23
May
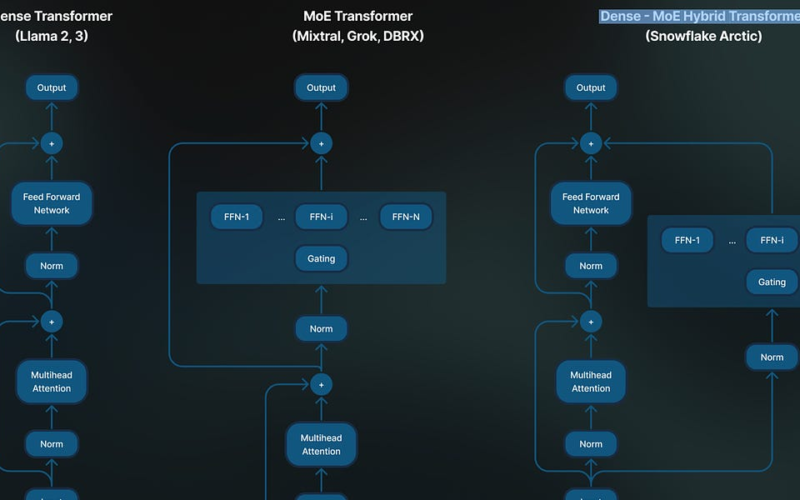
Llama 3: A Watershed AI moment? I reckon that the release of Llama 3 is perhaps one of the most important moments in AI development so far. The Llama 3 stable is already giving birth to all sorts of amazing animals and model derivatives. You can expect Llama 3 will unleash the mother of all battles against closed AI models like GPT-4.Meta AI just posted: ”Our largest Llama 3 models are over 400B parameters. And they are still being trained.” The upcoming Llama-400B will change the playing field for many independent researchers, little AI startups, one-man AI developers, and also…