
In this article, we will discuss OpenELM, a family of Open and Efficient Language Models from Apple.
Apple recently released a series of Small Language Models (SLMs). They are completely open source with weights, training, and inference code. Starting from a few hundred million parameters to just 3 billion parameters (the largest), there are eight models. If tuned properly such models can be easily deployed on edge devices. With this article, we will start a series on working with OpenELM models and making them as efficient as possible by further fine-tuning them and eventually tuning them for edge devices and CPUs.
We will cover the following topics in this article
- We will start with a discussion of the OpenELM paper including the model details, and results. This includes
- The detailing of the OpenELM architecture and how the scaling differs from the standard Transformer Decoder.
- OpenELM variants.
- Pretraining hyperparameters.
- Datasets used for pretraining.
- And benchmark results.
OpenELM – Open and Efficient Language Models
The OpenELM paper was published by Sachin Mehta et al (researchers from Apple). The primary aim of the paper is to create open and reproducible language models. They make the model weights, architecture code, training, and evaluation code completely open source.
Along with this, they approach the architecture modeling with a different layer-wise scaling strategy for efficient parameter allocation within each layer.
Furthermore, the paper also claims that by using a mix of openly available pretraining datasets, the OpenELM models achieve better results while being trained on fewer tokens.
The OpenELM Model and Architecture
As expected, the model is a decoder only language model with:
- No bias in the linear layers
- Using RMSNorm for pre-normalization
- ROPE for positional encoding
- Grouped Query Attention (GQA) instead of Multi-Head Attention (MHA)
- SwiGLU FFN instead of FFN
- Flash Attention for scaled dot-product attention
- And use the Llama 2 Tokenizer
However, contrary to previous approaches, the authors of OpenELM use a layer-wise scaling strategy. This enables more efficient parameter allocation across layers.
Quoting from the paper here which states:
This method utilizes smaller latent dimensions in the attention and feed-forward modules of the transformer layers closer to the input, and gradually widening the layers as they approach the output.
OpenELM – Mehta et al
What this actually means is that instead of using the same number of heads and dimensions in each transformer layer, OpenELM uses different numbers of heads and dimensions in the feed forward blocks.
Diving Deep Into the OpenELM Scaling Strategy
Before that, let’s consider the following notations:
- (N) as the total number of transformer layers
- (d_h) as the input dimension to each transformer layer
- (n_h) as the total number of heads in each transformer layer
- This brings us to the dimension of each head as (d_h = frac{d_{model}}{n_h})
- Additionally, we also have a scalar multiplier in all Transformer models for the FNN layers (blocks), let’s call it (m). As such, the hidden dimension in each FNN block becomes (d_{FFN}=m cdot d_{model})
I would highly recommend going through this Transformer Model from Scratch implementation if you need to get started with Transformers.
To make things clearer, let’s take a look at the following image from a Transformer Encoder Block.
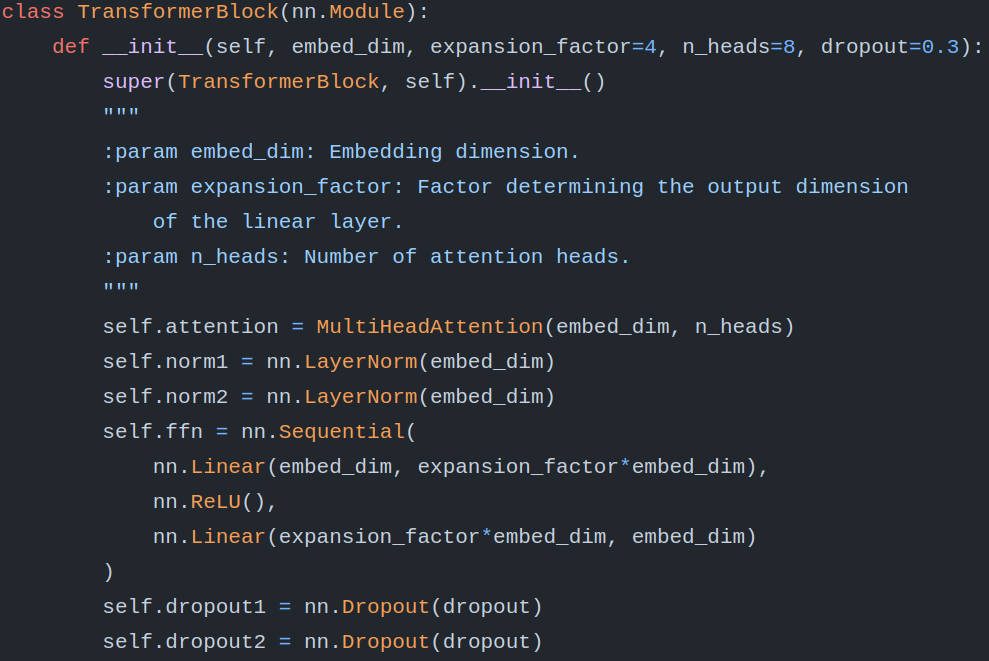
Okay, now, let’s map the notations with the coding name convention from the above code block.
embed_dimis (d_{model})n_headsis (n_h)expansion_factoris (m)
Considering, (d_{model}) is 512 (taking the classic example of the Transformer model from Vashwani et al.). Then, (d_{FFN}) with expansion factor (m) of 4 becomes 512 * 4 = 2048. Considering 8 heads in each transformer layer, the dimension of each head, i.e. (d_h) becomes 512 / 8 = 64.
Now that we have gotten all the notations cleared up, let’s focus on the OpenELM scaling strategy
The authors introduce two parameters for the scaling strategy, (alpha) and (beta).
Here’s how they interact with the rest of the model layers.
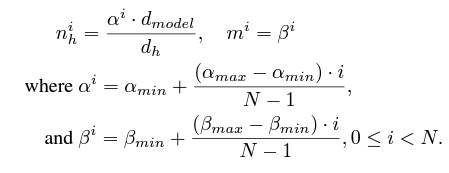
In short, (alpha) and (beta) affect the number of attention heads and the FFN multiplier in each Transformer layer. As the number of Transformer layers increases, so do the heads and FFN multiplier.
We get the standard Transformer Decoder model when (alpha_{min} = alpha_{max}) and (m_i = m). Note that the standard Transformer Decoder may not resonate with the “original Transformer Decoder” from Vashwani et al. if (alpha) and (m_i) are not 1.
OpenELM Variants
The researchers open-source two variants of the model:
- The base pretrained model for next token prediction.
- Instruction tuned models to follow simple instructions and answer basic questions.
All the weights are available on Hugging Face.
Both variants have models with four different parameter scales:
- OpenELM-0.27B with 270 million parameters.
- OpenELM-0.45B with 450 million parameters.
- OpenELM-1.08B with approximately 1.1 billion parameters.
- And OpenELM-3.04B with approximately 3 billion parameters.
OpenELM Pretraining Hyperparameters and Pretraining Datasets
Interestingly enough, the authors train all models for the same number of iterations, that is, 350K.
Before that, here are the other pretraining hyperparameters as mentioned in the paper:
- Usage of cosine learning rate schedule, with 5K warm up steps while decaying the final learning rate to 10% of the maximum learning rate.
- Weight decay of 0.1 and gradient clipping of 1.0.
- Usage of FSDP for some training runs, possibly the billion parameter ones.
- For all models, the global batch size was 4M.
The pretraining dataset is a combination of publicly available datasets. These include RefinedWeb, deduplicated PILE, RedPajama, and a subset of Dolma v1.6.
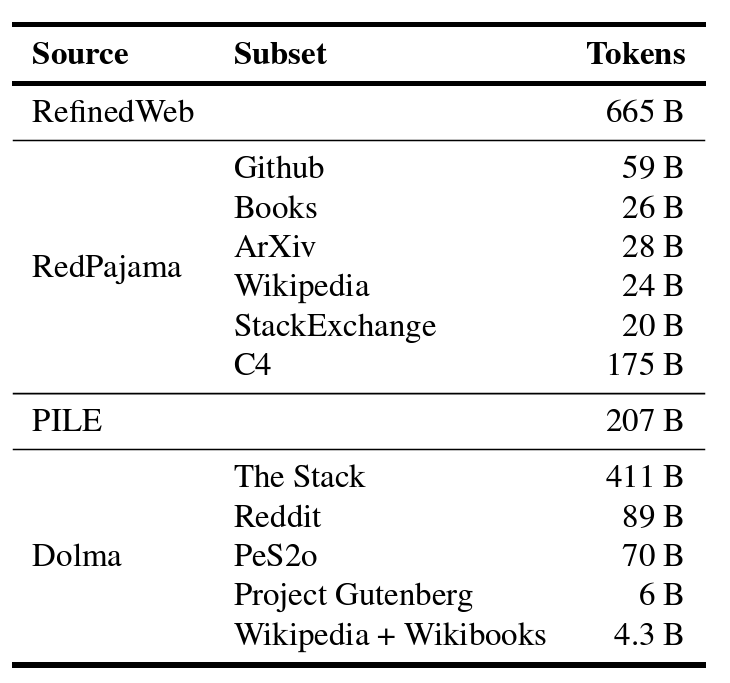
This brings the final dataset size to 1.5T tokens. All models were trained for 350,000 steps.
Now, at this stage, things don’t look so bad. LLama 2 was trained on 2T tokens with a global batch size of 4M. This brings the total number of steps to around 500,000. As the OpenELM models are substantially smaller, the above hyperparameters look good enough at first glance. However, it is very difficult to say anything further as the OpenELM paper does not provide a training/validation loss or perplexity across training runs as the Llama 2 paper does.
Benchmarks and Results
The authors benchmark the models using LM Evaluation Harness. These include tasks from 3 leaderboards: Standard zero-shot metrics, OpenLLM leaderboard, and LLM360.
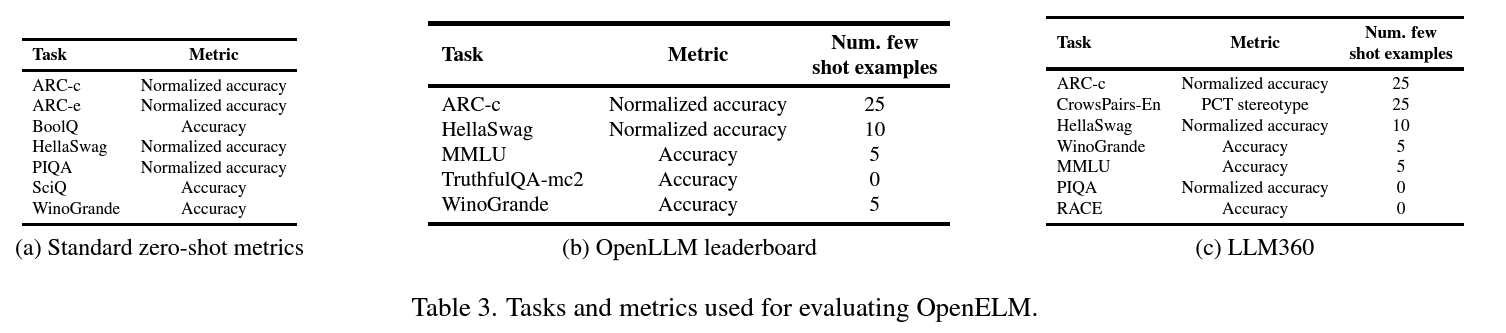
Here are the zero-shot benchmark results of different checkpoints obtained at different training iterations.
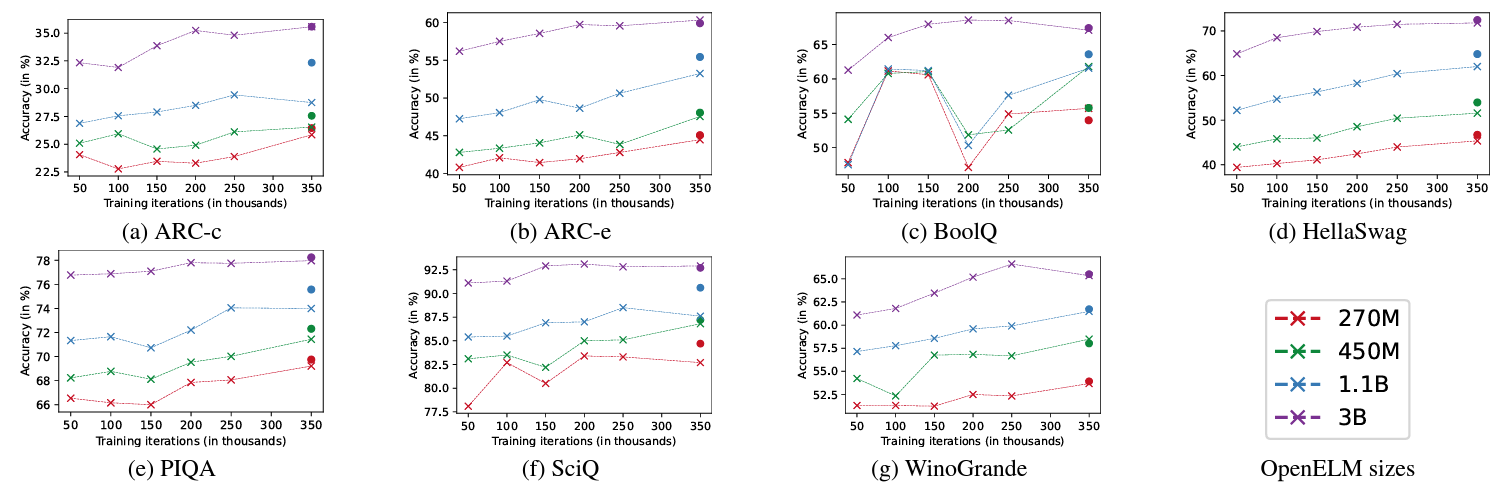
As mentioned in the paper as well, for most tasks, the performance improves as the training goes on. Also, larger models seem to perform better compared to smaller models.
However, there is more to it. Let’s take a look at the tables along with comparisons with other models.
Zero-Shot Benchmarks of OpenELM
Following is the zero-shot benchmark table from the paper.
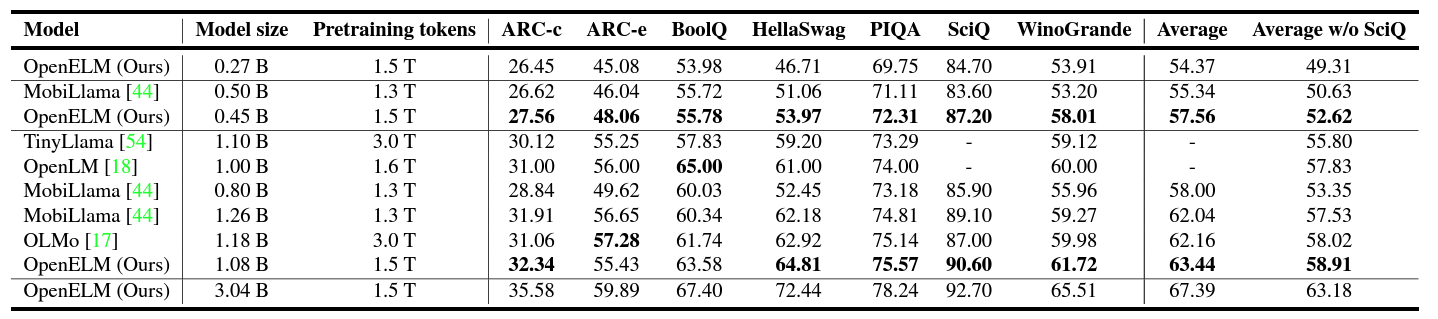
Okay, given that there are not many sub-300 M language models out there right now, the 0.27B is implicitly the best in its class.
Coming to the 0.45B model, it is performing better than its counterpart MobiLlama with 0.5B parameters.
We also see a similar trend for the 1.1B model. For the 3B model, the authors do not compare it with any other and the numbers are higher than all other models in the table.
OpenLLM Leaderboard
The following are few-shot benchmarks apart from the TruthfulQA-mc2.
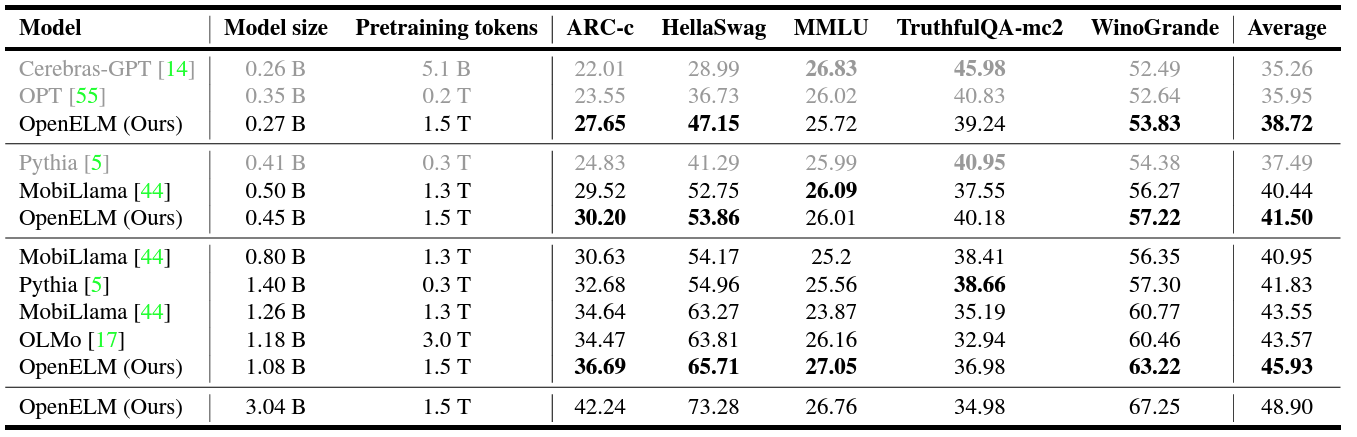
On average scores, the 0.27B, 0.45B, and 1.1B models are better than the other models of similar scale. The OpenELM-3B model again has the highest average score in the table.
LLM360 Tasks
This is again another few-shot results apart from PIQA and RACE which are zero-shot results.

The story remains almost the same here. The average score of OpenELM-0.45B and OpenELM-1.1B are higher than other similar scale models. And the OpenELM-3B is still the best model in the table.
Further Notes on Benchmarks and MMLU Scores
After this analysis, there is one important observation. The OpenELM-0.27B is impressive for its scale. Compared to its counterparts, it is way ahead in the OpenLLM leaderboard. Perhaps we can attribute that to the more training tokens.
However, one particular benchmark dataset catches the eye, MMLU, short for Massive Multitask Language Understanding. Simply put, it is a benchmark dataset with multiple choice questions, and 4 options. The model has to choose the correct option. At the moment, from the above numbers, it seems that each of the mentioned models is making random guesses (all scores are very close to 25).
But that does not mean that models do not perform well, or has been trained wrongly, or the evaluation has been messed up. As pointed out by this Hugging Face article, evaluating on MMLU is not very straightforward as well. There are a few versions online and each can differ in prompt strategy from the other. As the OpenLLM benchmarks are automated ones and a wrapper around the LM Evaluation Harness, we should not blame the authors right away for carrying out the benchmarks wrongly. This needs some serious further analysis which is out of the scope of this article at the moment.
Instruction Tuning Benchmarks
For instruction tuning, the authors train the models on UltraFeedback chat dataset consisting of 60K prompts. They also experiment with DPO (Direct Preference Optimization). On the whole, the results for all models improve across the board.
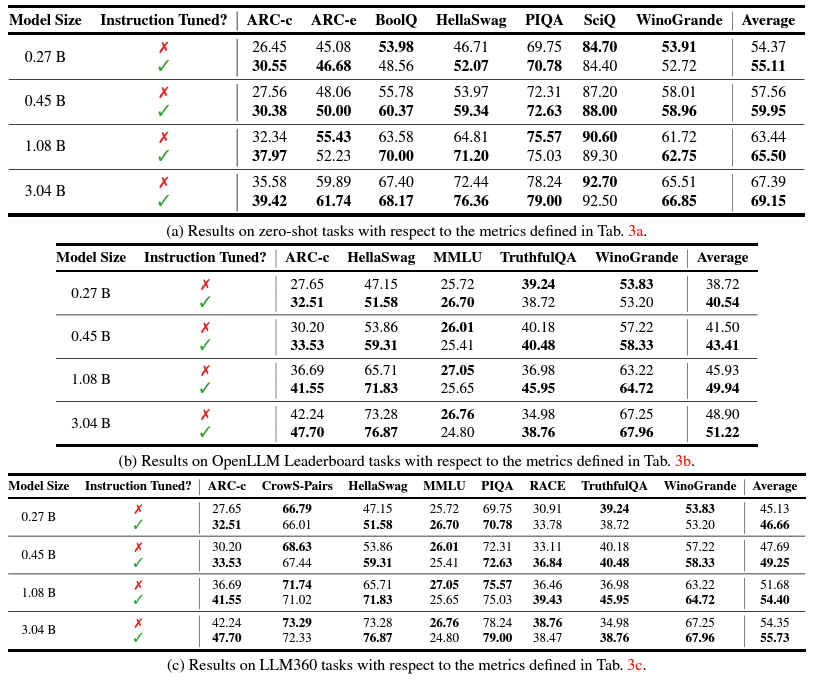
They further fine tune using PEFT with LoRA and DoRA on the CommonSense reasoning benchmark.
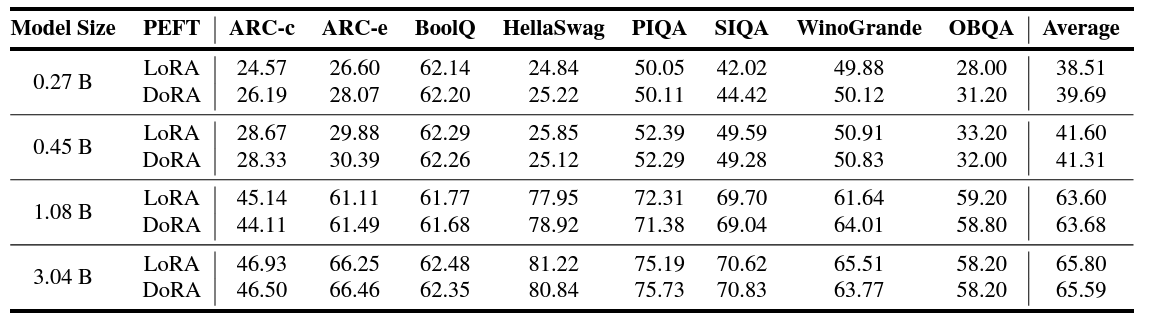
I also highly recommend going through the inference benchmarking section in the paper. The authors lay out the throughput of each model, compare it with others, and lay out the details on how to improve further.
A Few More Benchmarks
Interestingly enough, the authors did not compare with some of the most popular models out there, namely Microsoft Phi and Qwen models. Although they are not completely open-source, we can still pick out the numbers from papers for similar benchmarks and compare them.
Note: We compare only the base pretrained model for in the following sub-sections.
Further note: The Hugging Face OpenLLM leaderboard tasks were updated as I was writing this article. So, the numbers for Phi-1.5 were picked from the papers for whichever benchmarks were available.
Phi-1.5 (1.3B) vs OpenELM-1.1B
The Phi-1.5 contains 1.3B parameters, so, we can easily compare it with the OpenELM-1.1B model.
Here is a chart showing comparing both.
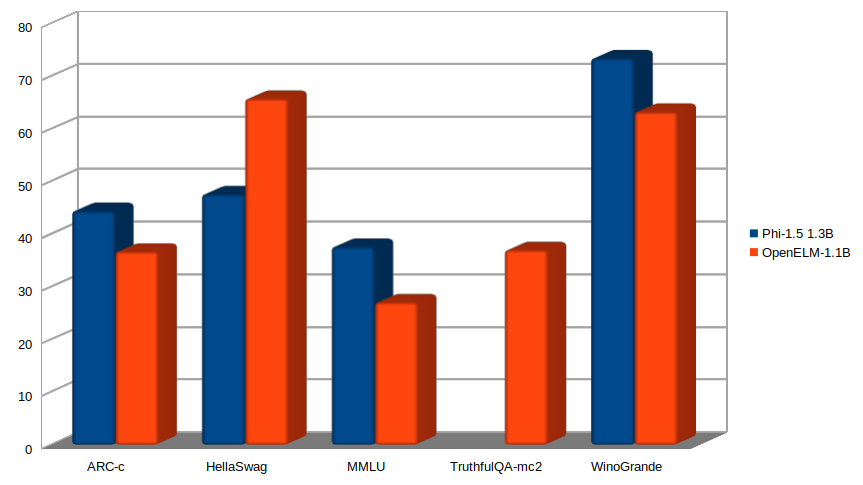
It is interesting to see that Phi 1.5 with much fewer training tokens (150B) surpasses the OpenELM model by a big margin in ARC-c and Winogrande.
Phi-2 (2.7B) vs OpenELM-3B
Another note: Unfortunately, Phi-2 does not contain an official paper, and the OpenLLM leaderboard tasks were updated as mentioned above. So, it became a bit difficult to obtain the actual numbers. We have the following diagram from the official announcement.
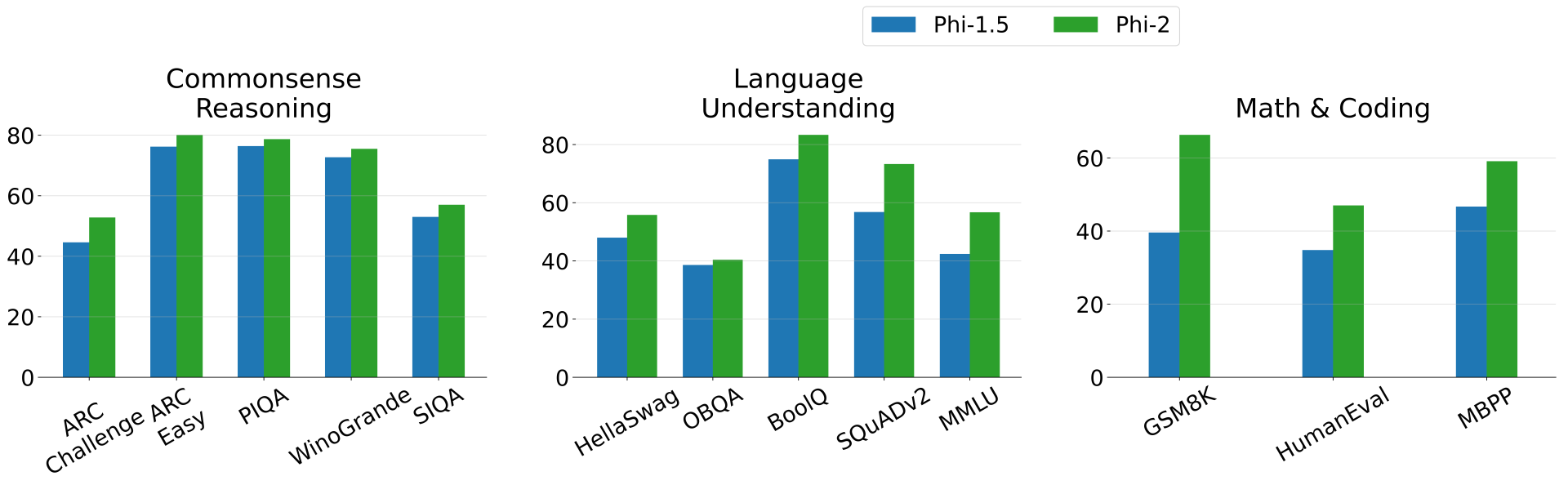
We can interpret a few points from the above:
- Just like Phi-1.5, Phi-2 also surpasses the OpenELM-3B pn ARC-c, WinoGrande, and MMLU.
- However, OpenELM-3B surpasses the Phi model on Hellaswag.
It is worthwhile to note that Phi models are trained on textbook quality and filtered-web data. Maybe we can attribute the higher performance to the dataset curation strategy. However, the dataset is not open like OpenELM models have been trained on. So, we never know exactly what the model has been trained on.
Qwen2-0.5B vs OpenELM-0.45B
Qwen2-0.5B is the most recent model which is comparable to the OpenELM-0.45B. Here are the results for the same benchmark datasets.
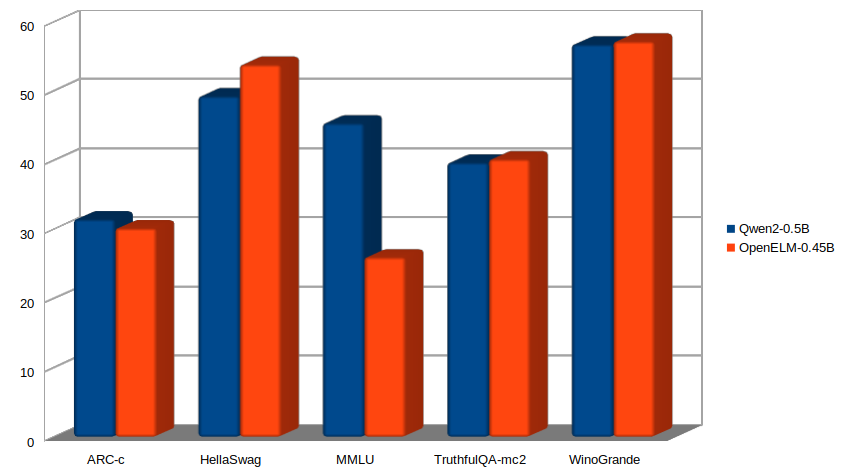
Apart from ARC-c and MMLU, with a smaller parameter count, the OpenELM-0.45B outperforms the Qwen2-0.5B which has been trained on 2.4T tokens.
Keeping aside the skeptical MMLU scores, overall, the smaller (sub-billion parameters) versions of OpenELM look really strong. Of course, further fine-tuning and comparison with other models will reveal more about their real world capabiilties.
Summary and Conclusion
We took a deep dive into the OpenELM model by Apple in this article. We started with a motivation behind the model, followed by its scaling architecture. Then we covered the pretraining dataset and benchmarks revealing how it holds up against other models. We also carried out a few custom benchmark comparisons from scores available online. In the following articles, we will run inference and fine-tuning using the OpenELM models, revealing more insights. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol