It’s easy to finetune models for our specific tasks; we just need a couple hundred or a few thousand samples. However, collecting these samples is costly and time-consuming. What if, we could bootstrap our tasks with out-of-domain data? We’ll explore this idea here.
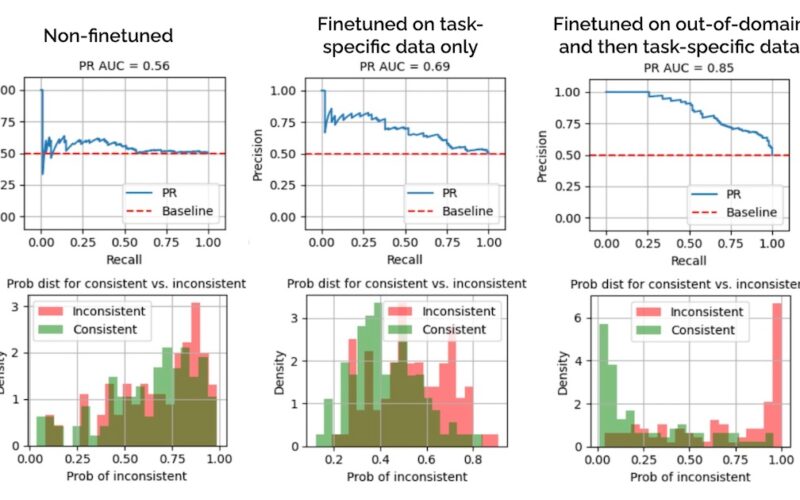
The task is to finetune a model to detect factual inconsistencies aka hallucinations. We’ll focus on news summaries in the Factual Inconsistency Benchmark (FIB). It is a challenging dataset—even after finetuning for 10 epochs on the training split, the model still does poorly on the validation split (middle in image below).
To examine how out-of-domain data helps, we re-instantiate our model and finetune on Wikipedia summaries for 3 epochs before finetuning for 10 epochs on FIB. This led to PR AUC of 0.85 (right below)—a 23% improvement over finetuning on FIB alone. Also, the probability distributions are better separated, making the model more suitable for production where we have to pick a threshold to classify a summary as inconsistent.
Evals on non-finetuned vs. task-specific finetuning vs. out-of-domain + task-specific finetuning
Okay, that was the high-level overview. Next, let’s dive into the details and visuals.
Classifying factual inconsistencies via NLI
We can detect factually inconsistent summaries via the natural language inference (NLI) task. The NLI task works like this: Given a premise sentence and a hypothesis sentence, the goal is to predict if the hypothesis is entailed by, neutral, or contradicts the premise.

Entailment, neutral, and contradiction labels in NLI (source)
We can apply NLI to abstractive summaries too. Here, the source document is the premise and the summary is the hypothesis. Thus, if the summary contradicts the source, that’s a factual inconsistency aka hallucination.

Entailment, neutral, and contradiction labels in abstractive summaries (source)
For the model, we’ll use a variant of BART that has been finetuned on the MNLI dataset. By default, an NLI model outputs probabilities for entailment (label = 2), neutral (label = 1), and contradiction (label = 0). To get the probability of factual inconsistency, we’ll drop the neutral dimension, apply a softmax on the remaining two dimensions, and take the probability of contradiction. It’s really just a single line of code:
def get_prob_of_contradiction(logits: torch.Tensor) -> torch.Tensor:
"""
Returns probability of contradiction aka factual inconsistency.
Args:
logits (torch.Tensor): Tensor of shape (batch_size, 3). The second dimension
represents the probabilities of contradiction, neutral, and entailment.
Returns:
torch.Tensor: Tensor of shape (batch_size,) with probability of contradiction.
Note:
This function assumes the probability of contradiction is in index 0 of logits.
"""
# Drop neutral logit (index=1), softmax, and get prob of contradiction (index=0)
prob = F.softmax(logits[:, [0, 2]], dim=1)[:, 0]
return prob
Finetuning to classify factual inconsistencies in FIB
The Factual Inconsistency Benchmark (FIB) is a dataset for evaluating whether language models can spot factual inconsistencies in summaries. It is based on news summaries from CNN/Daily Mail and XSUM, with 100 and 500 news articles from each respectively. Each news article comes with a pair of summaries where one is factually consistent with the source document while the other isn’t.

Given a gold summary and a distractor, can we assign a higher score to the factually consistent summary vs. the factually inconsistent summary? (source)
Four of the authors annotated the summaries, and each summary was annotated by two annotators. First, they annotated reference summaries as factually consistent or inconsistent. Then, they edited the factually inconsistent summaries to be factually consistent with an emphasis on making minimal edits. Most edits involved removing or changing keywords or phrases that were not found in the news article.
To prepare for finetuning and evaluation, we first excluded the CNN/Daily Mail documents and summaries—they were found to be low quality during visual inspection. Then, we balanced the dataset by keeping one consistent summary and one inconsistent summary for each news article. Finally, we split it into training and validation sets, where validation made up 20% of the data (i.e., 100 news articles). To prevent data leakage, the same news article doesn’t appear across training and validation splits.
Upon visual inspection, it seems challenging to distinguish between consistent vs. inconsistent summaries. The latter tends to contain words from or similar to the source document but phrased to be factually inconsistent. Here’s the first sample in the dataset:
Source: Vehicles and pedestrians will now embark and disembark the Cowes ferry separately following Maritime and Coastguard Agency (MCA) guidance. Isle of Wight Council said its new procedures were in response to a resident’s complaint. Councillor Shirley Smart said it would “initially result in a slower service”. Originally passengers and vehicles boarded or disembarked the so-called “floating bridge” at the same time. Ms Smart, who is the executive member for economy and tourism, said the council already had measures in place to control how passengers and vehicles left or embarked the chain ferry “in a safe manner”. However, it was “responding” to the MCA’s recommendations “following this complaint”. She added: “This may initially result in a slower service while the measures are introduced and our customers get used to the changes.” The service has been in operation since 1859.
Inconsistent summary: A new service on the Isle of Wight’s chain ferry has been launched following a complaint from a resident.
Consistent summary: Passengers using a chain ferry have been warned crossing times will be longer because of new safety measures.
Evaluating the non-finetuned model on FIB confirms our intuition: The model struggled and had low ROC AUC and PR AUC (below). Furthermore, probability distributions for consistent vs. inconsistent summaries weren’t well separated—this makes it unusable in production where we have to pick a threshold to classify outputs as inconsistent.

The non-finetuned model performs badly on FIB
After finetuning for 10 epochs via QLoRA, ROC AUC and PR AUC improved slightly to 0.68 – 0.69 (below). Nonetheless, the separation of probabilities is still poor. Taking a threshold of 0.8, recall is a measly 0.02 while precision is 0.67.

Even after finetuning for 10 epochs, performance isn’t much better
Pre-finetuning on USB to improve performance on FIB
It seems that finetuning solely on FIB for 10 epochs wasn’t enough. What if we pre-finetune on a different dataset before finetuning on FIB?
The Unified Summarization Benchmark (USB) is made up of eight summarization tasks including abstractive summarization, evidence extraction, and factuality classification. While FIB documents are based on news, USB documents are based on a different domain—Wikipedia. Labels for factual consistency were created based on edits to summary sentences; inconsistent and consistent labels were assigned to the before and after versions respectively. Here’s the first sample in the dataset:
Source: Wendy Jane Crewson was born in Hamilton, Ontario, the daughter of June Doreen (née Thomas) and Robert Binnie Crewson. Also in 2012, Crewson began playing Dr. Dana Kinny in the CTV medical drama “Saving Hope”, for which she received Canadian Screen Award for Best Supporting Actress in a Drama Program or Series in 2013.
Inconsistent (before): Wendy Jane Crewson (born May 9, 1956) is a Canadian actress and producer.
Consistent (after): Wendy Jane Crewson is a Canadian actress.
Nonetheless, the labeling methodology isn’t perfect. Summaries that were edited due to grammatical or formatting errors were also labeled as non-factual. For example, in the second sample, the only difference between the consistent and inconsistent summary is that the latter is missing the word “the”. IMHO, both summaries are factually consistent.
Source: When she returned to Canada, Crewson landed a leading role in the television movie “War Brides” (1980) directed by Martin Lavut, for which she received her first ACTRA Award nomination. From 1980 to 1983, she starred in the CBC drama series, “Home Fires”, a family saga set in Toronto during World War II. In 1991, Crewson appeared in her first breakthrough role in the American drama film “The Doctor” starring William Hurt.
Inconsistent (before): She began her career appearing on Canadian television, before her breakthrough role in 1991 dramatic film “The Doctor”.
Consistent (after): She began her career appearing on Canadian television, before her breakthrough role in the 1991 dramatic film “The Doctor”.
Cleaning the USB data is beyond the scope of this write-up so we’ll just use the data as is. (Surprisingly—or unsurprisingly—finetuning on the imperfect USB data was still helpful.) For the training and validation sets, we’ll adopt the split provided by the authors.
First, we re-instantiate the model before finetuning on the USB training split for 3 epochs with the same QLoRA parameters. Then, we evaluate on the FIB validation split.
Finetuning on USB data didn’t seem to help with the FIB validation split. (To be clear, we’ve not finetuned on the FIB data (yet) so the poor performance is expected.) ROC AUC and PR AUC barely improved (below), and the separation of probabilities appears just as bad. Taking the same threshold of 0.8, recall is 0.10 while precision is 0.59. Considering that the FIB data is balanced, precision of 0.59 is barely better than a coin toss.

Finetuning on 3 epochs of USB didn’t seem to help much with FIB…
But what happens when we add 10 epochs of finetuning on FIB? Our model now achieves PR AUC of 0.85—this is a 23% improvement over finetuning on FIB alone (PR AUC = 0.69). More importantly, the probability distributions of consistent vs. inconsistent summaries are better separated (right below), making the model more suitable for production. Relative to finetuning solely on FIB, at the same threshold of 0.8, we’ve increased recall from 0.02 to 0.50 (25x) and precision from 0.67 to 0.91 (+35%).

Or did it? Adding 10 epochs of FIB led to greatly improved performance
Considering that evals for the USB-finetuned (PR AUC = 0.60) and non-finetuned (PR AUC = 0.56) models weren’t that different, this improvement is unexpected. It suggests that, though finetuning on USB didn’t directly improve performance on FIB, the model did learn something useful that enabled the same 10 epochs of FIB-finetuning to achieve far better results. This also means that it may be tricky to directly assess the impact of data blending.
Takeaway: Pre-finetuning on Wikipedia summaries improved factual inconsistency classification in news summaries, even though the former is out-of-domain.
In other words, we bootstrapped on Wikipedia summaries to identify factually inconsistent news summaries. Thus, we may not need to collect as much finetuning data for our tasks if there are open-source, permissive-use datasets that are somewhat related. While this may be obvious for some, it bears repeating that transfer learning for language modeling can extend beyond pretraining to finetuning (also see InstructGPT and its predecessor).
(Also, it’ll likely work just as well if we blend both datasets and finetune via a single stage instead of finetuning in multiple stages on each dataset separately. That said, doing it in stages helped with understanding and visualizing the impact of each dataset.)
• • •
I hope you found this as exciting to read as it was for me to run these experiments. The code is available here. What interesting findings and tricks have you come across while finetuning your own models? Also, what other approaches work well for factual inconsistency detection? Please DM me or leave a comment below!
References
- Tam, Derek, et al. “Evaluating the factual consistency of large language models through summarization.” arXiv preprint arXiv:2211.08412 (2022).
- Krishna, Kundan, et al. “USB: A Unified Summarization Benchmark Across Tasks and Domains.” arXiv preprint arXiv:2305.14296 (2023).
- Lewis, Mike, et al. “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019).
- Williams, Adina, Nikita Nangia, and Samuel R. Bowman. “A broad-coverage challenge corpus for sentence understanding through inference.” arXiv preprint arXiv:1704.05426 (2017).
- Nallapati, Ramesh, et al. “Abstractive text summarization using sequence-to-sequence rnns and beyond.” arXiv preprint arXiv:1602.06023 (2016).
- Narayan, Shashi, Shay B. Cohen, and Mirella Lapata. “Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization.” arXiv preprint arXiv:1808.08745 (2018).
- Dettmers, Tim, et al. “Qlora: Efficient finetuning of quantized llms.” arXiv preprint arXiv:2305.14314 (2023).
- Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
- Stiennon, Nisan, et al. “Learning to summarize with human feedback.” Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
Appendix
You may be wondering how the model performed on USB. I excluded it from the main write-up so as not to distract from the FIB dataset—there were already so many graphs!
Performance of non-finetuned model on USB: The non-finetuned model struggled with the USB validation split and was barely able to distinguish between factually consistent vs. factually inconsistent summaries. The bulk of the probability density for both labels is at 0.0. This may be due to the labeling methodology where some grammatical or formatting errors were incorrectly labeled as factually inconsistent. See the second sample here.

Similarly, the non-finetuned model performs poorly on USB
Performance of finetuned model on USB: After three epochs, PR AUC increased from 0.62 to 0.92. Also, the separation of distributions is closer to what we’d like to see in production. Nonetheless, given the concerns with the labels, it’s hard to say if it’s learned to classify factual inconsistencies or other errors such as grammar and formatting.

But after 3 epochs it does much better
Thanks to Shreya Shankar for reading drafts of this—the highlights in the sample summaries were her brilliant idea.
If you found this useful, please cite this write-up as:
Yan, Ziyou. (Nov 2023). Out-of-Domain Finetuning to Bootstrap Hallucination Detection. eugeneyan.com.
https://eugeneyan.com/writing/finetuning/.
or
@article{yan2023finetune,
title = {Out-of-Domain Finetuning to Bootstrap Hallucination Detection},
author = {Yan, Ziyou},
journal = {eugeneyan.com},
year = {2023},
month = {Nov},
url = {https://eugeneyan.com/writing/finetuning/}
}Share on:
Join 8,000+ readers getting updates on machine learning, RecSys, LLMs, and engineering.
Source link
lol