29
May
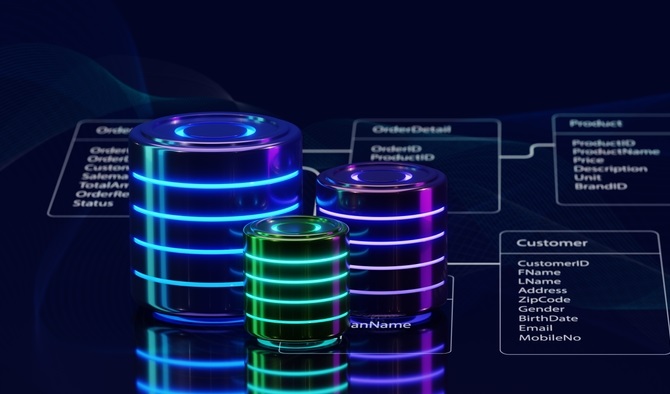
Whether it's manufacturing and supply chain management or the healthcare industry, Artificial Intelligence (AI) has the power to revolutionize operations. AI holds the power to boost efficiency, personalize customer experiences and spark innovation. That said, getting reliable, actionable results from any AI process hinges on the quality of data it is fed. Let's take a closer look at what's needed to prepare your data for AI-driven success. How Does Data Quality Impact AI Systems? Using poor quality data can result in expensive, embarrassing mistakes like the time Air Canada‘s chatbot gave a grieving customer incorrect information. In areas like healthcare, using…