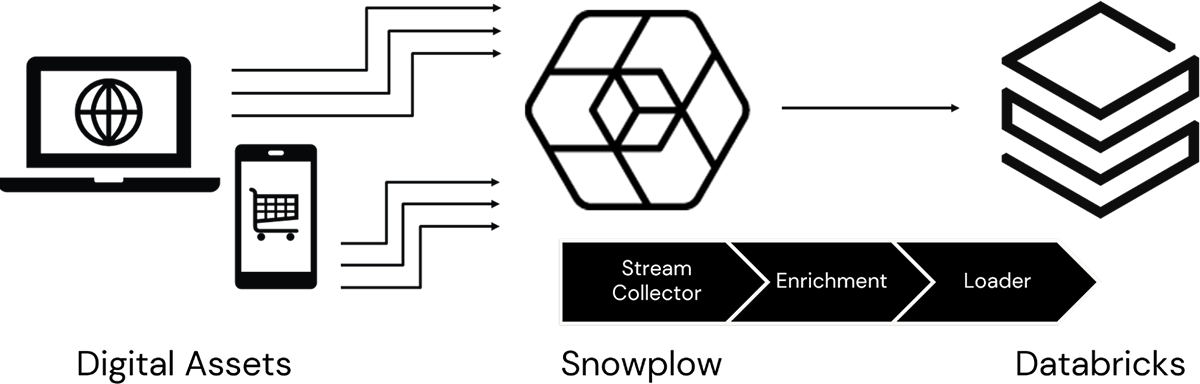
With more and more customer interactions moving into the digital domain, it’s increasingly important that organizations develop insights into online customer behaviors. In the past, many organizations relied on third-party data collectors for this, but growing privacy concerns, the need for more timely access to data and requirements for customized information collection are driving many organizations to move this capability in-house. Using customer data infrastructure (CDI) platforms such as Snowplow coupled with the real-time data processing and predictive capabilities of Databricks, these organizations can develop deeper, richer, more timely and more privacy-aware insights that allow them to maximize the potential of their online customer engagements (Figure 1).
{kind=link}
However, maximizing the potential of this data requires digital teams to partner with their organization’s data engineers and data scientists in ways they previously did not do when these data flowed through third-party infrastructures. To better acquaint these data professionals with the data captured by the Snowplow CDI and made accessible through the Databricks Data Intelligence Platform, we will examine how digital event data originates, flows through this architecture and ultimately can enable a wide range of scenarios that can transform the online experience.
Understanding event generation
Whenever a user opens, scrolls, hovers or clicks on an online page, snippets of code embedded in the page (referred to as tags) are triggered. These tags, integrated into these pages through a variety of mechanisms as outlined here, are configured to call an instance of the Snowplow application running in the organization’s digital infrastructure. With each request received, Snowplow can capture a wide range of information about the user, the page and the action that triggered the call, recording this to a high volume, low latency stream ingest mechanism.
This data, recorded to Azure Event Hubs, AWS Kinesis, GCP PubSub, or Apache Kafka by Snowplow’s Stream Collector capability, captures the basic element of the user action:
- ipAddress: the IP address of the user device triggering the event
- timestamp: the date and time associated with the event
- userAgent: a string identifying the application (typically a browser) being used
- path: the path of the page on the site being interacted with
- querystring: the HTTP query string associated with the HTTP page request
- body: the payload representing the event data, typically in a JSON format
- headers: the headers being submitted with the HTTP page request
- contentType: the HTTP content type associated with the requested asset
- encoding: the encoding associated with the data being transmitted to Snowplow
- collector: the Stream Collector version employed during event collection
- hostname: the name of the source system from which the event originated
- networkUserId: a cookie-based identifier for the user
- schema: the schema associated with the event payload being transmitted
Accessing Event Data
The event data captured by the Stream Collector can be directly accessed from Databricks by configuring a streaming data source and setting up an appropriate data processing pipeline using Delta Live Tables (or Structured Streaming in advanced scenarios). That said, most organizations will prefer to take advantage of the Snowplow application’s built-in Enrichment process to expand the information available with each event record.
With enrichment, additional properties are appended to each event record. Additional enrichments can be configured for this process instructing Snowplow to perform more complex lookups and decoding, further widening the information available with each record.
This enriched data is written by Snowplow back to the stream ingest layer. From there, data engineers have the option to read the data into Datbricks using a streaming workflow of their own design, but Snowplow has greatly simplified the data loading process through the availability of several Snowplow Loader utilities. While many Loader utilities can be used for this purpose, the Lake loader is the one most data engineers will employ as it lands the data in the high-performance Delta Lake format preferred within the Databricks environment and does so without requiring any compute capacity to be provisioned by the Databricks administrator which keeps the cost of data loading to a minimum.
Interacting with Event Data
Regardless of which Loader utility is employed, the enriched data published to Databricks is made accessible through a table named atomic.events. This table represents a consolidated view of all event data collected by Snowplow and can serve as a starting point for many forms of analysis.
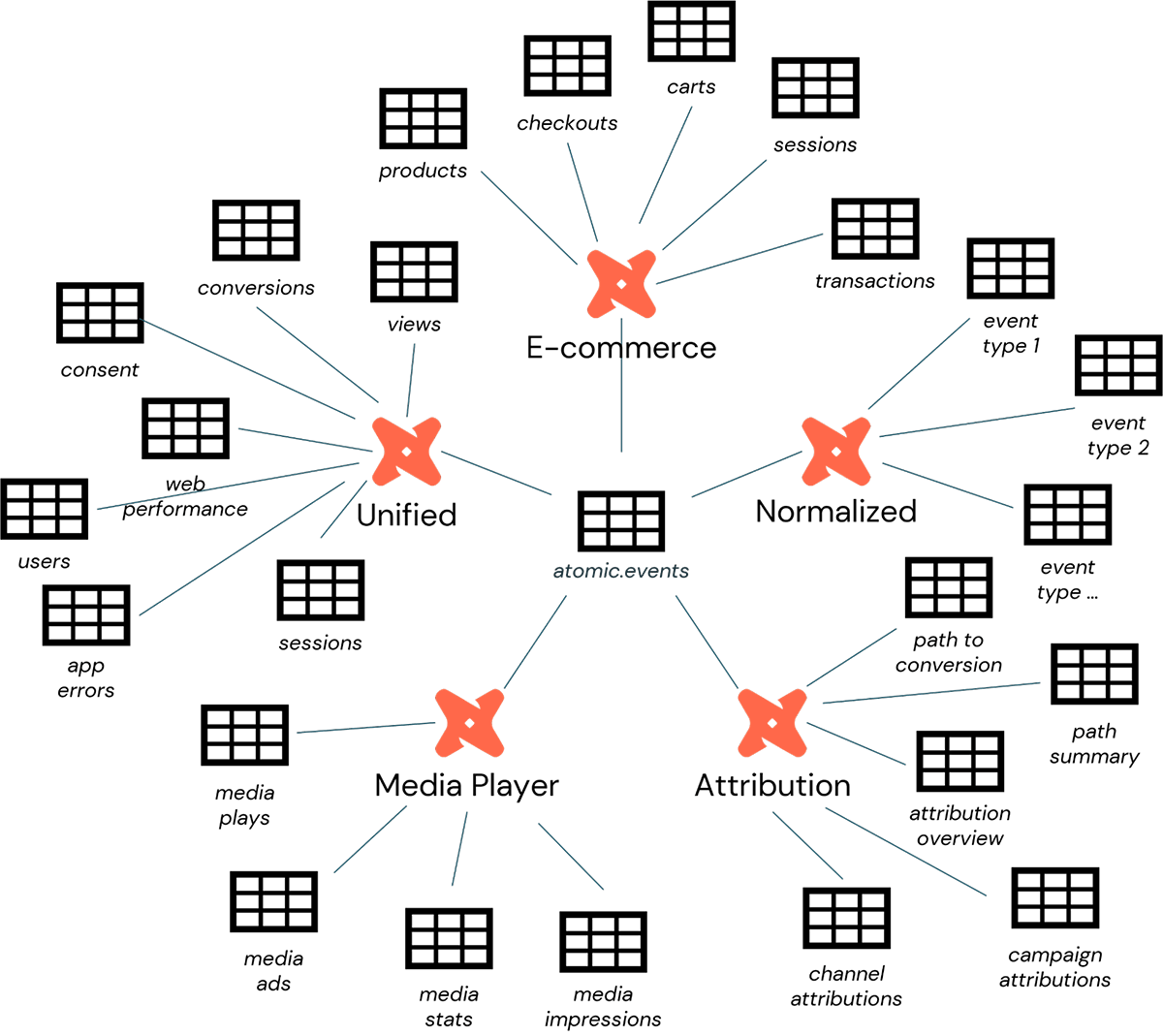
That said, the folks at Snowplow recognize that there are many common scenarios around which event data are employed. To align these data more directly with those scenarios, Snowplow makes available a series of dbt packages through which data engineers can set up lightweight data processing pipelines deployable within Databricks and aligned with the following needs (Figure 2):
- Unified Digital: for modeling your web and mobile data for page and screen views, sessions, users, and consent
- Media Player: for modeling your media elements for play statistics
- E-commerce: for modeling your e-commerce interactions across carts, products, checkouts, and transactions
- Attribution: used for attribution modeling within Snowplow
- Normalized: used for building a normalized representation of all Snowplow event data
In addition to the dbt packages, Snowplow makes available a number of product accelerators that demonstrate how analysis and monitoring of video and media, mobile, website performance, consent data and more can easily be assembled from this data.
The result of these processes is a classic medallion architecture, familiar to most data engineers. The atomic.events table represents the silver layer in this architecture, providing access to the base event data. The various tables associated with each of the Snowplow provided dbt packages and product accelerators represent the gold layer, providing access to more business-aligned information.
Extracting Insights from Event Data
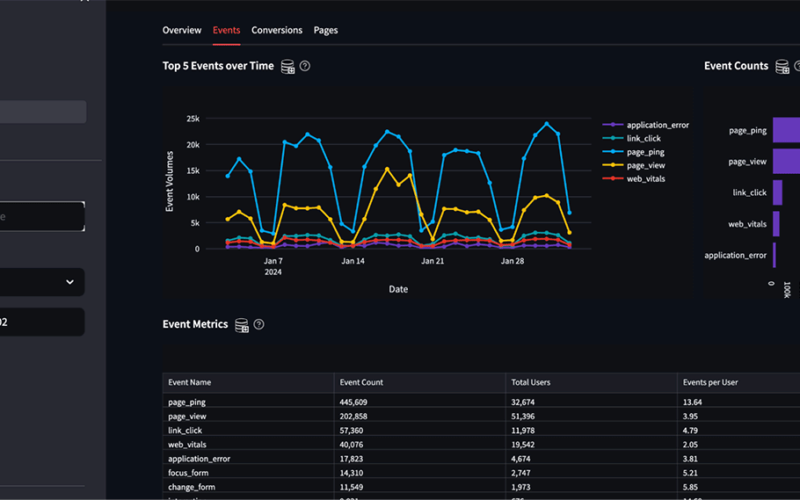
The breadth of the event data provided by Snowplow enables a wide range of reporting, monitoring and exploratory scenarios. Published to the enterprise via Databricks, analysts can access this data through built-in Databricks interfaces such as interactive dashboards and on-demand (and scheduled) queries. They may also employ several Snowplow Data Applications (Figure 3) and a wide range of third-party tools such as Tableau and PowerBI to engage this data as it lands within the environment.
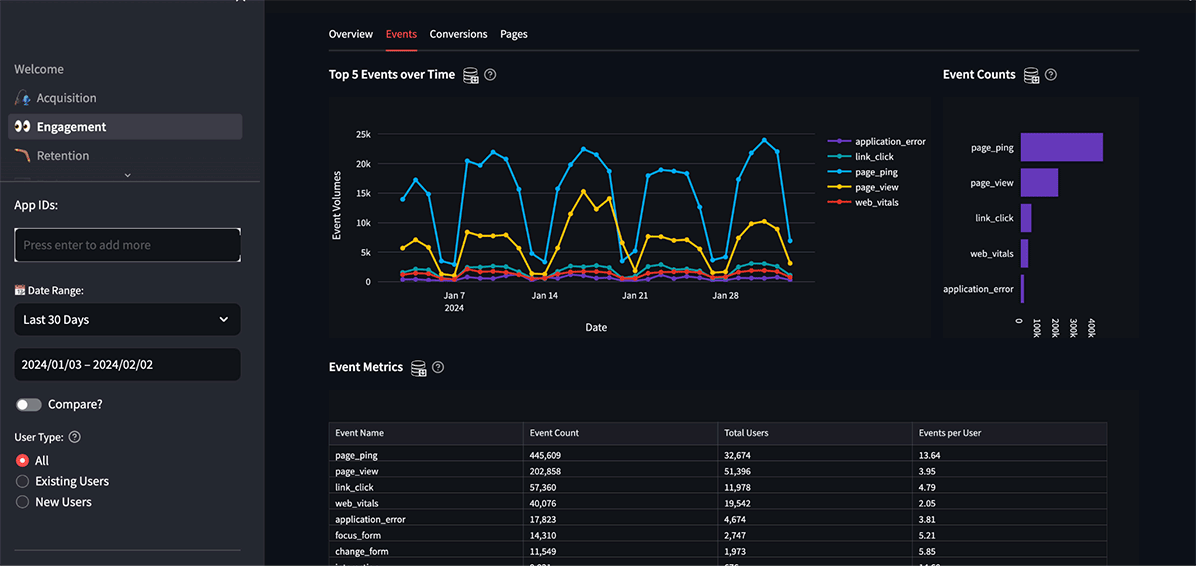
But the real potential of this data is unlocked as data scientists can derive deeper and forward-looking, predictive insights from them. Some common scenarios frequently explored include:
- Marketing Attribution: identify which digital campaigns, channels and touchpoints are driving customer acquisition and conversion
- E-commerce Funnel Analytics: explore the path-to-purchase customers take within the site, identifying bottlenecks and abandonment points and opportunities for accelerating the time to conversion
- Search Analytics: assess the effectiveness of your search capabilities in steering your customers to the products and content they want
- Experimentation Analytics: evaluate customer responsiveness to new products, content, and capabilities in a rigorous manner that ensures enhancements to the site drive the intended results
- Propensity Scoring: analyze real-time user behaviors to uncover a user’s intent to complete the purchase
- Real-Time Segmentation: use real-time interactions to help steer users towards products and content best aligned with their expressed intent and preferences
- Cross-Selling & Upselling: leverage product browsing and purchasing insights to recommend alternative and additional items to maximize the revenue and margin potential of purchases
- Next Best Offer: examine the shopper’s context to identity which offers and promotions are most likely to get the customer to complete the purchase or up-size their cart
- Fraud Detection: identify anomalous behaviors and patterns associated with fraudulent purchases to flag transactions before items are shipped
- Demand Sensing: use behavioral data to adjust expectations around consumer demand, optimizing inventories and in-progress orders
This list just begins to scratch the surface of the kinds of analyses organizations typically perform with this data. The key to delivering these is timely access to enhanced digital event data provided by Snowplow coupled with the real-time data processing and machine learning inference capabilities of Databricks. Together, these two platforms are helping more and more organizations bring digital insights in-house and unlock enhanced customer experiences that drive results. To learn more about how you can do the same for your organization, please contact us here.
Guide your readers on the next steps: suggest relevant content for more information and provide resources to move them along the marketing funnel.
Source link
lol