One of the most impactful applications of generative AI is a knowledge copilot for humans. A knowledge copilot intelligently reasons through contextual information, providing a delightful and practical user experience. I first wrote about this topic a year ago, let’s explore the industry and technological advances since then.
A knowledge copilot is a user’s thought partner, optimized for retrieving information from a knowledge base, reasoning through context, and synthesizing responses
Reasoning: With the launch of Open AI’s o1 model last September, it’s shown that models can reason as well as they can summarize and rewrite. GPT-4o can’t correctly count the number of letters ‘r’ in the word “strawberry,” a reflection of the state of AI models before o1. While it is arguable that what the o1 model does is not the same logical reasoning that humans do, it does a good job outperforming human experts at PhD-level science questions.
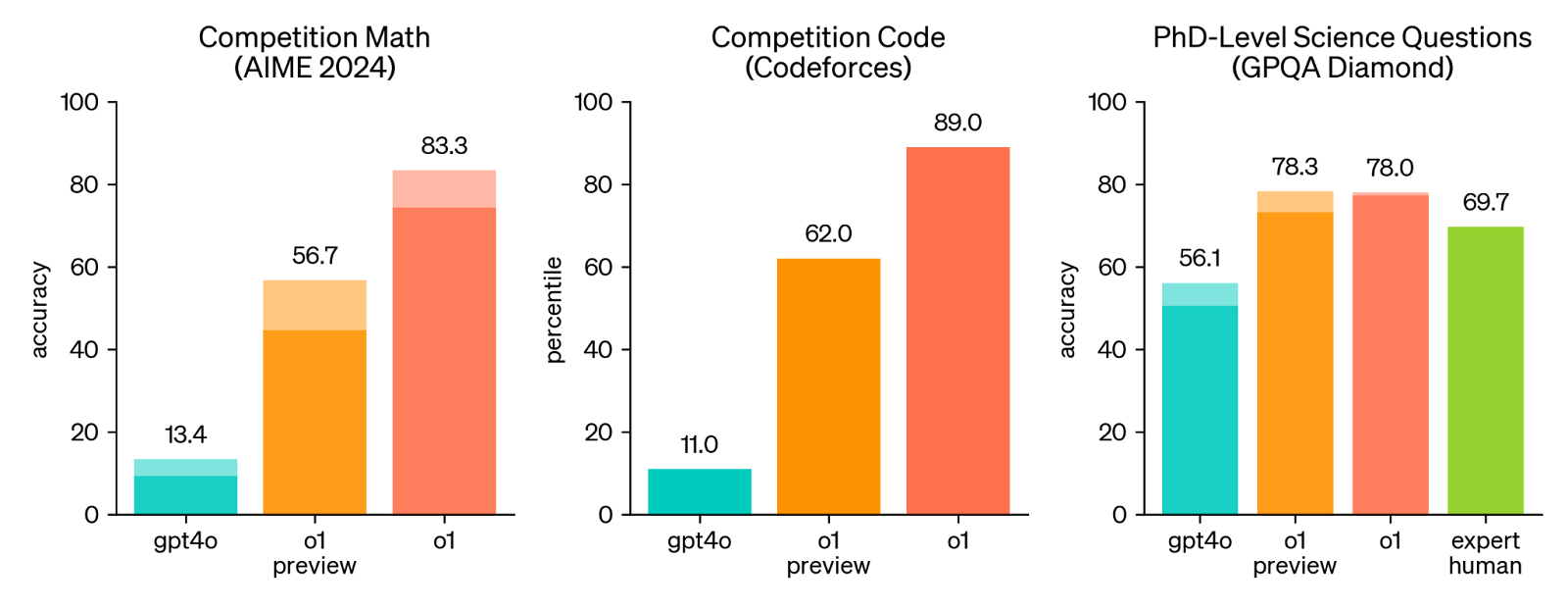
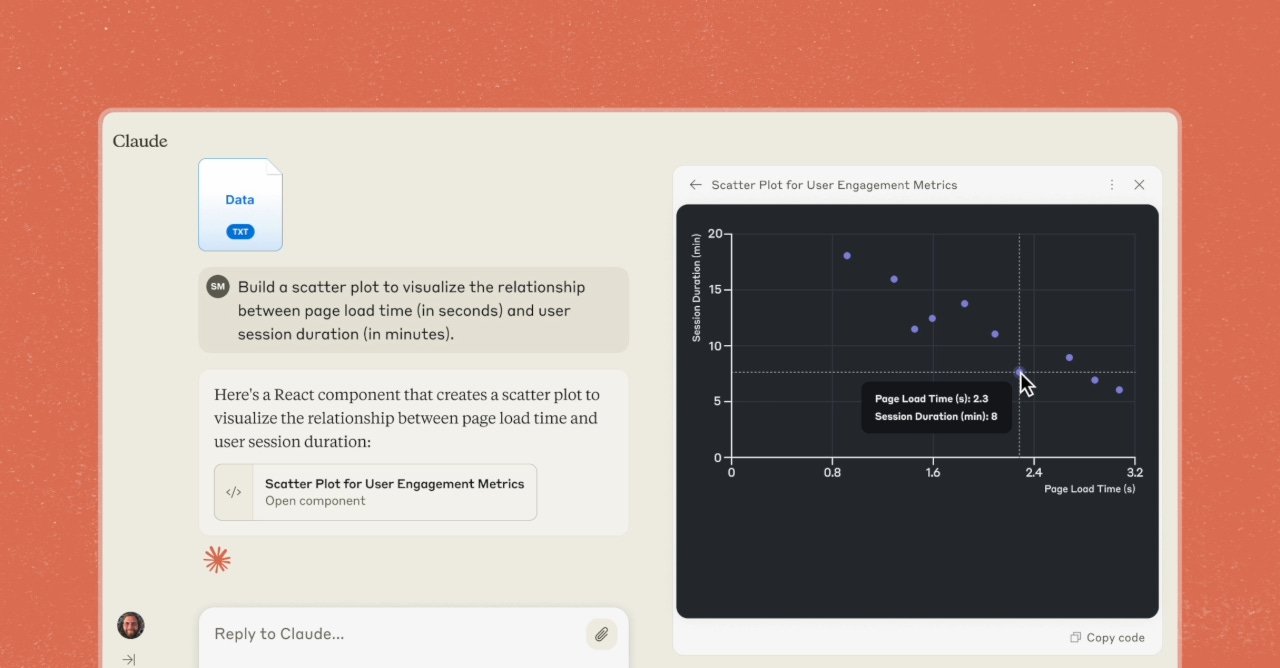
User Experience: The first copilots were pure chatbots, limited to text exchanges. Rapid improvements in copilot UX have occurred since then. Both OpenAI’s ChatGPT and Anthropic’s Claude now display code, apps, and documents—much like collaborating with another person today. ChatGPT’s advanced voice mode introduced an entirely new modality. With Anthropic’s new computer API, soon we’ll have copilots controlling our screens.
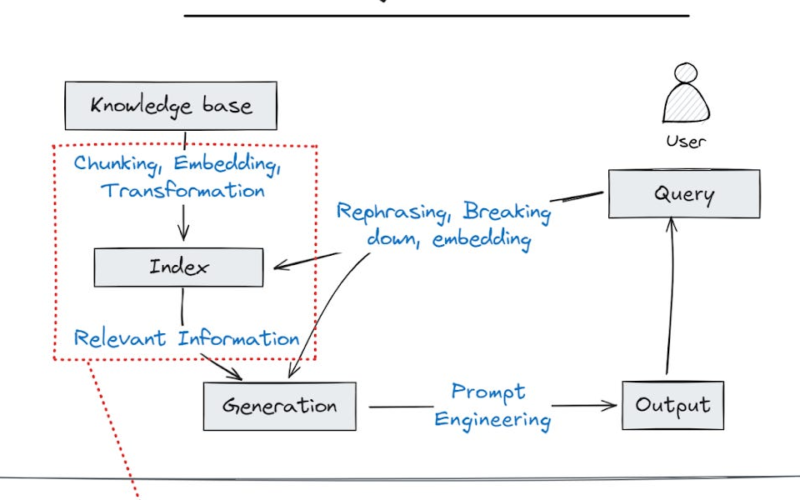
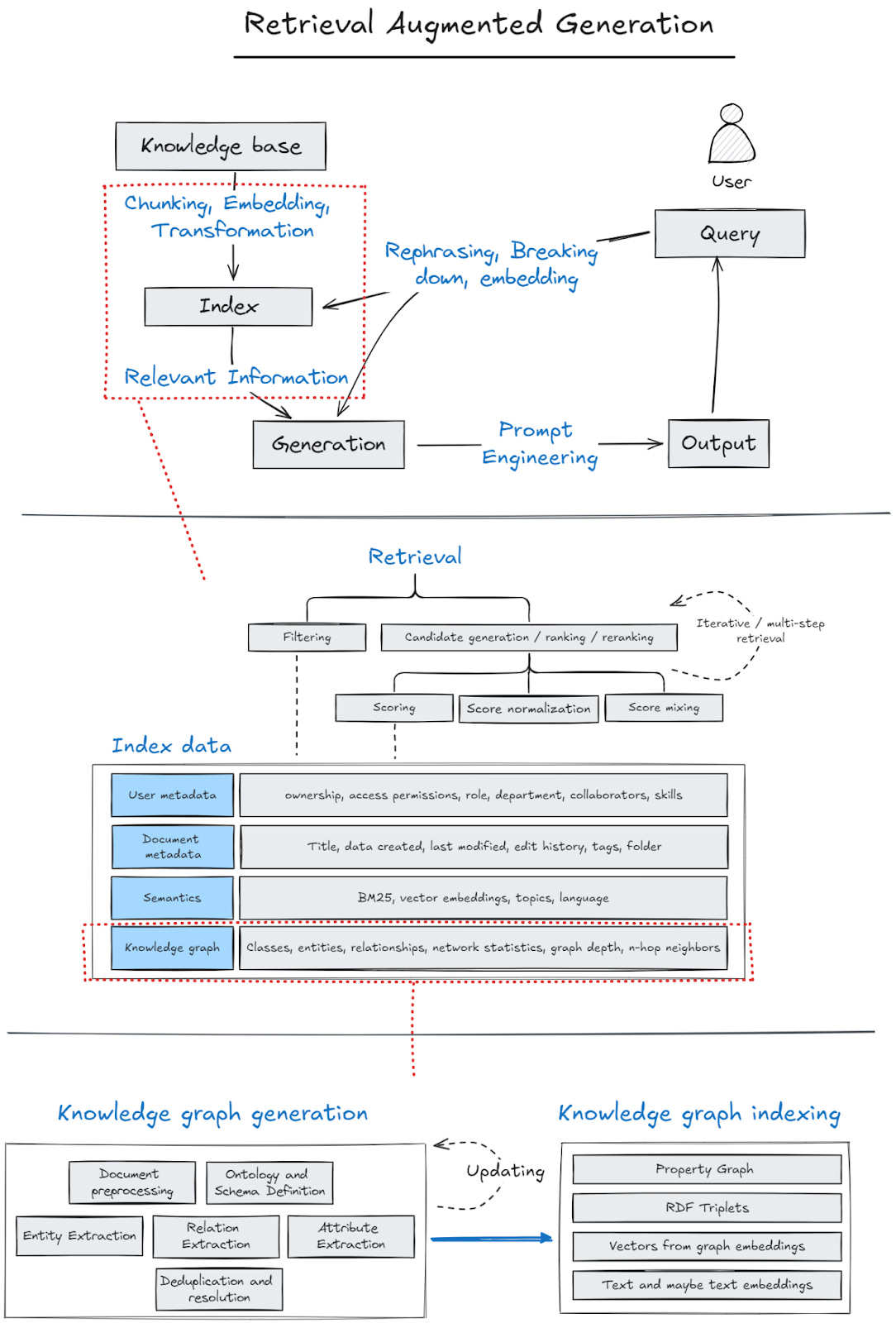
Context: For general conversations, the relevant context might be the knowledge stored within the model’s weights. For knowledge-intensive uses, the relevant context resides in private documents (i.e., knowledge base) and user information. Retrieval-Augmented Generation (RAG) is the only way to insert the ever-changing and growing knowledge base. Individually, we create new documents daily. In an enterprise, employees create thousands of new documents each day. Fine-tuning or dumping the entire knowledge base isn’t practical.
Over the past year, copilot deployments have grown from pilots to enterprise-wide. With a much larger knowledge base to sift through, RAG systems struggle to pull out the right information. It is notable that whenever RAG gets brought up in industry events I’ve attended, the vocal engineers express their frustrations about how it’s not pulling the right information. The quiet ones wince and commiserate.
As knowledge bases grow, using vector similarity becomes more fragile. The same words appear in multiple unrelated documents, making it difficult to identify the most contextually relevant documents for the copilot. Knowledge graph-augmented RAG (graph RAG) has emerged as a trend to improve accuracy. This approach was popularized by Microsoft’s GraphRAG paper and open-source project. New graph database open-source projects like Kuzu and the resurgence of Neo4j further point towards the trend.
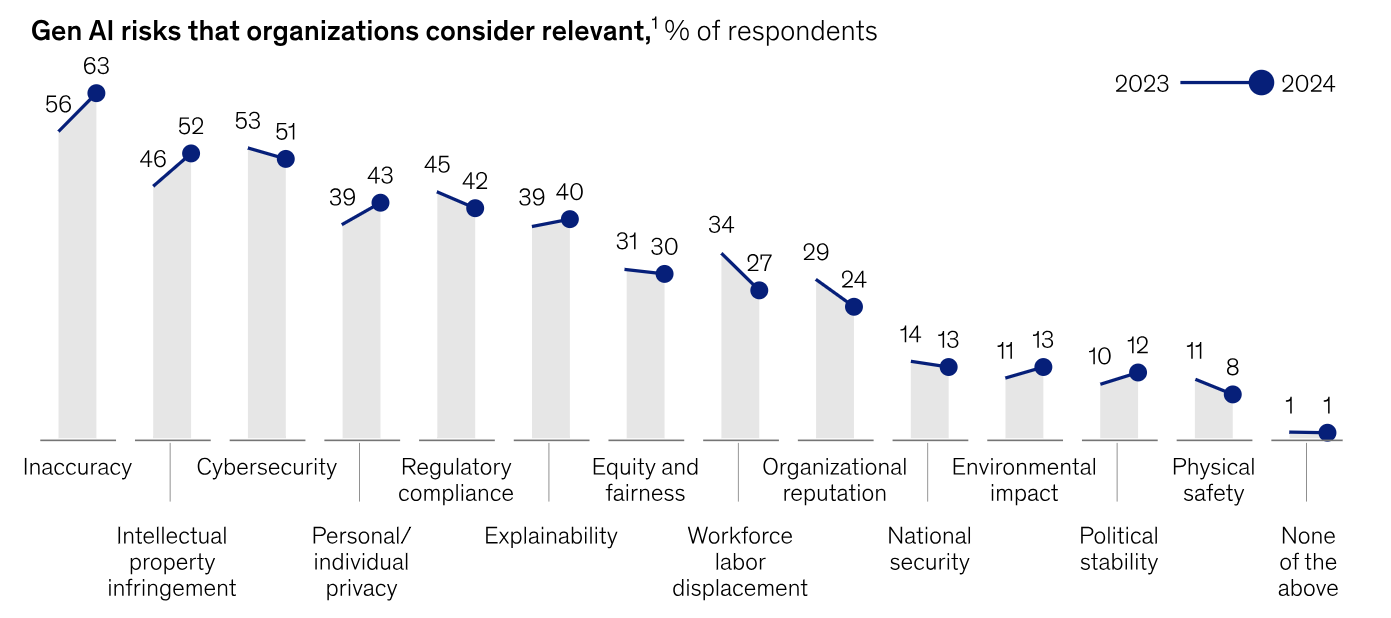
Using the wrong information as context leads to inaccurate or misleading copilot responses. That is the number one risk, and increasingly so, for organizations adopting AI. Inaccuracy erodes trust—the trust that gives us comfort to not have to constantly review copilot responses, and the trust that deters the adoption of software that many well-funded companies are building.
While better model (perhaps o2 in six months) and new user experiences (like having Claude guide my mom on how to find the settings menu on her phone) are always welcome, the bottleneck for knowledge copilots is setting the right context.
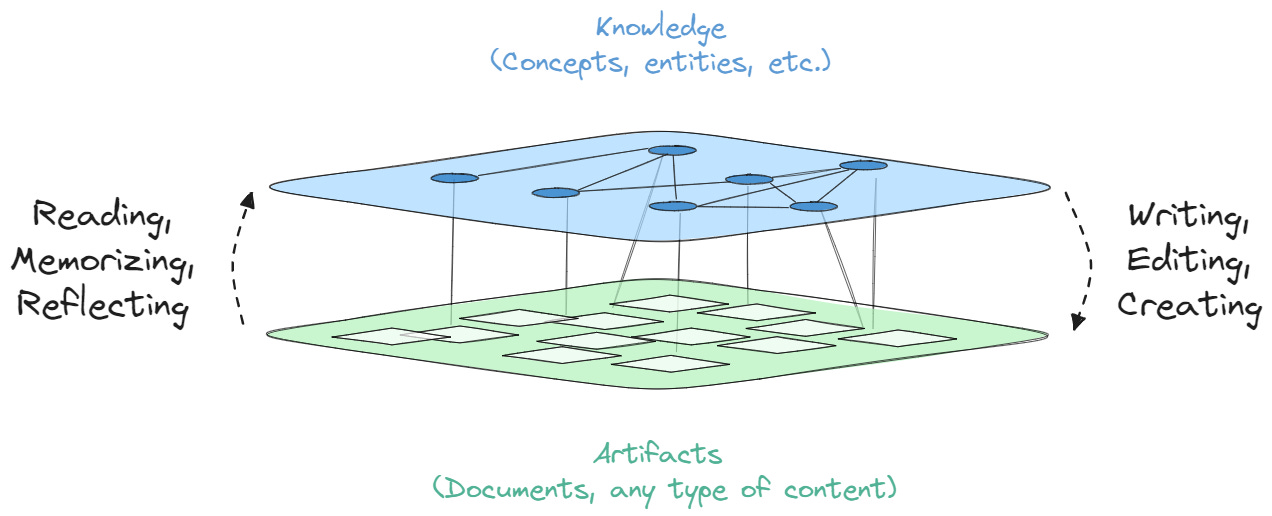
Knowledge graphs help because they are computer-readable representations of information that reflect the way humans think: entities (persons, things, events), relationships (spouse, author, attendee), and properties (age, date). The way we think is by entities and their relationships, not documents (unless you’re a lawyer): Kenn->writes->Generational. Generational->gains->Subscribers. Subscribers->seek->Knowledge. Knowledge->enhances->Learning. Learning->leads_to->Happiness. Happiness->increases_with->Subscribers.
While that is a tongue-in-cheek nudge for you to subscribe, it reflects the logical context that AI models can reference to reason through.
However, incorporating knowledge graphs into RAG is challenging. The first few steps are already complicated, requiring engineers to figure out:
-
How to parse raw documents (e.g., what about tables and drawings inside PDFs)?
-
How to chunk the parsed raw documents? Limit it to 100 tokens for all chunks? Or do we create rules to accommodate paragraph endings, sections, etc.?
-
How to augment & transform each chunk (Anthropic just introduced contextualization by pre-pending the previous chunk’s summary as context for the next chunk)?
-
What embedding model to use?
Indexing knowledge graphs is more complicated because it requires computationally intensive processing of the entire knowledge base. It involves intelligently rewriting the knowledge base into another format (graph generation) and then also having to figure out how to make it readable by the computer (graph indexing). There are several steps involved in generating a knowledge graph and different ways to index it, each with its pros and cons.
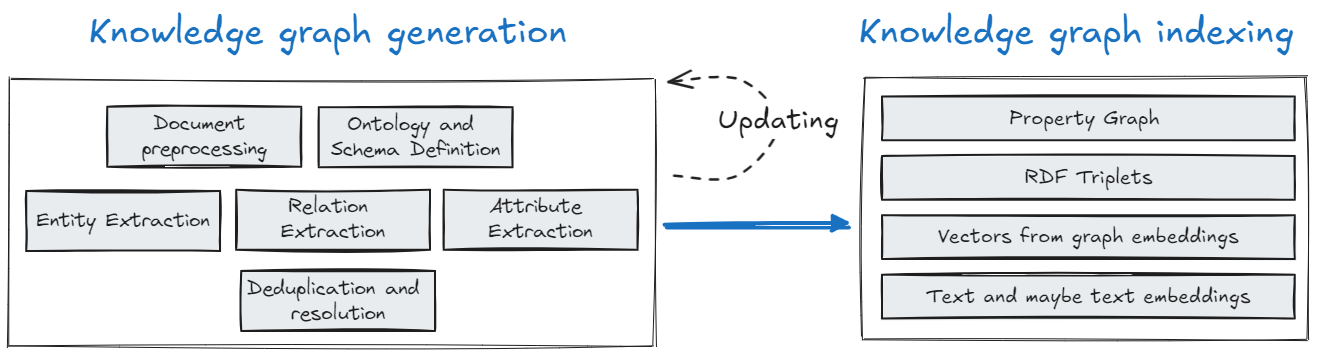
Knowledge Graph Generation:
-
Document Preprocessing: Preparing raw documents by cleaning and formatting them to ensure that the text is in a usable state for extracting knowledge.
-
Ontology and Schema Definition: Defining the structure and types of relationships that will be captured in the knowledge graph, essentially setting the rules for how information is organized.
-
Entity Extraction: Identifying key entities (such as people, places, or concepts) from the text to populate the nodes of the graph.
-
Relation Extraction: Extracting relationships between entities (such as “works at” or “is located in”) to form the edges of the graph.
-
Attribute Extraction: Identifying additional details or attributes about entities, like an entity’s age or location, which enhance the richness of the graph.
-
Deduplication and Resolution: Merging duplicate entities (e.g., “AI” and “Artificial Intelligence”) and resolving conflicts to ensure the graph is coherent.
-
Updating: As new information becomes available, the knowledge graph needs to be continuously updated to stay current. This involves re-running processes like entity extraction, relation extraction, and deduplication to integrate new data without disrupting the existing structure. The updated data is then re-indexed, ensuring that both the graph generation and indexing remain synchronized, enabling accurate and up-to-date access by computers.
Knowledge Graph Indexing:
-
Property Graph: A graph where each node and edge has associated properties, making it easy to search for specific attributes or relationships. It’s flexible and supports rich metadata but can become complex when scaling, especially with large datasets and multiple property relationships. Example:
(User:John)-[:FRIENDS_WITH]->(User:Jane) -
RDF Triples: A structure used to represent data in subject-predicate-object form, enabling a formal semantic structure. It offers a standardized way to represent relationships, ideal for web-scale data, but its rigid structure can make modeling complex, real-world scenarios more challenging. Example:
Kenn->writes->Generational -
Vectors from Graph Embeddings: Translating graph nodes into vectors allows for efficient operations like similarity searches. It excels in complex tasks like clustering, though it sacrifices the explicit relationship semantics found in the original graph. Example: A node for
User:Johnis converted into a vector[0.24, 0.87, 0.56] -
Text and Text Embeddings: Textual data is transformed into machine-readable format for easy search and comparison within the graph. While it integrates well with structured data, it can lose contextual nuances, leading to reduced accuracy in some cases. Example: The text
"John is a software engineer"
With LLMs, knowledge graph generation can be streamlined by using the same LLM for each step. But it still requires substantial engineering work to make the graph generation pipeline robust. User experience will also define the schema, which can be difficult if the application is broad.
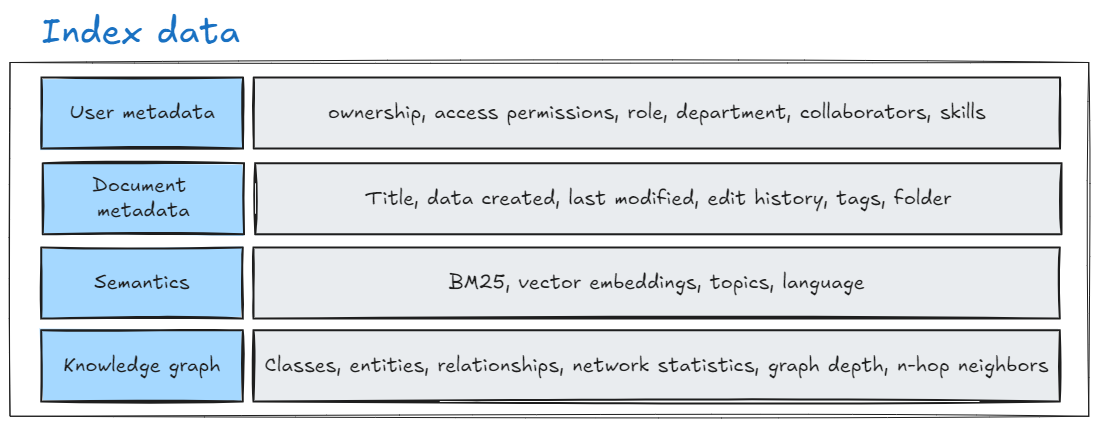
With knowledge graphs, there are four types of index data (there’s more, but we’ll stick with four) that can be used to retrieve the context. Given how complicated it can be to incorporate graphs, especially in a hybrid approach that combines multiple indexes, is it worth it?
It is. One of the more recent popular graph RAG frameworks is called LightRAG, which incorporates both knowledge graphs and semantics through text vector retrieval. The architecture below illustrates how it works.

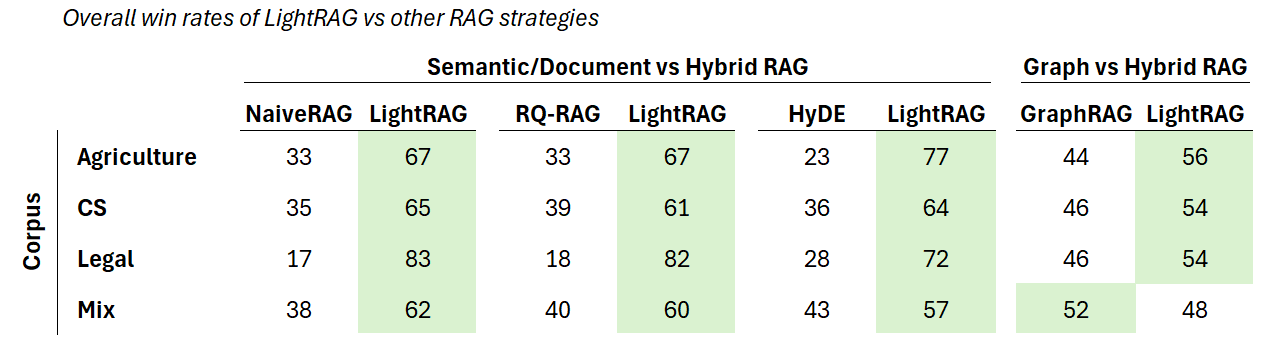
Researchers compared LightRAG to other RAG systems—Naive RAG (basic RAG that engineers often dislike), RQ-RAG (breaking down user queries into manageable sub-queries), HyDE (writing hypothetical responses to pull similar documents in the knowledge base), and GraphRAG—using different datasets from areas like agriculture, computer science, legal texts, and mixed topics. The datasets were large, containing hundreds of thousands to millions of words. To evaluate the models, the researchers looked at how well they answered questions based on completeness, variety, and usefulness.
LightRAG came out significantly ahead of the others, especially in providing complete and varied answers, thanks to its ability to combine detailed and broad retrieval through graphs and vectors. It was particularly effective with more complex and larger datasets, like legal documents, where it was better at creating rich, well-connected responses. Based on the results, a more sophisticated RAG is worth it.
Semantic/Document RAG
-
Naive RAG: Naive RAG segments texts into chunks and stores them in a vector database. It retrieves chunks based on similarity to the input query. This method is simple and fast but lacks the depth to understand relationships between the retrieved pieces, making it less effective for complex topics.
-
RQ-RAG: RQ-RAG breaks complex queries into multiple sub-queries, making each search more targeted and precise. By decomposing queries, it can retrieve information more accurately, especially when dealing with multi-faceted or ambiguous questions.
-
HyDE: HyDE generates a hypothetical document based on the query to guide the retrieval process. This approach allows the system to find information that best fits the imagined answer, making it particularly useful when the original query is vague or lacks specific keywords.
Knowledge graph RAG
-
GraphRAG (from the Microsoft paper): GraphRAG uses graphs to represent entities as nodes and relationships as edges, forming communities of related information. It retrieves data by traversing these communities, which is ideal for understanding complex interdependencies. Unlike LightRAG, GraphRAG doesn’t combine graph and vector retrieval, focusing solely on graph traversal for deeper contextual understanding.
Semantic-Document + knowledge graph (hybrid) RAG
-
LightRAG: LightRAG integrates graph structures and vector representations, allowing for both precise, low-level retrieval (specific entities) and broad, high-level retrieval (general themes). This combination makes it versatile and ensures comprehensive, context-aware responses. LightRAG can also quickly adapt to new information, without the need for full system rebuilds. Unlike GraphRAG, LightRAG’s dual system of graph and vector retrieval makes it efficient and capable of handling diverse queries.
However, knowledge graphs are just one component of a RAG system. LightRAG is already a relatively simple hybrid RAG strategy, but it remains complicated to productionize, especially as part of a larger RAG system that incorporates additional types index data into a complex retrieval system combining multiple metrics and steps.
Combine that with parsing different file formats and types, figuring out the right chunk size, transforming the prompt, and choosing the embedding model—you have a system that can serve as a technical moat for companies. It also means that building an enterprise-grade system can be a standalone business.
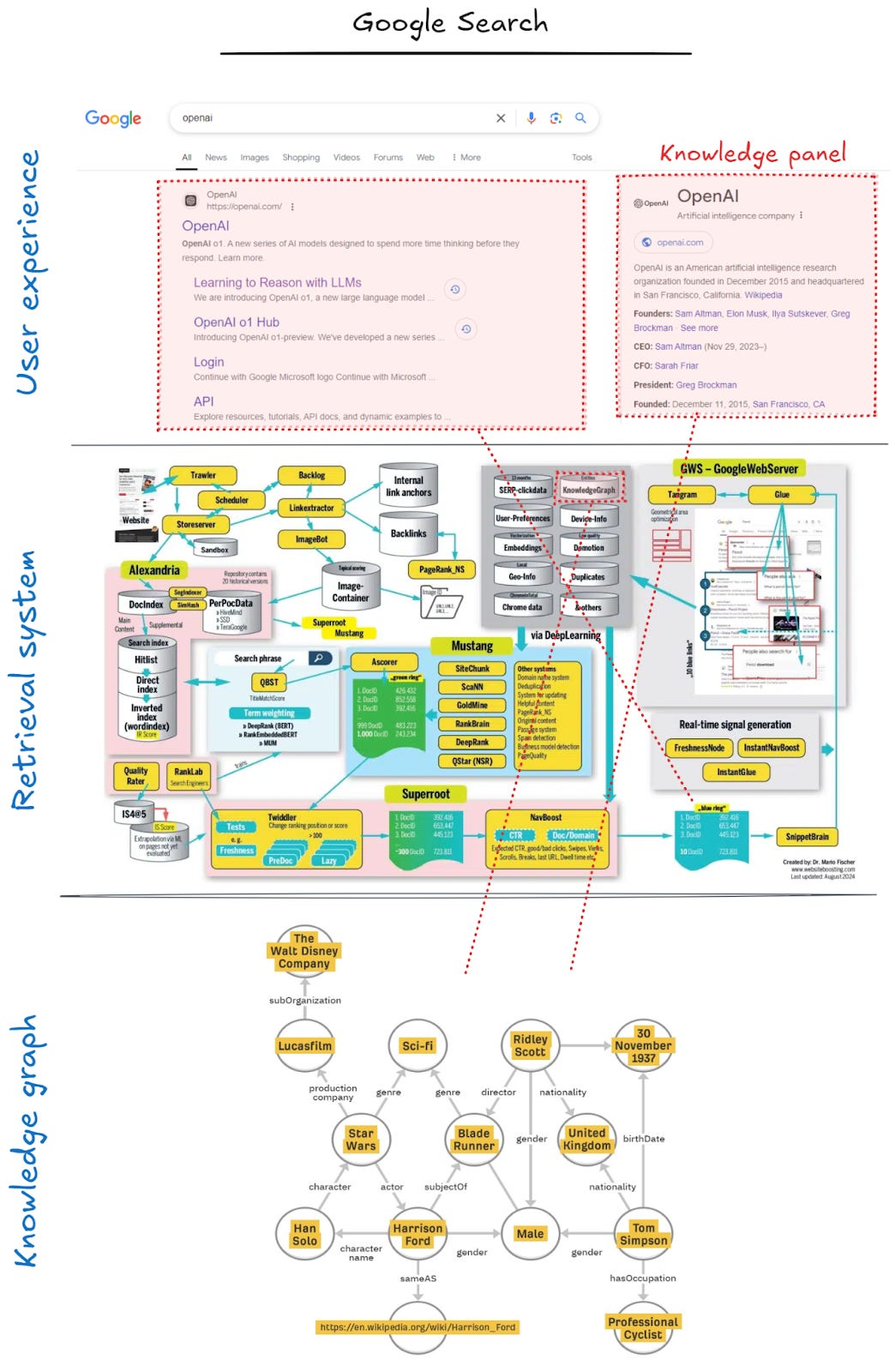
Two examples of this are Google (of course) for consumer search and Glean for enterprise search. While we don’t have details on how Glean’s systems work, we do have some for Google Search. Google’s Knowledge Graph contains 1,600 billion facts (relationships, details about entities, etc.) about 54 billion entities. It is used both to rank search results and to power a UX called knowledge panels. As you can see, the entire system is complex, with the knowledge graph forming a small yet important part of it.
Academic: Graph Retrieval-Augmented Generation: A Survey
Social: Former OpenAI Researcher Says the Company Broke Copyright Law
Commercial: Demo of Claude autonomously researching and orchestrating a sunrise hike by the Golden Gate bridge
Source link
lol