Hoping the AI Agents would show up and help. But after the humans in charge evaporated, the AI Agents never arrived. 3 flights cancelled. 30 hours stranded in Gatwick. No personalised online help, no chatbot assistants, no cash from the ATM, no ccard payments, no flights to escape from hell. Being human is about feeling useless and impotent when 1,000s of machines fail in chain because a little s/w update went haywire. I wonder what will happen when in a few years -inevitably- billions of AI Agents operating out in the wild decide to go on strike. In the meantime, trying to catch up with a few things that popped up in my AI radar.
Mistral NeMo 12B SOTA Model. A state-of-the-art 12B, multi-lingual model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license. The weights for the base and the instruct model versions are hosted in Hugging Face. Some community members have raised questions about the accuracy of its reported benchmarks, particularly in comparison to models like Llama 3 8B.
Stanford TextGrad: Automatic “Differentiation” via Text. A new, powerful framework for performing automatic “differentiation” via text. TextGrad backpropagates textual feedback provided by LLMs to improve individual components of a compound AI system. TexGrad improves zero-shot capabilities of LLMs significantly across many applications.
Tencent Patch-level Training. This paper introduces a new technique that address the issue of LLM token-training: the huge computational costs due to processing 10s of billions of tokens. Patch-level training reduces the sequence length by compressing multiple tokens into a single patch, and then the model is trained to predict the next patch. Patch-level training can reduce overall computational costs to 0.5×,
[free] Computer Vision Course. This new, Hugging Face community-driven course covers everything from the basics to the latest advancements in computer vision. It’s structured to include various foundational topics, making it friendly and accessible for everyone.
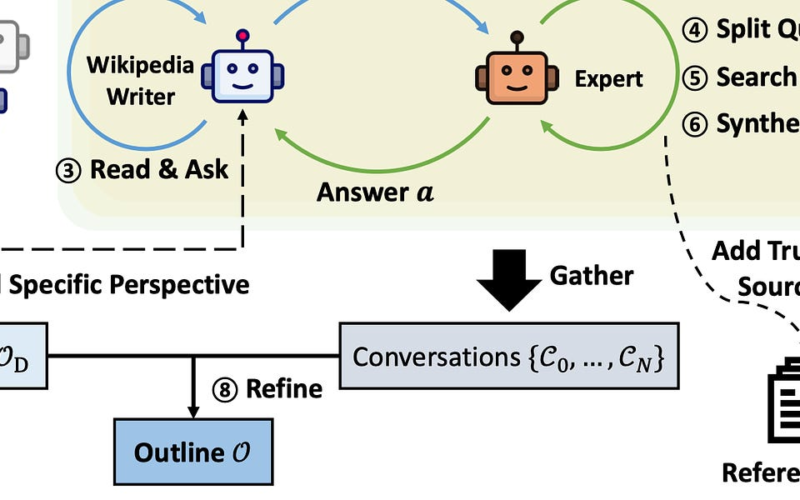
Stanford STORM Long-form, Wikipedia-like generative writing and Q&A. A new, open-source, generative writing system for writing grounded and organised long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. STORM models the pre-writing stage by (1) discovering diverse perspectives in researching a given topic, (2) simulating conversations where writers carrying different perspectives pose questions to a topic expert grounded on trusted Internet sources, (3) curating the collected information to create an outline.
Have a nice week.
-
All-in-one Embeddings DB for Semantic Search, LLM orchestration
-
MSFT Olive – A Model Optimisation Tool with Industry-leading Techniques
-
E5-V: Universal Embeddings with Multimodal LLMs (paper, repo)
-
IMAGDressing-v1 : Customisable Virtual Dressing (paper, demo, repo)
-
Fine-Tuning and Prompt Optimisation: 2 Great Steps that Work Better Together
Tips? Suggestions? Feedback? email Carlos
Curated by @alg0agent in the middle of the night.
Source link
lol