Hey all, excited to finally share a report I have been working on with TextQL, a startup building a fully virtual data analyst. In this report, we go through the modern data stack and where the generative AI opportunities are. At the end, we also feature an interview with TextQL CEO & co-founder, Ethan Ding. You can download a PDF version of this report at the end of this post.
Table of Contents:
-
Modern data stack and business intelligence
-
Modern BI problems & generative AI opporunities
-
Deep dive: Text-to-SQL
-
Notable companies: Incumbents & startups
-
Company feature: TextQL
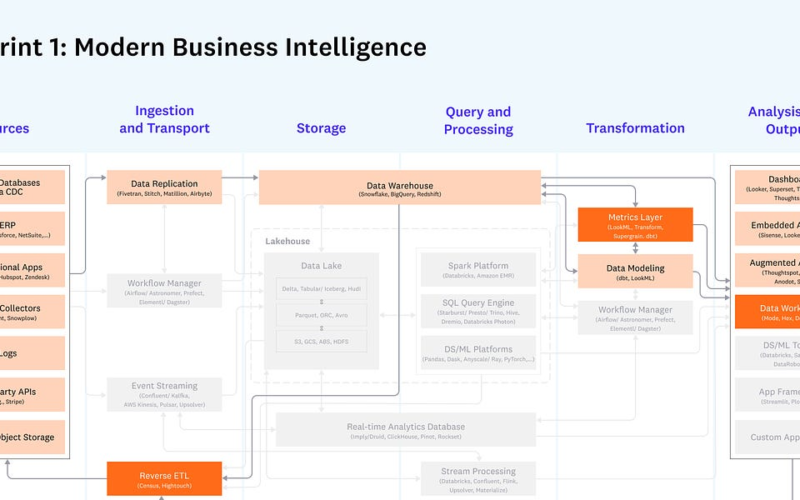
The modern data stack (MDS) emerged as a response to the growing need for managing and analyzing massive amounts of data generated by various sources like web applications, IoT devices, and third-party APIs. The traditional data stack, which often relied on monolithic, on-premises infrastructure and relational databases, struggled to keep up with the increasing volume, variety, and velocity of data. Consequently, the MDS was developed to accommodate these new data challenges more effectively and efficiently.
Two defining features of the MDS are its scalability and modularity. It leverages cloud-based services, distributed storage, and processing systems, allowing organizations to scale their data infrastructure more efficiently and cost-effectively. This approach also supports integration of point solutions for data ingestion, storage, processing, analysis, and visualization, making it adaptable to changing needs.
Modern business intelligence (MBI), built on top of the MDS, focuses on providing faster, more flexible, and scalable analytics solutions. Instead of using manual ETL processes for data integration, modern BI platforms employ automated data pipelines and ELT processes, speeding up data processing and transformation. Moreover, modern BI tools enable self-service analytics. Business users can analyze data without relying on data experts.
For example, a retail company might use the MDS to collect data from various sources like online sales, customer feedback, and social media interactions. They could use a cloud-based data warehouse like Snowflake to store and manage this data, and then employ data processing tools like Apache Spark or dbt for cleaning and transforming it. Finally, the company can leverage modern BI platforms like Tableau or Looker to analyze the data and generate actionable insights to optimize marketing campaigns and drive sales growth.
MBI comprises several components of the MDS architecture: data discovery, data modeling, metrics layer, end-user facing dashboard, and analytics.
-
Data discovery: This process involves identifying, collecting, and integrating various data sources relevant to the business. The objective is to obtain a comprehensive understanding of the data landscape while pinpointing gaps or inconsistencies.
-
Data modeling: This step transforms raw data into an easily analyzable and comprehensible format. Data modeling generally entails creating data structures, defining relationships between datasets, and ensuring data quality and consistency.
-
Metrics layer: This component deals with defining and tracking key performance indicators (KPIs) and other vital metrics. The metrics layer establishes a consistent framework for evaluating and measuring performance over time.
-
End-user facing dashboards & analytics: This aspect focuses on presenting data in a clear and actionable manner for end-users. Dashboards and analytics tools enable users to visualize data, explore trends, and make informed decisions based on insights.
-
Spreadsheets: Although not typically considered part of the MDS architecture, spreadsheets remain a widely used tool for data analysis and manipulation. They facilitate data organization, calculations, and charting.
The modularity of MDS and MBI, while beneficial, has introduced new problems: disconnected tools and unmanageable data swamps. MDS often consist of disconnected tools that need specialized knowledge to integrate. The scalability of storage & compute also leads to a store-everything mentality creating unmanageable data swamps in SQL-centric data stores. With data being ingested from different sources, understanding the context becomes difficult. Tracing back entities and tables become increasingly perplexing with each step losing context. Sometimes even requiring another tool to decipher. Consequently, teams struggle to identify the source of truth, leading to ad-hoc, bespoke tables for answering specific questions. This creates “data debt” as these one-off solutions accumulate over time.
These problems present opportunities for generative AI to unlock the value of MBI.
-
Natural language querying (usually but not limited to text-to-SQL)
Pain point: Non-technical users struggle to extract insights from data stored in databases due to the learning curve associated with SQL or other query languages.
Status quo: Business users often rely on data analysts or engineers to write SQL queries, which is time-consuming and create bottlenecks in decision-making.
Use case solution: Generative AI converts natural language queries into SQL code. For example, a product manager asks, “What is the average revenue per user for the past three months?” The AI generates the SQL query, retrieves the information, and presents the result to the user.
-
Data documentation (table-to-text and SQL-to-text)
Pain point: Understanding and navigating complex data structures is challenging, especially when documentation is lacking or outdated.
Status quo: Data documentation is often created manually, which is time-consuming, error-prone, and difficult to maintain.
Use case solution: Generative AI generates dataset documentation, including descriptions of fields, data types, and relationships between tables. For example, when given a database schema for an e-commerce platform, the AI can create a document explaining each table (e.g., orders, customers, products) and their relationships.
-
Data munging / transformation
Pain point: Data preparation tasks such as classification, transformation, and cleaning are time-consuming and tedious.
Status quo: Data analysts and engineers spend a significant amount of time on manual data wrangling, which slows down the analysis process.
Use case solution: Generative AI automates data preparation tasks. For example, suppose an organization has inconsistent date formats across multiple data sources. The AI identifies the discrepancies, standardizes the date formats, and cleans the data.
-
Natural language analysis
Pain point: Data analysis using SQL is limiting, especially for more advanced techniques like clustering, sentiment analysis, or even simple financial analysis.
Status quo: Analysts and data scientists often need to be familiar with spreadsheet formulas or programming languages to perform advanced data analysis, which requires expertise.
Use case solution: Generative AI models and analyzes data without relying on SQL queries. For instance, an AI model can analyze customer transaction data to identify distinct customer segments based on their purchase behavior.
Text-to-SQL, sometimes called natural language interfaces to databases (NLIDB), refers to the process of converting natural language queries into SQL queries that can be executed on a database. The primary goal of text-to-SQL systems is to provide a more user-friendly and accessible way for non-technical users to interact with databases, eliminating the need to learn complex SQL syntax. In this section, we will explore the historical evolution of text-to-SQL systems, highlighting key milestones and breakthroughs that have shaped the field.
If you observe the data space, you will notice a recurring trend: every couple of years a wave of startups emerge claiming to solve natural language data analysis. But data professionals have grown accustomed to being disappointed by products that are only right 50% of the time or only return outputs assuming your data is perfectly cleaned and your query matches the labels exactly. Catalyzed by OpenAI’s large language models, a new wave of these startups is spinning up again. With foundation models, maybe this time is different.
Rule-Based Systems (1970s-1990s) The journey of text-to-SQL began in the 1970s when computer scientists experimented with systems like LUNAR and CHAT-80. These early systems relied on handcrafted rules and keyword matching to translate natural language queries into SQL. While they demonstrated the potential of text-to-SQL, they struggled to handle complex queries and had limited scalability.
[LUNAR] has made considerable progress towards the ultimate goal of providing a general purpose natural language interface between men and machines. It is an experimental, research prototype of a question-answering system to enable a lunar geologist to conveniently access, compare, and evaluate the chemical analysis on lunar rock and soil composition that is accumulating as a result of the Apollo moon missions
Classical Machine Learning (1990s-2000s) The advent of machine learning in the 1990s brought new possibilities to the field of text-to-SQL. Researchers developed statistical models that could learn from data, allowing for more flexible and accurate query translation. One notable system from this era was PRECISE, which used statistical parsing to map natural language to SQL queries.
Deep Learning (2010s) The 2010s marked the arrival of deep learning, which had a transformative impact on text-to-SQL. Researchers started using neural networks, particularly sequence-to-sequence (seq2seq) models, to automatically generate SQL queries from natural language. These models were capable of handling complex queries and achieved impressive accuracy on benchmark datasets like WikiSQL.
Transformers & Foundation Models (2020s) The 2020s have seen the rise of transformer-based models, which have become the foundation of modern text-to-SQL systems. Pre-trained models like T5, BERT, & GPT-3 have been fine-tuned for text-to-SQL tasks, achieving state-of-the-art results. Off-the-shelf GPT-4 performs exceedingly well as well. These models are powerful because they’re trained on vast amounts of text, allowing them to capture linguistic patterns and relationships. Another key development in this era is embedding analytical tasks in a conversational interface, reflecting that real-world analysis is done iteratively in practice.
The introduction of benchmark datasets, such as WikiSQL and Spider, played a crucial role in driving progress in text-to-SQL research. These datasets provided large-scale, annotated examples of natural language queries and corresponding SQL queries, allowing researchers to train and evaluate their models in a standardized manner. In 2018, 11 Yale students at the LILY lab released the Spider dataset, the latest text-to-SQL performance benchmark containing 10K+ questions for over 200 databases across 100+ domains. It is currently the academic standard for measuring text-to-SQL models. The following year, the same lab released CoSQL, a conservational text-to-SQL dataset based on the original Spider dataset. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from 3k dialogues querying 200 complex DBs spanning 138 domains.
In April 2023, a team using the system DIN-SQL + GPT-4 reached the top of the Spider benchmark leaderboard with a score of 85%, outperforming the previous best by 5% points. This is a significant margin since the next 10 models perform within 5% points of each other.

While off the shelf LLM models provide a good baseline of syntactically correct SQL queries based on academic benchmarks, in practice queries are more complex. LLMs need to paired with an execution engine that evaluates, modifies, and validates the raw LLM SQL output. There are different approaches this from training a fine-tuned model, like PICARD, to a more flexible system, like DIN-SQL.
Query engine = LLM + execution engineSince DIN-SQL is the state-of-the-art as of writing, we’ll focus on it. The acronym stands for Decomposed In-Context Learning of Text-to-SQL with Self-Correction and was created by Mohammadreza Pourreza and Davood Rafiei from University of Alberta. To identify where LLMs fall short, both researchers tested off-the-shelf LLMs like OpenAI Codex’s SQL outputs against the Spider dataset. The incorrect outputs were then categorized to understand where off-the-shelf results fail.
-
Schema Linking: LLMs often struggle with correctly identifying and linking elements of the database schema (like column names, table names, or entities) mentioned in the natural language queries.
-
Complex Queries: LLMs can struggle with more complex queries, especially those involving multiple table joins, nested queries, or set operations. They may not correctly identify all the tables required or the correct keys to join the tables.
-
Grouping: Queries that require a GROUP BY clause can pose a challenge. The model may not recognize the need for grouping or may use the wrong columns for grouping the results.
-
Invalid SQL: Sometimes, the SQL statements generated by LLMs have syntax errors and cannot be executed.

Armed with a grounded understanding of where LLMs fail, they designed the four modules that comprise DIN-SQL.
-
Schema Linking Module: This module identifies references to database schema and condition values in natural language queries. It’s a critical preliminary step in most existing text-to-SQL methods. It helps to link the natural language query to the relevant parts of the database schema.
-
Classification & Decomposition Module: This module classifies each query into one of three classes: easy, non-nested complex, and nested complex. It then decomposes the query accordingly. This step helps to break down the problem into smaller, more manageable sub-problems.
-
SQL Generation Module: This module generates the SQL query based on the results of the previous modules. Depending on the complexity of the query, it may use different prompts for each query class. This step is where the actual SQL query is generated.
-
Self-Correction Module: This module corrects minor mistakes in the generated SQL queries. It’s a final step to ensure the accuracy and correctness of the generated SQL queries.

While an 85% score on the Spider dataset is impressive, there are still areas to improve the query engine and other parts of the MBI stack.
-
Improved Text to SQL Models: While general models like GPT-4 perform well out-of-the-box, specialized text-to-SQL models will eventually beat them. These fine-tuned models are expected to deliver quicker response times, require fewer parameters, and offer broader context windows for understanding tabular relationships.
-
Data Modeling and ETL: Initial solutions in this field will depend on existing data models and cleaned data to deliver analytics. However, it’s anticipated that future products will be capable of extracting Common Table Expressions (CTEs) and tidying up SQL files exceeding 1,000 lines and refactoring them into staging tables. These products could potentially generate an ETL pipeline immediately upon indicating an API source for data, thereby streamlining data transfer into warehouses and optimizing the computation of necessary joins.
-
Documentation and Dictionaries: Maintaining updated data dictionaries and documentation of past queries has been a persistent challenge for data teams. Given that most data in warehouses are inserted and then neglected due to the ease of data ingestion compared to its cleaning and comprehension, data refactors often render these dictionaries obsolete. The advent of self-maintaining data documentation could significantly benefit existing data teams, serving as a useful reference for language models to grasp and adapt to the specific terminologies used by distinct teams.
-
End-to-End Decision Making: While text-to-SQL accuracy is a noteworthy development, the substantial value lies in enabling non-technical individuals to pose abstract questions like “What should I do today?” and allowing the product to deduce the user’s priorities, propose data-driven queries, interrogate the data, perform the analysis, and present decision recommendations with accompanying trade-offs. The new code interpreter module from OpenAI that analyzes CSV files using Python represents a fresh approach to this area.
-
ThoughtSpot unveiled Sage (March 2023), initially powered by using GPT-3 and now GPT-4.
-
Tableau/Salesforce announced Tableau GPT (May 2023), which is powered by Einstein, the AI platform powering Salesforce’s portfolio of products.
-
Microsoft Power BI announced Copilot for PowerBI alongside a unified analytics solution Fabric (May 2023). The Fabric solution is their “full stack” MDS, combining disparate data subsystems from data storage to data connectors to PowerBI into a single UX.
-
Google Looker has “Ask Looker” (January 2022), offering users the ability to find and visualize data insights through natural language queries. Surprisingly, nothing has been announced yet regarding the use of foundation models explicitly. But given Google Cloud’s momentum, we can expect something soon.
The past couple of months have seen an explosion of activity as new startups experiment with the latest models. While the dynamics of generative AI gives incumbents the benefit of more data and wider distribution, the modularity of the MDS has given startups potential foothold to wedge into. Instead of creating a market map of all companies, which is expanding every day, we are instead highlighting four notable startups approaching the problem space in distinct ways:
-
TextQL is building a fully virtual data analyst, Ana, that can navigate the MDS. It’s cataloging and enriching the semantic layer, then using that as a reference to write accurate SQL and Python to return business insights to end users. Approach: serve business users via a chat interface

-
Equals is a modern spreadsheet that can do what we expect from Excel & Google Sheets but its also albel to pull from data warehouses and other systems via SQl or their native integrations. It recently announced Command+K, which allows users to smartly fill a spreadsheet using existing data on the spreadsheet. Approach: serve end users via a spreadsheet interface
-
Hex is a platform designed to simplify the work of modern data teams by streamlining the entire analytics workflow. Hex users can mix and match SQL, Python, and no-code in its “polyglot” notebooks, with a built-in AI assistant that can generate, edit, debug, and explain code. Hex allows users to build dashboards, reports, or interactive tools and publish them with a click. Approach: serve data scientists in a notebook IDE

-
Numbers Station is automating the data stack by first focusing on the data transformation steps. With natural language, users can build transformation pipelines and export it into dbt scripts. It can also perform intelligent data munging such as classifying the data of other columns and fuzzy matching records across data sources. Approach: serve data analysts & analytics engineers



TextQL is building a fully virtual data analyst that can navigate the MDS. It’s cataloging and enriching the semantic layer, then using that as a reference to write accurate SQL and Python to return business insights to end users.

Ethan Ding (CEO) was the data product manager at Tackle, where he grew his team of data engineers from 4 to 12 and built across snowflake and redshift, dbt and Astronomer, in-house data catalogs, and all BI tools. During his time there he ran every SQL report for the business to save engineering time for six months
Mark Hay (CTO) was a Senior Software Engineer at Meta for three years, where he worked on ML and Heuristic Abuse Detection Systems, processing over 50 million queries per second, maintained the largest Haskell Deployment in the world at over 7 million lines of code, and optimized ML infrastructure to save over $1.5m a year in computing cost.
Q: What is TextQL?
Imagine a data analyst – they can document your data, write queries, ask you what you mean by your question, find the right dashboards, and create reports with provide recommendations for what you need to do. We’re building that, but our analyst doesn’t sleep, doesn’t need to context switch, and answers all of your questions pretty much instantly.
Q: Why did you start TextQL? What’s the origin story of eventually getting conviction to start a company? Especially in a space where there’s a lot of incumbents
While I was at Tackle, I was doing all of the SQL-monkey-work for the whole company – and I realized I could automate myself out of that role once I came across the improving performance of language model’s code generation abilities. Then I looked at the incumbents and challengers and realized that everyone was building with and for the models that existed already, instead of looking at the slope and building forward facing products.
When we forecast 10 years in the future, I don’t think the role of the data analyst, someone who works on top of a layer of cleaned dbt tables and communicates with business users about what they need, is going to exist anymore. Every single piece of that, from the question clarification, dashboard navigation, SQL writing and Python analysis will be automated. From there, we worked backwards to figure out how to build that future.
Q: How does TextQL work?
TextQL’s product has 3 parts, which can be thought of as the rails, the train, and the station.
The rails is the catalog and semantic layer, we document every dbt model and column in your warehouse and then enrich that information in the semantic layer. We then store all of that information, alongside an index of your BI tools within a data catalog.
The train is the query engine that uses a vector database to identify the correct output from your data assets to return to a user. It gets you the table and data you’re looking for.
The station is our python interpreter, it picks up the table output and analyzes it for leading indicators, linear regression, predictive analysis, and anything else an analyst can do in a notebook.
Q: Why couldn’t I just grab open source models out there or use ChatGPT?
While the models seem good enough on academic benchmarks, they don’t have infinite context windows. Relying on the metrics or semantics layer adds that additional guardrail, and we can return existing dashboards when that’s the right solution (as opposed to trying to generate new SQL every time).
Also – do you really want to rebuild everything we’ve built from scratch? There are a dozen integrations, metadata management, context window management, model tuning, validation test set question generation, validation testing, model selecting, vector indexing, and the list keeps going…
Q: Anything proprietary you’re doing differently than everyone else?
There’s no other team out there that’s enriching your documentation and metadata, indexing every single asset, storing that in a language model-friendly way, and then using that to power analysis on the other side.
Our secret sauce is our Capsule (name still pending). When we were taking a customer live, we realized a lot of domain-specific information easily maps onto a semantic layer. We invented a Capsule, a unit of domain-specific metadata that we can synthesize from every conversation you have with TextQL – making it more intelligent every time you interact.
Q: What’s your wedge into this market?
With a lot of our peers, they often market their value as sidestepping the data and BI team directly or indirectly. But all companies will have data teams that will be the custodian of the data. As someone who ran the data team at Tackle and run their SQL reports, a text-to-SQL solution is not enough. We will build deep integrations with their semantic layer (dbt, Coalesce) and data catalogs (Alation, Collibra), ensuring that the definitions we use are the same as the ones they’ve laid out. That model will win over the trust of data teams in the short run by delivering accurate summaries of their past work.
Q: Data analysis is probably one of the most crowded application space for generative AI, maybe 2nd or 3rd to writing assistants. What are you worried about?
I’m doing this because I think the future will be a world where anyone will be analyze their data without any technical skills – no more bottlenecks on the data team for other people to get the analysis they need. If someone else cracks the perfect experience that solves the problem for everyone – I’d be perfectly happy with that.
This is a massive opportunity and a massive problem, and I think we have a solid shot on goal here. Is it a layup? Probably not, but I’m excited never the less.
PDF Version: Download
Source link
lol