Data quality monitoring. Data testing. Data observability. Say that five times fast.
Are they different words for the same thing? Unique approaches to the same problem? Something else entirely?
And more importantly-do you really need all three?
Like everything in data engineering, data quality management is evolving at lightning speed. The meteoric rise of data and AI in the enterprise has made data quality a zero day risk for modern businesses-and THE problem to solve for data teams. With so much overlapping terminology, it’s not always clear how it all fits together-or if it fits together.
But contrary to what some might argue, data quality monitoring, data testing, and data observability aren’t contradictory or even alternative approaches to data quality management-they’re complementary elements of a single solution.
In this piece, I’ll dive into the specifics of these three methodologies, where they perform best, where they fall short, and how you can optimize your data quality practice to drive data trust in 2024.
Understanding the modern data quality problem
Before we can understand the current solution, we need to understand the problem-and how it’s changed over time. Let’s consider the following analogy.
Imagine you’re an engineer responsible for a local water supply. When you took the job, the city only had a population of 1,000 residents. But after gold is discovered under the town, your little community of 1,000 transforms into a bona fide city of 1,000,000.
How might that change the way you do your job?
For starters, in a small environment, the fail points are relatively minimal-if a pipe goes down, the root cause could be narrowed to one of a couple expected culprits (pipes freezing, someone digging into the water line, the usual) and resolved just as quickly with the resources of one or two employees.
With the snaking pipelines of 1 million new residents to design and maintain, the frenzied pace required to meet demand, and the limited capabilities (and visibility) of your team, you no longer have the the same ability to locate and resolve every problem you expect to pop up-much less be on the lookout for the ones you don’t.
The modern data environment is the same. Data teams have struck gold, and the stakeholders want in on the action. The more your data environment grows, the more challenging data quality becomes-and the less effective traditional data quality methods will be.
They aren’t necessarily wrong. But they aren’t enough either.
So, what’s the difference between data monitoring, testing, and observability?
To be very clear, each of these methods attempts to address data quality. So, if that’s the problem you need to build or buy for, any one of these would theoretically check that box. Still, just because these are all data quality solutions doesn’t mean they’ll actually solve your data quality problem.
When and how these solutions should be used is a little more complex than that.
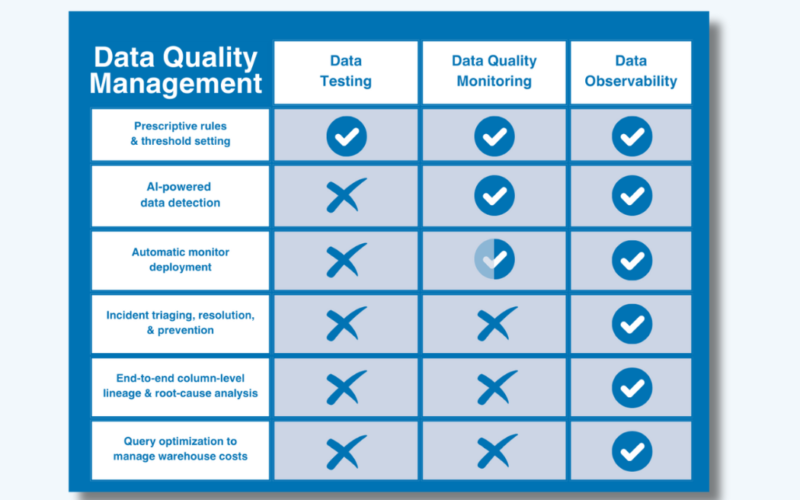
In its simplest terms, you can think of data quality as the problem; testing and monitoring as methods to identify quality issues; and data observability as a different and comprehensive approach that combines and extends both methods with deeper visibility and resolution features to solve data quality at scale.
Or to put it even more simply, monitoring and testing identify problems-data observability identifies problems and makes them actionable.
Here’s a quick illustration that might help visualize where data observability fits in the data quality maturity curve.
Now, let’s dive into each method in a bit more detail.
Data testing
The first of two traditional approaches to data quality is the data test. Data quality testing (or simply data testing) is a detection method that employs user-defined constraints or rules to identify specific known issues within a dataset in order to validate data integrity and ensure specific data quality standards.
To create a data test, the data quality owner would write a series of manual scripts (generally in SQL or leveraging a modular solution like dbt) to detect specific issues like excessive null rates or incorrect string patterns.
When your data needs-and consequently, your data quality needs-are very small, many teams will be able to get what they need out of simple data testing. However, As your data grows in size and complexity, you’ll quickly find yourself facing new data quality issues-and needing new capabilities to solve them. And that time will come much sooner than later.
While data testing will continue to be a necessary component of a data quality framework, it falls short in a few key areas:
- Requires intimate data knowledge-data testing requires data engineers to have 1) enough specialized domain knowledge to define quality, and 2) enough knowledge of how the data might break to set-up tests to validate it.
- No coverage for unknown issues-data testing can only tell you about the issues you expect to find-not the incidents you don’t. If a test isn’t written to cover a specific issue, testing won’t find it.
- Not scalable-writing 10 tests for 30 tables is quite a bit different from writing 100 tests for 3,000.
- Limited visibility-Data testing only tests the data itself, so it can’t tell you if the issue is really a problem with the data, the system, or the code that’s powering it.
- No resolution-even if data testing detects an issue, it won’t get you any closer to resolving it; or understanding what and who it impacts.
At any level of scale, testing becomes the data equivalent of yelling “fire!” in a crowded street and then walking away without telling anyone where you saw it.
Data quality monitoring
Another traditional-if somewhat more sophisticated-approach to data quality, data quality monitoring is an ongoing solution that continually monitors and identifies unknown anomalies lurking in your data through either manual threshold setting or machine learning.
For example, is your data coming in on-time? Did you get the number of rows you were expecting?
The primary benefit of data quality monitoring is that it provides broader coverage for unknown unknowns, and frees data engineers from writing or cloning tests for each dataset to manually identify common issues.
In a sense, you could consider data quality monitoring more holistic than testing because it compares metrics over time and enables teams to uncover patterns they wouldn’t see from a single unit test of the data for a known issue.
Unfortunately, data quality monitoring also falls short in a few key areas.
- Increased compute cost-data quality monitoring is expensive. Like data testing, data quality monitoring queries the data directly-but because it’s intended to identify unknown unknowns, it needs to be applied broadly to be effective. That means big compute costs.
- Slow time-to-value-monitoring thresholds can be automated with machine learning, but you’ll still need to build each monitor yourself first. That means you’ll be doing a lot of coding for each issue on the front end and then manually scaling those monitors as your data environment grows over time.
- Limited visibility-data can break for all kinds of reasons. Just like testing, monitoring only looks at the data itself, so it can only tell you that an anomaly occurred-not why it happened.
- No resolution-while monitoring can certainly detect more anomalies than testing, it still can’t tell you what was impacted, who needs to know about it, or whether any of that matters in the first place.
What’s more, because data quality monitoring is only more effective at delivering alerts-not managing them-your data team is far more likely to experience alert fatigue at scale than they are to actually improve the data’s reliability over time.
Data observability
That leaves data observability. Unlike the methods mentioned above, data observability refers to a comprehensive vendor-neutral solution that’s designed to provide complete data quality coverage that’s both scalable and actionable.
Inspired by software engineering best practices, data observability is an end-to-end AI-enabled approach to data quality management that’s designed to answer the what, who, why, and how of data quality issues within a single platform. It compensates for the limitations of traditional data quality methods by leveraging both testing and fully automated data quality monitoring into a single system and then extends that coverage into the data, system, and code levels of your data environment.
Combined with critical incident management and resolution features (like automated column-level lineage and alerting protocols), data observability helps data teams detect, triage, and resolve data quality issues from ingestion to consumption.
What’s more, data observability is designed to provide value cross-functionally by fostering collaboration across teams, including data engineers, analysts, data owners, and stakeholders.
Data observability resolves the shortcomings of traditional DQ practice in 4 key ways:
- Robust incident triaging and resolution-most importantly, data observability provides the resources to resolve incidents faster. In addition to tagging and alerting, data observability expedites the root-cause process with automated column-level lineage that lets teams see at a glance what’s been impacted, who needs to know, and where to go to fix it.
- Complete visibility-data observability extends coverage beyond the data sources into the infrastructure, pipelines, and post-ingestion systems in which your data moves and transforms to resolve data issues for domain teams across the company
- Faster time-to-value-data observability fully automates the set-up process with ML-based monitors that provide instant coverage right-out-of-the-box without coding or threshold setting, so you can get coverage faster that auto-scales with your environment over time (along with custom insights and simplified coding tools to make user-defined testing easier too).
- Data product health tracking-data observability also extends monitoring and health tracking beyond the traditional table format to monitor, measure, and visualize the health of specific data products or critical assets.
Data observability and AI
We’ve all heard the phrase “garbage in, garbage out.” Well, that maxim is doubly true for AI applications. However, AI doesn’t simply need better data quality management to inform its outputs; your data quality management should also be powered by AI itself in order to maximize scalability for evolving data estates.
Data observability is the de facto-and arguably only-data quality management solution that enables enterprise data teams to effectively deliver reliable data for AI. And part of the way it achieves that feat is by also being an AI-enabled solution.
By leveraging AI for monitor creation, anomaly detection, and root-cause analysis, data observability enables hyper-scalable data quality management for real-time data streaming, RAG architectures, and other AI use-cases.
So, what’s next for data quality in 2024?
As the data estate continues to evolve for the enterprise and beyond, traditional data quality methods can’t monitor all the ways your data platform can break-or help you resolve it when they do.
Particularly in the age of AI, data quality isn’t merely a business risk but an existential one as well. If you can’t trust the entirety of the data being fed into your models, you can’t trust the AI’s output either. At the dizzying scale of AI, traditional data quality methods simply aren’t enough to protect the value or the reliability of those data assets.
To be effective, both testing and monitoring need to be integrated into a single platform-agnostic solution that can objectively monitor the entire data environment-data, systems, and code-end-to-end, and then arm data teams with the resources to triage and resolve issues faster.
In other words, to make data quality management useful, modern data teams need data observability.
First step. Detect. Second step. Resolve. Third step. Prosper.
This story was originally published here.
The post The Past, Present, and Future of Data Quality Management: Understanding Testing, Monitoring, and Data Observability in 2024 appeared first on Datafloq.
Source link
lol