MinIO DataPod reference architecture (Image courtesy MinIO)
The number of companies planning to store an exabyte of data or more is skyrocketing, thanks to the AI revolution. To help streamline the storage buildouts and calm queasy CFO stomachs, MinIO last week proposed a reference architecture for exascale storage that allows enterprises to get to exascale in repeatable 100 PB increments using industry standard off-the-shelf infrastructure, called DataPod.
Ten years ago, at the height of the big data boom, the average analytics deployment among enterprises was in the single-digit petabytes, and only the largest data-first companies had data sets exceeding 100 PB, usually on HDFS clusters, according to AB Periasamy, co-founder and co-CEO at MinIO.
“That has completely shifted now,” Periasamy said. “One hundred to 200 petabytes is the new single-digit petabytes, and the data-first organization is moving towards consolidating all of their data. They’re actually going to exabytes.”
The generative AI revolution is driving enterprises to rethink their storage architectures. Enterprises are planning to build these massive storage clusters on-prem, since putting them in the cloud would be 60% to 70% more expensive, MinIO says. Often times, enterprises have already invested in GPUs and need bigger and faster storage to keep them fed with data.

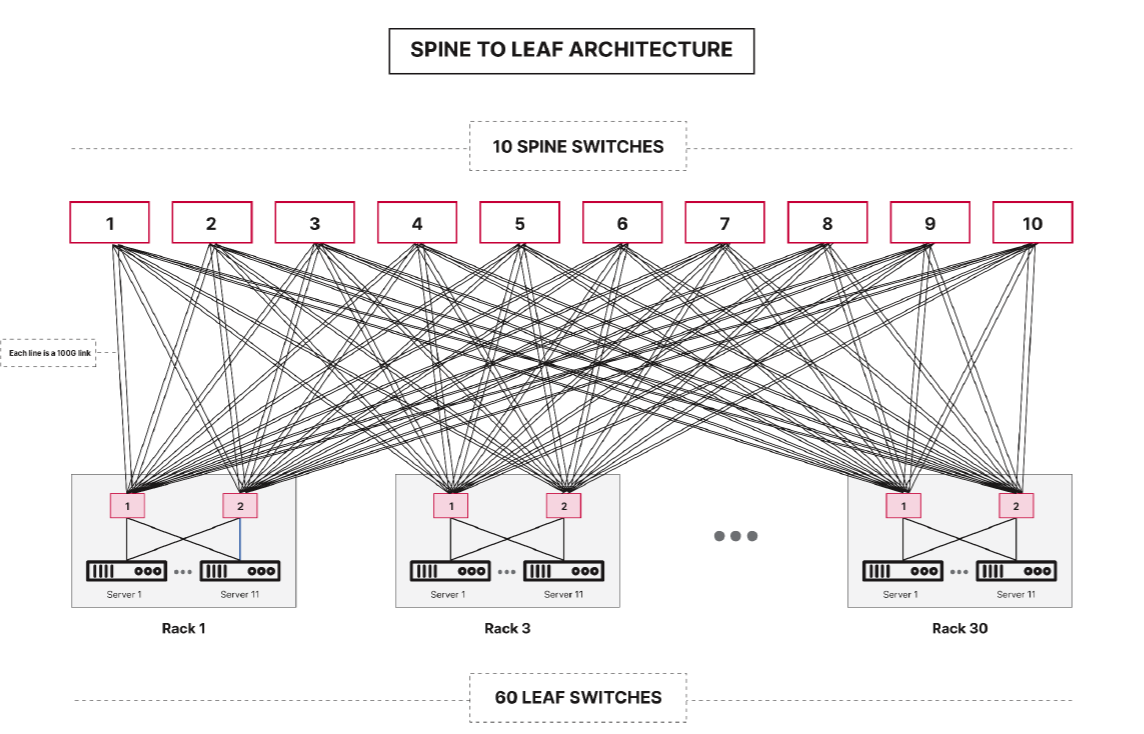
MinIO spells out exactly what goes into its exascale DataPod reference architecture (Image courtesy MinIO)
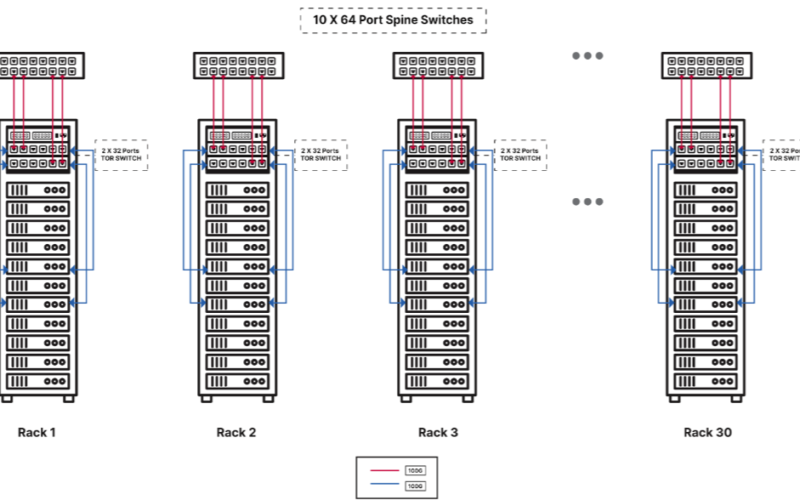
MinIO’s DataPod reference architecture features industry-standard X86 servers from Dell, HPE, and Supermicro, NVMe drives, Ethernet switches, and MinIO’s S3-compatible object storage system.
Each 100 PB DataPod is composed of 11 identical racks, and each rack is composed of 11 2U storage servers, two top of rack (TOR) layer 2 switches, and one management switch. Each 2U storage server in the rack is equipped with a 64-core, single-socket processor, 256GB of RAM, a dual-port 200 Gbe Ethernet NIC, 24 2.5” U.2 NVMe drive bays, and 1,600W redundant power supplies. The spec calls for 30TB NVMe drives, for a total of 720 TB raw capacity per server.
Thanks to the sudden demand for developing AI, enterprises are now adopting concepts about scalability that folks in the HPC world have been using for years, says Periasamy, who is a co-creator of the Gluster distributed file system used in supercomputing.
“It’s actually a simple term we used in the supercomputing case. We called it scalable units,” he tells Datanami. “When you build very large systems, how do you even build and ship them? We delivered in scalable units. That’s how they planned everything, from logistics to rolling out. A core operational system was designed in terms of scalable units. And that’s how they also expanded.
MinIO uses dual 100GbE switches with its DataPod reference architecture (Image courtesy MinIO)
“At that scale, you don’t really think in terms of ‘Oh I’m going to add few more drives, a few more enclosures, a few more servers,’” he continues. “You don’t do one server, two servers. You think in terms of rack units. And now that we are talking in terms of exascale, when you are looking at exascale, your unit is different. That unit we are talking about is the DataPod.”
MinIO has worked with enough customers with exascale plans over the past 18 months that it felt comfortable defining the core tenets in a reference architecture, with the hope that it will simplify life for customers in the future.
“What we learned from our top line customers, now we are seeing a common pattern emerging for the enterprise,” Periasamy says. “We are simply teaching the customers that, if you follow this blueprint, your life is going to be easy. We don’t need to reinvent the wheel.”
MinIO has validated this architecture with multiple customers, and can vouch that it scales up to an exabyte of data and beyond, says MinIO CMO Jonathan Symonds.
“It just takes much friction out of the equation, because they don’t go back and forth,” Symonds says. “It facilitates for them ‘This is how to think about the problem.’ I want to think about it in terms of A, units of measure, buildable units; B, the network piece; and C, these are the types of vendors and these are the types of boxes.”

AB Periasamy, the co-founder and co-CEO of MinIO
MinIO has worked with Dell, HPE, and Supermicro to come up with this reference architecture, but that doesn’t mean it’s limited to them. Customers can plug other hardware vendors into the equation, and even mix and match their server and drive vendors as they build out their DataPods.
Enterprises are concerned about hitting limits to their scalability, which is something that MinIO took into consideration with devising the architecture, Symonds says.
“’Smart software, dumb hardware’ is very much embedded into the kind of corpus of what DataPod offers,” he says. “Now you can think about it and be like, alright, I can plan for the future in a way that I can understand the economics, because I know what these things cost and I can understand the performance implications of that, particularly that they can scale linearly. Because that’s a huge problem: Once you can get to 100 petabytes or 200 petabytes or up to an exabyte, is this concept of performance at scale. That’s the huge challenge.”
In its white paper, MinIO published average street pricing, which a amounted to $1.50 per TB/month for the hardware and $3.54 per TB/month for the MinIO software. At a rate of about $5 per TB per month, a 100PiB (pebibyte) system would cost roughly $500,000 per month. Multiply that times 10 to get the rough cost for an exabyte system.
The large costs may having you looking twice, but it’s important to keep in mind that, if you decided to store that much data in the cloud, the cost would be 60% to 70% higher, Periasamy says. Plus, it would cost much more to actually move that data into the cloud if it wasn’t already there, he adds.![]()
“Even if you want to take hundreds of petabytes into the cloud, the closest thing you’ve got is UPS and FedEx,” Periasamy says. “You don’t have the kind of bandwidth on the network even if the network is free. But network is very expensive compared to even the storage costs.”
When you factor in how much customers can save on the compute side of the equation by using their own GPU clusters, the savings really add up, he says.
“GPUs are ridiculously expensive on the cloud,” Periasamy says. “For some time, cloud really helped, because those vendors could procure all of the GPUs available at the time and that was the only way to go do any kind of GPU experimentation. Now that that’s easing out, customers are figuring out that going to the co-lo, they save tons, not just on the storage side, but on the hidden part–the network and the compute side. That’s where all the savings are enormous.”
You can read more about MinIO’s DataPod here.
Related Items:
Data Is the Foundation for GenAI, MIT Tech Review Says
GenAI Show Us What’s Most Important, MinIO Creator Says: Our Data
MinIO, Now Worth $1B, Still Hungry for Data
Source link
lol