on a particular benchmark mean for a specific application.
The NFCL categories are split based on the source of their APIs rather than the kind of evaluation. However, they also differ in difficulty, as we describe below.
- NVD Library: The queries in this category are based on the two search APIs from the National Vulnerability Database: searchCVE and searchCPE. Since there are only two APIs to choose from, this is a relatively easy task that only requires calling one of them. The complexity arises from the fact that each function has around 30 arguments.
- VirusTotal: These are based on the VirusTotal APIs which are used to analyze suspicious files and URLs. There are 12 APIs but they are simpler than NVD. Therefore, models typically score slightly higher on VirusTotal than NVD. VirusTotal still requires only a single function call.
- OTX: These are based on the Open Threat Exchange APIs. There are 9 extremely simple APIs and this is usually the category where most models score the highest.
- Places: These are based on a set of APIs that are related to querying details about locations. While there are only 7 fairly simple functions, the questions require nested function calls (eg., fun1(fun2(fun3(args))) ) which makes it tricky for most models. While a few of the questions require only one function call, many require nesting of up to 7 functions.
- Climate API: As the name suggests, this is based on APIs used to retrieve climate data. Again, while there are only 9 simple functions, they often require multiple parallel calls and nested calls, making this benchmark quite difficult for most models.
- VirusTotal Nested: This is based on the same APIs as the VirusTotal benchmark, but the questions all require nested function calls to be answered. This is one of the hardest benchmarks, primarily because most models were not designed to output nested function calls.
- NVD Nested: This is based on the same APIs as the NVD benchmark, but the questions require nested function calls to be answered. None of the models we have tested were able to score higher than 10% on this benchmark.
Note that while we refer to the above categories as involving APIs, they are implemented using static dummy Python function definitions whose signatures are based on real-world APIs. Under the BFCL taxonomy, NVD, VirustTotal and OTX categories would be labeled as Multiple Function but with more candidate functions to choose from. The parallel examples in Climate would be categorized as Parallel Function, while the nested examples in the remaining categories do not have an equivalent. In fact, nested function calls are a somewhat unusual eval since they are typically handled through multi-turn interactions in the function-calling world. This also explains why most models, including GPT-4, struggle with them. In addition to likely being out of distribution from the model’s training data, the LLM must plan the order of function invocations and plug them into the correct argument of the later function calls. We find that despite not being representative of typical use cases, it is a useful eval since it tests both planning and structured output generation while being less susceptible to eval overfitting.
Scoring for NFCL is based purely on string matching on the final function call generated by the model. While this is not ideal, we find that it rarely, if at all, leads to false positives.
| Strengths | Weaknesses |
|---|---|
| Other than OTX, none of the categories appear to be showing signs of saturation and typically reveal a significant gap between models whose function-calling capabilities are expected to be different. | Most function-calling implementations refer to the OpenAI spec; therefore, they are unlikely to solve the nested categories without breaking it down into a multi-turn interaction. |
| The harder categories requiring nested and parallel calls are still challenging, even for models like GPT-4. We believe that while customers may not use this capability directly, it is representative of the model’s ability to plan and execute which is essential for complex real-world applications. | The scoring is based on exact string matching of the function calls and may be leading to false negatives. |
| Some of the function descriptions are lacking and can be improved. Furthermore, several of them are atypical in that they have a large number of arguments or have no required arguments. | |
| None of the examples test relevance detection. |
3. Results from running the evals
In order to make a fair comparison across different models, we decided to run the evals ourselves with some minor modifications. These changes were primarily made to keep the prompting and parsing uniform across models.
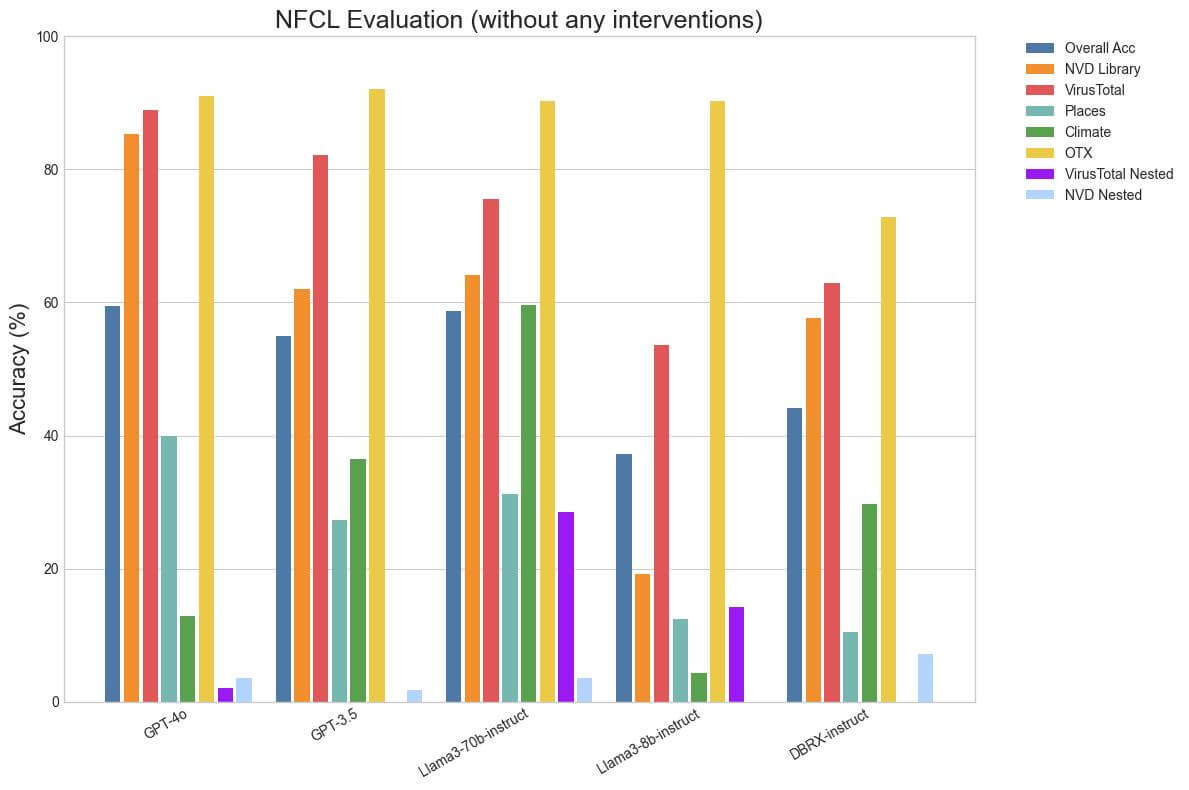
We found that evaluating even on publicly available benchmarks is sometimes nuanced as the behavior can vary wildly with different generation kwargs. For example, we find that accuracy can vary as much as 10% in some categories of BFCL when generating with Temperature 0.0 vs Temperature 0.7. Since function-calling is a fairly programmatic task, we find that using Temperature 0.0 usually results in the best performance across models. We made the decision to include the function definitions and descriptions in the system prompt as repeating them in each user prompt would incur a much higher token cost in multi-turn conversations. We also used the same minimal parsing across models in our implementations for both NFCL and BFCL. Note that the DBRX-instruct numbers that we report are lower than that from the publicly hosted leaderboard while the numbers for the other models are higher. This is because the public leaderboard uses Temperature 0.7 and bespoke parsing for DBRX.
We find that the results on NFCL without any changes align with the expected ordering, in that GPT-4o is the best in most categories, followed closely by Llama3-70b-instruct, then GPT-3.5 and then DBRX-instruct. Llama3-70b-instruct closes the gap to GPT-4o on Climate and Places, likely because they require nested calls. Somewhat surprisingly, DBRX-instruct performs the best on NVD Nested despite not being trained explicitly for function-calling. We suspect that this is because it is not biased against nested function calls and simply solves it as a programming exercise. BFCL reveals some signs of saturation, in that Llama3-70b-instruct outperforms GPT-4o in almost every category except for Relevance Detection, although the latter has likely been trained explicitly for function-calling since it supports tool use. In fact, LLaMa-3-8b-instruct is surprisingly close to GPT-4 on several BFCL categories despite being a clearly inferior model. We posit that a high score on BFCL is a necessary, rather than sufficient, condition to be good at function calling. Low scores indicate that a model clearly struggles with function calling whereas a high score doesn’t guarantee that a model is better at function calling.
4. Improving Function-calling Performance
Once we have a reliable way to evaluate a capability and know how to interpret the results, the obvious next step is to try and improve those results. We found that one of the keys to unlocking a model’s function-calling abilities is specifying a detailed system prompt that gives the model the ability to reason before making a decision on which function to call, if any. Further, directing it to structure its outputs using XML tags and a somewhat strict format makes parsing the function call easy and reliable. This eliminates the need for bespoke parsing methods for different models and applications.
Another key element is ensuring that the model is given access to the details of the function, its arguments and their data types in an effective format. Ensuring that each argument has a data type and a clear description helps elevate performance. Few-shot examples of expected model behavior are particularly effective at guiding the model to evaluate the relevance of the passed functions and discouraging the model from hallucinating functions. In our prompt, we used few-shot examples to guide the model to go through each of the provided functions one-by-one and evaluate whether they are relevant to the task before deciding which function to call.

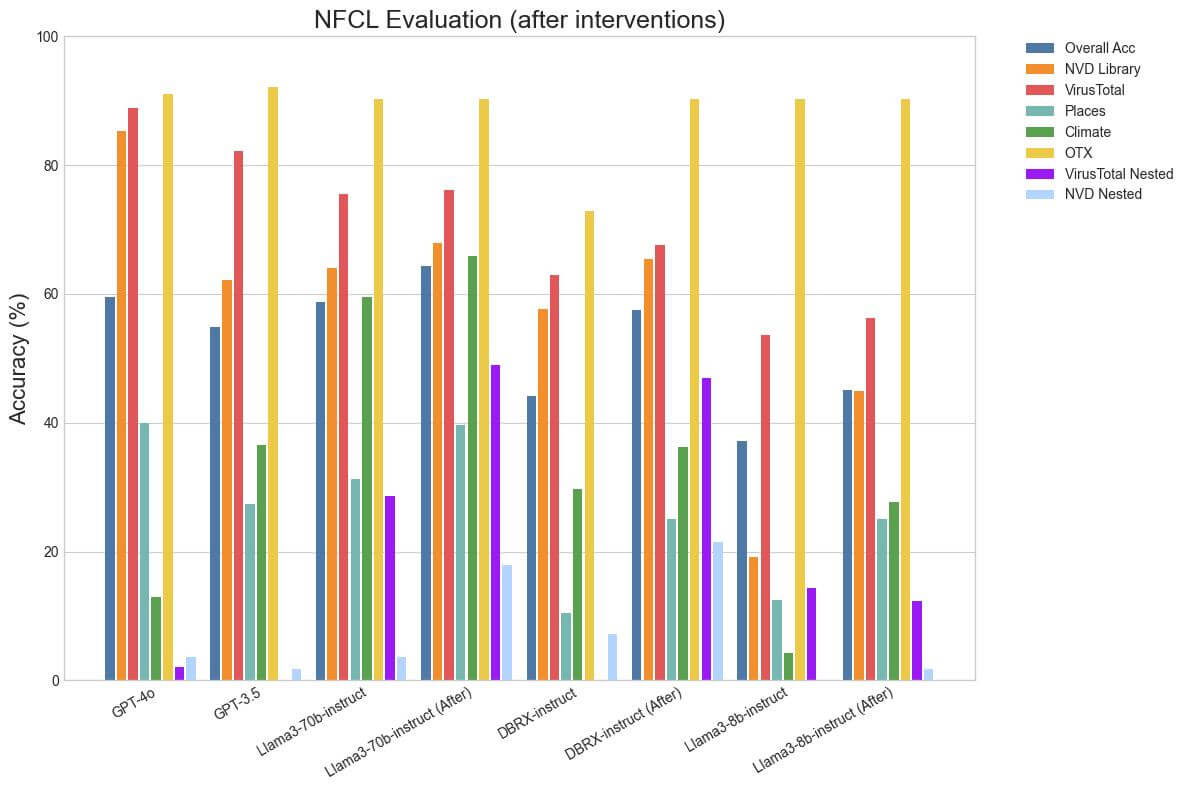
With this approach, we were able to increase the Relevance Detection accuracy of Llama3-70b-instruct from 63.75% to 75.41% and Llama3-8b-instruct from 19.58% to 78.33%. There are a couple of counterintuitive results here: the relevance detection performance of Llama3-8b-instruct is higher than the 70b variant! Also, the performance of DBRX-instruct actually dropped from 84.58% to 77.08%. The reason for this is due to a limitation in the way relevance detection is implemented. Since all the test cases only contain irrelevant functions, a model that is poor at function-calling and calls functions incorrectly or even fails to ever call a function will do exceptionally well in this category. Therefore, it can be misleading to view this number outside of the context of its overall performance. The high relevance detection accuracy of DBRX-instruct before our changes is because its outputs were often structurally flawed and therefore its overall function-calling performance was poor.
The general directions in our system prompt look like this:
Please use your own judgment as to whether or not you should call a function. In particular, you must follow these guiding principles:
1. You may assume the user has implemented the function themselves.
2. You may assume the user will call the function on their own. You should NOT ask the user to call the function and let you know the result; they will do this on their own. You just need to pass the name and arguments.
3. Never call a function twice with the same arguments. Do not repeat your function calls!
4. If none of the functions are relevant to the user's question, DO NOT MAKE any unnecessary function calls.
5. Do not assume access to any functions that are not listed in this prompt, no matter how simple. Do not assume access to a code interpretor either. DO NOT MAKE UP FUNCTIONS.
You can only call functions according to the following formatting rules:
Rule 1: All the functions you have access to are contained within {tool_list_start}{tool_list_end} XML tags. You cannot use any functions that are not listed between these tags.
Rule 2: For each function call, output JSON which conforms to the schema of the function. You must wrap the function call in {tool_call_start}[...list of tool calls...]{tool_call_end} XML tags. Each call will be a JSON object with the keys "name" and "arguments". The "name" key will contain the name of the function you are calling, and the "arguments" key will contain the arguments you are passing to the function as a JSON object. The top level structure is a list of these objects. YOU MUST OUTPUT VALID JSON BETWEEN THE {tool_call_start} AND {tool_call_end} TAGS!
Rule 3: If user decides to run the function, they will output the result of the function call in the following query. If it answers the user's question, you should incorporate the output of the function in your following message.We also specified that the model uses the <thinking> tag to generate the rationale for the function call while specifying the final function call within <tool_call> tags.
Supposed the functions available to you are:
<tools>
[{'type': 'function', 'function': {'name': 'determine_body_mass_index', 'description': 'Calculate body mass index given weight and height.', 'parameters': {'type': 'object', 'properties': {'weight': {'type': 'number', 'description': 'Weight of the individual in kilograms. This is a float type value.', 'format': 'float'}, 'height': {'type': 'number', 'description': 'Height of the individual in meters. This is a float type value.', 'format': 'float'}}, 'required': ['weight', 'height']}}}]
[{'type': 'function', 'function': {'name': 'math_prod', 'description': 'Compute the product of all numbers in a list.', 'parameters': {'type': 'object', 'properties': {'numbers': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The list of numbers to be added up.'}, 'decimal_places': {'type': 'integer', 'description': 'The number of decimal places to round to. Default is 2.'}}, 'required': ['numbers']}}}]
[{'type': 'function', 'function': {'name': 'distance_calculator_calculate', 'description': 'Calculate the distance between two geographical coordinates.', 'parameters': {'type': 'object', 'properties': {'coordinate_1': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The first coordinate, a pair of latitude and longitude.'}, 'coordinate_2': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The second coordinate, a pair of latitude and longitude.'}}, 'required': ['coordinate_1', 'coordinate_2']}}}]
</tools>
And the user asks:
Question: What is the current time in New York?
Then you should respond with:
<thinking>
Let's start with a list of functions I have access to:
- determine_body_mass_index: since this function is not relevant to getting the current time, I will not call it.
- math_prod: since this function is not relevant to getting the current time, I will not call it.
- distance_calculator_calculate: since this function is not relevant to getting the current time, I will not call it.
None of the available functions, [determine_body_mass_index, math_prod, distance_calculator] are pertinent to the given query. Please check if you left out any relevant functions.
As a Large Language Model, without access to the appropriate tools, I am unable to provide the current time in New York.
</thinking>While the exact system prompt that we used may not be suitable for all applications and all models, the guiding principles can be used to tailor it for specific use cases. For example, with Llama-3-70b-instruct we used an abridged version of our full system prompt which skipped the few-shot examples and omitted some of the more verbose instructions. We would also like to emphasize that LLMs can be quite sensitive to indentation and we encourage using markdown, capitalization and indentation carefully.
We computed an aggregate metric by averaging across the subcategories in BFCL and NFCL while dropping the easiest categories (Simple, OTX). We also ignored the Climate column, since it weights the nested function calling ability too highly. Finally, we upweighted relevance detection since we found it particularly pertinent to the ability of models to perform function calling in the wild.
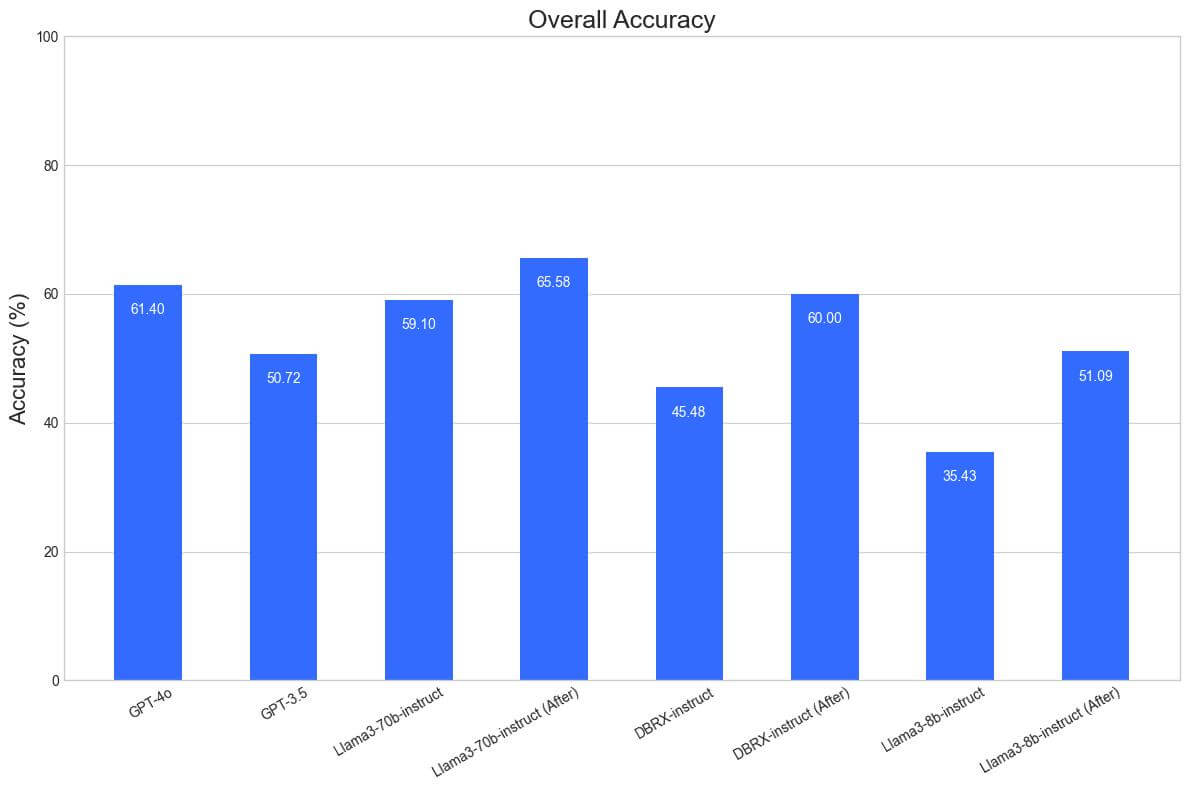
The aggregate metric shows that Llama3-70b-instruct, which was already approaching GPT-4o in quality, surpasses it with our modifications. Both DBRX-instruct and Llama3-8b-instruct which start at below GPT-3.5 quality surpass it and begin to approach GPT-4o quality on these benchmarks.
An additional note is that LLMs do not provide guarantees on whether they can generate output that adheres to a given schema. As demonstrated by the results above, the best open source models exhibit impressive capabilities in this area. However, they are still susceptible to hallucinations and occasional mistakes. One way to mitigate these shortcomings is by using structured generation (otherwise known as constrained decoding), a decoding technique that provides guarantees of the format in which an LLM outputs tokens. This is done by modifying the decoding step during LLM generation to eliminate tokens that would violate given structural constraints. Popular open source structured generation libraries are Outlines, Guidance, and SGlang. From an engineering standpoint, structured generation gives strong guarantees that are useful for productionisation which is why we use it in our current implementation of function calling on the Foundation Models API. In this blog, we have only presented results with unstructured generation for simplicity. However, we want to emphasize that a well-implemented structured generation pipeline should further improve the function-calling abilities of an LLM.
5. Conclusion
Function calling is a complex capability that significantly enhances the utility of LLMs in real-world applications. However, evaluating and improving this capability is far from straightforward. Here are some key takeaways:
- Comprehensive evaluation: No single benchmark tells the whole story. A holistic approach, combining multiple evaluation frameworks like BFCL and NFCL is crucial to understanding a model’s function calling capabilities.
- Nuanced interpretation: High scores on certain benchmarks, while necessary, are not always sufficient to guarantee superior function-calling performance in practice. It is essential to understand the strengths and limitations of each evaluation metric.
- The power of prompting: We have demonstrated that careful prompting and output structuring can dramatically improve a model’s function-calling abilities. This approach allowed us to elevate the performance of models like DBRX and Llama-3, bringing them closer to or even surpassing GPT-4o in certain aspects.
- Relevance detection: This often-overlooked aspect of function calling is crucial for real-world applications. Our improvements in this area highlight the importance of guiding models to reason about function relevance.
To learn more about function calling, review our official documentation and try out our Foundational Model APIs.
Source link
lol