Introduction
Just like having a massive pile of books won’t make you a genius unless you read and understand them, a mountain of data won’t make a powerful AI if it’s not properly labeled.
Data annotation involves labeling data points, such as images or text, with relevant information, enabling the algorithms to learn and make sense of the patterns within the data. In simple terms, data annotation helps the algorithms distinguish between what’s important and what’s not with the help of labels and annotations, allowing them to make informed decisions and predictions. While annotation can be performed manually by humans, there are dedicated tools used for labeling that are widely used for creating the data for machine learning use cases.
Now you might be wondering, why exactly we need these annotation tools when we can label the ML data on our own. We can just ask human labelers to do the annotation e.g. through Amazon’s Mechanical Turk. To understand this, you must understand various factors associated with human labelers. While human labelers can do the work, it might take them a lot of time to label a colossal amount of data, and this time will lead to higher costs. Along with this, preparing data manually can lead to biases and mistakes due to humans in the loop. These are the most important reasons why you might require a tool for annotation that can solve all these issues while streamlining the entire data annotation process with semi or full automation. As there exist plenty of annotation tools, sometimes it becomes hard to select the one that best suits your requirements and needs.
In this article, you’ll discover the essential key metrics to consider when evaluating data annotation tools, explore a curated list of some of the best tools available, and gain valuable insights into how to choose the right tool for your specific needs. By the end, you’ll be equipped with the knowledge and tools you need to take your machine-learning projects to the next level. Note that in this article, we will use the terms labeling and annotating interchangeably.
Choosing the right data annotation tool is like picking the perfect paintbrush for your masterpiece. The wrong tool can make the job messy and frustrating. That’s why considering key metrics is crucial. These metrics help you evaluate a tool’s capabilities and ensure it aligns with your project’s specific needs. Here’s a breakdown of some essential factors to consider.
Performance Metrics for Tools
Accuracy, precision, mean average precision, and IoU are the cornerstones of high-quality data annotation for different types of annotation tasks. The idea is to compare the annotated data with ground truth annotations and use one of these metrics (depending on the use case) to evaluate if the annotations are correct.
- Accuracy: This measures the overall correctness of your annotations. Imagine a tool that labels 90% of your cat images correctly. That’s a good accuracy score! But what about the other 10%? If ensuring a high percentage of correctly labeled data is critical (like for medical imaging), prioritize tools with high accuracy scores. Here is how accuracy is calculated.
Accuracy = (Number of correctly labeled items) / (Total number of items) x 100%
- Precision: This tells you how relevant your positive labels are. Going back to our cat example, with high precision, most of the images the tool labels as “cat” are cats (and not, say, dogs). If minimizing irrelevant positive labels is crucial (like filtering out inappropriate content), focus on precision. Here is how the precision is calculated
Precision = (Number of true positives) / (Total number of positive labels) x 100%
- Mean Average Precision (mAP): This metric is widely used for object detection tasks. It works on the concept of computing the average precision across all the classes annotated by the tool providing the single measure of the tool’s performance. The higher the mAP value, the better the annotation tool for object detection tasks. You can learn more about this metric here.
- IoU (Intersection Over Union): This is one of the most popular measures for object detection and segmentation tasks. It measures the overlap between the tool annotated bounding box (or segmentation mask) and the ground truth bounding box. Higher IoU indicates the better localization accuracy of the tool in creating the bounding boxes. You can learn more about IoU in this article.
All these measures are essential for building reliable machine-learning models. Inaccurate or imprecise annotations can lead the model down the wrong path, resulting in poor performance. Remember that all these metrics are important, but their relative weight depends on your specific project requirements and the type of task you are dealing with. Apart from these mentioned ones, other ML performance metrics like F1-Score, Confusion Matrix, Cohens’ Kappa for Multi-class Annotation, etc. can also be used for evaluating the annotation tool’s performance depending on the task and use case.
Support for Annotating Different Types of Data and Annotations
The ability of the tools to annotate different kinds of data is another important factor to take into account when assessing data annotation software. It evaluates the tool’s adaptability and compatibility with various data types, including text, audio, video, and photos. A strong data annotation tool should support you to annotate a variety of data formats, giving your machine learning projects flexibility and scalability. Accurate and thorough annotations require a tool that can handle many data sources, whether you’re working with voice analysis, natural language processing, or image identification.
Apart from support for various data types, a tool should also be versatile in terms of support for different annotation types. If you are paying for an annotation tool, you might require it to support different annotation types such as preparing labels for classification, creation of bounding boxes for object detection, creation of masks for segmentation tasks, temporal annotations for the video and audio annotations, custom annotation for specific project requirements, etc. A robust annotation tool should provide intuitive interfaces and tools for annotators to create, edit, and visualize annotations of various types efficiently.
Scalability
Imagine your project growing with more data, more tasks, and more annotators! Scalability refers to a tool’s ability to handle growing data volumes and user bases. Here’s why it matters:
- Efficiency: As your project progresses, you might need to annotate massive datasets. A scalable tool ensures smooth performance even with large data loads, preventing slowdowns and bottlenecks.
- Collaboration: If your project involves multiple annotators, scalability ensures the tool can effectively manage user access, task distribution, and collaborative annotation workflows. This becomes crucial for maintaining consistency and quality as your team grows.
By choosing a scalable data annotation tool, you future-proof your project and avoid the hassle of switching tools halfway through if your needs expand. Look for tools that offer efficient data storage, parallel processing capabilities, and user management functionalities to ensure smooth sailing as your project scales up.
Ease of use
Not everyone is a data annotation ninja! A user-friendly interface is essential for a smooth and efficient annotation experience. Here’s why ease of use is a must-consider metric:
- Reduced Learning Curve: A user-friendly interface is easy to learn, minimizing training time and getting your team to annotate data quickly.
- Minimized Errors: Clear labeling options and intuitive workflows prevent mistakes, ensuring the quality and accuracy of your annotations.
- Improved Morale: A frustration-free tool makes data annotation more enjoyable, boosting team morale and efficiency.
Look for tools that offer features like drag-and-drop functionality, customizable labeling options, and clear annotation guidelines within the interface. By prioritizing ease of use, you can empower your team to focus on what matters most which is high-quality data annotation.
Customizability
Customizability is essential in selecting a data annotation tool, especially for projects with unique requirements or specialized datasets. It empowers users to tailor the annotation process, defining custom types and workflows. For example, an annotation could allow one to customize workflow to support multi-stage review workflows involving multiple experts like annotators, radiologists, and clinicians. This flexibility ensures precise alignment with project objectives, enhancing annotation quality and model performance. For instance, in projects with domain-specific terminology, customizability accommodates intricacies for more accurate annotations.
A customizable tool adapts to various project needs, from dataset characteristics to workflow preferences. Organizations can streamline annotation processes and optimize outcomes. Additionally, customization fosters innovation, enabling the exploration of new techniques and approaches. Prioritizing customizability unlocks the tool’s full potential for advancing machine learning projects.
Collaboration features
Data annotation is often a team effort! Collaboration features are crucial for managing multiple annotators and ensuring a smooth workflow. The collaboration feature allows you to assign tasks to specific team members, track progress, and maintain communication throughout the annotation process. This keeps everyone on the same page and ensures efficient task completion.
Collaborative tools often include features like multi-annotator workflows and annotation history tracking. This allows you to leverage the combined expertise of your team, identify potential inconsistencies, and ensure the overall quality of your annotated data. By prioritizing collaboration features, you can empower your team to work together effectively, leading to faster annotation completion and higher-quality data for your machine-learning projects.
Pricing and affordability
Data annotation can be an investment, so finding a tool that fits your budget is crucial. Data annotation tools come with various pricing models (subscriptions, pay-per-task, etc.). Evaluating pricing structures and features ensures you choose a tool that delivers the capabilities you need without breaking the bank.
The most expensive tool isn’t always the best! Consider the tool’s functionalities, scalability, and overall value proposition about its cost. Look for tools that offer transparent pricing and features that directly benefit your project’s needs. By carefully considering pricing and affordability, you can find a data annotation tool that empowers your project’s success without straining your budget.
Here is a tabular summary of all the features that you should look for in a data annotation tool:
Choosing the perfect data annotation tool can feel overwhelming with so many options available. But worry not! This section unveils some of the best tools in the market, each with its unique strengths and functionalities. You will be introduced to various tools that cater to different project needs and budgets.
Label Studio
Label Studio is an open-source data annotation platform offering a high degree of customization. It allows you to create custom labeling tasks and interfaces tailored to your specific project needs.
Label Studio provides a range of annotation tools, such as bounding boxes, polygons, and text classification, along with support for active learning and model-assisted labeling. Its pricing model offers flexible options based on usage and features, with options for both individual users and enterprise-level projects.
As Label Studio includes a lot of annotation types and supports annotation for all kinds of data, it is a little complex to learn and set it up. But you need not worry as DagsHub has your back here. Label Studio is integrated into DagsHub, and every repository in DagsHub comes with a fully configured Label Studio workspace that lets you easily annotate your data while being fully API compatible with the Label Studio API. You can learn more about this integration here.
Pros:
- Offers extensive customization options for workflow management.
- Provides support for active learning and model-assisted labeling.
- Free to use, ideal for budget-conscious projects or those requiring unique functionalities.
Cons:
- Label Studio has many advanced features like auto-labeling and magic wand selection, which means that the learning curve may be steep for new users.
- Setting up and customizing Label Studio might require some programming knowledge.
- Troubleshooting and maintenance might be more challenging compared to commercially supported platforms.
DagsHub aims to solve the last two issues i.e. set up and customization, and troubleshooting and maintenance if you use Label Studio on DagsHub.
Researchers and developers can leverage Label Studio’s customization features for unique annotation tasks. For instance, they might use it to annotate complex scientific data (like microscopy images) or create custom labeling interfaces for specific research projects.
Labelbox
Labelbox is a powerful data annotation platform designed to streamline the process of labeling datasets for machine learning tasks. It offers a user-friendly interface and support for annotating various data types including images, text, and videos. You can access Labelbox through its website here or explore its GitHub repository here. Additionally, you can experience a demo of Labelbox to understand its functionality better.

Labelbox offers a variety of tools for different annotation tasks, like bounding boxes for objects, polygons for shapes, and semantic segmentation for complex labeling. It also helps to organize your data efficiently with features like labeling version control, data filtering, and project templates. The platform operates on a subscription-based pricing model, offering various plans tailored to different user needs, ranging from free plans for individual users to enterprise plans with advanced features and dedicated support.
Pros:
- User-friendly interface for efficient annotation.
- Supports various data types and complex labeling tasks.
- Strong collaboration features for team projects.
- Integrates with popular machine learning tools.
Cons:
- Custom pricing plans might be less transparent compared to fixed pricing models.
- The free plan has limitations on data volume and features.
Labelbox is used by companies like NASA and Sharper Shape for tasks like annotating videos for detecting Martian frost patterns and annotating pipeline images and videos for detecting utility defects respectively.
SuperAnnotate
SuperAnnotate is a comprehensive data annotation platform designed to simplify the process of annotating large datasets for machine learning projects and also provides support for various data formats (images, text, audio, video). You can explore its functionality on the platform’s GitHub repository here.
SuperAnnotate helps annotate data with a wide range of tools like bounding boxes, polygons, and speech tagging. It also offers tools to streamline repetitive tasks and improve annotation efficiency. On top of that, it helps to manage teams, assign tasks, and ensure data quality through collaborative annotation features. SuperAnnotate offers a free plan with limitations and paid plans with varying pricing structures (subscriptions, pay-per-task).
Pros:
- User-friendly interface for various data types.
- Automation features boost annotation efficiency.
- Real-time collaboration features for seamless teamwork.
- Advanced annotation tools for diverse data types and projects.
Cons:
- Free plan limitations might require upgrading for larger projects.
- Pricing structure complexity might require careful evaluation for optimal cost.
Companies like BOSCH and Smith and Nephew use SuperAnnotate for tasks like labeling video data for object-tracking applications in automobiles and healthcare.
Appen
Appen is a well-established data annotation service provider with a global workforce of annotators. They offer human-in-the-loop solutions for various data types, ensuring high-quality annotations for your machine-learning projects.
Appen provides a comprehensive suite of annotation tools and services, including image, text, and audio annotation, as well as natural language processing (NLP) services. The platform offers flexible pricing models based on project complexity, volume, and turnaround time, ensuring cost-effective solutions for businesses of all sizes.
Pros:
- Access to a large pool of qualified annotators.
- Expertise in handling diverse data types.
- Focus on high-quality annotations.
Cons:
- Pricing might be higher compared to self-service annotation tools.
- Less control over the annotation process compared to in-house teams.
- Turnaround times may be longer for complex or large-scale projects
Appen helps developers in annotating sensor data to train perception algorithms and supports NLP researchers in annotating text data for sentiment analysis and language modeling tasks. Dolby and Siemens are among various organizations that use Appen.
V7
V7 focuses on speeding up the data annotation process through automation and a user-friendly interface. It specializes in image and video annotation, offering tools for tasks like object detection and image segmentation.
V7 offers a range of annotation features, including bounding boxes, polygons, key points, and semantic segmentation masks, allowing users to annotate various types of data with precision and accuracy. The platform provides flexible pricing options tailored to the specific needs of each project, with transparent pricing based on the volume and complexity of annotations required.
Pros:
- Speeds up the annotation process through automation.
- Collaboration features, such as real-time editing and commenting to facilitate teamwork and communication among annotators.
- Well-suited for image and video annotation tasks.
Cons:
- Limited data type support compared to some all-in-one platforms.
- Might not be ideal for highly complex annotation projects requiring extensive customization.
V7’s platform is used in various applications like medical imaging analysis. For instance, It might help annotate medical scans to train AI models for disease detection. Abyss and Genmab are some of the companies that use V7 for annotation tasks.
Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a managed data labeling service in the SageMaker ecosystem. It supports various annotation tasks like bounding boxes and semantic segmentation masks for images, videos, and text data.
Ground Truth offers flexible pricing based on annotation volume and complexity. It integrates seamlessly with AWS services for data management and model training.
Pros:
- Seamless integration with AWS ecosystem.
- Scalability for large datasets.
- Quality control mechanisms for accuracy.
- Support for active learning approaches.
Cons:
- Dependency on AWS infrastructure.
- The steep learning curve for setup and configuration.
- Limited customization options.
It is widely used in e-commerce for image classification and in healthcare for medical image annotation.
Dataloop
Dataloop is an end-to-end data annotation platform that offers tools for various data labeling tasks such as image and video annotation, text labeling, and audio transcription.
Dataloop handles large datasets efficiently and adapts to growing project needs. It easily manages data annotation tasks, assigns work, and ensures quality control within your team. Dataloop offers services for data pre-processing, annotation automation, and integration with machine learning models. It also follows a pricing plan, you can know about it here.
Pros:
- Manages large datasets and scales well for complex projects.
- Facilitates collaboration for efficient annotation workflows.
- Offers advanced features for streamlined data preparation and analysis.
Cons:
- Pricing might be higher compared to some basic annotation tools.
- Feature-rich interface might have a steeper learning curve for beginners.
This tool is used in image annotation in retail for product recognition tasks.
Labellerr
Labellerr is a cloud-based data annotation platform designed for AI and machine learning projects. It offers a range of annotation tools for image, video, and text data, with customizable workflows and collaboration features.
Labellerr offers tools to organize data, automate repetitive tasks, and ensure data quality. It helps annotate images, text, audio, and video data with a variety of tools for tasks like classification, segmentation, and keypoint labeling. Its pricing model includes a free plan for students and researchers, a monthly plan, and pay-as-you-go options based on the number of annotations or a monthly subscription plan.
Pros:
- User-friendly interface with customizable workflows.
- Supports various data types including images, videos, and text.
- Collaborative annotation and project management features.
- Flexible pricing options to suit different project needs.
Cons:
- Limited advanced machine learning integration.
- Occasional performance issues during peak usage times.
Labellerr’s platform is used in various industries for instance, in agriculture, Labellerr can be used to annotate images of crops to identify diseases or monitor plant growth, helping develop AI models for precision agriculture.
Kili
Kili is a versatile data annotation platform that supports image, text, and video annotation for machine learning projects. It offers a user-friendly interface with customizable workflows and collaboration features, making it suitable for both small-scale and enterprise-level projects.
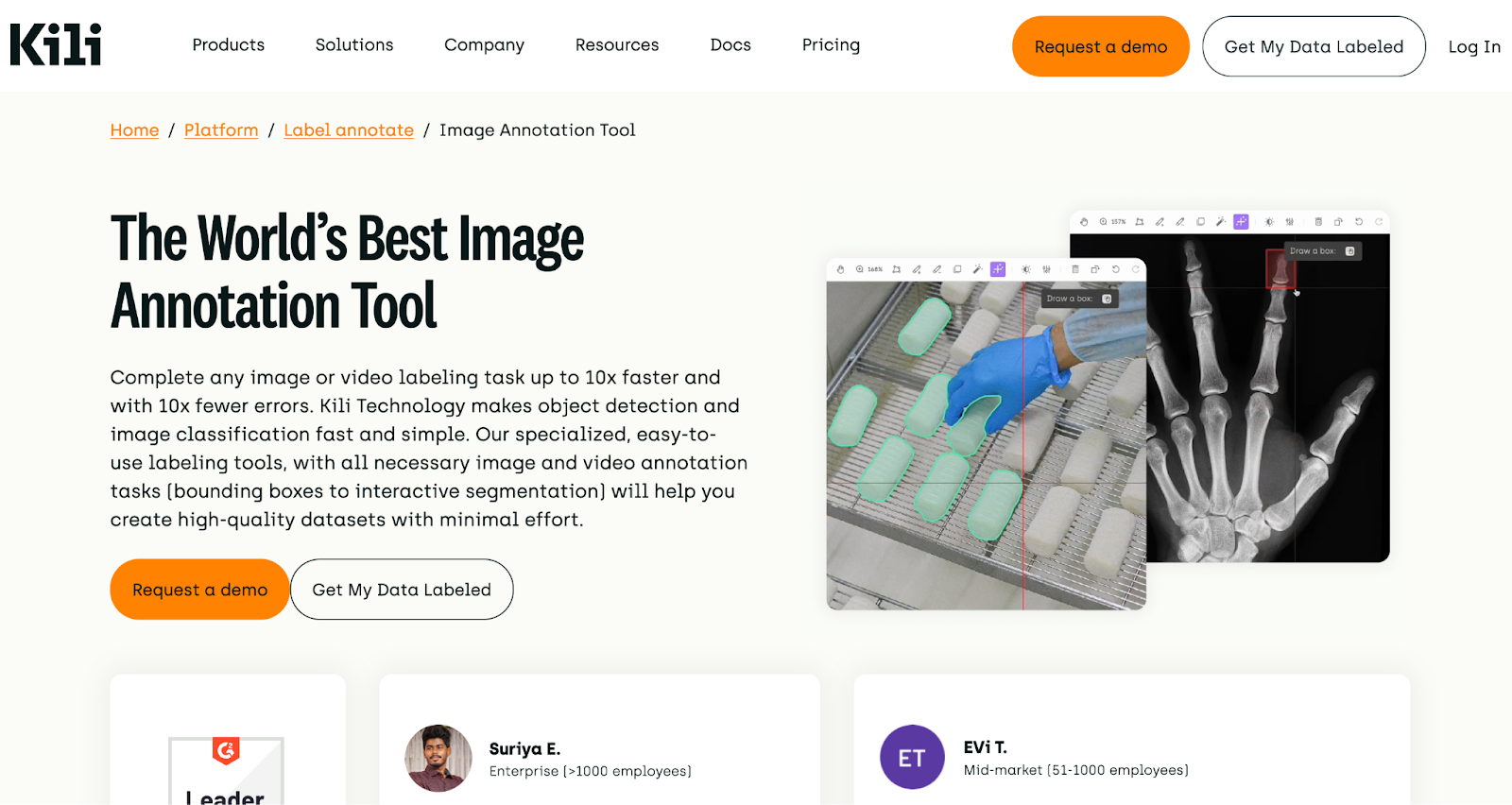
Kili combines human annotation with AI tools to streamline repetitive tasks and improve efficiency. Kili provides a range of annotation tools, including bounding boxes, polygons, and text classification, along with automated quality control features. Its pricing model offers flexible options based on the number of users and annotations, with volume discounts available for larger projects.
Pros:
- Intuitive interface with a wide range of annotation tools.
- Advanced quality control features for ensuring annotation accuracy.
- Scalable pricing model with options for both small and large projects.
Cons:
- Limited customization options for workflow management.
- Some users may find the learning curve steep initially.
- Integration with third-party machine learning platforms could be improved.
Kili can be used in retail for product image annotation tasks and in finance for document classification and data extraction.
Scale.ai
Scale.ai offers a comprehensive data annotation platform with a twist – it combines human expertise with cutting-edge machine learning. This unique approach aims to deliver high-quality, efficient annotations for your machine-learning projects.

Scale.ai leverages AI to pre-label data and guide human annotators, resulting in faster and more accurate annotations. Scale.ai provides a variety of annotation tools, including bounding boxes, polygons, and semantic segmentation, along with support for custom task creation and automation. Its pricing model offers flexible options based on project requirements and volume, with transparent pricing and scalable solutions for different needs.
Pros:
- Faster annotation through AI-assisted labeling.
- Focus on high-quality data with robust quality control.
- Scalable to accommodate growing data volumes.
Cons:
- Pricing might be higher compared to some self-service annotation tools.
- Less control over the annotation process compared to completely in-house teams.
Scale.ai is used in autonomous vehicle image annotation for image and LiDAR data annotation, as well as in retail for product recognition and classification tasks.
Conclusion
Data annotation serves as the backbone of machine learning projects, providing labeled datasets essential for training accurate models. This process of data annotation ensures that machine learning algorithms can learn from high-quality data, leading to reliable predictions and insights. Throughout this article, you have explored a range of data annotation tools, each offering unique features and capabilities tailored to different needs. Whether you prioritize user-friendliness (like Labelbox or SuperAnnotate), cutting-edge automation (V7), or open-source flexibility (Label Studio), there’s a perfect tool waiting to be discovered.
Remember, the right annotation tool is like a secret weapon for your machine-learning project. Consider your project’s data type, complexity, budget, and team size when making your choice. Don’t hesitate to explore trials and demos to find the perfect fit. With the knowledge you’ve gained and the powerful tools at your disposal, you’re well on your way to building groundbreaking AI models!
Source link
lol